
Spark开发_缺少Hadoop的可执行文件winutils.exe java.io.IOException: Could not locate executable null\bin\winuti
scala版本与spark版本不匹配
错误代码:
Exception in thread "main" java.lang.NoSuchMethodError: scala.Product.$init$(Lscala/Product;)V
at org.apache.spark.SparkConf$DeprecatedConfig.<init>(SparkConf.scala:799)
at org.apache.spark.SparkConf$.<init>(SparkConf.scala:596)
at org.apache.spark.SparkConf$.<clinit>(SparkConf.scala)
at org.apache.spark.SparkConf.set(SparkConf.scala:94)
at org.apache.spark.SparkConf.set(SparkConf.scala:83)
at org.apache.spark.SparkConf.setAppName(SparkConf.scala:120)
at WordCount$.main(WordCount.scala:6)
at WordCount.main(WordCount.scala)
Process finished with exit code 1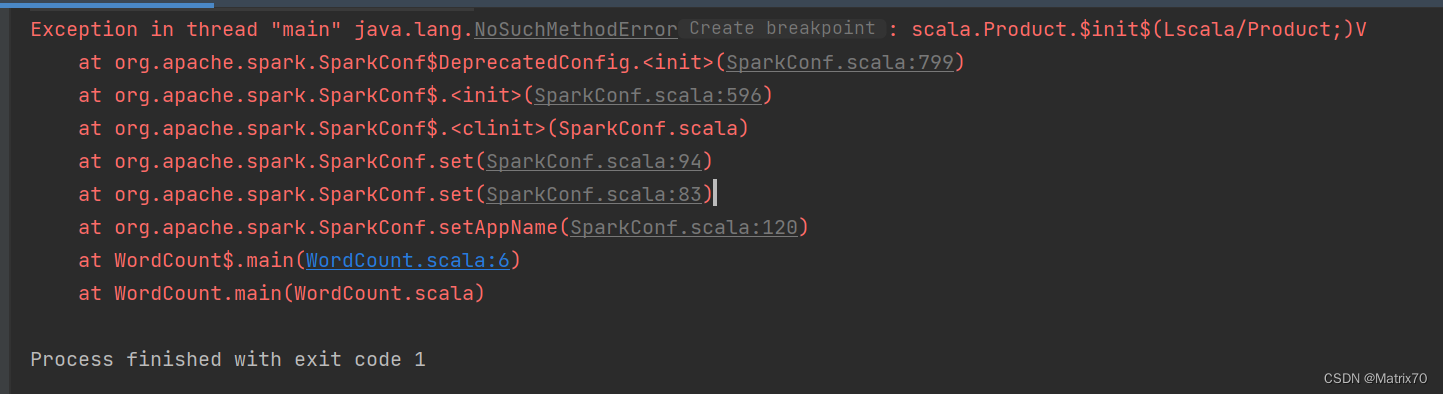
失败原因
由于scala版本与Spark版本不一致引起的编译失败。
我是用的是scala2.11.8,Spark3.2.0版本的,是不匹配的。Spark 3.2.0需要 Scala 2.12+,需要将项目编译为 Scala 2.12+ 才能使用 Spark 3.2.0。否则,需要使用 Spark 3.1.x 的版本和 Scala 2.11.x 的版本。
版本
Spark
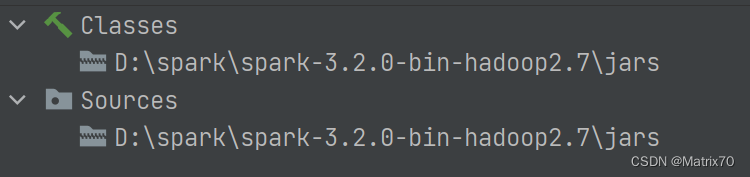
scala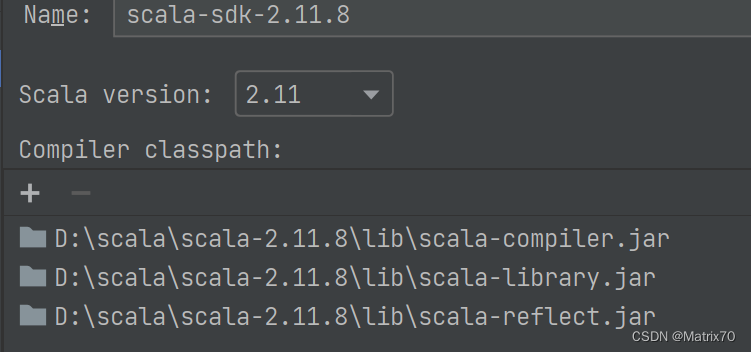
解决办法:
把scala版本升上去。
缺少Hadoop的可执行文件winutils.exe
java.io.IOException: Could not locate executable null\bin\winutils.exe in the Hadoop binaries.
-
确保已正确设置Hadoop的环境变量,并重新启动终端。
-
下载并安装Hadoop的二进制文件,并将其解压缩到正确的目录中(例如,C:/Hadoop/)。
-
从Apache官网上下载winutils.exe文件,并将其复制到Hadoop的bin目录中。
文件路径写成了文件
Exception in thread "main" org.apache.hadoop.mapred.InvalidInputException: Input path does not exist: file:/D:/workspace/spark/src/main/Data/data1.txt

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐


 1
1 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)