打脸Claude Code!Codex 全端支持第三方模型接入
全端支持第三方模型!Codex 深度配置与避坑实战指南
OpenAI 旗下的 Codex 现已在全端(含 CLI 与桌面客户端)正式开放第三方模型接入。
开发者可以通过自定义配置文件,自由接入各类开源或闭源模型。
本文将详细拆解 Codex 的配置流程、协议兼容方案、本地与云端模型接入步骤,并提供完整的避坑指南。
---
协议升级:理解 Codex 的 Responses API
在 2026 年的更新中,Codex 彻底废弃了传统的 Chat Completions 协议。
目前 Codex 全端已全面采用全新的 Responses API 协议。
Responses API 专为 Agent 交互设计,支持更复杂的工具调用、多模态输入和状态管理。
这就带来了一个核心问题:许多仍在使用 Chat Completions 协议的第三方模型(如 DeepSeek 官方接口)无法直接直连。
要解决这个问题,我们需要通过兼容层、支持新协议的网关或多模型聚合平台进行转接。
在配置之前,我们先来看看如何接入已经原生支持该协议的本地模型。
---
本地模型接入实战:Ollama 与 LM Studio
如果你希望在本地完全离线运行代码助手,Ollama 和 LM Studio 是极佳的选择。
1. Ollama 配置步骤
新版 Ollama 已经原生支持 Responses API 协议。
打开你的 Codex 配置文件 config.toml,添加以下配置:
model = "qwen2.5-coder:32b"
model_provider = "local_ollama"
[model_providers.local_ollama]
name = "Ollama"
base_url = "http://localhost:11434/v1"由于本地服务运行在局域网内,默认没有鉴权,因此无需配置 env_key。
你也可以直接使用命令行参数快速启动:
codex --oss2. LM Studio 配置步骤
LM Studio 是 Codex 内置支持的本地供应商。
在配置文件中指定:
model_provider = "lmstudio"或者在启动时指定默认的本地供应商:
oss_provider = "lmstudio"---
云端第三方模型接入与协议适配
对于无法直接支持 Responses API 的云端模型,我们需要使用多模型聚合平台或协议转换网关。
方案一:使用 OpenRouter 转接
OpenRouter 在网关侧实现了 Responses API 的转换。
在 OpenRouter 控制台绑定你的目标模型 API Key 后,在 config.toml 中配置:


toml
model = "deepseek/deepseek-v4-pro"
model_provider = "openrouter"
[model_providers.openrouter]
name = "OpenRouter"
base_url = "https://openrouter.ai/api/v1"
env_key = "OPENROUTER_API_KEY"在终端中导出环境变量:
export OPENROUTER_API_KEY=sk-or-your-key你也可以在运行时临时切换模型:
codex --profile openrouter --model anthropic/claude-sonnet-4-6方案二:使用 OpenAI Compatible API 演示环境配置
为了方便大家理解如何在 Codex 中配置兼容 OpenAI 格式的第三方模型服务,本文以 iThinkAPI 作为演示环境进行讲解。
Codex 支持通过标准 OpenAI Compatible API 接入各类主流模型。
在实际配置时,我们主要需要关注 API Key、Base URL 以及模型名称。
以下是 Codex 接入第三方模型服务的标准配置块:
Base URL:https://token.ithinkai.cn/v1
API Key:YOUR_API_KEY
Model:以服务文档为准,最新模型 gpt-5.5、claude-opus-4-8、gpt-image-2 等可按文档查看;涉及图片生成时,以 0.05¥/图起、2k/4k 支持等服务文档说明为准。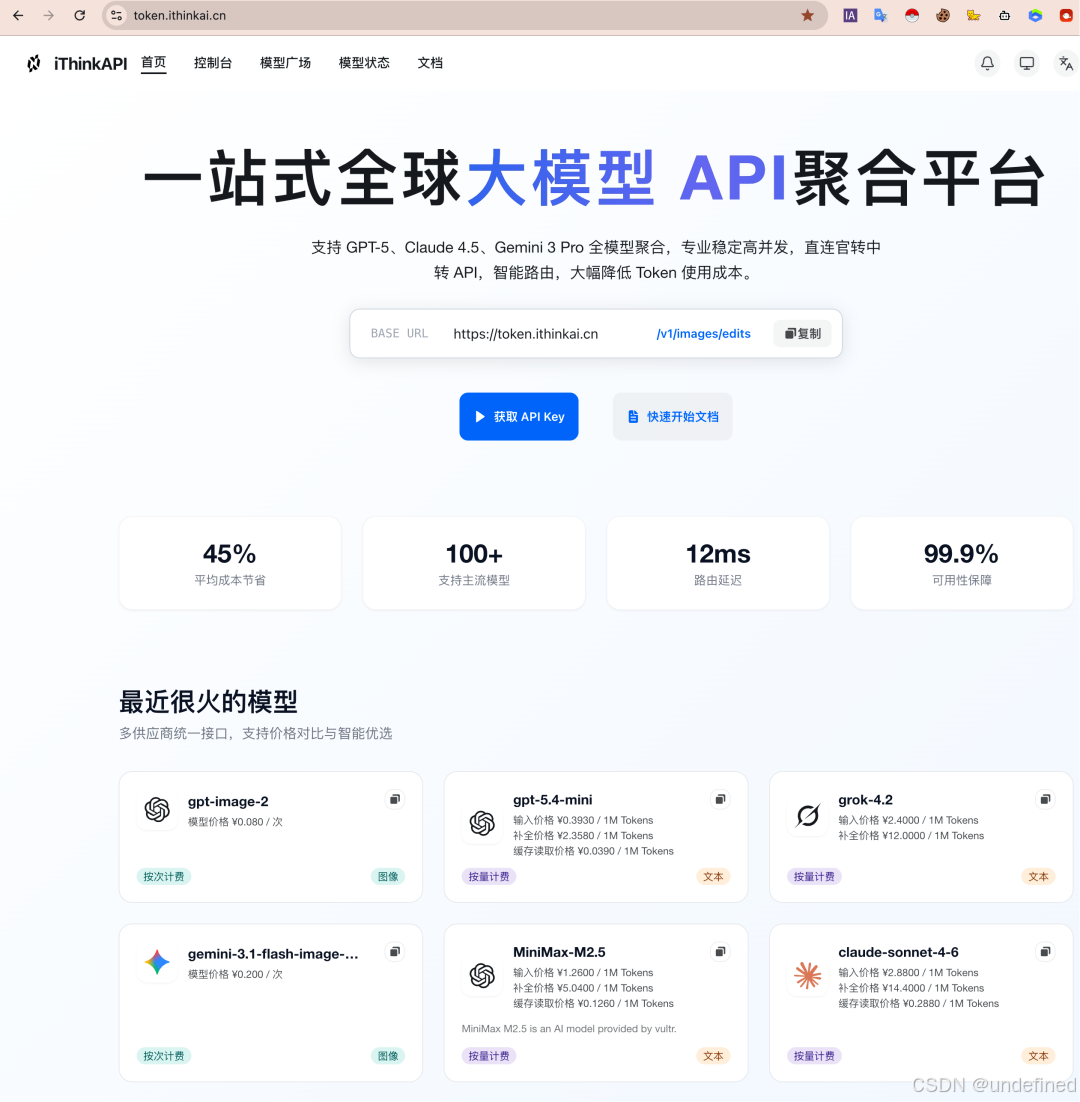
为了让 Codex 能够顺利调用这些模型,我们需要完成以下两个关键配置步骤:
第二步:挑选模型与确定分组
首先,登录你的多模型聚合平台控制台,进入“模型广场”。
在搜索框中输入 gpt、claude 或 image 等关键词,筛选出你当前任务所需的模型。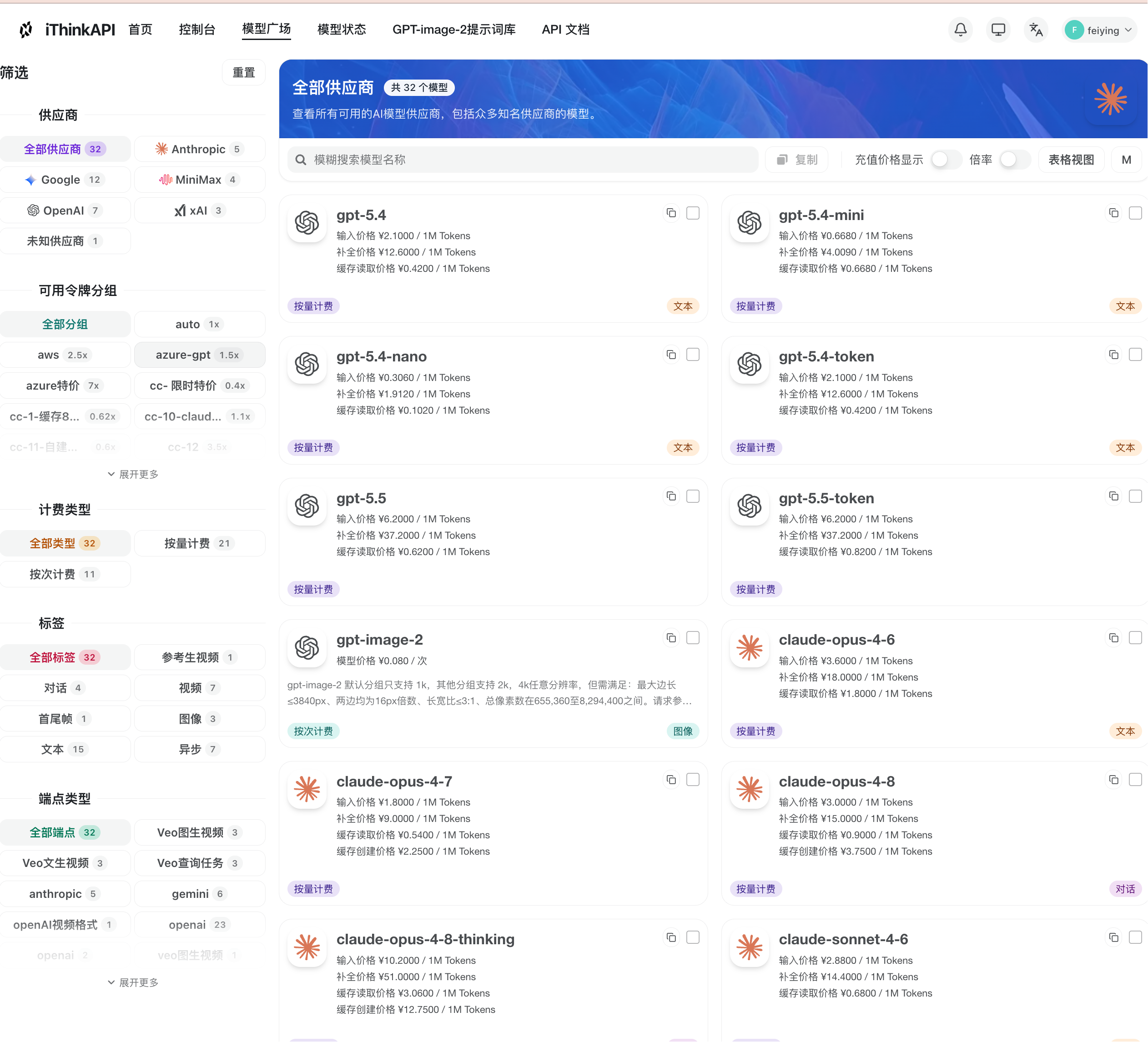
确认该模型对应的分组或线路。
需要注意的是,同一个模型在不同的分组或线路下,其响应速度、调用额度以及可用状态可能会有所差异。
具体的模型列表和分组规则,请务必以平台的实时服务文档为准。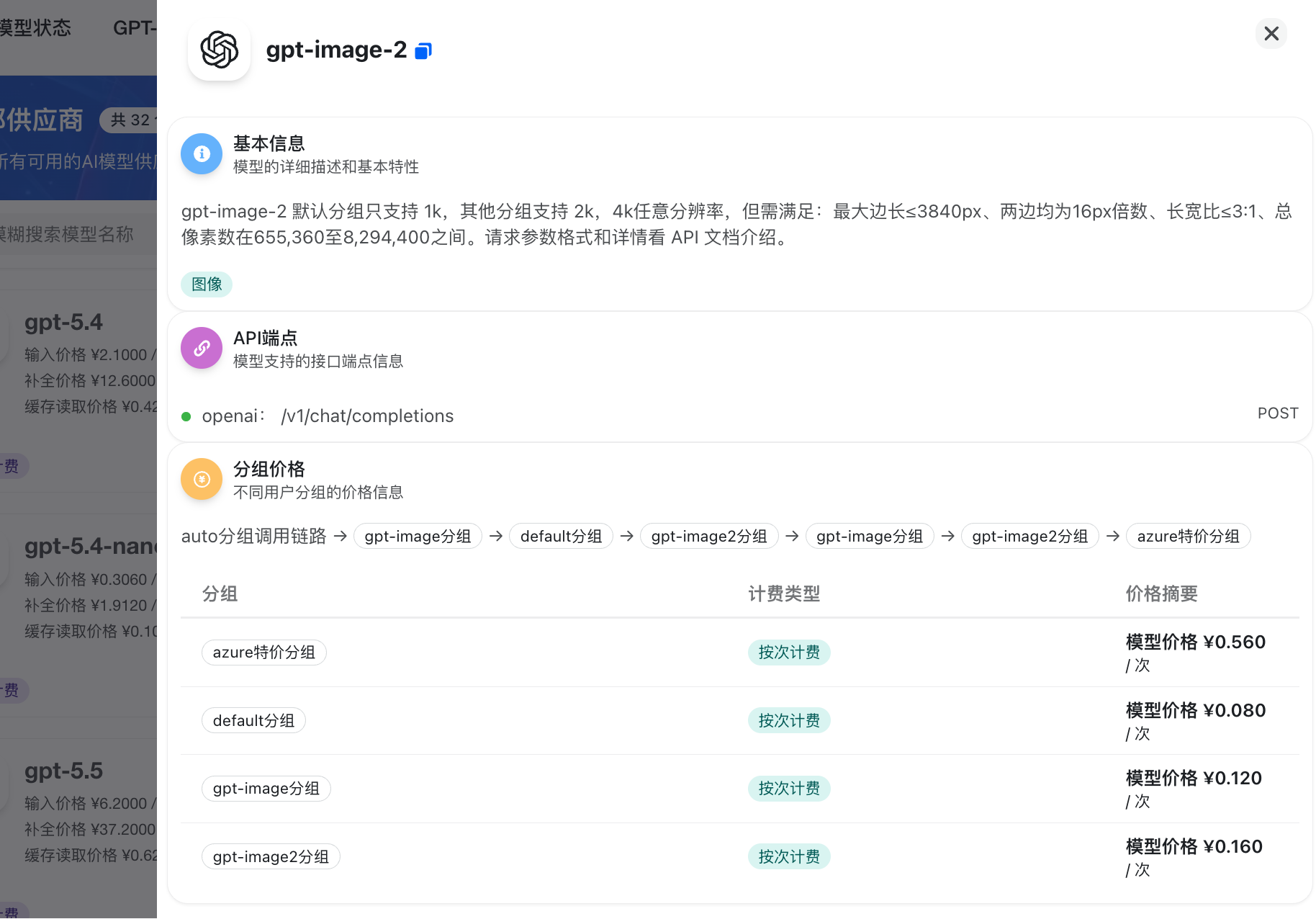
第三步:创建 API 令牌
确定好模型和分组后,进入控制台的“令牌管理”页面。
点击“添加令牌”按钮,创建一个新的 API Key。
在创建时,记得将该令牌绑定你在第二步中选中的模型分组。
如果你不确定具体的模型限制,可以先将限制条件留空。
令牌创建成功后,复制生成的 API Key。
回到本地的 Codex 配置文件中,将 Key 填入对应的 env_key 字段,并配置好 Base URL 和 Model 名称,即可进行连接测试。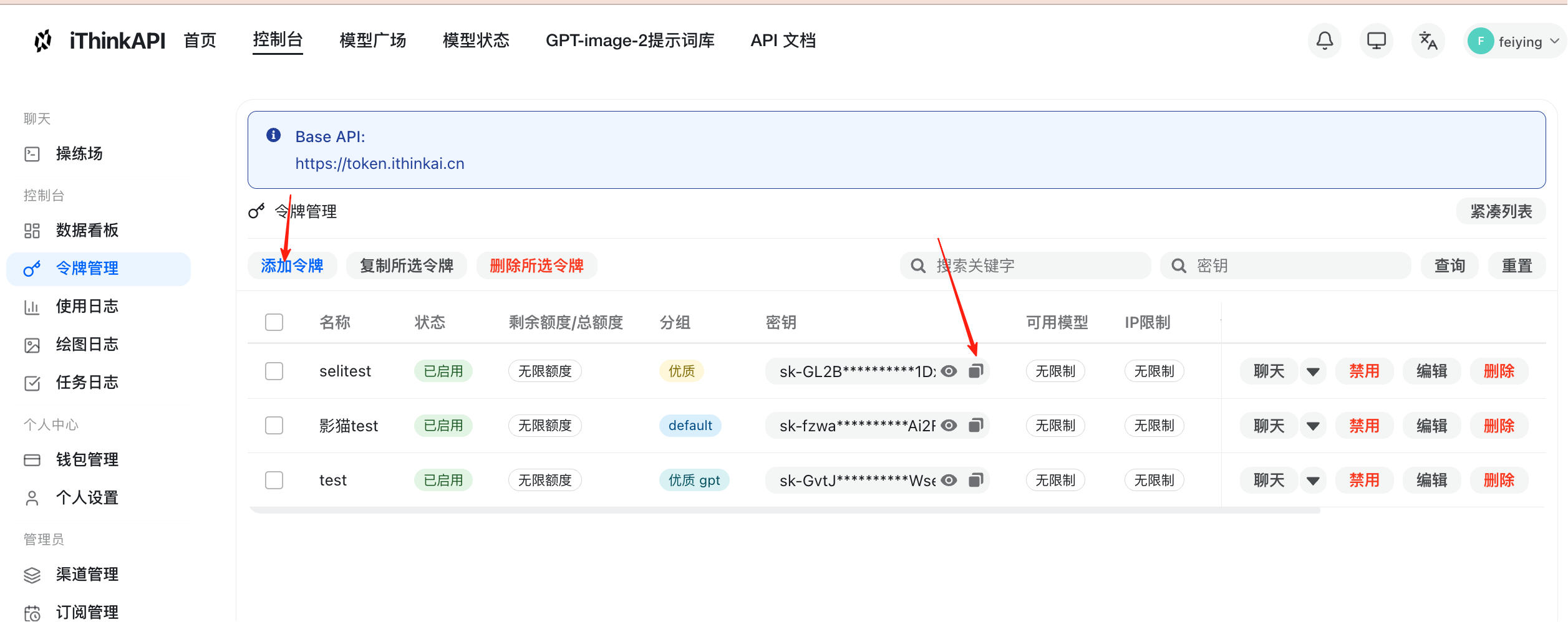
---
90+ 配置项如何管理?可视化工具实战
随着 Codex 功能的演进,其配置选项已多达 98 个。
手动修改 config.toml 不仅低效,还容易出现格式错误。
为了简化这一过程,推荐使用可视化的 Codex 图形配置工具。
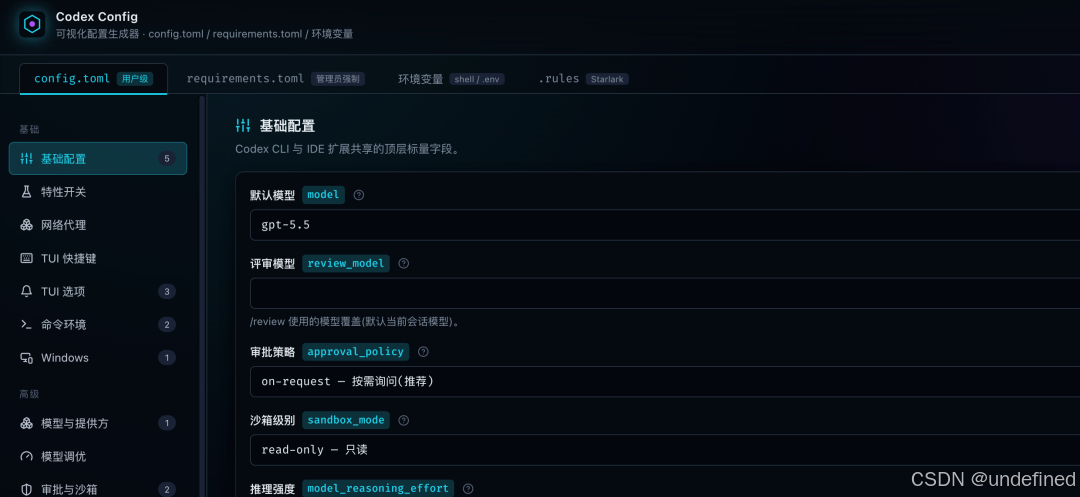
该工具实时同步了官方最新的 Codex 配置字段,并为每一条配置增加了详细的中文注解。
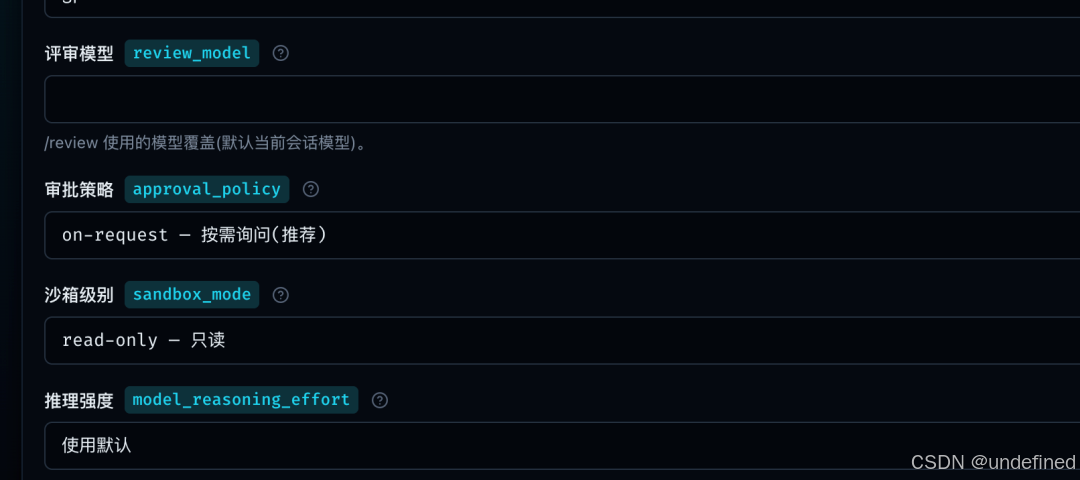
通过可视化界面,你可以轻松完成最简化的基础配置。
配置完成后,支持一键下载配置文件或直接复制内容。
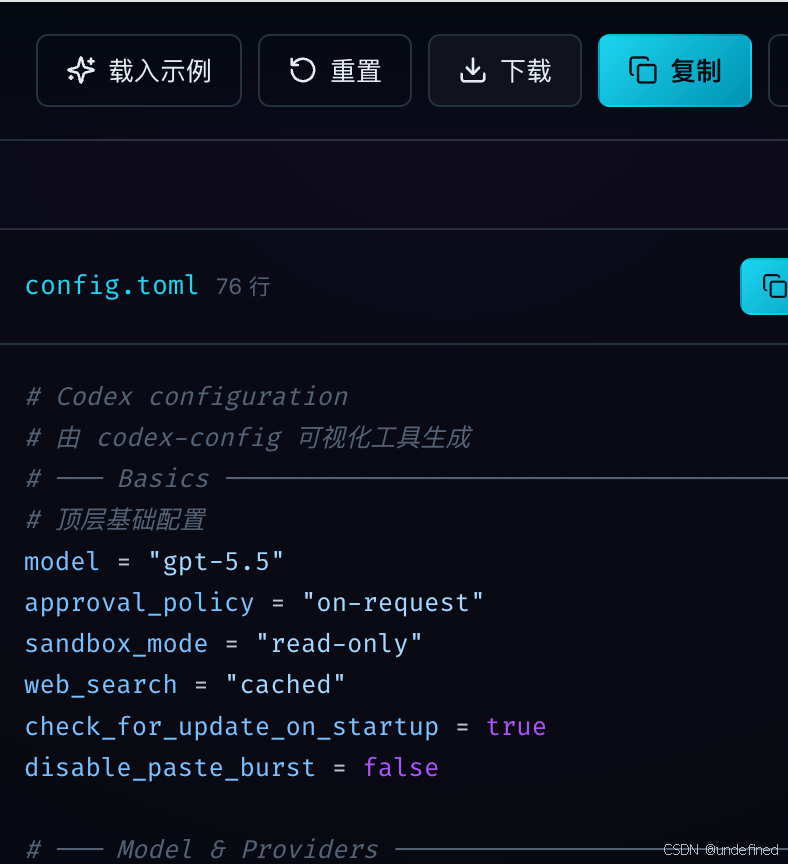
将生成的配置文件保存到本地的 .codex 目录中即可直接生效。
可视化配置工具访问地址:https://codexapp.cc
---
混合模型工作流与成本核算
在实际的开发场景中,合理搭配不同的模型可以达到效率与成本的平衡。
1. 规划阶段(高级模型)
在项目规划、架构设计或复杂 Bug 排查阶段,建议配置高智能的模型(如 gpt-5.5 或 claude-opus-4-8)。
这类模型能够更好地理解复杂的上下文和业务逻辑,给出更合理的整体方案。
2. 执行阶段(轻量模型)
在具体的代码生成、单测编写或格式化任务中,可以切换为响应速度更快的开源模型(如 Qwen2.5-Coder)或高性价比的云端模型。
通过在 .codex 配置文件中设置不同的 Profile,可以实现一键切换,从而优化 Token 消耗。
---
常见报错与排错指南
在配置第三方模型时,以下几个坑点需要特别注意:
1. 报错:400 Bad Request (Protocol Mismatch)
- 原因:你接入的第三方 API 仅支持传统的 Chat Completions 协议,而 Codex 强制要求 Responses API 协议。
- 排查:检查你的 Base URL 是否经过了协议转换网关,或者确认该供应商是否已适配新协议。
2. 报错:Connection Refused (本地模型无法连接)
- 原因:Ollama 或 LM Studio 的本地服务未启动,或者绑定的端口(如 11434)被占用。
- 排查:在终端运行
curl http://localhost:11434/v1/models测试本地服务是否正常响应。
3. 报错:401 Unauthorized
- 原因:环境变量未正确加载,或 API Key 填写错误。
- 排查:在终端运行
echo $OPENROUTER_API_KEY(或你自定义的环境变量名),确认 Key 已正确写入当前 Shell 环境。
---
总结
Codex 全端开放第三方模型接入,为开发者提供了极大的自由度。
无论是通过 Ollama 部署本地私有模型,还是通过多模型聚合平台调用云端大模型,合理的配置都能让你的 AI 编程体验翻倍。
建议结合可视化配置工具,根据不同的开发阶段灵活切换模型,从而达到性能与成本的最佳平衡。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 1
1 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)