数据库服务对象,从人转向智能体
数据库服务对象,从人转向智能体
过去十年,我们习惯了这样的画面:产品经理跑到数据工程师的工位前,提需求、等排期、拿报表。这套“人拉数”的模式,链条长、响应慢,数据就像仓库里的积压货物,不办手续根本出不来。
但Gartner一份报告直接给这传统模式下了“病危通知书”:到2028年,将有三分之一的企业软件界面不再是图形按钮,而是直接面向AI智能体。 数据库的服务对象,正从人转向一群不知疲倦的代码。
别把现在的智能体想象成只会查字典的助手。它们正在成为数据库真正的“主人”,而钥匙就是一套全新的交互协议。

最核心的变化来自MCP协议(大模型上下文协议)。它就像给智能体配了一把万能数据插座,让大模型能直接与数据库“对话”。传统模式下,人类得写SQL才能取数;现在智能体通过Function Calling机制,自己就能把“帮我分析下季度销售趋势”这句人话,翻译成数据库听得懂的指令,自动完成检索、计算甚至可视化。
更颠覆的是A2A协议(智能体到智能体协议)。单个智能体能力有限,但通过A2A,一群智能体能跨系统协同作战。一个负责查交易数据,另一个调取客服录音,第三个做情感分析——它们自己商量着就把活干了,全程无需人类插手。数据库从过去那个被动等待指令的“仓库管理员”,变成了主动参与决策的“智囊团成员”。
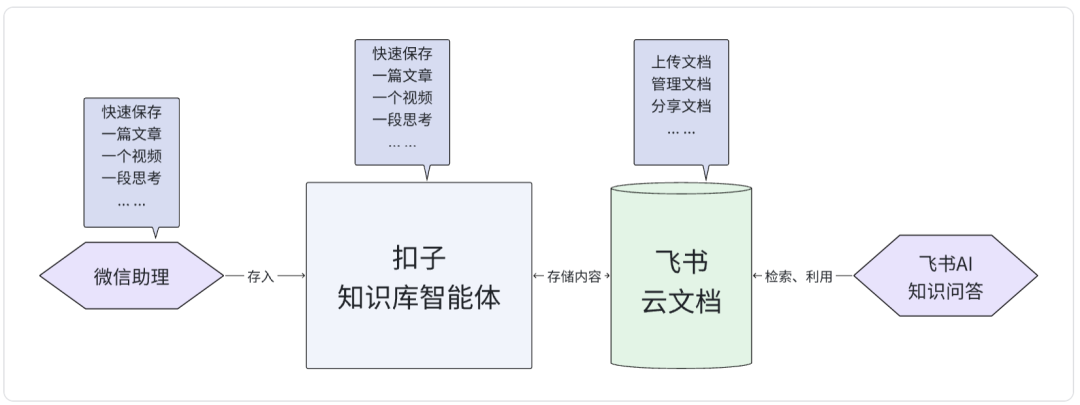
这套新协议,直接改写了数据的消费逻辑。过去是“人拉数”:你问,它答;你不问,数据就躺平。未来是“AI推数”:智能体不再等你开口,而是基于上下文和目标,主动把洞察喂到你嘴边。
想象一下高校科研管理的场景:以前每到季度末,科研秘书得手动从各系统扒数据,拼出一份成果统计表。现在,智能体自己盯着项目进度、经费使用率、论文发表情况,一旦发现某个指标异常,立刻推送预警和优化建议。这不是简单的报表自动化,而是从“查询为中心”到“任务为中心”的范式转移。
这种转变背后有个扎心的逻辑:人类越来越成为系统的瓶颈。我们处理信息的速度有限,提问的能力也有限。而智能体可以7×24小时监控数据流,在毫秒级完成“感知-分析-推送”的闭环。数据库的使命,正从支撑关键业务记录,转向成为AI时代的实时决策引擎。

二、 传统数据库的三大“不适应症”
当服务对象从“人”变成“智能体”,传统数据库的底层逻辑开始崩塌。这并非简单的性能不足,而是架构设计上的根本性错配——那些曾经支撑起互联网黄金时代的技术范式,正在成为AI时代最沉重的枷锁。
2.1 数据盲区:80%的非结构化数据价值被埋没
全球超过80%的数据是非结构化数据,包括银行海量的客服语音、面签录像、尽调图像、财务文本和社交舆情。但在传统关系型数据库的视角里,这些数据几乎是“不可见”的。

问题的根源在于架构基因。传统数据库的核心是处理行和列组成的结构化数据,要求数据在入库前就被严格定义格式。面对一段录音或一张图片,它只能将其视为无意义的二进制大对象(BLOB)存储,无法直接对其中的语义进行分析。
这意味着什么?金融机构坐拥海量信息,却只能依赖人工抽检或事后转录,巨大的业务价值被深埋在数据沼泽中。当智能体需要直接理解图片内容、检索相似视频片段、分析文本情绪时,传统数据库连数据“是什么”都无法识别,智能体就失去了决策的基础。这种语义理解能力的缺失,让传统数据库在AI时代沦为数据孤岛。
更关键的是,这不是简单“加个向量插件”就能解决的——非结构化数据的价值不在存储,而在语义检索与理解,这要求数据库从内核层面重构数据处理逻辑。
2.2 负载瓶颈:难以应对智能体带来的不确定性流量冲击
传统数据库的负载模型是“可预测”的。无论是双十一的交易峰值,还是月底的报表批量处理,其压力曲线有规律可循,可以通过提前扩容来应对。
但智能体的流量模式完全不同。OceanBase CTO杨传辉指出了一个关键洞察:AI智能体的生态类似于网红生态——绝大多数Agent默默无闻,少数爆款却会带来突发性的超高流量。一个突然走红的AI应用,可能在几分钟内让数据库请求量暴增百倍,而且这些请求不再是简单的CRUD操作,而是复杂的向量检索、多模态混合查询。
这种高度不确定的负载,要求数据库必须具备极致的弹性伸缩能力,也就是Serverless架构。传统数据库的扩容周期以小时甚至天计,根本无法跟上智能体流量的脉冲式变化。当数据库被突如其来的查询请求击垮时,智能体的“智能”就无从谈起。
更深层的问题在于成本。企业不可能为偶尔的峰值长期支付高昂的闲置资源,但传统架构下“预留峰值容量”的模式,与智能体时代“零成本冷启动”的需求之间,存在着难以调和的矛盾。
三、 AI原生数据库的“换脑”与冷思考
当服务对象从人变成智能体,数据库需要的不是功能补丁,而是一次根本性的架构重塑——从被动响应的存储仓库,转变为主动理解、推理并推送知识的认知引擎。
3.1 核心能力:以混合搜索统一处理多模态数据,对抗幻觉
传统数据库的运作逻辑是精确匹配:给定SQL查询,返回确定结果集。但智能体的工作方式截然不同。它面对的是银行海量的客服语音、面签视频、尽调图像和财务文本——全球超过80%的非结构化数据在传统数仓里只能沉睡,因为关系型引擎天然无法理解这些信息的内涵。
AI原生数据库的分水岭在于混合搜索能力。它必须在一套引擎中同时处理向量、全文、标量和空间地理数据,让智能体用自然语言提问时,数据库不仅“听懂”,还能跨模态关联信息。OceanBase CEO杨冰的判断很直接:在一个数据库中支撑事务、分析与AI混合搜索,才能在数据源头驱动实时、可信的智能。
但更棘手的问题藏在背后:大模型幻觉。当智能体直接操作生产数据,一次错误推理可能造成实际业务损失。AI原生数据库的解法是内置数据分支能力,让AI在隔离环境中安全探索与迭代,同时保证每次输出都可追溯到原始数据。这不是锦上添花,而是企业级AI落地的硬性门槛。
3.2 价值审视:是支撑智能体的刚需,还是技术泡沫下的伪需求?
面对密集发布的AI数据库产品,一个合理的质疑浮出水面:这到底是真实刚需,还是又一轮技术泡沫?
从需求端看,变化是真实的。Gartner预测,到2028年,三分之一的企业软件界面将转向智能体前端。这意味着数据库将面对数量级的租户增长和高度不确定的负载模式——一个智能体可能长期静默,也可能瞬间爆发海量请求。这种“网红式”的流量特征,传统架构根本无法弹性应对。
但冷静审视,技术成熟需要多个“科技树”同时点亮。数据库自治讲了多年,囿于AI能力不足和大模型幻觉问题始终未真正落地。IDC中国研究经理王楠也指出,数据库智能体要真正实现自治,还需跨越从半自主决策到主动解决问题的鸿沟。
一个技术要成熟,需要很多“科技树”同时被点亮——如果基建问题无法完全解决,也就无从谈规模化应用。
这意味着,AI原生数据库的演进不会是直线冲刺,而更可能经历过高期望的峰值、泡沫化的谷底,最终筛选出真正成熟的技术路径。对企业而言,关键不在于追逐概念,而在于识别哪些场景已具备落地条件,哪些还需等待技术拐点。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 2
2 0
0- 0



 已为社区贡献16条内容
已为社区贡献16条内容

所有评论(0)