【探索实战】搞定多云多集群,Kurator 这把“瑞士军刀”是真香,带你玩转分布式云原生
【探索实战】搞定多云多集群,Kurator 这把“瑞士军刀”是真香,带你玩转分布式云原生
哎,今儿咱们不整那些虚头巴脑的概念,直接聊点硬核但又实在的东西——Kurator。你知道现在云原生这块儿,单集群玩得溜已经不算啥了,企业都开始搞多云、混合云、边缘计算,这时候光靠原生的 K8s 有点顶不住,得有个像样的“大管家”。Kurator 就是这么个角色,整合了 Karmada、Volcano、Istio 这些业界扛把子,把分布式云原生那一套给玩明白了。咱们这就扒一扒它的底裤,看看它是怎么把这些复杂的组件捏合在一起的。
1. 撸起袖子直接干:环境搭建与架构初探
既然要玩,咱就得先把它跑起来。这玩意儿安装其实没那么玄乎,官方都给咱打包好了。
极速搭建环境
咱别整那些复杂的依赖检查了,直接来个简单粗暴的。你得有台 Linux 机器,网络得通畅(你懂的)。咱们直接去它老家拉代码或者下个包。
如图这是kurator的gitCode站内资源
点击项目中可以看到如下的源码文件内容
到这一步我们下载源码就分成方便啦
如果我们有git环境就可以直接用命令clone到本地
如果没有的话也可以直接下载zip包
下载下来解压缩就能得到源码文件啦
如下是源码文件
分布式云原生架构是个啥
你想象一下,以前咱是在一台大电脑上管一堆程序,现在是你有好几个机房,有的在阿里云,有的在腾讯云,甚至还有工厂里的边缘设备。分布式云原生架构就是要把这散落在天涯海角的资源,看成“一台超级计算机”。Kurator 在这里面就是做“操作系统”的,它把底下的异构资源屏蔽掉,给你提供统一的接口。
Kurator 架构与 GitHub 大本营
这张Kurator架构图挺清晰的,Kurator 架构分为 Fleet Manager 统一管理集群、插件、应用与策略,Operator 负责流量与同步,底层集成多云与观测组件: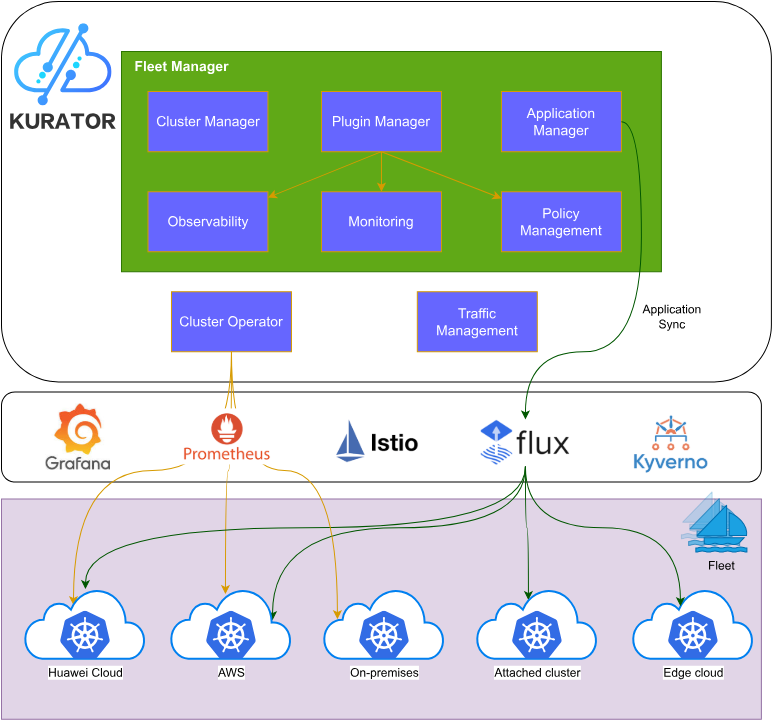
Kurator 的架构其实很像个夹心饼干。最底下是各种集群(Member Clusters),中间是核心引擎(包括 Karmada 管编排、Istio 管流量、Volcano 管调度等),最上面是统一的 API。它把这些开源大佬们集成在一起,不是简单的堆砌,而是做了深度融合。
想看源码或者给大神提 Issue?直接去 Kurator 开源项目的 GitHub 主页 溜达一圈(就在上面那个 clone 链接里)。那里活跃度还挺高,文档也全,是咱们学习的第一手资料。
2. Karmada:多集群管理的“最强大脑”
说到 Kurator 的多集群能力,核心就是 Karmada。这玩意儿简直就是 K8s 的 K8s。
Karmada 多集群管理平台的核心架构
Karmada 的架构特别有意思,它分了“控制面”和“数据面”。
- 控制面:就像个总指挥部,它有自己的 API Server、Controller Manager 和调度器。你把任务发给它,它不跑业务,只负责发号施令。
- Agent 模式:它支持 Push 和 Pull 两种模式。如果你的子集群在内网,Karmada 还能通过 Agent 主动连回来,这就解决了复杂的网络穿透问题。
这是Karmada多集群管理平台的核心架构图,展示了控制平面如何通过推送和拉取两种模式与成员集群进行协同管理: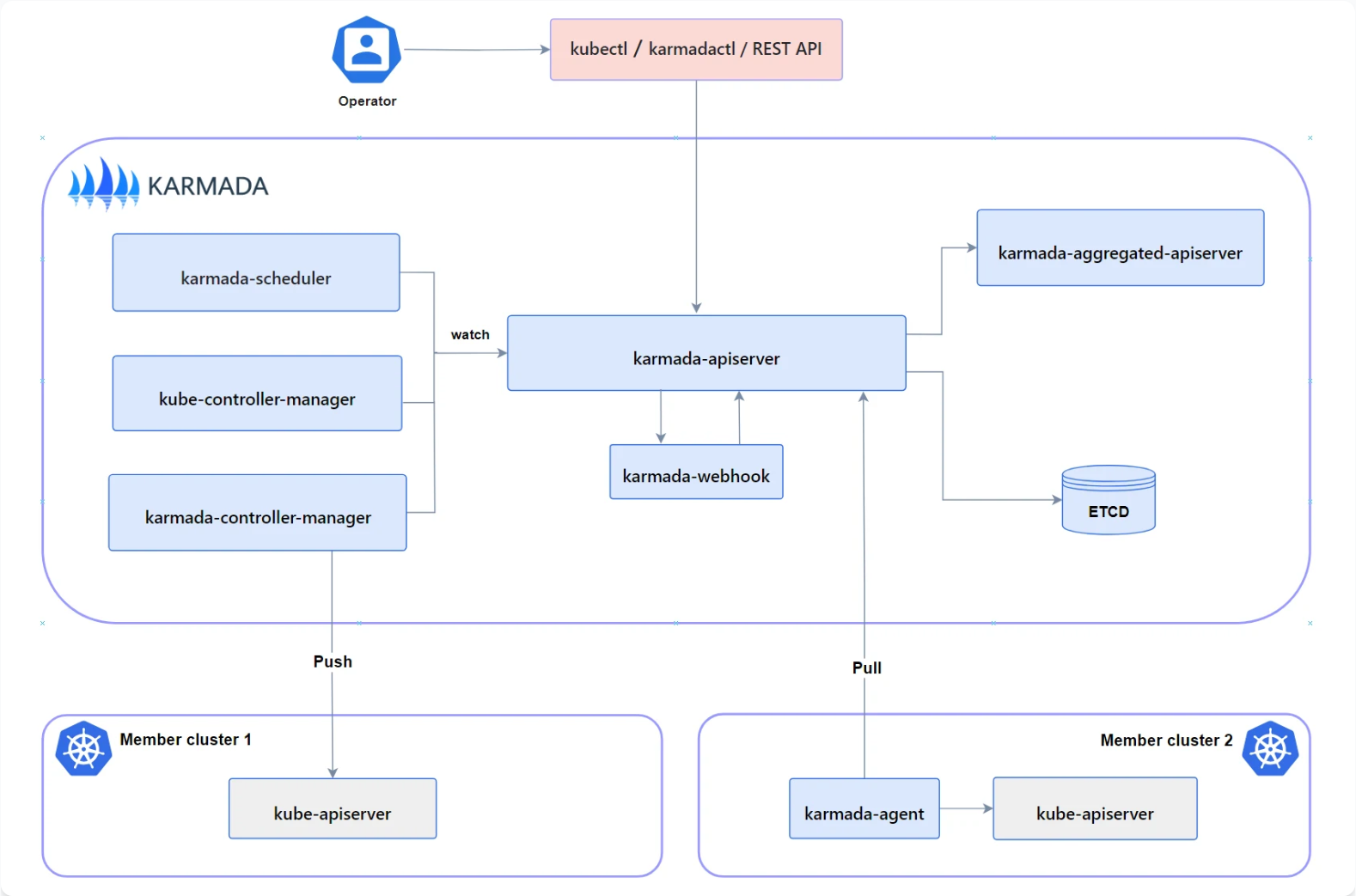
Karmada 跨集群弹性伸缩策略
这个功能我必须要吹一下。以前你的应用在 A 集群爆了,B 集群还空着,干着急。Karmada 的跨集群弹性伸缩(FederatedHPA) 能让你定义一个全局的伸缩策略。
比如说,你有个 Web 服务,流量来了,它能自动检测到 A 集群 CPU 满了,然后直接在 B 集群给你扩容新的 Pod。这就好比你开分店,总店人满了,自动把客流导到隔壁新开的分店去,无缝衔接。
这是Karmada跨集群弹性伸缩策略参考图,展示了其如何通过FederatedHPA策略在多个成员集群间协调Pod副本数实现统一伸缩: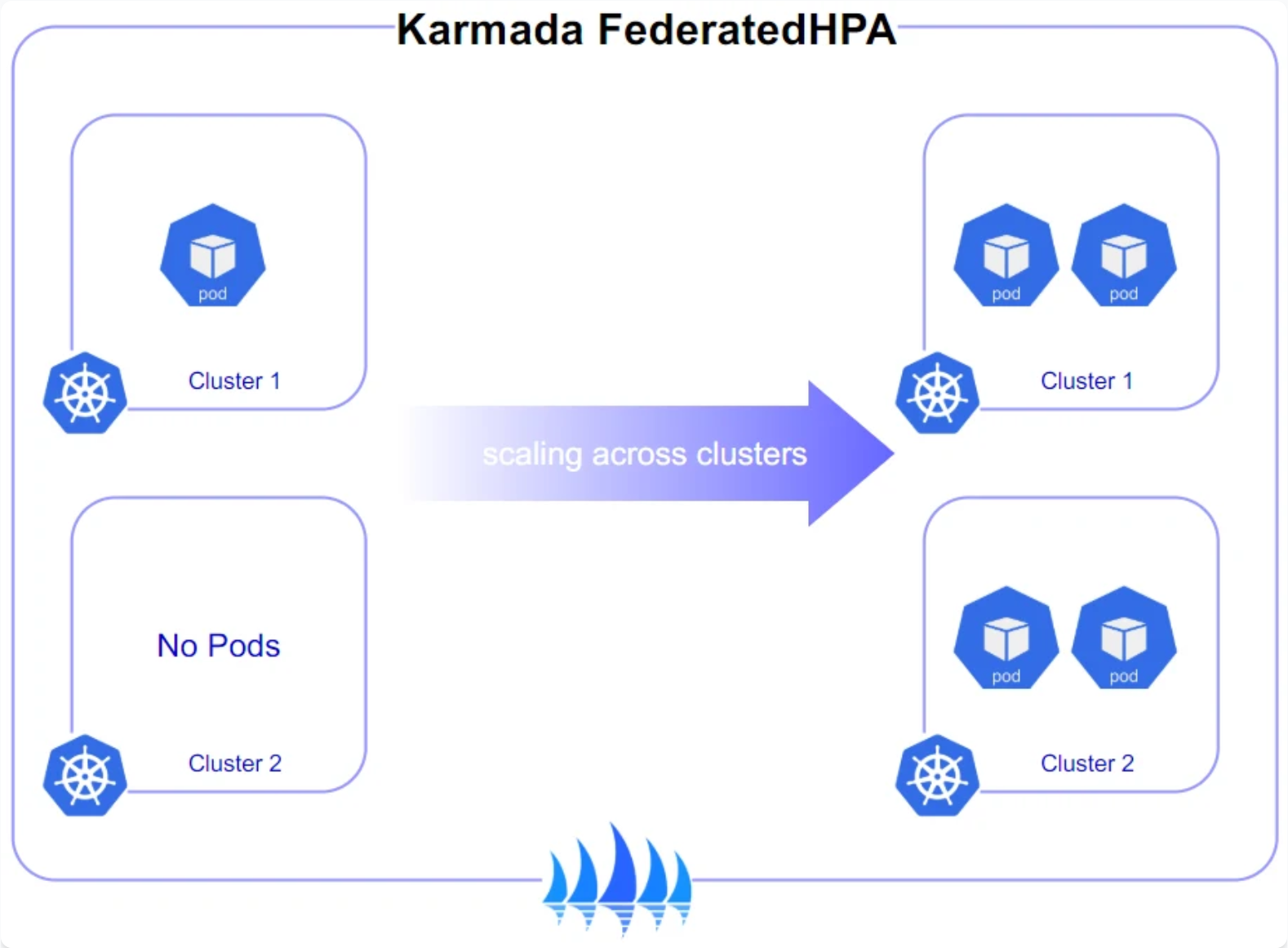
3. Fleet 与策略:像管一个连队一样管集群
Kurator 引入了 Fleet(舰队)的概念,这名字听着就霸气。意思就是把一堆集群编个队,统一管理。
Fleet 队列中身份相同性
这是Fleet队列中身份相同性的官方示意图,直观展示了跨集群的命名空间与部署服务间关联映射关系: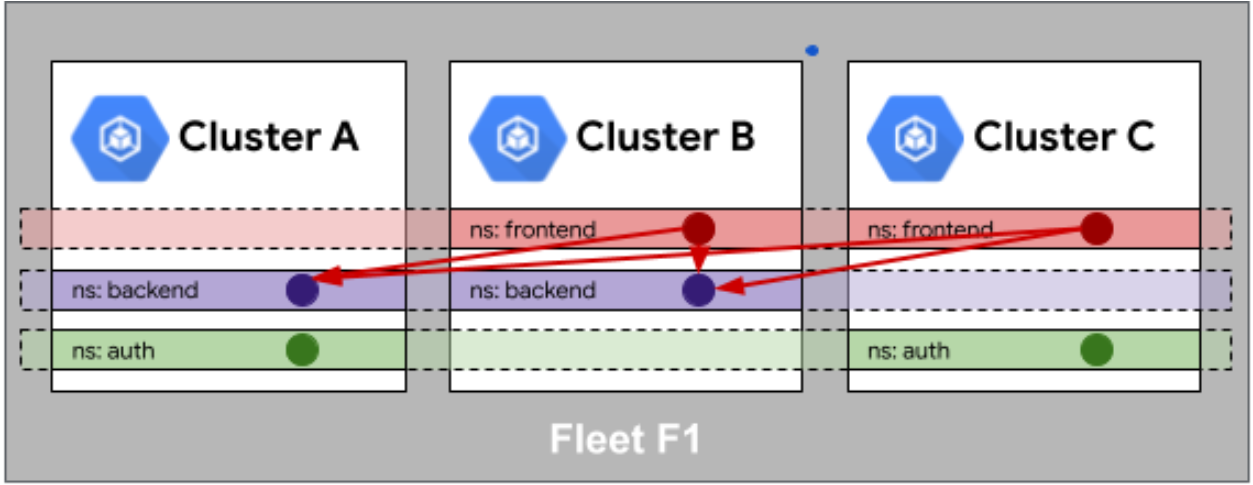
这块儿稍微有点绕,但很重要。在 Fleet 模式下,有个叫 Identity Sameness(身份相同性)的概念。啥意思呢?就是你在集群 A 里的“张三”(ServiceAccount),到了集群 B 里还得是“张三”,权限、认证信息得一模一样。
这就好比你拿了张工牌,在总部能刷开门,去分公司出差,这卡照样能刷开门,系统还得认出是你。这对于跨集群的服务调用简直是救命稻草,不然每个集群都要重新配一套账号体系,运维得疯。
Fleet 基于 Kyverno 的多集群策略架构
这是Fleet基于Kyverno的多集群策略管理架构图,展示了策略配置如何通过Fleet分发到各集群执行引擎: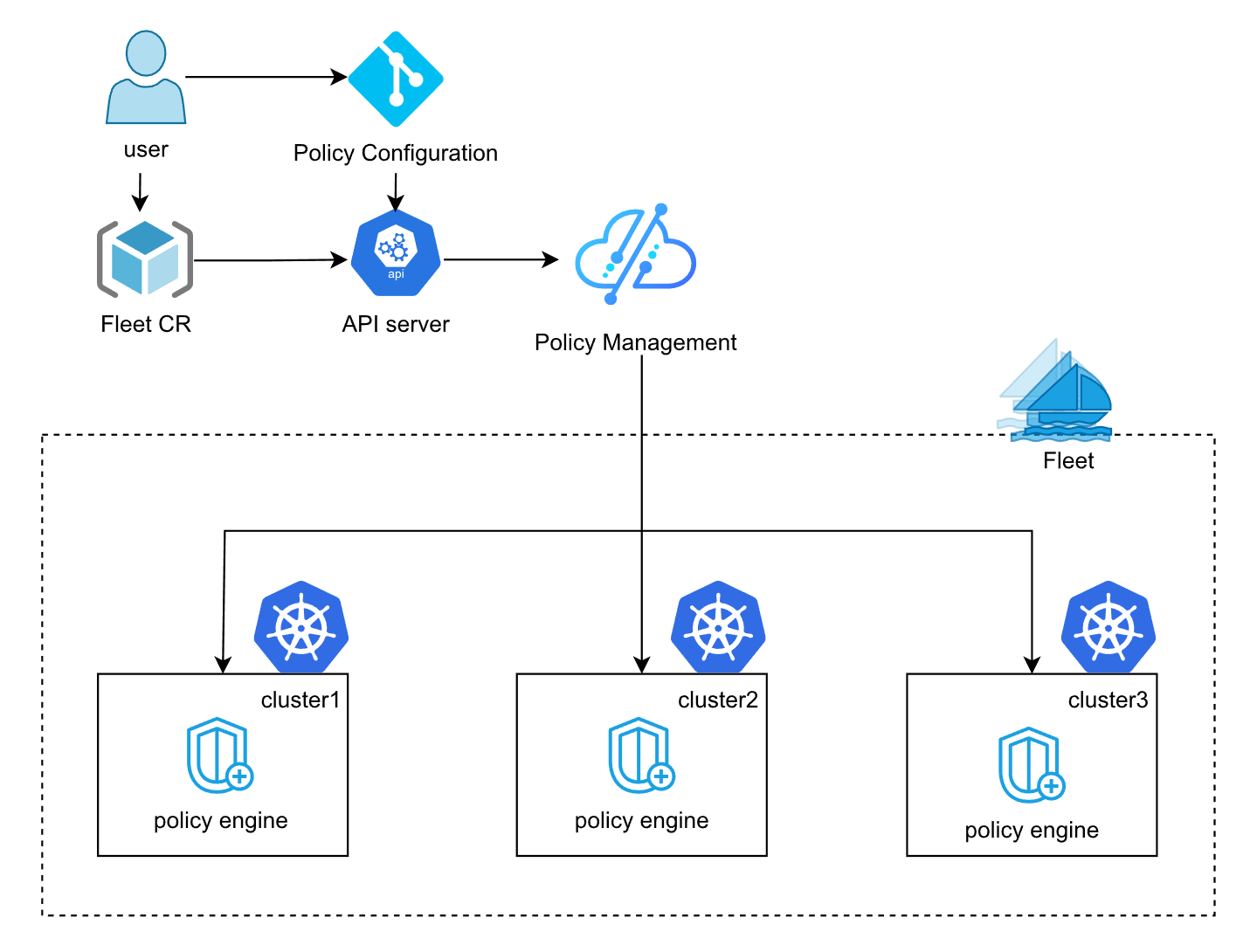
管一群熊孩子(集群)必须得有家规。Kurator 用的是 Kyverno 来做策略管理。
它的架构是这样的:你在 Fleet 的控制面定义好策略(比如“所有镜像必须来自公司私有库”),Kurator 会通过 Fleet 的管道,把这个策略分发到每一个子集群里。子集群里有个 Kyverno 的 Agent 守着,谁敢违规部署,直接拦截。
Kurator 的统一策略管理架构
这张图展示了Kurator的统一策略管理架构,用户只需要在一处定义策略,就能通过Fleet和FluxCD自动同步到多个集群,配合Kyverno实现跨集群的一致性治理,真正做到“一次配置,全栈生效”: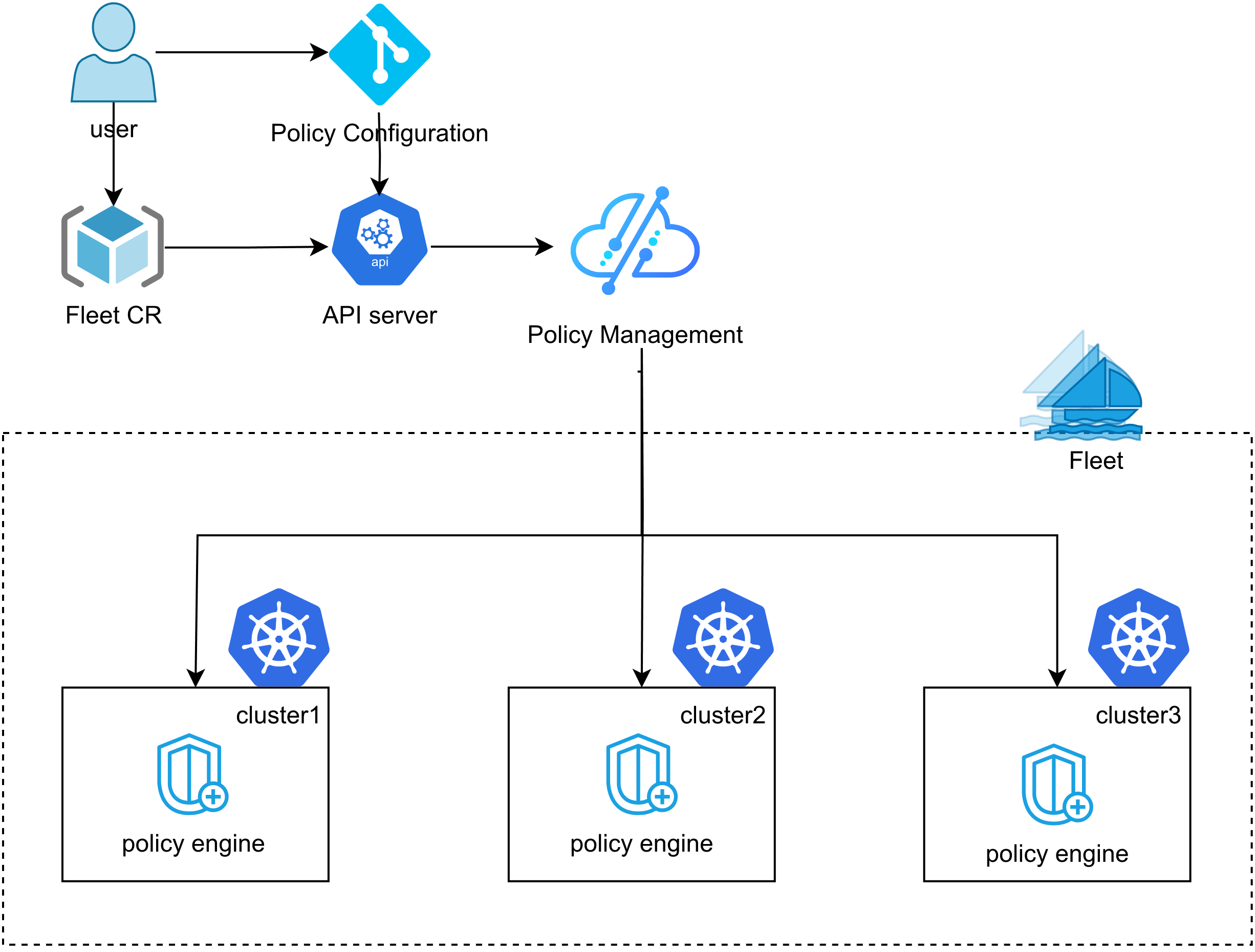
Kurator 把这个再升华了一下,做成了统一策略管理。你不需要去每个集群敲 kubectl apply。你只需要在 Kurator 的控制台写一份 Policy YAML,它自动同步。
# 这是一个手搓的策略示例,意思是不许用 root 用户跑程序
apiVersion: kyverno.io/v1
kind: ClusterPolicy
metadata:
name: disallow-root-user
spec:
validationFailureAction: enforce
rules:
- name: check-runasnonroot
match:
resources:
kinds:
- Pod
validate:
message: "哥们,这容器不能用 root 跑,这是规矩!"
pattern:
spec:
securityContext:
runAsNonRoot: true
4. 调度与网格:精细化操作的艺术
光把应用发下去不行,还得跑得好(调度)和通得顺(网络)。
Volcano 分组调度
这是Volcano分组调度参考图,展示了其如何通过整体资源检查与阈值判断,实现批处理作业的成组调度与资源保障: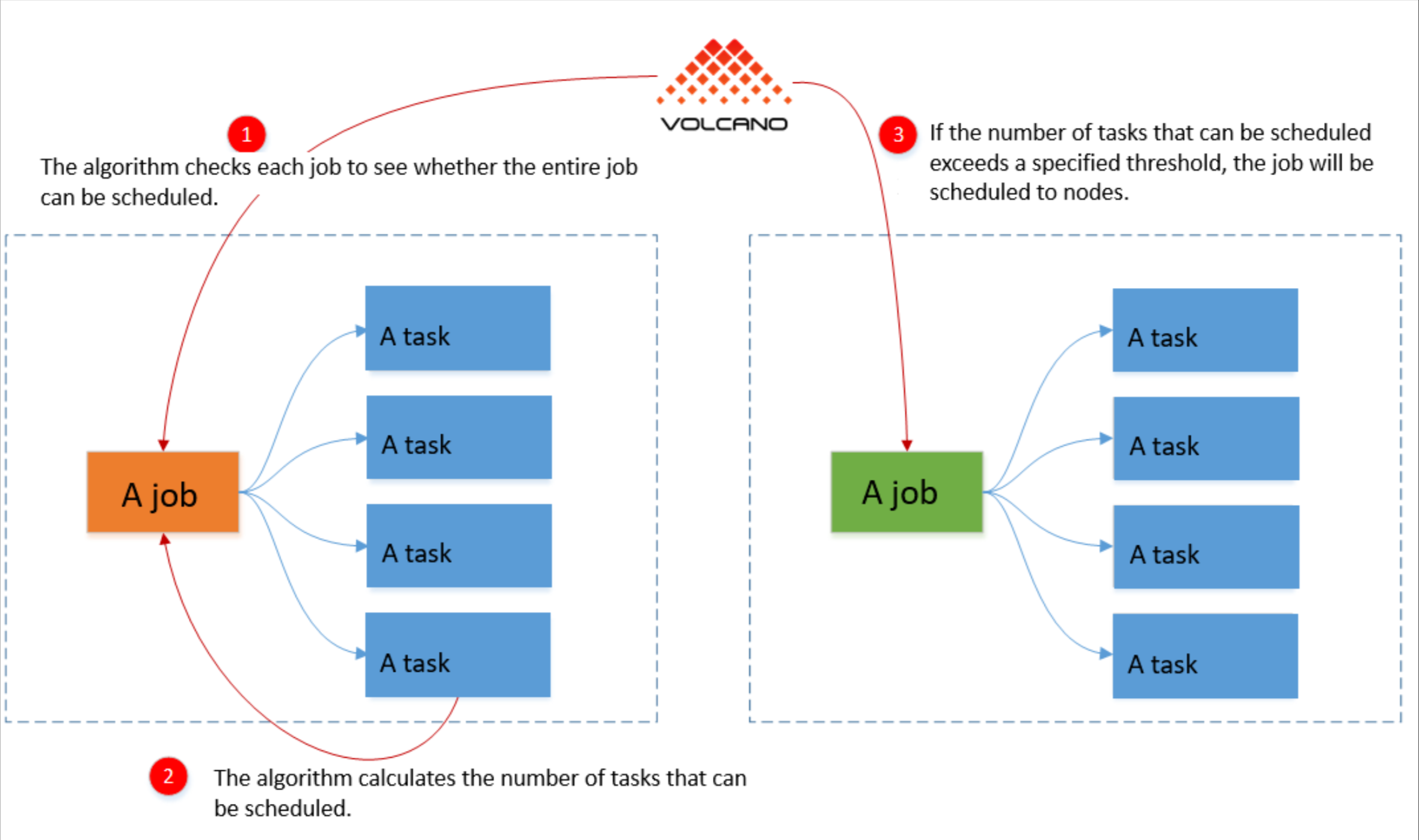
对于搞 AI 或者大数据的兄弟,Kubernetes 原生的调度器有点弱鸡。Kurator 塞了个 Volcano 进去。
重点聊聊 Volcano 分组调度(Gang Scheduling)。这就好比以前是只要有空位就坐,现在是“不管是 5 个人还是 10 个人,必须凑齐了一起上桌吃饭,少一个都不开席”。这对于那种需要并行计算的任务特别关键,避免了死锁——比如资源只够起一半的 Worker,结果大家都卡在那等另一半,纯浪费资源。
Istio 服务网格
这是Istio服务网格的参考架构图,展示了服务间通过Envoy代理进行通信,并由统一控制平面提供发现、配置与安全策略: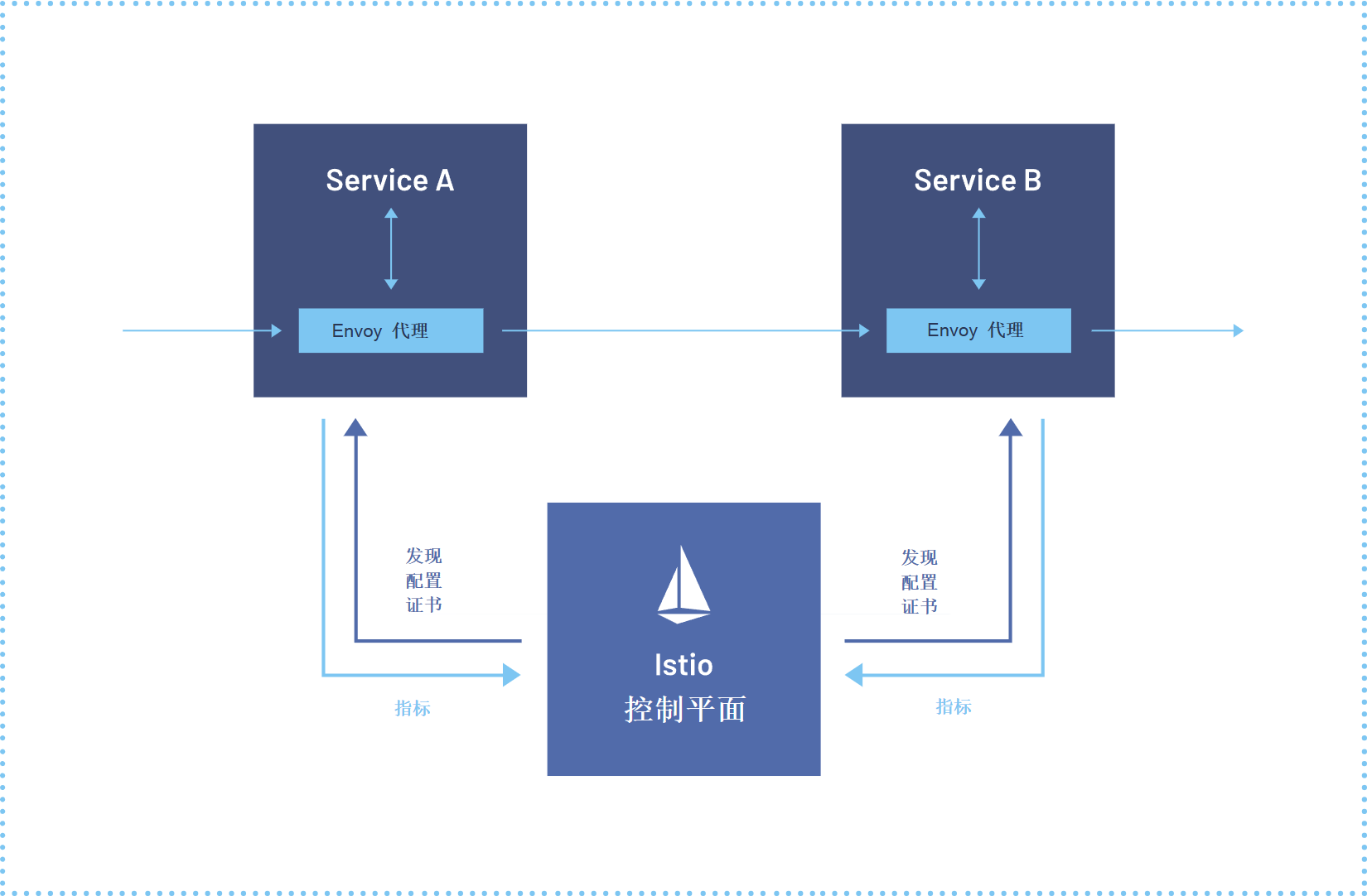
跨集群网络是个大坑,Kurator 用 Istio 服务网格 来填。它不仅解决了服务发现的问题(A 集群的服务怎么找到 B 集群的服务),还搞定了流量治理。你可以做跨集群的金丝雀发布,或者全局的熔断限流。Kurator 帮你把 Istio 的控制面和数据面配置都屏蔽了,你只管用就行。
5. GitOps 与分发:自动化的物流系统
最后咱聊聊怎么把代码变成服务,这块儿 Kurator 结合 GitOps 玩得很溜。
GitOps 边缘计算
在边缘计算场景下,服务器可能在塔克拉玛干沙漠的某个基站里,网路时断时续。传统的“推”模式很容易失败。
Kurator 采用 GitOps 模式,配合 FluxCD。边缘节点只要连上网,就会去 Git 仓库里拉取最新的配置。断网了没事,本地继续跑;网来了,自动同步。这叫“最终一致性”,特别适合边缘这种若即若离的环境。
Kurator 分发流程的状态机
这个比较底层,但很有意思。Kurator 在分发应用时,内部维护了一个严密的分发流程状态机。
你可以把它想象成一个快递物流系统:
- Pending(揽件中):任务刚提交,还在检查依赖。
- Syncing(运输中):配置正在往各个目标集群同步。
- Applied(派送中):配置已经到了子集群,正在执行 Apply。
- Ready(已签收):子集群反馈说“我跑起来了”。
- Failed(拒收):中间任何环节出错,状态机都会捕获异常,并根据策略决定是重试还是报错。
这套状态机保证了你发 1000 个集群,心里也有底,知道哪个卡住了,哪个好了。
# 假装这是我们在监控分发状态
apiVersion: apps.kurator.dev/v1alpha1
kind: Application
metadata:
name: my-super-app
status:
# 这里的状态机流转是自动的
phase: Syncing # -> 可能会变成 Ready 或者 Failed
conditions:
- type: Ready
status: "False"
reason: "ClusterB_Network_Error"
message: "B集群网线好像被人拔了,正在重试..."
关于 Kurator 的这点事儿,今儿就聊到这。其实你只要记住,它就是一个把 Karmada、Volcano、Istio 这些牛逼工具打包并在多云环境下调教好的“超级管家”。下次再遇到多集群的烂摊子,试试 Kurator,没准能让你早点下班。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 20
20 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)