【探索实战】Kurator 做稳态:一位 SRE 眼里的分布式云原生韧性工程!
一、先说痛感:多云多集群时代,SRE 的难度是几何级数在涨
以一个典型中大型互联网/ToB 企业为例,基础架构大多长这样:
- 公有云厂商 A:主营业务生产集群 + 预发集群
- 公有云厂商 B:推荐、搜索、AI 相关集群
- 自建机房:一些核心系统、历史服务和数据平台
- 边缘节点:靠近用户的接入、缓存或推理集群
技术栈表面上很统一:“大家都有 Kubernetes”。
但真正到 SRE 桌面上的事情,是这些:
-
告警来自四五套 Prometheus / 云监控 / APM,同一个接口错误率要在 N 个看板里找;
-
发布流程千差万别:有的用 Jenkins + kubectl,有的用 Helm,有的用 GitOps;
-
策略散落各处:Pod 安全、配额、网络策略、准入 Hook 分别在各集群“手抄”一遍;
-
灾备演练时,很难回答一句话:
“这个用户面向的关键服务,在所有集群上的错误率、延迟和容量情况,现在到底怎样?”
这也是我看 Kurator 的时候,最关心的一点:
它能不能把这些“多集群稳定性问题”,归并成一套可治理的“平台能力”?
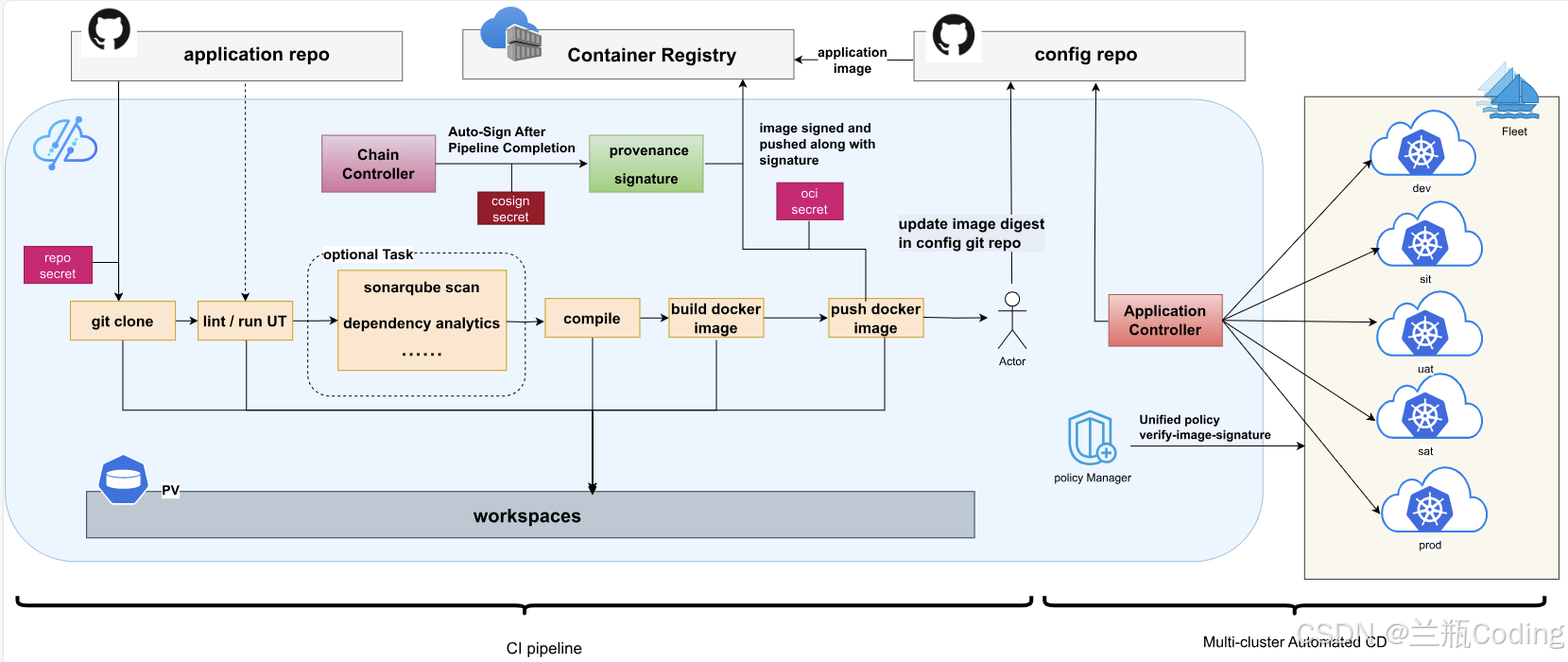
二、Kurator 在稳定性上的“基本盘”:它到底帮了什么忙?
Kurator 自身的官方定位是“开源分布式云原生平台”,集成了 Kubernetes、Istio、Prometheus、Karmada、KubeEdge 等主流项目,帮助用户构建和管理分布式云原生基础设施,强调 GitOps、应用统一分发、监控与策略统一治理等能力。([华为开发者][1])
从一个 SRE 的视角,我会把它的“稳态能力”拆成几块来看:
-
统一资源与拓扑:Fleet + AttachedCluster
AttachedCluster把已有集群纳入 Kurator 管理,不管它是在哪个云、用啥方式搭的。([华为开发者][1])Fleet把“业务相关的一组集群”打包成一个逻辑管理单元,在这个层级上挂监控、策略、发布等插件。([华为开发者][1])
-
统一应用与发布:Application + Rollout
Application用 GitOps 方式做多集群应用分发,解决“版本不一致”和“人工多次操作”的问题。([华为开发者][1])Rollout提供金丝雀、A/B、蓝绿等策略,在一个 Fleet 维度实现统一灰度发布。([GitHub][2])
-
统一观测:Metric 插件 + Prometheus + Thanos + Grafana
- 在各集群下发 Prometheus + Thanos Sidecar,在上层聚合为统一的 Query 入口,再配 Grafana 做多集群指标视图。([华为开发者][1])
-
统一安全与策略:Policy 插件 + Kyverno
- Policy 插件基于 Kyverno,在 Fleet 颗粒度配置策略,统一 Pod 安全标准、资源配额等。([华为开发者][1])
-
标准化变更路径:Pipeline + Tekton / Tekton Chains
- Pipeline 封装 Tekton 进行 CI/CD,并引入 Tekton Chains 做供应链安全和溯源。([GitHub][2])
如果把 SRE 的工作拆成“守住 SLO + 控制变更 + 管理容量 + 防人祸 + 跑演练”,Kurator 基本都提供了某种层面的“钩子”,关键在于怎么把这些能力串联起来。
接下来我就按“稳定性工程的五个常见场景”,一步步走一遍。
三、搭一套“稳定性实验场”:最小化 Kurator 多集群环境
这一节更多是给“想自己实操一遍”的人准备,你可以按需删减或替换为企业内部环境的搭建过程。
3.1 本地结构:1 个管理集群 + 2 个成员集群
用 kind 起 3 套集群:
# 管理集群(宿主)
kind create cluster --name kurator-host
# 成员集群,用来模拟两个业务区域
kind create cluster --name cluster-blue
kind create cluster --name cluster-green
设置 KUBECONFIG 指向管理集群,并安装 Kurator 相关组件(Cluster Operator、Fleet Manager 等),具体命令可以参考官网文档或 Helm 安装说明。([华为开发者][1])
3.2 把成员集群接入 Kurator:Secret + AttachedCluster
为两个成员集群创建 kubeconfig Secret:
kubectl create ns kurator-system
kubectl -n kurator-system create secret generic cluster-blue-kubeconfig \
--from-file=kubeconfig=/path/to/cluster-blue.kubeconfig
kubectl -n kurator-system create secret generic cluster-green-kubeconfig \
--from-file=kubeconfig=/path/to/cluster-green.kubeconfig
创建 AttachedCluster:
apiVersion: cluster.kurator.dev/v1alpha1
kind: AttachedCluster
metadata:
name: cluster-blue
namespace: kurator-system
spec:
kubeconfig:
name: cluster-blue-kubeconfig
key: kubeconfig
---
apiVersion: cluster.kurator.dev/v1alpha1
kind: AttachedCluster
metadata:
name: cluster-green
namespace: kurator-system
spec:
kubeconfig:
name: cluster-green-kubeconfig
key: kubeconfig
应用后,确认两个 AttachedCluster 的状态:
kubectl get attachedcluster -n kurator-system
小建议:在企业环境里,可以约定 AttachedCluster 的命名和 CMDB 中的“集群 ID / 区域 ID”保持一致,后续做 SLO 与容量报表时更好对齐。
3.3 声明一个 Fleet:为“一个业务域”建管理边界
我们把这两个集群当成同一个用户-facing 业务的“蓝 / 绿”双集群,建立一个 Fleet:
apiVersion: fleet.kurator.dev/v1alpha1
kind: Fleet
metadata:
name: checkout-fleet
namespace: kurator-system
spec:
clusters:
- name: cluster-blue
kind: AttachedCluster
- name: cluster-green
kind: AttachedCluster
plugin:
metric: {} # 后面再补充监控配置
policy: {} # 后面再挂策略
应用后,一个“围绕结算业务的一组集群”的逻辑边界就立起来了。
接下来,我们就以这个 Fleet 为核心,展开 SRE 的几大场景。
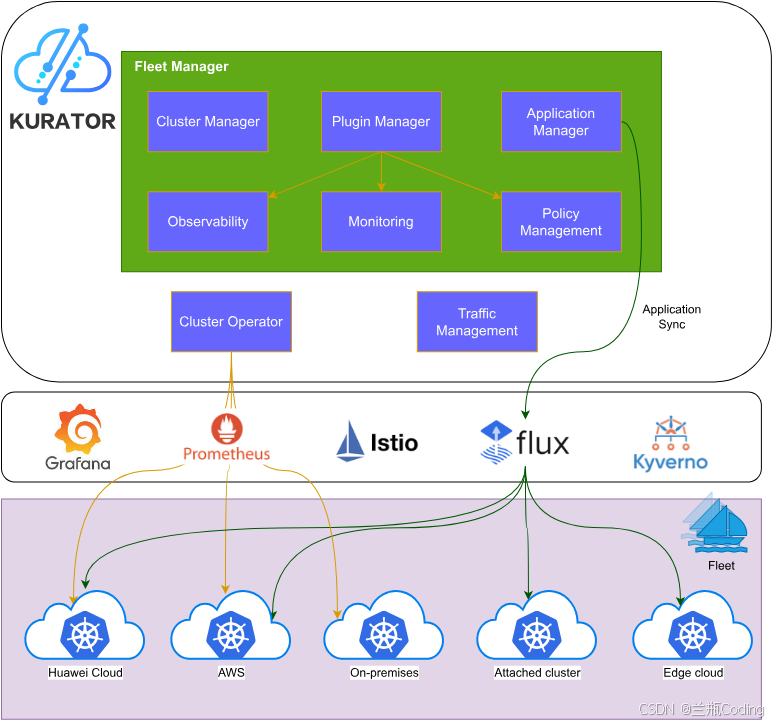
当然,我们可以直观研究下官方所给的Kurator的产品架构图:
四、场景一:把跨集群 SLO 变成“平台内建能力”
4.1 Metric 插件:多集群监控的统一入口
Kurator 的 Metric 插件基于 Prometheus、Thanos 和 Grafana,在 Fleet 维度自动部署和配置多集群监控。([华为开发者][1])
你可以在 Fleet 中这样开启:
apiVersion: fleet.kurator.dev/v1alpha1
kind: Fleet
metadata:
name: checkout-fleet
namespace: kurator-system
spec:
clusters:
- name: cluster-blue
kind: AttachedCluster
- name: cluster-green
kind: AttachedCluster
plugin:
metric:
thanos:
objectStoreConfig:
secretName: thanos-objstore # 存放对象存储配置的 Secret
grafana:
enabled: true
adminUser: admin
adminPasswordSecret: grafana-admin
Fleet Manager 会在两个成员集群自动安装 Prometheus + Thanos Sidecar,并在管理平面部署 Thanos Query 和 Grafana,形成统一指标视图。([华为开发者][1])
4.2 定义跨集群 SLO:以结算接口为例
假设我们的结算服务暴露了以下指标(Prometheus):
checkout_http_requests_total{service="checkout",status=...}checkout_http_request_duration_seconds_bucket{service="checkout"}
我们希望定义一个“全球 SLO”:
- 7 天滚动窗口内,结算请求成功率 ≥ 99.9%
- P95 延迟 < 300ms
在 Thanos 中,可以写出跨集群的错误率 PromQL(按“status_class”聚合):
sum by (status_class) (
rate(checkout_http_requests_total{
service="checkout",
status_class=~"5xx"
}[5m])
)
/
sum(
rate(checkout_http_requests_total{
service="checkout"
}[5m])
)
同理,P95 延迟可以这么算:
histogram_quantile(
0.95,
sum(rate(checkout_http_request_duration_seconds_bucket{
service="checkout"
}[5m])) by (le)
)
如果每个成员集群都给指标打上 cluster label(例如通过 Prometheus external_labels 或 ServiceMonitor),你还可以拆成:
- 全球整体错误率 / 延迟
- 各集群错误率 / 延迟对比
在投稿里,你可以进一步展开:把这些 SLO 写成内部约束、告警规则,甚至构思成 Kurator 上层的一个 SLO CRD,这样“前瞻创想”的味道也会更浓一点。
而且,感兴趣的同学可前往直接克隆代码,体验一波。
五、场景二:用 Rollout 做跨集群金丝雀,避免“一键全网事故”
5.1 单集群 Rolling Update 的局限
在多集群环境中,如果你只是对每个集群做一个简单的 RollingUpdate:
- 一旦版本有严重 bug,很可能在短时间内把所有区域同时打趴;
- 灰度和回滚策略全靠人记,一不小心就“绿区灰度了,蓝区忘了”;
- 很难围绕“用户和流量”来做精细控制,只是在副本上做手脚。
Kurator 的 Rollout 能力,是在 Fleet 维度做统一渐进式发布控制,支持金丝雀、A/B、蓝绿等模式。([Kurator][3])
5.2 一个跨集群金丝雀示例:从 10% 到 100%
假设结算服务在两个集群都有 Deployment:checkout,我们想要:
- 先在
cluster-blue做小流量金丝雀; - 指标达标后,逐步提升 blue 集群流量占比;
- 最后再同步到
cluster-green上;
我们可以在管理平面为 Fleet 创建一个 Rollout 对象(示例结构,仅供参考):
apiVersion: rollout.kurator.dev/v1alpha1
kind: Rollout
metadata:
name: checkout-canary
namespace: kurator-system
spec:
# 需要做渐进式发布的工作负载
workload:
apiVersion: apps/v1
kind: Deployment
name: checkout
# 可选:按集群选择 target
strategy:
canary:
steps:
- name: blue-10
cluster: cluster-blue
weight: 10
pause: 5m
- name: blue-50
cluster: cluster-blue
weight: 50
pause: 10m
- name: blue-100
cluster: cluster-blue
weight: 100
pause: 10m
- name: green-50
cluster: cluster-green
weight: 50
pause: 10m
- name: green-100
cluster: cluster-green
weight: 100
metrics:
- name: global-error-rate
query: |
sum(rate(checkout_http_requests_total{
service="checkout",
status_class=~"5xx"
}[5m]))
/
sum(rate(checkout_http_requests_total{
service="checkout"
}[5m]))
thresholdRange:
max: 0.001
- name: global-p95-latency
query: |
histogram_quantile(
0.95,
sum(rate(checkout_http_request_duration_seconds_bucket{
service="checkout"
}[5m])) by (le)
)
thresholdRange:
max: 0.3
在底层,Rollout 会与 Istio / Nginx Ingress / 服务网格配合,调整 VirtualService 或流量路由的权重。([Kurator][3])
SRE 视角的价值是:
- 发布策略被结构化存进了 CRD,不再藏在脚本和脑子里;
- 每一步金丝雀都有可见的状态和回滚条件,可以纳入值班手册和演练流程;
- 可以在 Fleet 层统一定义“高风险服务必须走金丝雀 + 指标评估”,强制将变更治理制度化。
六、场景三:用统一策略管理,把“人为事故”挡在集群门外
6.1 为什么策略一定要做在 Fleet 层?
多云多集群情况下,如果你在每个集群单独安装 Kyverno/OPA 再分发策略:
-
策略文件重复管理,容易出现版本漂移;
-
安全团队和审计很难得到统一视图:
“到底哪些集群启用了 baseline,哪些还是空门?”
Kurator 的 Policy 插件用 Kyverno 做引擎,通过 Fleet 把策略在多集群范围分发和治理。([华为开发者][1])
6.2 一个“防 CPU 爆表”的统一策略示例
以一个 SRE 常见痛点为例:
某业务研发发布时忘了写资源限制,结果某个 Pod 把 node CPU 干到 100%,邻居服务都跟着抖。
我们可以用一个简单的 Kyverno 策略,强制要求在指定命名空间中的 Pod 必须设置 resources.limits。在 Kurator 的 Fleet CR 中用高阶语义开启,例如:
apiVersion: fleet.kurator.dev/v1alpha1
kind: Fleet
metadata:
name: checkout-fleet
namespace: kurator-system
spec:
clusters:
- name: cluster-blue
kind: AttachedCluster
- name: cluster-green
kind: AttachedCluster
plugin:
policy:
kyverno:
podSecurity:
standard: baseline
severity: high
validationFailureAction: Enforce
# 想象中的扩展字段,可在你们内部实践中自定义
resourcePolicy:
requireLimits:
namespaces:
- checkout-prod
- checkout-canary
在 Kurator 的实现层面,会根据这些高层字段生成 Kyverno 的 Policy/ClusterPolicy 并下发到每个集群。([华为开发者][1])
Kyverno Policy(示例)大致是这样的:
apiVersion: kyverno.io/v1
kind: ClusterPolicy
metadata:
name: require-resources-limits
spec:
validationFailureAction: Enforce
background: true
rules:
- name: check-resources
match:
any:
- resources:
kinds: ["Pod"]
namespaces: ["checkout-prod", "checkout-canary"]
validate:
message: "CPU and memory limits are required."
pattern:
spec:
containers:
- resources:
limits:
cpu: "?*"
memory: "?*"
这样的一层封装带来的收益是:
- 安全/平台团队只需要在 Fleet CR 中调整策略开关;
- 集群侧的 Kyverno 配置对普通业务而言是“透明”的;
- Policy 状态可以在 Fleet 的
status.policy中汇总展示,方便审计。([华为开发者][1])
而且,我们还可以看到开源了很多项目:

七、场景四:用 Fleet + 多集群调度做混合云灾备与容量治理
7.1 “跨集群扩容”和“区域容灾”是稳定性工程的必考题
在高可用设计里,我们经常会做:
- 同城双活 / 两地三中心;
- 不同云厂商之间的“互为灾备”;
- Traffic shifting:当某区域承压时,把部分流量挪到其他集群。
Kurator 自身并不重新实现调度引擎,而是拥抱 Karmada 之类多集群编排项目,并在 Fleet 这层对它们进行组织。([华为开发者][1])
7.2 基于 PropagationPolicy 的“跨集群副本分布”示例
假设我们希望 checkout 这个 Deployment:
- 在
cluster-blue保持 6 副本; - 在
cluster-green保持 3 副本;
可以在 Kurator 管理的 Karmada 控制面创建类似这样的策略(示意):
apiVersion: policy.karmada.io/v1alpha1
kind: PropagationPolicy
metadata:
name: checkout-propagation
namespace: checkout
spec:
resourceSelectors:
- apiVersion: apps/v1
kind: Deployment
name: checkout
placement:
clusterAffinity:
clusterNames:
- cluster-blue
- cluster-green
---
apiVersion: policy.karmada.io/v1alpha1
kind: OverridePolicy
metadata:
name: checkout-replicas
namespace: checkout
spec:
resourceSelectors:
- apiVersion: apps/v1
kind: Deployment
name: checkout
overrideRules:
- targetCluster:
clusterNames: ["cluster-blue"]
overriders:
replicasOverrider:
value: 6
- targetCluster:
clusterNames: ["cluster-green"]
overriders:
replicasOverrider:
value: 3
在流量层面,可以配合 Rollout / 网关权重配置,让“副本数”和“流量比例”匹配或错峰。
进一步的构想是:
- 把容量相关的 desired/actual replicas、节点数、历史 QPS 等指标聚合到 Kurator 的 Metric / SLO 层;
- 提供一个 Fleet 级别的“容量建议”或“自动扩容策略”CRD,根据观测数据调节各集群负载比例。
这些都是基于 Kurator + Karmada 现有能力可以逐步演进出来的稳定性工程玩法。
八、场景五:Pipeline 把“变更路径”标准化,降低人为复杂度
8.1 没有标准变更路径,SRE 就永远在救火
一旦进入多云、多集群阶段,如果各个业务线、各个集群的发布方式五花八门:
- 有用 Jenkins SSH 上去跑脚本的;
- 有直接在 IDE 里连 kubeconfig apply 的;
- 有一半在用 Helm,但 values 各不相同;
变更审核和风险控制就会非常困难。
Kurator 在 v0.6.0 开始引入 Pipeline 能力,基于 Tekton 做封装,并整合 Tekton Chains 做供应链安全。([GitHub][2])
8.2 一个“结算服务标准流水线”示例
下面是一条典型的流水线示例(简化),从代码到镜像,再到签名与 GitOps 更新:
apiVersion: pipeline.kurator.dev/v1alpha1
kind: Pipeline
metadata:
name: checkout-ci
namespace: cicd
spec:
repo:
url: https://git.example.com/checkout.git
revision: main
tasks:
- name: clone
template: git-clone # 预置模板
- name: unit-test
template: go-test
runAfter: ["clone"]
- name: lint
template: go-lint
runAfter: ["clone"]
- name: build-image
template: build-and-push-image
runAfter: ["unit-test", "lint"]
params:
- name: image
value: registry.example.com/checkout:$(revision)
- name: update-manifest
customTask:
image: alpine:3.18
command: ["/bin/sh", "-c"]
args:
- |
# 用 yq / sed 更新 Application 仓库中的镜像 tag
echo "patching gitops repo..."
- name: sign-image
template: cosign-sign
runAfter: ["build-image"]
params:
- name: image
value: registry.example.com/checkout:$(revision)
chainSecurity:
enabled: true
attestation:
type: in-toto
store:
type: oci
url: registry.example.com/attestations
在 SRE 的日常实践中,可以定义一些准则:
- 所有生产发布必须基于 Pipeline 执行,禁止“跳过流水线直发”;
- 只有
chainSecurity状态为成功的版本才允许进入 Rollout 阶段; - 结合 Policy 插件,对未签名/未扫描的镜像在 Admission 阶段直接拒绝。
这样,稳定性不再只是“上了 Prometheus”和“配置了告警”,而是从变更入口就开始管理风险。
九、一次虚构但真实感很强的“跨集群重大故障演练”复盘
这一节你可以替换成你们自己的故障演练或真实事故复盘,我先用一个虚构但常见的案例说明一下 Kurator 在其中能扮演什么角色。
9.1 事件背景
-
业务:结算服务
checkout,部署在cluster-blue和cluster-green两个集群; -
SLO:7 天成功率 ≥ 99.9%,P95 < 300ms;
-
架构:
- Kurator 管理两个集群,定义了
checkout-fleet; - 开启了 Metric 插件和 Policy 插件;
- 发布流程走 Kurator Pipeline + Rollout 金丝雀;
- Kurator 管理两个集群,定义了
9.2 演练目标
-
模拟
cluster-blue节点网络抖动导致错误率飙升; -
验证:
- 跨集群 SLO 告警是否触发及时;
- 是否能在控制平面快速看出“哪个集群异常”;
- 是否能通过 Rollout/流量迁移机制控制影响面。
9.3 演练过程(简化版)
-
注入故障
- 在
cluster-blue注入网络 delay 或丢包(可用tc或 chaos 工具); - 结算服务在该集群的错误率开始上升,延迟变大。
- 在
-
监控层响应
- Thanos 聚合指标后,
global-error-rate指标开始超阈值; - 按 SLO 告警策略,触发“全球结算错误率超阈”告警;
- 在 Grafana 面板上,一眼能看到
cluster-blue的局部错误率远高于cluster-green。
- Thanos 聚合指标后,
-
控制面决策
- 值班 SRE 在 Kurator 管理界面里查看
checkout-fleet的状态,以及关联的 Application / Rollout; - 通过 Rollout 或网关权重配置,将更多流量导向
cluster-green,同时限制cluster-blue的 QPS; - 如果必要,可在 Karmada 维度增开
cluster-green的副本数。
- 值班 SRE 在 Kurator 管理界面里查看
-
策略层保障
- 因为 Policy 插件已经统一开启了资源配额和 Pod 安全策略,即便某个业务方误操作部署异常,也不会进一步放大故障面。
-
复盘与改进
-
演练结束后,复盘 Timeline:
- 告警触发时间、SRE 感知时间、控制面操作时间;
- Kurator Fleet 视图是否足够清晰地呈现“业务视角的健康状态”;
- 是否需要在 Fleet 上增加更高层次的 SLO CRD 或事件流。
-
在这样一个演练故事里,Kurator 不只是“一个多集群管理工具”,而是承载了:
- 指标和 SLO 的汇聚点;
- 变更策略和发布控制的执行器;
- 策略和安全基线的统一入口;
- 演练与复盘中“可观可控”的平台载体。
十、总结:Kurator 把 SRE 的很多“术”,沉淀成了“平台的道”
站在 SRE 的角度,我会这样给 Kurator 下一个“稳定性工程”的总结:
-
统一观测和 SLO
- Metric 插件 + Prometheus + Thanos,让“跨集群 SLO”成为一种可落地的实践,而不是 PPT 概念。
-
可控可审的发布
- Application/GitOps + Rollout,把“如何发布”变成写在 CRD 里的显式策略;
- 灰度、回滚逻辑都能在平台层被检查、被演练。
-
防线前移的策略治理
- Policy 插件 + Kyverno 让 Pod 安全、资源配额、镜像来源等变成“Fleet 级别默认规则”;
- 多云、多集群下把“人祸”拦在门外。
-
标准化的变更路径
- Pipeline 封装 Tekton 和供应链安全,让“从代码到上线”的链路在平台层可见、可控。
-
面向灾备与容量的拓扑抽象
- Fleet / AttachedCluster / 多集群调度,为混合云灾备和动态扩容提供了天然的组织单元。
…
(未完待续)

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 21
21 0
0- 0



 已为社区贡献19条内容
已为社区贡献19条内容

所有评论(0)