
Llama3的传奇新篇章:手搓Llama3-12B-Chinese,Ollama部署简单高效_网友手搓llama3-12b-chinese
前段时间有一个号称是「Llama3-120b」的神秘大模型火了起来,原因在于它表现太过出色了,可以轻松击败GPT-4、gpt2-chatbot。但实际上Llama 3首发阵容里并没有120B的模型。
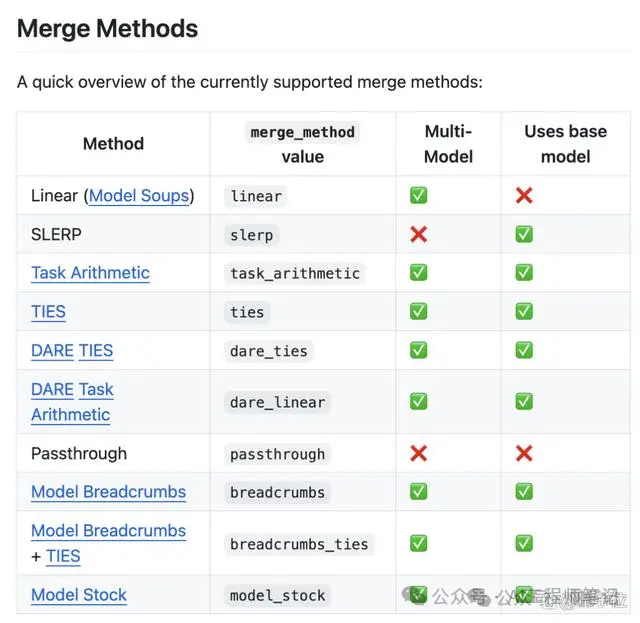
经过网友的深扒,发现其竟然是使用MergeKit制作,将Meta官方LIama3 70B模型合并(Self-Merge)。
MergeKit是专门用来合并预训练模型的工具包,合并可以完全在 CPU 上运行,也可以使用低至8GB的VRAM进行加速。在GitHub上已经收获3.6k星。
目前支持Llama、Mistral、GPT-NeoX、StableLM 等模型。

①人工智能/大模型学习路线
②AI产品经理入门指南
③大模型方向必读书籍PDF版
④超详细海量大模型实战项目
⑤LLM大模型系统学习教程
⑥640套-AI大模型报告合集
⑦从0-1入门大模型教程视频
⑧AGI大模型技术公开课名额
Llama3-12B
基于这个缝合大模型的思路,网友又陆续发布了Llama3-12B,其中还包括了中文微调的12B模型。

信息显示,wwe180/Llama3-12B-Chinese-lingyang是使用mergekit创建的预训练语言模型的合并得到。该模型以hfl/llama-3-chinese-8b-instruct-v2为基础,采用直通合并方法进行合并。
合并的YAML配置如下:
slices:
- sources:
- model: "hfl/llama-3-chinese-8b-instruct-v2"
layer_range: [0, 10]
- sources:
- model: "hfl/llama-3-chinese-8b-instruct-v2"
layer_range: [7, 17]
- sources:
- model: "hfl/llama-3-chinese-8b-instruct-v2"
layer_range: [13, 23]
- sources:
- model: "hfl/llama-3-chinese-8b-instruct-v2"
layer_range: [18, 28]
- sources:
- model: "hfl/llama-3-chinese-8b-instruct-v2"
layer_range: [22, 32]
merge_method: passthrough
base_model: "hfl/llama-3-chinese-8b-instruct-v2"
dtype: bfloat16
此外,网友还开源了GGUF模型,这样我们就可以使用ollama进行部署了。
使用ollama部署
1、下载llama3-13b-chinese-lingyang.Q6_K.gguf模型。
下载地址:
https://huggingface.co/wwe180/Llama3-12B-Chinese-lingyang-Q6_K-GGUF
2、创建一个名为 Modelfile 的文件,并使用 FROM 指令,填写的模型的本地文件路径和必要的配置。
FROM ./llama3-13b-chinese-lingyang.Q6_K.gguf
TEMPLATE """
{{ if .System }}<|start_header_id|>system<|end_header_id|>
{{ .System }}<|eot_id|>{{ end }}{{ if .Prompt }}<|start_header_id|>user<|end_header_id|>
{{ .Prompt }}<|eot_id|>{{ end }}<|start_header_id|>assistant<|end_header_id|>
{{ .Response }}<|eot_id|>
"""
PARAMETER stop "<|start_header_id|>"
PARAMETER stop "<|end_header_id|>"
PARAMETER stop "<|eot_id|>"
3、执行ollama create llama3:12b -f Modelfile,在Ollama中创建模型

4、执行ollama list验证是否创建成功

大家可以自己实际去试一下效果。
读者福利:如果大家对大模型感兴趣,这套大模型学习资料一定对你有用
对于0基础小白入门:
如果你是零基础小白,想快速入门大模型是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以根据这些资料规划好学习计划和方向。
包括:大模型学习线路汇总、学习阶段,大模型实战案例,大模型学习视频,人工智能、机器学习、大模型书籍PDF。带你从零基础系统性的学好大模型!
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓

👉AI大模型学习路线汇总👈
大模型学习路线图,整体分为7个大的阶段:(全套教程文末领取哈)

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
👉大模型实战案例👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

👉大模型视频和PDF合集👈
观看零基础学习书籍和视频,看书籍和视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。


👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐



 18
18 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容









{kind=link}
所有评论(0)