一文详看大模型长文本如何评估:四大主流评测数据集的任务设计、数据集构建方案
大语言模型(LLM)尽管在各种语言任务中表现抢眼,但通常仅限于处理上下文窗口大小范围内的文本。
有越来越多的基准被提出来测试LLM的长文本理解能力。
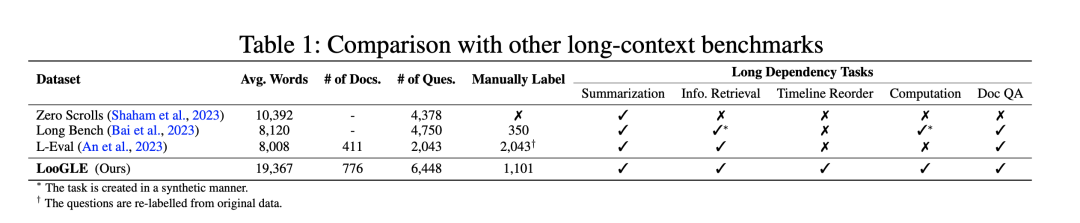
当前具有代表性的长文本评测主要包括Zero-SCROLLS、L-Eval、LongBench以及loogle四个基准。
本文对这个几个数据集进行梳理,供大家一起参考,包括任务的设计、任务数据集的构造方案,这些都很有借鉴性。
一、ZeroSCROLLS评测数据集
ZeroSCROLLS将不同来源的数据集自动处理成平均10k词的统一输入格式。
地址:https://arxiv.org/pdf/2305.14196.pdf
ZeroSCROLLS作为一个零测试基准,包含十个自然语言任务的测试集,每个任务都要求对不同类型的长文本进行推理,每个任务最多只能使用500个示例。
其中:
六个数据集是该工作根据Shaham等人的研究成果改编的,另外四个是新任务。
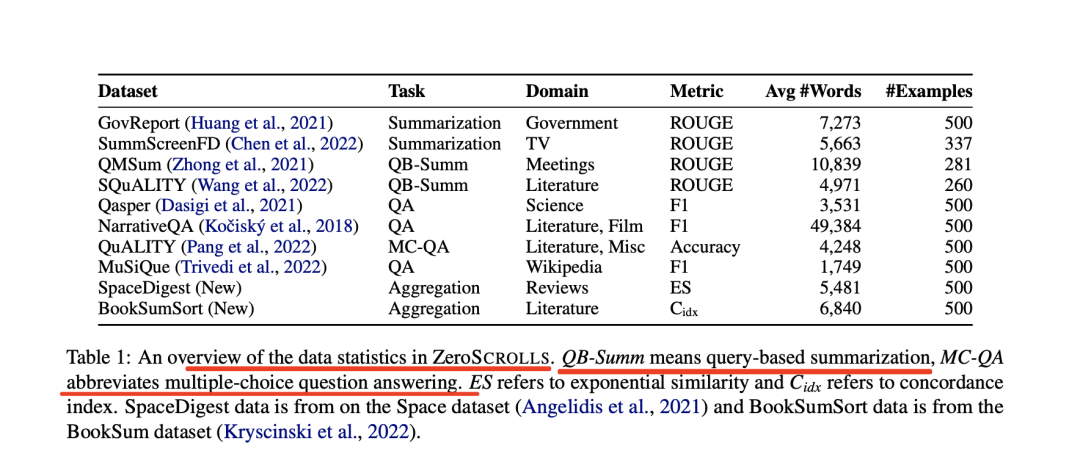
1、Summarization摘要任务
该工作采用了SCROLLS中的三个摘要数据集(GovReport、SummScreenFD和QM-Sum),并增加了第四个数据集(SQuALITY)。
GovReport和SummScreenFD是全文档摘要任务,而QMSum和SQuALITY则以查询为重点。
其中:
GovReport:包含国会研究服务处和美国政府问责办公室的长篇报告及其专家书面摘要。
SummScreenFD:包含从维基百科和TVMaze收集的电视节目集脚本及其摘要。
QMSum:一个基于查询的会议记录摘要数据集。该数据集包含学术会议、工业产品会议以及威尔士和加拿大议会的会议记录。除了会议笔录,每个实例还包含一个查询,目的是将摘要集中在特定主题上。
SQuALITY:一个以问题为中心的摘要数据集,给定古腾堡计划中的一个故事,任务是根据一个指导性问题生成该故事或其某些方面的摘要。
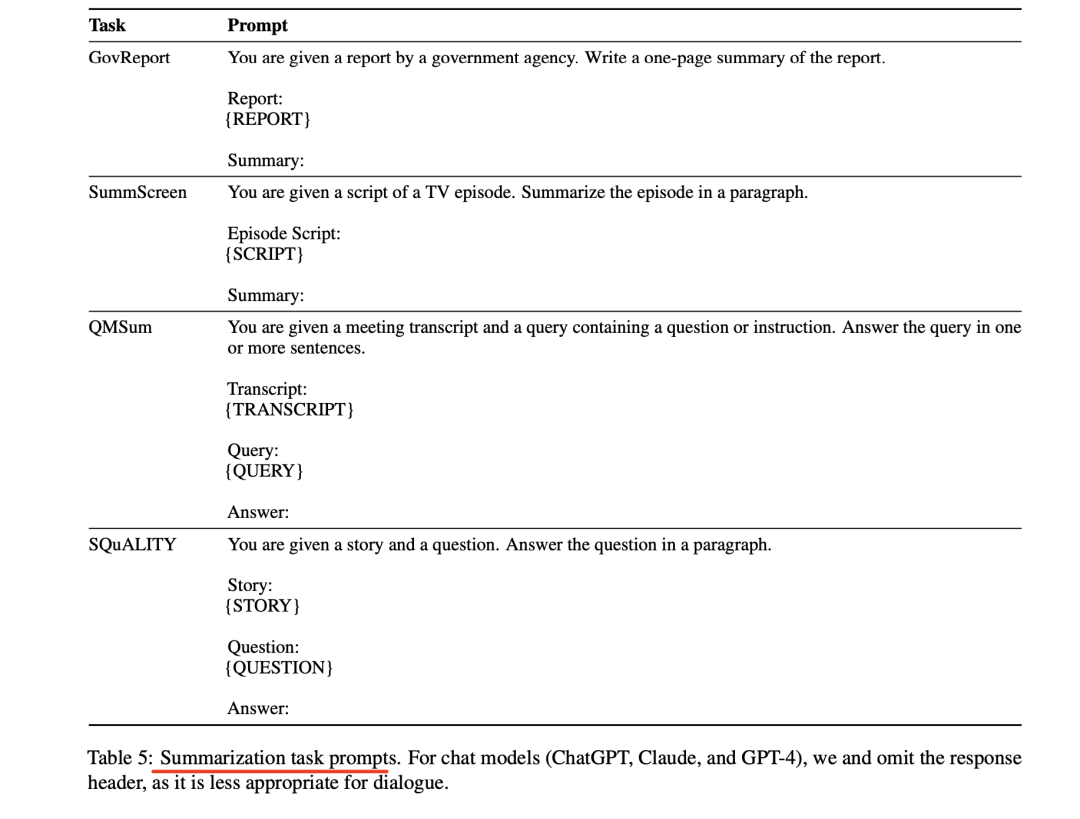
摘要任务对应的prompt如下:
2、Question Answering
该工作采用了SCROLLS的三个问题解答数据集(Qasper、NarrativeQA和QuAL-ITY),并增加了MuSiQue,该数据集侧重于多跳问答。
其中:
Qasper:包含来自语义学者开放研究语料库(S2ORC)的NLP论文。NLP从业人员根据摘要提出问题,另一组从业人员根据文章内容进行回答。
NarrativeQA:包含对古腾堡计划(ProjectGutenberg)中的书籍和各种网站中的电影剧本的提问和回答。为了创建问题和答案,标注人员者从维基百科中获得了书籍和电影的摘要。 每个问题由一个或多个标注人员回答。
QuALITY:包含来自古腾堡计划、开放美国国家语料库等的故事和文章。每篇文章都包含一个故事和一个选择题;问题编写者在指导下编写需要阅读故事的大部分内容才能正确作答的问题。
MuSiQue:一个多跳问题解答数据集,输入是20个维基百科段落和一个需要在不同段落之间进行多次跳转的问题。在原始数据集中,每个问题都有一个无法回答的孪生问题,即正确答案不存在于段落中。该工作为ZeroSCROLLS随机抽取了100个无法回答的问题和400个可以回答的问题。
3、Aggregation
该工作创建了两个新任务,从结构上看,这两个任务要求对输入信息的不同部分进行上下文关联和信息聚合。其中:
SpaceDigest:一项新的情感聚合任务。给定Space数据集中的50条酒店评论(不含评分),任务是确定正面评论的百分比。
该工作从原始数据集中评分最高的500家酒店中为每家酒店创建一个示例(50条评论),只保留严格意义上的正面评论(评分为5分或4分)或负面评论(评分为2分或1分),剔除评分为3分的矛盾评论。
为了验证人类是否能很好地完成这项任务,该工作给5名标注人员提供了一个缩略版的示例(每个示例包含10条评论),并要求他们写出正面评论的百分比。
每位标注人员需要分配到10个示例(每位注释者100条评论,总计500条)。
BookSumSort:一项基于Book-Sum数据集的新任务,该数据集包含各种来源的小说、戏剧和长诗的章节(或部分)摘要。
给定一个章节摘要的列表,任务是根据BookSum中摘要的原始顺序对其重新排序。该工作通过人工从BookSum中选择125本书的摘要来创建任务,只保留高质量的实例。该工作对每篇摘要进行人工编辑,删除引言、序言、概述等内容,以及任何其他可能表明摘要确切位置的信息;
例如,"第8章以简描述......开始"被替换为"本章以简描述......开始","随着戏剧的开场,希波吕托斯宣布......"被替换为"希波吕托斯宣布......"。每个摘要列表包含3至86个章节的摘要,中位数为15个,平均每个实例包含18.8个章节。
该工作从每个列表中随机选择4种排列方式,创建500个实例。
对应的prompt如下:

二、L-Eval评测数据集
L-Eval(L-EVAL: INSTITUTING STANDARDIZED EVALUATION FOR LONG CONTEXT LANGUAGE MODELS)从规模较小的类似公共数据集中重新标注数据和指令,以确保质量。此外,它还优化了评估程序和基线,以获得更准确的结论。
地址:https://arxiv.org/pdf/2307.11088.pdf
表1列出了L-Eval的统计数据
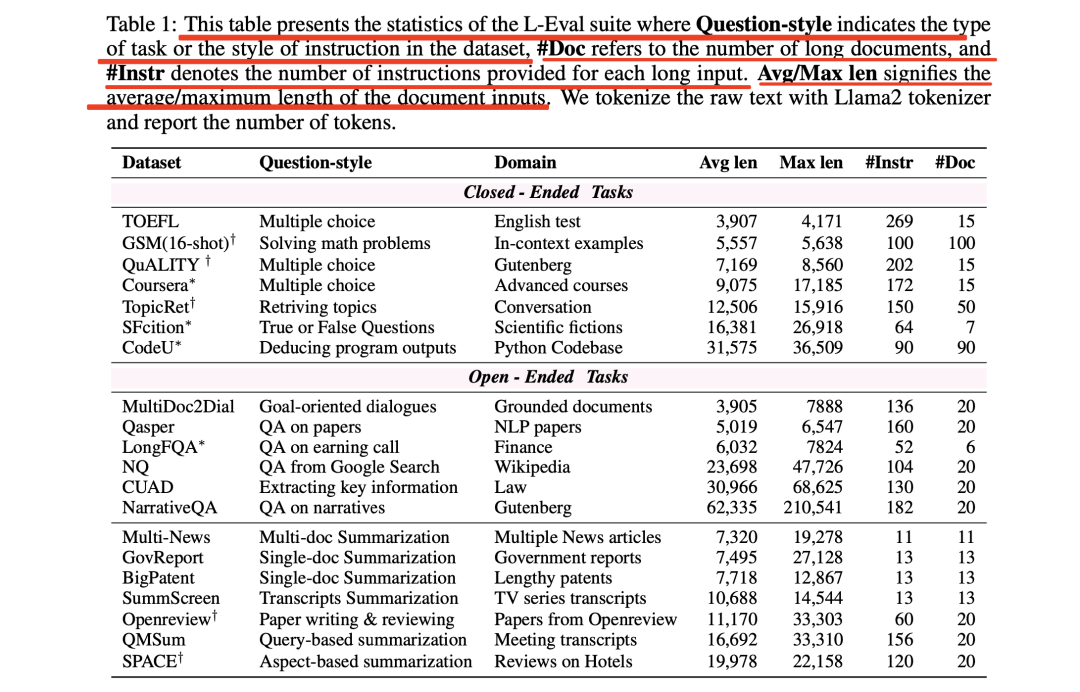
L-Eval包含多种题型,如:
选择题(TOFEL、QuALITY、Coursera)
真假题(SFiction)
数学题(GSM)
代码理解(CodeU)
目标导向对话(Multi-Doc2Dial)
提取式QA(CUAD、NQ)
摘要性QA(LongFQA、NarrativeQA、Qasper)
单篇文档摘要(GovReport、BigPatent、SummScreen、SummScreen、QMSum)
多文档摘要(Multi-News、SPACE)
研究写作(Openre-view)
在数据分布方面,L-Eval中的长文档涉及法律、金融、学术论文、讲座、长篇对话、新闻、著名Python代码库、长篇小说和会议等多个领域。
在长度方面,L-Eval的平均输入长度从4k到60k不等,最大样本包含近20万个token。这种多样性代表了现实世界中不同任务可能需要不同长度的上下文和指令的情况,不同任务的引用长度也有很大差异。
1、从零开始的数据标注
L-Eval共有4个从头标注的数据集:Coursera、SFcition、CodeU和LongFQA。
原始资源分别是来自Coursera的视频、以前的开源数据集、著名Python库的源代码以及公开的通话记录。
为了降低标注的难度,该工作选择了四门与大数据和机器学习相关的公开课程。输入的长文档是视频的字幕。问题和真实答案由作者标注。Coursera的教学方式是选择题。为了增加任务的难度,该工作设置了多个正确选项。
CodeU是代码理解数据集,要求LLM推断冗长Python程序的输出。该工作主要使用Numpy的源代码,并构建了一个字符串处理代码库。
为了防止LLM根据其参数知识回答问题,该工作替换了原始函数名。LLM应首先找到函数被调用的位置,并确定调用了哪些函数。
LongFQA该工作还注意到,金融领域缺乏长语境问题解答数据集,因此该工作根据6家公司网站投资者关系部分的公开盈利电话记录来标注QA对。
2、从公共数据集重新标注数据
该工作在L-Eval中对5个公开数据集进行了重新标注。
其中:
GSM(16-shot)源自GSM8k数据集。考虑到如果LCLM在较长的语境中仍能保持其推理能力,那么使用更多高质量的示例将对数学问题的解决产生积极影响。该工作用较长的"思维链"(Chain-of-Thought)构建了16个上下文示例,其中8个示例来自"思维链"集线器(Chain-of-Thought-hub),8个示例由该工作自己构建。
在QuALITY中注入了新的合成指令来测试全局上下文建模,例如"该工作能从这个故事中最长的句子中推断出什么?"和"故事中有多少个单词?
Openreview数据集包含从openreview.net收集的论文。该工作要求模型撰写摘要部分,总结相关工作,最后给出反馈,包括给作者的宝贵建议和一些问题。
3、数据过滤与校正
剩下的12个任务来源于现有数据集。然而,L-Eval在数据收集后需要更多的人力,因为该工作发现以前的长序列数据集的标注质量波动很大,有很多无法回答的问题与上下文无关。这些错误很难通过以往工作中的自动预处理脚本来纠正。
在L-Eval中,所有样本都是在数据收集后手动过滤和校正。具体地,该工作使用Claude-100k作为助手来过滤错误的QA和无法回答的问题。
首先,该工作将冗长的文档输入Claude,并要求它提供答案和解释。如果clsude给出的答案与基本事实严重不符,或者说该工作无法从上下文中推断出答案,就会对其进行重新标注或直接删除。
三、LongBench评测数据集
LongBench《LongBench: A Bilingual, Multitask Benchmark for Long Context Understanding》提供了一个双语和多任务数据集,具有不同长度、分布、模式、语言和领域的各种序列,用于全面评估长语境理解能力。
地址:https://arxiv.org/abs/2308.14508
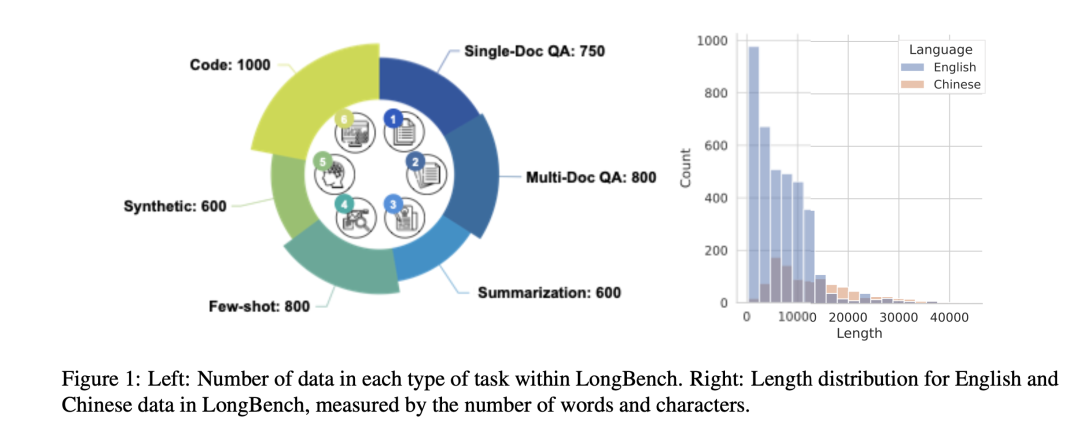
1、Single-Doc QA单文档问答
对于单文档QA,该工作主要关注具有较长文档的实例。包括:NarrativeQA,该数据集由长故事和测试阅读理解能力的问题组成。该工作还从Qasper中采样,该数据集的特点是对NLP论文进行QA,并由NLP从业人员进行标注。
为了更好地测试模型在不同领域的长语境理解能力,该工作手工整理了中英文的MultiFieldQA数据集。
具体地,首先从多个来源收集文件和文章,包括法律文件、政府报告、百科全书、学术论文等。该工作邀请了三位博士生为每篇文章的问题和答案进行标注,为了便于自动评估,标注时尽量给出明确的答案。
在注释过程中,该工作确保答案可以从文件中推断出来,而且证据的位置是相当随机的,以避免出现偏差,例如,如果与答案相关的语句经常出现在开头或结尾。
2、Multi-Doc QA多文档问答
多文档问答要求模型从多个文档中提取和组合信息以获得答案,这通常比单文档问答更具挑战性。
英语测试样本来自三个基于维基百科的多跳QA数据集:HotpotQA、2WikiMultihopQA和MuSiQue。
HotpotQA涉及一些由母语人士直接撰写的2-hop问题,给出两个相关的段落。
2WikiMultihopQA包含多达5跳的问题,这些问题是通过人工设计的模板合成的,以确保这些问题无法通过捷径解决。
MuSiQue中的问题由涉及最多4跳推理的简单问题精心组成,然后由标注人员进行解析,以避免走捷径并确保语言的自然性。原始数据集中的每个问题都有2-4个提供一步推理证据的辅助段落和几个分散注意力的段落作为补充。
为了调整数据以进行长文本评估,该工作利用维基百科中包含支持段落或干扰段落的完整段落作为语境。首先,在上下文中包含支持性段落,然后添加尽可能多的干扰性段落,直到总长度达到最大长度。最后,这些段落被随机排序,形成多文档上下文。
除了这三个英文数据集之外,该工作还构建了一个基于DuReader的中文数据集。为了使其适用于评估长语境能力,该工作不仅为每个问题提供若干与该问题相关的文档,还从全部文档集中任意选择若干文档作为干扰项,直到每个问题与20个文档相关联。
3、Summarization摘要
与通常可以利用上下文中的局部信息来解决的质量保证任务相比,摘要要求对整个上下文有更全面的了解。
原始GovReport数据集是美国政府问责局和国会研究服务部的详细报告的大规模集合,每份报告都附有人工撰写的摘要,内容涵盖各种国家政策问题。
QMSum数据集包含了232个会议的查询-摘要对标注,涉及多个领域,包括产品会议、学术会议和委员会会议。该工作将查询视为输入I,将会议内容视为上下文C,将摘要视为答案A。
MultiNews是多文档摘要数据集,由2-10篇讨论同一事件或话题的新闻文章组成,每篇文章都配有人工撰写的摘要,总结了多篇源文章中的关键信息。在LongBench中,该工作在第i篇新闻文章前加入"Documenti",并将其串联到上下文C中。
VCSUM是一个大规模的中文会议摘要数据集,由239个真实会议组成,持续时间超过230小时,可支持多种摘要任务。在LongBench中,选择VCSUM中的长片段作为评估样本。
4、Few-shot Learning
为了确保任务的多样性,该工作将分类、总结和阅读理解任务纳入了few shot学习场景中。该工作纳入了两个具有细粒度类标签的分类数据集,包括TREC和LSHT,前者是涉及50个细粒度类的问题分类任务,后者是涉及24个类的中文新闻分类任务。
在摘要任务方面,使用SAMSum数据集,该数据集包含有标注摘要的信使式对话。TriviaQA包含标有证据段落的问答对,该工作将其用作阅读理解任务。该工作将TriviaQA中字数少于1,000字的段落过滤为潜在示例。
对于TREC、LSHT、SAMSum和TriviaQA,范围分别为[100,600]、[10,40]、[10,100]、[2,24]。
5、Synthetic Task合成任务
合成任务通过精心设计来测试模型在特定场景和模式下的能力。在LongBench中,该工作设计了三个合成任务。
PassageRetrieval-en和PassageRetrieval-zh基于英文维基百科和C4数据集构造,对于每个数据条目,该工作随机抽取30个段落,并选择其中一个使用GPT-3.5-Turbo进行总结。该任务要求模型识别精心制作的摘要所对应的原始段落。
PassageCount试要求模型利用完整的上下文来完成任务。对于每项数据,从英文维基百科中随机选取几个段落,将每个段落随机重复若干次,最后将段落打乱,要求模型确定给定集合中唯一段落的数量。具体地,该工作随机选择M作为段落数的上限。然后,从[2,M]范围内随机抽取唯一段落数N,从N个唯一段落中进行随机抽样(替换),得到最终的M个段落。
6、Code Completion代码补全任务
代码自动补全是自动补全系统的一项重要任务,它可以根据先前的代码输入和上下文帮助用户补全代码。
这项任务会对模型构成巨大挑战,尤其是在处理冗长的代码输入或甚至是资源库级数据时。这主要是因为模型需要根据代码元素内部的关系(如类和函数定义之间的关系)在长距离序列中建立注意力。因此,该工作认为这是一项适合评估模型长语境建模能力的任务。
其中:
LCC数据集取自原始的长代码完成数据集。原始数据集是根据长度过滤GitHub上一个文件中的代码而构建的。该数据包括作为上下文的前几行长代码和作为答案的下一行代码。
考虑到版本库级别的代码补全设置,这就需要汇总跨文件的代码信息。为此,该工作采用了RepoBench-P数据集。
RepoBench-P数据集收集自Github代码库,首先根据模块导入语句从其他文件中检索相关代码片段。然后将这些代码片段与当前文件中的前几行代码串联起来作为上下文,并用于预测下一行代码。
该工作从原始数据集中选择了最具挑战性的XF-F(跨文件优先)设置,在这种设置中,文件内上下文没有提供模块的先前使用情况来帮助预测。
对于每份原始数据,该工作会对包含真实跨文件代码片段(人工标注为最佳预测上下文)的跨文件代码片段进行打乱,并将其合并为上下文C。
四、LooGLE评测数据集
LooGLE包含更具挑战性的长依赖任务,如事件时间线重排、理解/推理和计算。这些任务不仅需要信息检索,还需要对整个文本进行理解/推理。
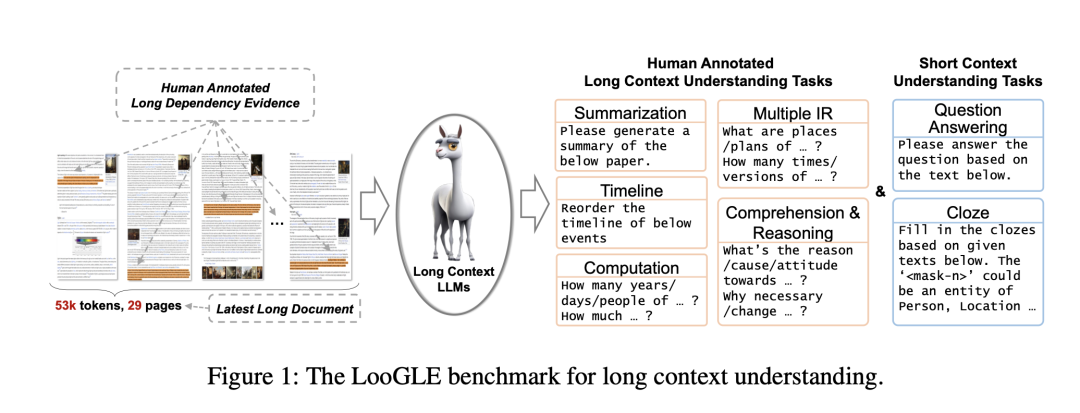
如表2所示,有三类数据源。
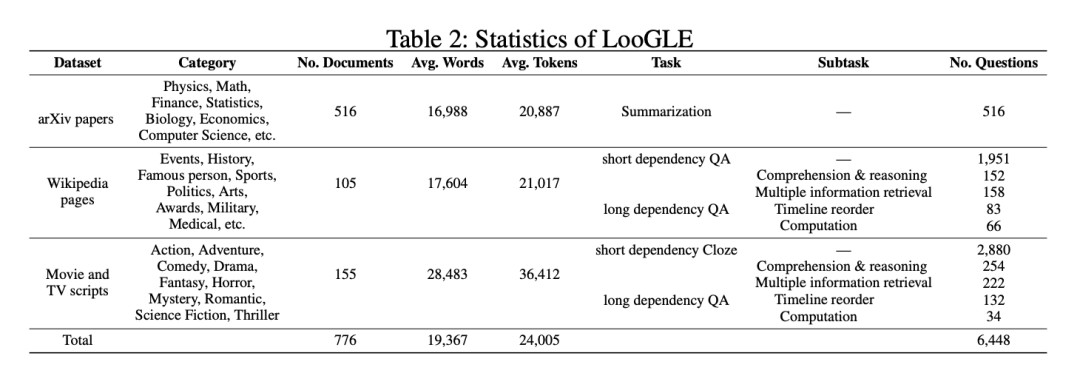
LooGLE中生成了两类主要任务:短依赖任务和长依赖任务。
对于短依赖性任务,从维基百科文章和脚本中生成短QA。
对于长依赖性任务,包括针对arXiv论文的摘要和针对长文档理解的人工设计QA任务。
QA有四个主要子任务:多重信息检索、时间轴重排、计算、理解和推理。该工作精细地生成任务/问题,以定制每个数据源的内在特征,从而更好地进行长文理解评估。
论文地址:https://arxiv.org/pdf/2311.04939.pdf
项目地址:https://github.com/bigai-nlco/LooGLE.
1、数据集的选择和构建
该LooGLE基准由3个数据源组成:科学论文、维基百科文章、电影和电视脚本,它们都涵盖了不同的主题和类别,用所有文档都是2022年后的文档,长度超过10k。
其中,
针对arXiv论文。采用随机抽取的方法,从arXiv网站(https://arxiv.org/)上的10,000个大量条目中抽取数据。这些条目从2022年1月到2023年4月不等。然后提取它们的摘要,使其成为该工作总结任务的主要来源。该工作在保证数据质量方面相当严格,所以删去参考文献部分,清理数学公式中的乱码,并剔除字数少于10,000字的文档。经过全面检查,该工作最终收集到了516篇可靠的研究论文。
对于维基百科文章,首先从官方网站(Wikimedia Downloads)下载并解析了以.bz文件格式存在的最新页面文章。然后,利用来自HuggingFace(https://huggingface.co/datasets/wikipedia)的开源维基百科数据集(202203.en)子集,保留了2022年之后字数超过10k的文章。由于转储文件中的某些页面可能已不存在,并被重定向到相关页面,因此只保留重定向后的页面(免责摘要、引文和参考文献)。
对于电影和电视脚本,所有剧本均来自三个网站(https://www.scriptslug.com,https://thescriptlab.com/,https://8flix.com),包括2022年之后上映的电影和电视剧
2、长依赖任务
摘要Summarization:直接使用每篇论文的摘要作为生成摘要的参考。摘要有效地捕捉了每篇论文的主要内容和关键信息。
每个文档的平均字数在10,000到20,000之间,需要生成5到10个问题。此外,参与者不得使用大型语言模型和ChatGPT等工具进行文章阅读、数据生成和标注。
Long dependency QA长依赖性问答:花费了大量精力手动编制了约1.1k个真正的长依赖性质量保证对。该工作手动设计了4个长依赖性任务:多重信息检索、时间轴重排、计算、理解和推理,如图2所示。

a.多重信息检索Multiple information retrieval
与传统的短期检索任务完全不同,对于一个特定的答案,整个文本中通常存在多种多样的证据。这项任务要求从广泛分布的冗长文本中提取大量信息,然后汇总证据,得出最终答案。证据的呈现方式非常明显,可以直接在原文的句子或章节中找到。
b.计算Computation
与前一项任务类似,它首先需要从大量文本中进行多重信息检索。文本中的大部分证据都以数字数据的形式出现,通常以问题的形式出现,如询问数量、频率、持续时间、具体数字等。
要做出准确的回答,必须深刻理解问题及其与所提供的数字数据之间的关联。这一过程在很大程度上依赖于掌握大量背景信息的能力,同时还涉及一定程度的数学推理能力。
c.时间轴重排Timeline reorder
这项任务采用了较为传统的形式,其中包括"请将下列事件的时间线重新排序"的指令,以及一组以排列顺序呈现的事件。任务的目的是将这些事件按照时间顺序排列在全文中。
这些事件直接来源于原文,可以是摘录的片段,也可以是概括的事实信息。要成功完成这项任务,就必须记住或全面理解文件的中心故事情节,并评估模型在时间意识方面的熟练程度。
d.理解和推理Comprehension and reasoning
这项任务不仅要求对问题有深刻的理解,还要求进行复杂的推理,以辨别寻找适当证据的内在含义。最常见的问题模式涉及对因果关系、影响、贡献、态度以及与各种事件相关的基本属性的探究。
这项任务的答案在原文中并不明显。它们往往需要多步推理来模拟内在的联系和依赖关系,从而有助于通过复杂的分析过程获得答案。
2、短依赖任务
短依赖任务包括Question Answering (QA) 任务和Cloze任务。为了生成简短的依赖关系问题解答对,该工作利用了GPT3.5-turbo-16k。这些简短的依赖关系问答对通常不需要大量的证据检索,可以从本地化的片段中提取。

该工作将每篇文章分为多个片段,并采用迭代方法来提示语言模型(LLM)根据这些片段生成QA对,包括文章中的相关支持证据。
随后对QA对进行人工审核,通过过滤非必要的上下文和删除多余的描述来完善部分答案。这一严格的整理过程是为了确保所生成的QA对的高质量和相关性。
2、Cloze任务
最初,该工作将每个脚本分成不同长度的片段。然后,该工作使用GPT3.5-turbo-16k生成与源片段一致的事实摘要以及提示中包含的一些限制条件(见附录D)。
之后,使用BERT-large对生成的摘要进行命名实体识别(NER),将类型限制为人名、地点和组织。
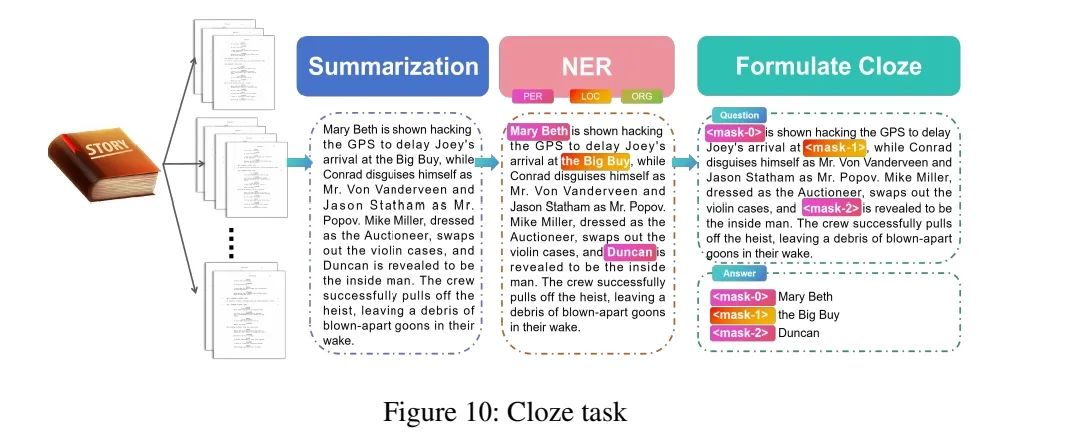
最后,从摘要中随机选择一定数量(不超过5个)的实体作为占位符进行屏蔽,标记为""。该目标是根据长上下文预测被屏蔽的实体。
五、总结
本文主要针对长文本评估,梳理了当前具有代表性的长文本评测,包括Zero-SCROLLS、L-Eval、LongBench以及loge四个基准。
其中关于数据集的选取,任务的设计,以及对现有模型的评估都具有很好的指引性,对于具体的细节信息,可以对参考文献进行查阅,会有更多的收获。
六、参考文献
1、https://arxiv.org/pdf/2311.04939.pdf
2、https://arxiv.org/abs/2308.14508
3、https://arxiv.org/pdf/2307.11088.pdf
4、https://arxiv.org/pdf/2305.14196.pdf
七、关于作者
老刘,刘焕勇,NLP开源爱好者与践行者,主页:https://liuhuanyong.github.io。
八、关于365文档
更多技术文档和资讯请查看365文档

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 6
6 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)