

YOLOv9添加HWD_Down,替换ADown实现有效涨点
yolov9
YOLOv9是前沿的对象检测框架,它通过利用可编程梯度信息实现高效学习,带来显著的性能提升。这个开源项目在MS COCO数据集上展示出卓越的准确性与速度平衡,模型大小从轻量级到大型不等,满足不同场景需求。例如,YOLOv9-C在保持紧凑的参数量(25.3M)下,实现了53.0%的高平均精度。开发者不仅能够享受到即刻部署的乐趣,还能通过丰富的社区资源进行模型转换、加速推理和多任务学习,支持如TensorRT、ONNX、OpenVINO等技术,以及在ROS中的集成应用。无论是深入研究还是实际项目应用,YOLOv9都是一个强大且灵活的选择,为计算机视觉领域的爱好者和专业人士提供了一个高性能的工具包。【此简介由AI生成】
项目地址:https://gitcode.com/gh_mirrors/yo/yolov9
·
声明:不讲原理、只说改进、只看效果
一、HWD_Down代码
class HWD_ADown(nn.Module):
def __init__(self, c1, c2): # ch_in, ch_out, shortcut, kernels, groups, expand
super().__init__()
# c1 = c1.float()
# c2 = c2.floats()
self.c = c2 // 2
# self.cv1 = Conv(c1 // 2, self.c, 3, 2, 1)
self.cv1 = HWD(c1 // 2, self.c, 3, 1, 1)
self.cv2 = Conv(c1 // 2, self.c, 1, 1, 0)
def forward(self, x):
x = x.float() # 将输入数据转换为float类型
x = nn.functional.avg_pool2d(x, 2, 1, 0, False, True)
x1, x2 = x.chunk(2, 1)
x1 = self.cv1(x1)
x2 = torch.nn.functional.max_pool2d(x2, 3, 2, 1)
x2 = self.cv2(x2)
return torch.cat((x1, x2), 1)
class HWD(nn.Module):
def __init__(self, in_ch, out_ch, k, s, p):
super(HWD, self).__init__()
from pytorch_wavelets import DWTForward
self.wt = DWTForward(J=1, mode='zero', wave='haar')
self.conv = Conv(in_ch * 4, out_ch, k, s, p)
# self.conv = Conv(in_ch * 4, out_ch, k, s, p, bias=False, dtype=torch.half) # 假设Conv类支持dtype参数
def forward(self, x):
# x = x.float() # 将输入数据转换为float类型
yL, yH = self.wt(x.float())
y_HL = yH[0][:, :, 0, ::]
y_LH = yH[0][:, :, 1, ::]
y_HH = yH[0][:, :, 2, ::]
x = torch.cat([yL, y_HL, y_LH, y_HH], dim=1)
x = self.conv(x)
return x
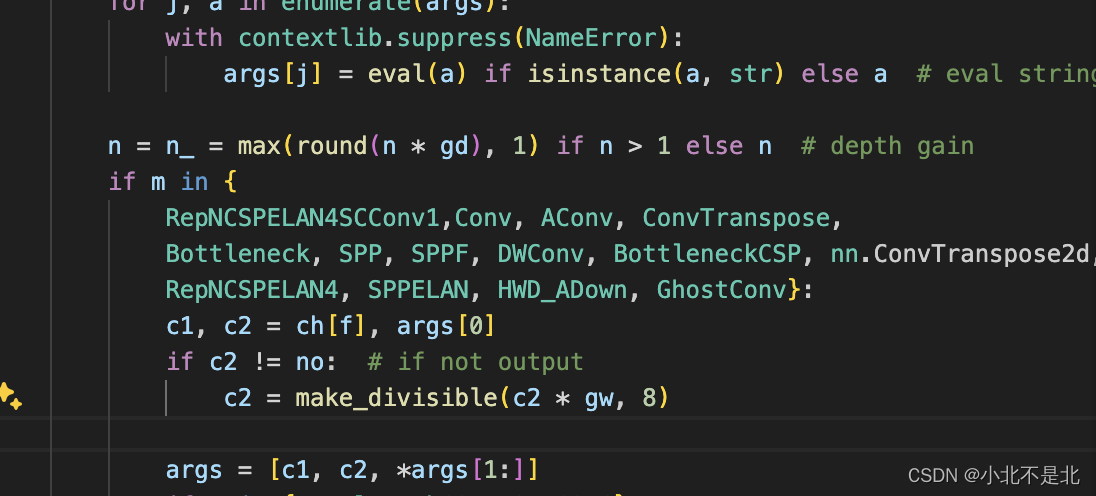
二、插入位置
直接替换原有ADown位置即可,在yolo.py文件中替换为见下图:
yolov9
YOLOv9是前沿的对象检测框架,它通过利用可编程梯度信息实现高效学习,带来显著的性能提升。这个开源项目在MS COCO数据集上展示出卓越的准确性与速度平衡,模型大小从轻量级到大型不等,满足不同场景需求。例如,YOLOv9-C在保持紧凑的参数量(25.3M)下,实现了53.0%的高平均精度。开发者不仅能够享受到即刻部署的乐趣,还能通过丰富的社区资源进行模型转换、加速推理和多任务学习,支持如TensorRT、ONNX、OpenVINO等技术,以及在ROS中的集成应用。无论是深入研究还是实际项目应用,YOLOv9都是一个强大且灵活的选择,为计算机视觉领域的爱好者和专业人士提供了一个高性能的工具包。【此简介由AI生成】
项目地址:https://gitcode.com/gh_mirrors/yo/yolov9
看上下文代码直接换。
三、yaml文件示例
# YOLOv9
# parameters
nc: 80 # number of classes
depth_multiple: 1.0 # model depth multiple
width_multiple: 1.0 # layer channel multiple
#activation: nn.LeakyReLU(0.1)
#activation: nn.ReLU()
# anchors
anchors: 3
# YOLOv9 backbone
backbone:
[
[-1, 1, Silence, []],
# conv down
[-1, 1, Conv, [64, 3, 2]], # 1-P1/2
# conv down
[-1, 1, Conv, [128, 3, 2]], # 2-P2/4
# elan-1 block
[-1, 1, RepNCSPELAN4, [256, 128, 64, 1]], # 3
# avg-conv down
[-1, 1, HWD_ADown, [256]], # 4-P3/8
# elan-2 block
[-1, 1, RepNCSPELAN4, [512, 256, 128, 1]], # 5
# avg-conv down
[-1, 1, HWD_ADown, [512]], # 6-P4/16
# elan-2 block
[-1, 1, RepNCSPELAN4, [512, 512, 256, 1]], # 7
# avg-conv down
[-1, 1, HWD_ADown, [512]], # 8-P5/32
# elan-2 block
[-1, 1, RepNCSPELAN4, [512, 512, 256, 1]], # 9
]
# YOLOv9 head
head:
[
# elan-spp block
[-1, 1, SPPELAN, [512, 256]], # 10
# up-concat merge
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 7], 1, Concat, [1]], # cat backbone P4
# elan-2 block
[-1, 1, RepNCSPELAN4, [512, 512, 256, 1]], # 13
# up-concat merge
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 5], 1, Concat, [1]], # cat backbone P3
# elan-2 block
[-1, 1, RepNCSPELAN4, [256, 256, 128, 1]], # 16 (P3/8-small)
# avg-conv-down merge
[-1, 1, HWD_ADown, [256]],
[[-1, 13], 1, Concat, [1]], # cat head P4
# elan-2 block
[-1, 1, RepNCSPELAN4, [512, 512, 256, 1]], # 19 (P4/16-medium)
# avg-conv-down merge
[-1, 1, HWD_ADown, [512]],
[[-1, 10], 1, Concat, [1]], # cat head P5
# elan-2 block
[-1, 1, RepNCSPELAN4, [512, 512, 256, 1]], # 22 (P5/32-large)
# multi-level reversible auxiliary branch
# routing
[5, 1, CBLinear, [[256]]], # 23
[7, 1, CBLinear, [[256, 512]]], # 24
[9, 1, CBLinear, [[256, 512, 512]]], # 25
# conv down
[0, 1, Conv, [64, 3, 2]], # 26-P1/2
# conv down
[-1, 1, Conv, [128, 3, 2]], # 27-P2/4
# elan-1 block
[-1, 1, RepNCSPELAN4, [256, 128, 64, 1]], # 28
# avg-conv down fuse
[-1, 1, HWD_ADown, [256]], # 29-P3/8
[[23, 24, 25, -1], 1, CBFuse, [[0, 0, 0]]], # 30
# elan-2 block
[-1, 1, RepNCSPELAN4, [512, 256, 128, 1]], # 31
# avg-conv down fuse
[-1, 1, HWD_ADown, [512]], # 32-P4/16
[[24, 25, -1], 1, CBFuse, [[1, 1]]], # 33
# elan-2 block
[-1, 1, RepNCSPELAN4, [512, 512, 256, 1]], # 34
# avg-conv down fuse
[-1, 1, HWD_ADown, [512]], # 35-P5/32
[[25, -1], 1, CBFuse, [[2]]], # 36
# elan-2 block
[-1, 1, RepNCSPELAN4, [512, 512, 256, 1]], # 37
# detection head
# detect
[[31, 34, 37, 16, 19, 22], 1, DualDDetect, [nc]], # DualDDetect(A3, A4, A5, P3, P4, P5)
]
四、运行成功截图
重新跑太麻烦,直接粘贴中间;在运行之前需关闭混合精度训练;不多做赘述。

推荐内容
阅读全文
AI总结
YOLOv9是前沿的对象检测框架,它通过利用可编程梯度信息实现高效学习,带来显著的性能提升。这个开源项目在MS COCO数据集上展示出卓越的准确性与速度平衡,模型大小从轻量级到大型不等,满足不同场景需求。例如,YOLOv9-C在保持紧凑的参数量(25.3M)下,实现了53.0%的高平均精度。开发者不仅能够享受到即刻部署的乐趣,还能通过丰富的社区资源进行模型转换、加速推理和多任务学习,支持如TensorRT、ONNX、OpenVINO等技术,以及在ROS中的集成应用。无论是深入研究还是实际项目应用,YOLOv9都是一个强大且灵活的选择,为计算机视觉领域的爱好者和专业人士提供了一个高性能的工具包。【此简介由AI生成】
最近提交(Master分支:21 天前 )
5b1ea9a8 - 9 个月前
0bf4f52b - 9 个月前

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐



 11
11 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容
相关推荐
查看更多
yolov9
yolov9
yolov5
yolov5 - Ultralytics YOLOv8的前身,是一个用于目标检测、图像分割和图像分类任务的先进模型。
热门开源项目
运营活动

活动日历
查看更多
直播时间 2025-04-09 14:34:18


樱花限定季|G-Star校园行&华中师范大学专场

直播时间 2025-04-07 14:51:20

樱花限定季|G-Star校园行&华中农业大学专场
直播时间 2025-03-26 14:30:09

开源工业物联实战!
直播时间 2025-03-25 14:30:17

Heygem.ai数字人超4000颗星火燎原!
直播时间 2025-03-13 18:32:35

全栈自研企业级AI平台:Java核心技术×私有化部署实战

所有评论(0)