Cell 重磅:微软 GigaTIME——从 5 美元病理切片到万人级免疫图谱,多模态 AI 重塑肿瘤微环境研究范式
Cell 重磅:微软 GigaTIME——从 5 美元病理切片到万人级免疫图谱,多模态 AI 重塑肿瘤微环境研究范式
一、研究背景
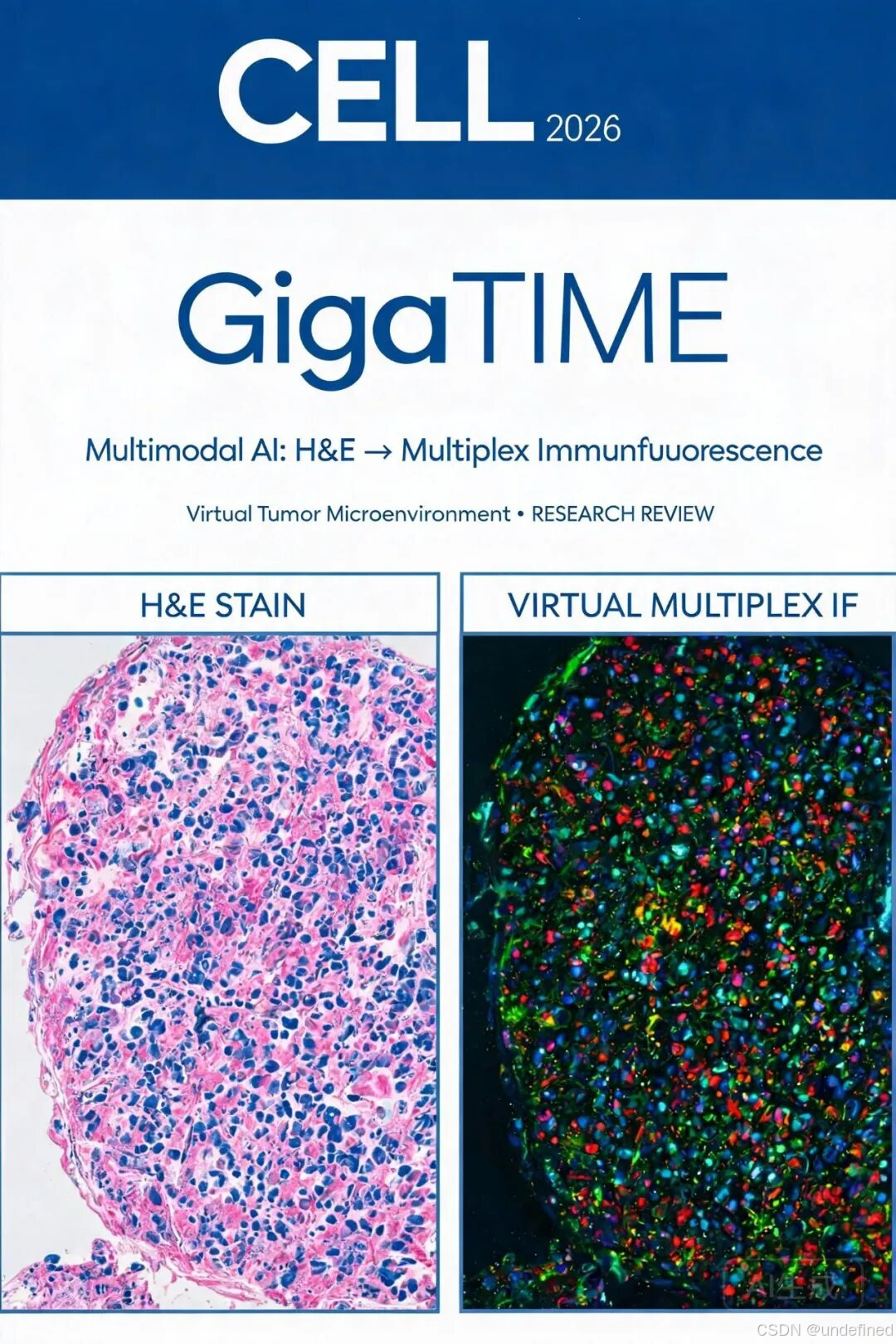
肿瘤微环境(Tumor Microenvironment, TIME)是决定癌症进展和治疗响应的核心战场。肿瘤的生长、转移和耐药并非仅由癌细胞本身决定,而是癌细胞与其周围免疫细胞、基质细胞、血管及信号分子动态相互作用的结果 [1]。这一认知推动了癌症治疗理念从"杀死癌细胞"向"治理滋生癌细胞的生态系统"转变。
解析 TIME 最核心的空间成像技术之一是多重免疫荧光(Multiplex Immunofluorescence, mIF),它能够同时检测组织切片中 20 余种蛋白质标志物的表达水平和空间分布,为精准免疫治疗提供关键信息 [2]。然而,mIF 的高昂成本(每张切片数千美元)和耗时特性(数天处理周期)严重限制了其规模化应用,即便顶尖实验室每年也只能覆盖极少部分样本 [3]。这一矛盾导致 TIME 研究长期停留在几十至上百例的小样本观察层面,难以在人群尺度上揭示肿瘤免疫的普适规律。
与此同时,苏木精-伊红(H&E)染色切片作为癌症诊疗的常规手段,每张成本仅 5-10 美元,全球医院每天产生海量 H&E 数据。此前,微软团队发布的 GigaPath 模型已证明 H&E 切片中蕴含丰富的结构信号,可用于预测关键生物标志物 [4]。但这些工作大多局限于组织整体水平的平均生物标志物状态,无法解析单细胞分辨率的空间免疫信息。
2025 年 12 月 9 日,微软研究院、Providence 医疗系统与华盛顿大学联合团队在 Cell 正刊发表了一项里程碑式研究——GigaTIME(Giga Tumor Immune MicroEnvironment),首次通过多模态 AI 将廉价的 H&E 病理切片"翻译"为高分辨率的虚拟 mIF 图像,并在 14,256 名癌症患者中构建了首个基于空间蛋白质组学的人群规模 TIME 研究 [5]。
二、研究创新点
GigaTIME 的核心创新体现在以下五个方面:
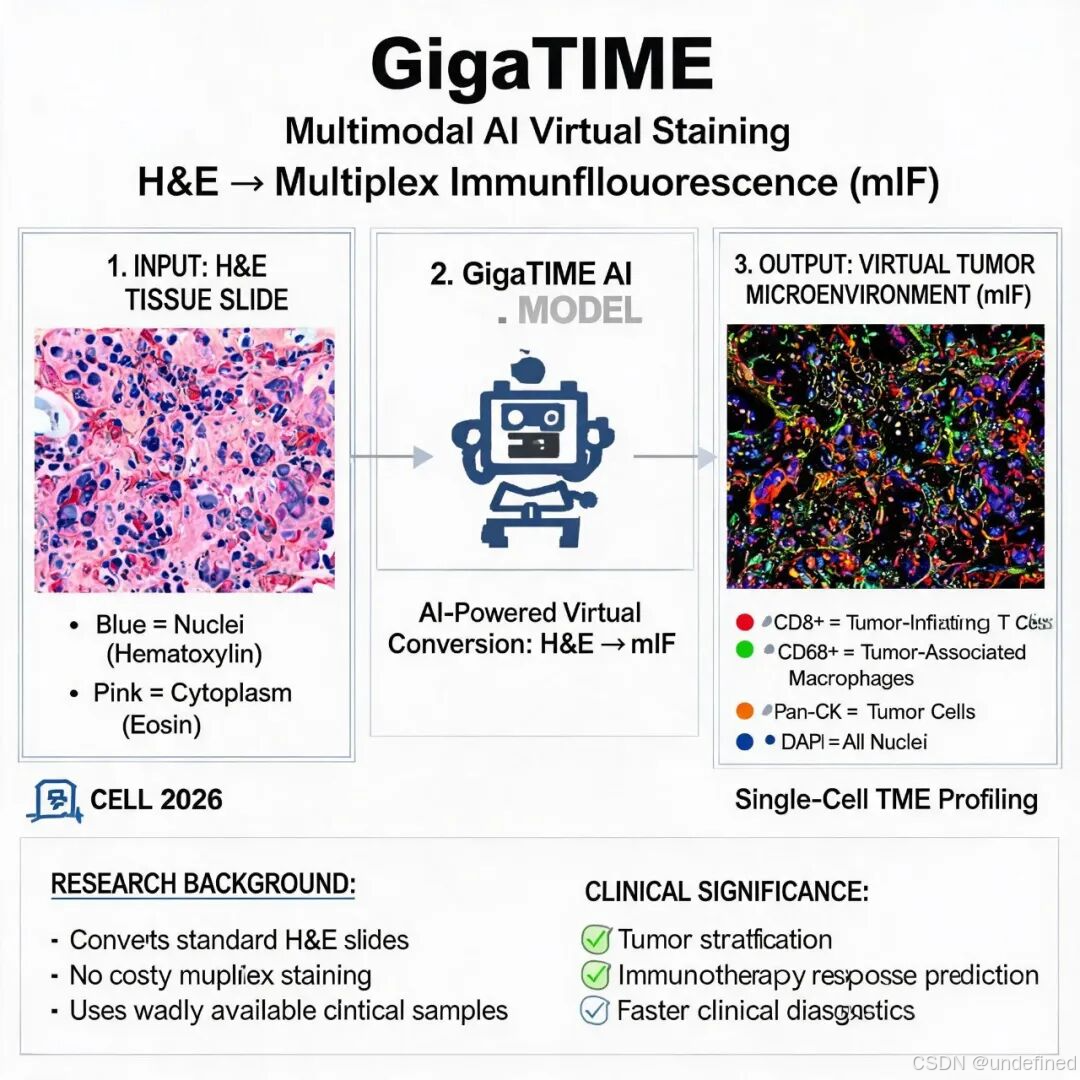
1. 跨模态"翻译"范式变革。 首次实现从 H&E 形态学染色到 21 通道 mIF 蛋白空间表达的跨模态转换,打通了"细胞形态"与"细胞状态"之间的信息壁垒。GigaTIME 并非简单生成图像,而是学习两种模态之间的"语言关系",将 H&E 中隐含的细胞核、细胞质和结构纹理信息"翻译"为免疫空间中的真实蛋白表达。
2. 前所未有的数据规模。 在 4,000 万个细胞级别的配对 H&E-mIF 数据上训练,覆盖 21 个蛋白质通道。随后应用于 14,256 名真实世界癌症患者,跨越 24 种癌症类型和 306 种亚型,生成约 30 万张虚拟 mIF 图像——这是迄今为止最大规模的 TIME 空间蛋白质组学研究。
3. 人群尺度的生物标志物发现。 在虚拟人群中识别出 1,234 个统计学显著的蛋白质-生物标志物关联,涵盖泛癌种、癌种内部和亚型内部三个层级,其中既包括文献验证的已知关联(如 MSI-H/TMB-H 与 CD138 上调),也发现了过去因样本量不足而无法观察的新型关联(如 KRAS、KMT2D 驱动突变与免疫活化的全局关系)。
4. 独立外部验证的稳健性。 在癌症基因组图谱(TCGA)10,200 名患者的独立数据上验证,虚拟蛋白激活的 Spearman 相关系数达 0.88,显著关联的 Fisher 精确检验 p < 2×10⁻⁹,证明了模型在不同人群、癌种构成和组织来源间的跨数据集泛化能力。
5. 全面开源与临床可及性。 微软将 GigaTIME 在 Hugging Face、GitHub 和 Microsoft Foundry Labs 全量开源,使这一技术不再局限于少数顶尖团队,有望成为精准肿瘤学的基础能力。
三、技术原理
GigaTIME 的技术架构围绕跨模态学习和人群规模推理展开,其核心设计理念在于从大规模配对数据中学习细胞形态到细胞状态的映射关系。
训练数据构建。 研究团队与 Providence 医疗系统合作,构建了包含 4,000 万个细胞的配对 H&E-mIF 训练数据集。每对数据包含一张 H&E 染色全切片图像(Whole Slide Image, WSI)和对应的 21 通道 mIF 图像,涵盖 DAPI(细胞核)、CK(上皮标记)、CD3/CD4/CD8(T 细胞亚群)、CD20(B 细胞)、CD68/CD163(巨噬细胞)、PD-L1、Caspase 3 等关键免疫和功能蛋白。数据集来源于 Providence 系统内 51 家医院和上千家诊所的真实临床样本,确保了训练数据的多样性和代表性。
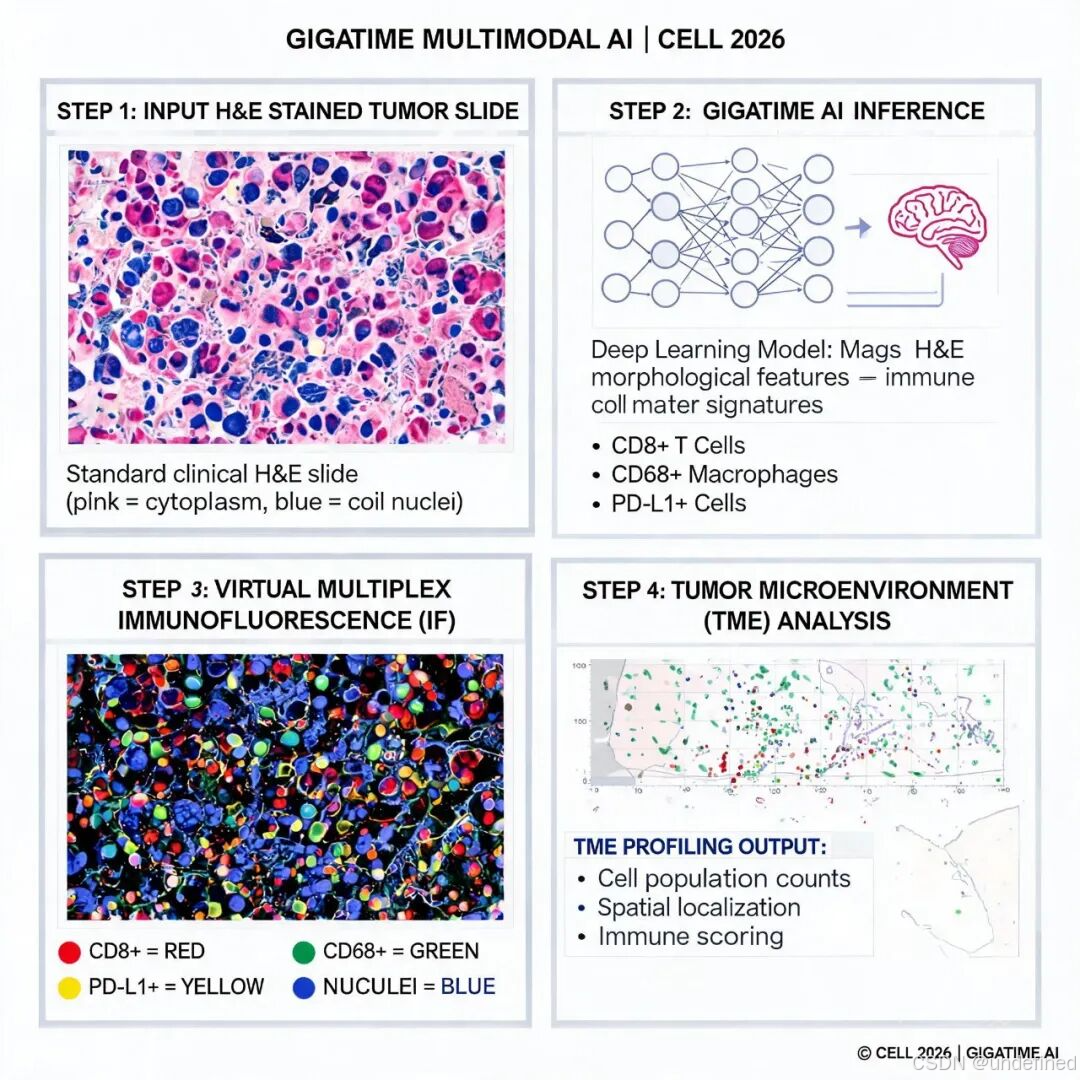
跨模态翻译架构。 GigaTIME 采用基于深度学习的跨模态图像翻译框架,以 H&E 全切片图像为输入,输出 21 通道的虚拟 mIF 图像。模型在细胞级别学习 H&E 形态特征(如细胞核大小、染色质纹理、细胞质染色模式)与 mIF 蛋白表达之间的对应关系。与传统的 CycleGAN 等方法相比,GigaTIME 在结构一致性(Dice 系数)和信号一致性(Pearson 相关系数)两个维度均实现了显著提升,生成的虚拟 mIF 在 DAPI、CK、CD68、CD4 等关键通道上与真实 mIF 高度相关。
基于 GigaPath 的架构继承。 GigaTIME 继承了微软此前发布的 GigaPath 全切片基础模型的部分架构优势。GigaPath 是首个能够处理十亿像素级别全切片图像的视觉 Transformer 基础模型,为大尺寸病理图像的全局特征提取提供了高效方案。GigaTIME 在此基础上进一步实现了从单模态(H&E)到多模态(H&E→mIF)的跨模态扩展。
人群规模推理与下游分析。 训练完成后,GigaTIME 被应用于 Providence 系统内 14,256 名癌症患者的 H&E 切片,生成约 30 万张虚拟 mIF 图像。随后,研究团队开展了三个层面的下游分析:生物标志物关联分析(识别蛋白质表达与基因突变、TMB 等的关联)、患者生存分层(利用虚拟 mIF 特征区分高低风险人群)和空间组合模式分析(探索蛋白质通道间的非线性交互作用)。
独立外部验证。 为验证虚拟 mIF 的可靠性,团队将 GigaTIME 应用于 TCGA 10,200 名患者的数据,并与 Providence 虚拟人群进行交叉比较。两个独立人群在癌症亚型级别的虚拟蛋白激活模式上高度一致(Spearman r = 0.88),证明了 GigaTIME 跨人群、跨机构的泛化能力。
四、实验结果
GigaTIME 在多个维度展现了卓越性能,以下为核心实验结果的系统总结:
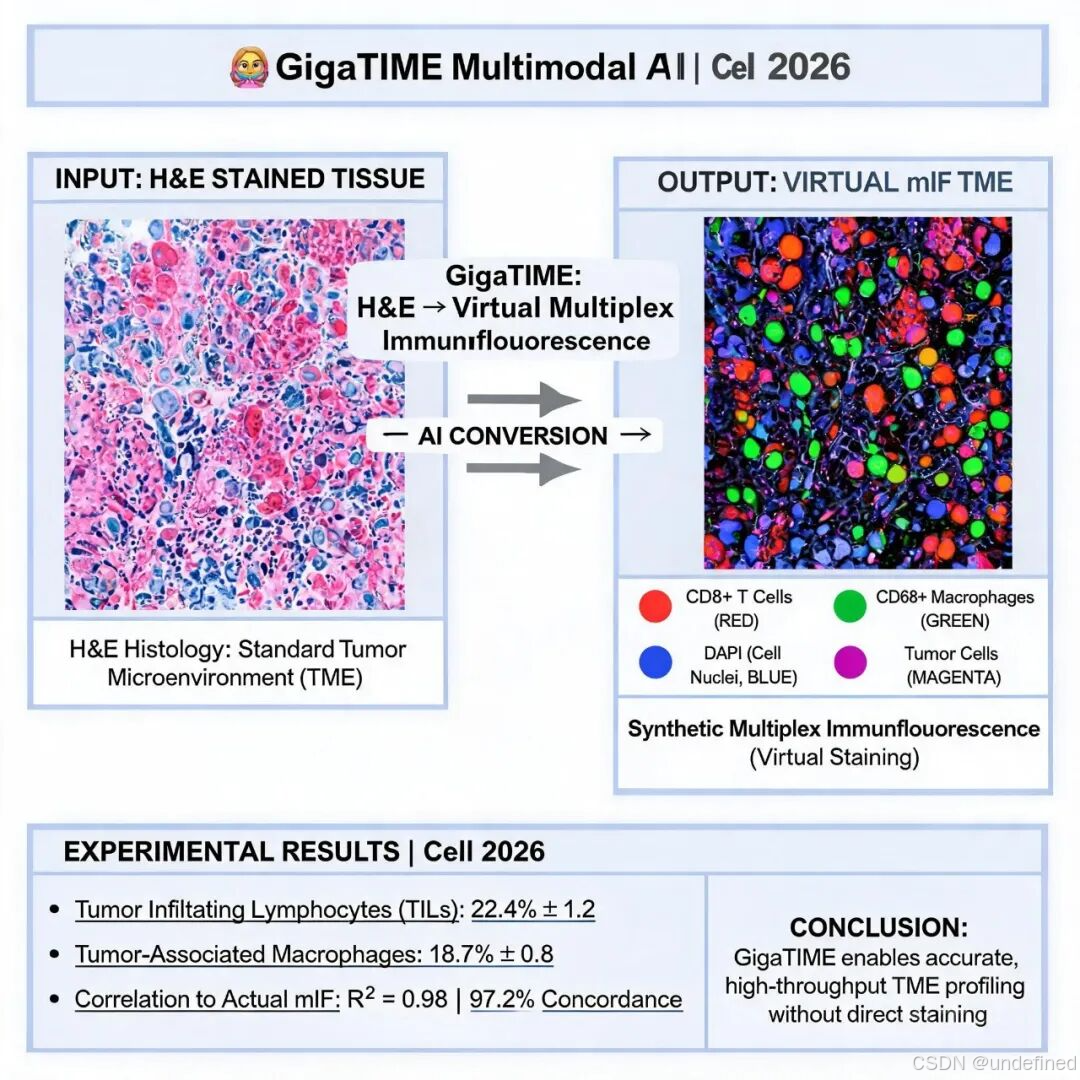
1. 跨模态翻译质量。 在留出测试集上,GigaTIME 的 H&E→mIF 翻译性能显著优于 CycleGAN 等现有方法。在结构一致性方面,Dice 系数显著提升;在信号一致性方面,Pearson 相关系数在多个蛋白通道上表现优异。以 DAPI、PD-L1、CD68 等关键通道为例,虚拟 mIF 与真实 mIF 的激活密度高度一致,散点图呈现强线性相关。
2. 虚拟人群规模与覆盖。 模型成功应用于 14,256 名真实世界癌症患者,生成 299,376 张虚拟 mIF 图像,覆盖 24 种癌症类型和 306 种 OncoTree 亚型。这一规模使 TIME 研究首次从"几十例"跨越到"万人级"。
3. 生物标志物关联发现。 经多重假设检验校正后,虚拟人群中识别出 1,234 个统计学显著的蛋白质-生物标志物关联:
• 泛癌种层面:MSI-H 和 TMB-H 患者普遍伴随 CD138、CD4 等免疫相关通道上调,与文献一致;
• 癌种和亚型层面:发现 KRAS、KMT2D 等驱动突变与免疫活化之间的新型全局关联,此前因样本量不足无法被观察到;
• 空间层面:虚拟 mIF 的熵、信噪比和锐度等空间指标与临床生物标志物存在显著关联。
4. 患者生存分层。 GigaTIME 整合 21 通道蛋白特征构建的 GigaTIME signature 在泛癌种、肺癌和脑癌中均能有效区分高低生存风险患者(log-rank 检验)。虚拟 CD3 和虚拟 CD8 单独预测效果与文献中真实 CD3/CD8 的表现一致,而 21 通道联合 signature 性能更优。
5. 独立外部验证。 TCGA 10,200 名患者的独立验证显示:
• 虚拟蛋白激活在不同癌症亚型间的 Spearman 相关系数为 0.88;
• Providence 和 TCGA 两个人群在蛋白质-生物标志物关联上显著重叠(Fisher's exact test p < 2×10⁻⁹);
• Providence 虚拟人群比 TCGA 多发现 33% 的显著关联,凸显了大规模真实世界数据的独特价值。
6. 空间组合模式。 虚拟人群揭示了蛋白质通道间的非线性组合效应。例如,CD138/CD68 联合和 PD-L1/Caspase 3 联合在生物标志物关联上显著优于单一通道,展示了虚拟人群在探索复杂免疫交互方面的独特优势。
| 评估维度 | 核心指标 | 结果 |
| 翻译质量 vs CycleGAN | Dice 系数 / Pearson r | 显著提升 |
| 虚拟人群规模 | 患者数 / 虚拟 mIF 数 | 14,256 人 / ~300,000 张 |
| 覆盖范围 | 癌症类型 / 亚型 | 24 种 / 306 种 |
| 显著关联发现 | 蛋白质-生物标志物关联数 | 1,234 个 |
| 外部验证 | TCGA Spearman 相关系数 | 0.88 |
| 生存分层 | 泛癌种 log-rank | 显著区分 |
| Providence vs TCGA | 关联重叠显著性 | p < 2×10⁻⁹ |
五、技术优势
1. 极低成本实现高维免疫分析。 GigaTIME 将获取 mIF 的成本从每张数千美元降低至近乎为零(仅需常规 H&E 切片),使大规模免疫微环境分析从"奢侈品"变为"日用品"。这种成本优势对于资源有限的医疗中心和低收入国家具有革命性意义。
2. 人群尺度的统计效力。 14,256 名患者的虚拟人群使研究者能够在充分的统计效力下发现新型生物标志物关联,突破了传统 mIF 研究因样本量不足而无法探索的"未知领域"。
3. 跨数据集泛化能力。 在 TCGA 独立人群上的高度一致性(r=0.88)证明 GigaTIME 并非对训练数据的"过拟合",而是真正学到了细胞形态与细胞状态之间的通用映射关系,具备跨机构、跨人群的泛化能力。
4. 空间分辨率的单细胞分析。 与仅输出组织平均值的传统方法不同,GigaTIME 生成的虚拟 mIF 保留了单细胞分辨率和空间位置信息,使得肿瘤免疫的"几何学"分析成为可能。
5. 全面开源。 微软将模型、代码和预训练权重全部开源,降低了学术和临床研究者的使用门槛,推动了精准肿瘤学领域的公平可及。
六、应用前景
GigaTIME 的临床和科研应用前景广阔,主要体现在以下方向:
精准免疫治疗决策。 通过分析肿瘤免疫微环境的组成和状态,GigaTIME 可帮助判断肿瘤是"冷肿瘤"(免疫荒漠型)还是"热肿瘤"(免疫浸润型),从而指导免疫检查点抑制剂的使用决策和联合治疗策略。
大规模生物标志物发现。 虚拟人群为系统性探索 TIME 蛋白与基因突变、临床结局之间的关联提供了前所未有的平台,有望加速新型预测性生物标志物的发现和验证。
药物研发与临床试验。 制药企业可利用 GigaTIME 在回顾性队列中快速筛选免疫相关药物靶点,在临床试验中利用虚拟 mIF 进行患者分层,从而降低研发成本、提高试验成功率。
"虚拟患者"(Digital Twin)构建。 微软团队将 GigaTIME 定位为"虚拟患者"愿景的第一步。未来,整合病理、基因组、影像学等多维度数据的"数字孪生"模型有望准确预测疾病进展和治疗反应,实现从"一刀切"到"千人千面"的精准医疗。
基层医疗赋能。 在缺乏 mIF 实验室的基层和偏远地区,GigaTIME 可通过常规 H&E 切片提供高维免疫分析能力,缩小医疗资源差距。
七、研究局限性与未来方向
尽管 GigaTIME 取得了突破性成果,但仍存在以下局限:
1. 训练数据的地理和种族多样性。 训练数据主要来自 Providence 医疗系统,其患者人口学特征可能无法完全代表全球人群。未来需要在更多样化的地理和种族队列中验证和微调。
2. 虚拟 mIF 的生物学保真度边界。 虽然虚拟 mIF 与真实 mIF 高度一致,但 AI 生成的内容始终存在"幻觉"风险。对于训练数据中未充分覆盖的罕见癌症类型或特殊组织形态,虚拟 mIF 的准确性需要进一步验证。
3. 蛋白质通道的有限性。 当前 GigaTIME 仅覆盖 21 个蛋白质通道,而人类蛋白质组包含数万种蛋白质。未来需要扩展至更多通道,以更全面地刻画 TIME 的复杂性。
4. 前瞻性临床验证缺失。 当前研究为回顾性分析,GigaTIME 在真实临床工作流中的前瞻性效用——如能否真正改善免疫治疗决策和患者预后——仍需通过随机对照试验验证。
5. 计算资源需求。 处理十亿像素级别的全切片图像需要较高的计算资源,在资源受限场景中的部署仍面临挑战。未来需要进一步优化模型效率。
未来方向: 团队计划将 GigaTIME 扩展至更多空间模态和细胞状态通道,并与 LLaVA-Med 等多模态对话框架集成,实现"与数据对话"的交互式图像分析。此外,将 GigaTIME 生成的虚拟 mIF 与基因组学、转录组学和影像组学数据融合,构建更全面的"虚拟患者"模型,是长期研究目标。
八、结论
GigaTIME 代表了 AI 医学影像领域的一次范式级突破——它不是简单地"识别"图像中的病变,而是从一种成像模态"翻译"出另一种模态的信息,本质上是一种跨模态信息生成。通过将 5 美元的 H&E 切片转化为数千美元的免疫图谱,并在 14,256 名患者的规模上验证其临床价值,GigaTIME 为精准免疫肿瘤学打开了一扇全新的大门。这项工作不仅展示了多模态 AI 在医学影像中的巨大潜力,也为"虚拟患者"时代的到来奠定了第一块基石。
参考文献
1. Binnewies M, Roberts EW, Kersten K, et al. Understanding the tumor immune microenvironment (TIME) for effective therapy. Nature Medicine, 2018, 24(5): 541-550. PMID: 29686425.
2. Taube JM, Akturk G, Angelo M, et al. The Society for Immunotherapy of Cancer (SITC) 2020 consensus statement on multiplex immunohistochemistry and immunofluorescence. Journal for ImmunoTherapy of Cancer, 2020, 8(1): e000155. PMID: 32060053.
3. Tan WCC, Nerurkar SN, Cai HY, et al. Overview of multiplex immunohistochemistry/immunofluorescence techniques in the era of cancer immunotherapy. Cancer Communications, 2020, 40(4): 135-153. PMID: 32198821.
4. Xu H, Usuyama N, Bagga J, et al. A whole-slide foundation model for digital pathology from real-world data. Nature, 2024, 630: 181-189. DOI: 10.1038/s41586-024-07441-w. PMID: 38778098.
5. Valanarasu JMJ, Xu H, Usuyama N, et al. Multimodal AI generates virtual population for tumor microenvironment modeling. Cell, 2026, 189(2): 386-400.e19. DOI: 10.1016/j.cell.2025.11.016. PMID: 41371214.
6. Chen RJ, Ding T, Lu MY, et al. Towards a general-purpose foundation model for computational pathology. Nature Medicine, 2024, 30: 850-862. PMID: 38504018.
7. Wang X, Zhao J, Marostica E, et al. A pathology foundation model for cancer diagnosis and prognosis prediction. Nature, 2024, 634: 970-978. DOI: 10.1038/s41586-024-07894-z. PMID: 39232164.
| 论文关键信息 | 内容 |
| 论文标题 | Multimodal AI generates virtual population for tumor microenvironment modeling |
| 期刊 | Cell |
| 发表时间 | 2025年12月9日(在线发表);2026年1月22日(正式出版) |
| DOI | 10.1016/j.cell.2025.11.016 |
| PMID | 41371214 |
| 通讯作者 | Hoifung Poon(微软研究院)、Sheng Wang(华盛顿大学) |
| 第一作者 | Jeya Maria Jose Valanarasu |
| 核心团队 | 微软研究院、Providence医疗系统、华盛顿大学 |
| 开源地址 | https://github.com/prov-gigatime/GigaTIME |
| 数据规模 | 4,000万细胞训练 / 14,256患者推理 / 约30万张虚拟mIF |

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 2
2 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)