AI 压缩上下文那一下,替你扔了什么
重度用 AI 干活的话,你大概见过这么一行字——「正在压缩上下文」,或者一个进度条走到底,提示你上下文快满了。
那一下,AI 在干嘛?
大多数人没细想。你以为它就是「整理一下、腾点地方,继续陪你聊」。但实际上,那一瞬间,它在替你做一件挺重的事:决定你们之前所有的对话和工作,哪些留下、哪些扔掉。而且这个决定,你基本看不见,默认也插不上手。
它扔掉的东西,可能正是你过会儿要用的。这就是为什么有时候 AI 会突然「失忆」——前面好好的,压缩一下,它就忘了你反复交代过的事。
我把市面上主流 agent 的压缩机制扒了个底朝天,从 Claude Code 到 Codex、Gemini CLI、OpenHands、Aider。发现它们压的方式很不一样,但底下是同一套逻辑。今天就把这条「压缩流水线」彻底拆开:它到底按什么顺序压、什么活得下来、什么第一个被丢,以及你怎么才能不被它的遗忘坑到。
先纠正一个误会:压缩不是「浓缩成精华」
很多人以为,压缩就是 AI 把前面聊的东西「智能地总结成精华」,留下重点。
不完全是。真实的压缩,是一套有明确优先级的取舍——它不是一上来就「概括」,而是先挑最不值钱、最占地方的下手。能用便宜手段腾出地方,就绝不动用昂贵的「概括」。
理解这条流水线的顺序,比记住任何单个技巧都重要。它大概是这么三步走,从最无损到最有损。
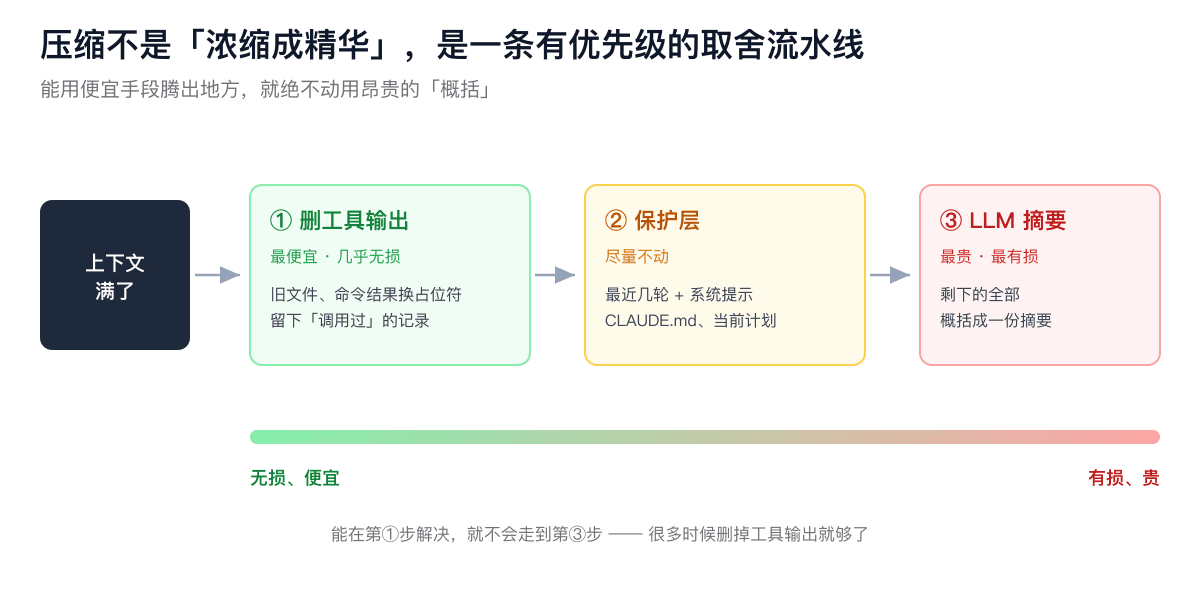
第一刀:先删工具输出
AI 干活的时候,最占地方的不是你们的对话,是工具输出——它读过的文件内容、跑命令的结果、搜索返回的一大堆东西。这些在一个干活的 agent 里,能占到七八成的空间。
而这些东西有个特点:用完就可以扔,要的时候再调一次就行。它读过的那个文件,内容记不记得在上下文里无所谓,反正需要时再读一遍。
所以压缩的第一刀,永远先砍这里:把旧的工具输出,内容替换成一个占位符(类似「旧结果已清空」),但保留「我当时调用过这个工具」的记录。这样模型知道自己干过这事,只是具体结果不在眼前了。
这一刀便宜、快、几乎无损——不用调用模型,就是机械地删。Claude Code 每次回答前都会默默做这个清理,只留最近 5 个工具结果,其余清掉。Anthropic 的接口里也有专门的开关干这件事,你能设「保留最近几个、至少清掉多少、哪些工具的结果永远别清」。
很多时候,光这一刀,地方就腾出来了,根本用不着后面更狠的手段。
保护层:最近的,和钉死的
第二件事,是它尽量不动的部分。
一类是「最近的」。最近一段对话、最近几轮操作,原样保留——因为你当下正在干的事,全靠它。
一类是「钉死的」。系统提示、项目根目录的 CLAUDE.md(如果你用 Claude Code)、当前的任务计划、正在用的技能——这些被钉在上下文里,压缩不去碰。
这里藏着一个特别重要、但很多人不知道的点:你写在 CLAUDE.md 里的规则,压缩动不了;但你在聊天里临时交代的话,压缩说删就删。 后面会展开它的意义。
最后一招:让模型把剩下的写成一份摘要
前面两步还不够,才轮到最后这一步——让模型把剩下的历史,概括成一份摘要,然后把原始的长对话整个换成这份摘要。这是最贵(要额外调一次模型)、也最有损的一步。
这一步里,藏着我觉得最值得讲的一个细节。
很多人以为它就是甩给模型一句「帮我总结一下前面」。不是。至少 Claude Code 不是——它用的是一个固定的九段模板,逼着模型按格式一段段填:

你看这九段——它要的不只是「聊了啥」,还有「为什么」(意图)、「卡在哪」(错误和修复)、「接下来干啥」(待办、下一步)。它甚至要求模型把你说过的关键的话逐字引用下来,不许自己换个说法转述。为什么?因为一旦允许它「自己理解着复述」,转着转着就会跑偏,越压越偏离你最初的意思。逐字引用,是给它上的一道锁。
顺便说一句,你如果用过 Claude Code,有时会看到对话开头冒出一句「This session is being continued from a previous conversation…」——那一整段,就是这份摘要本身。你看到它,说明你的对话已经被压过、换过一轮了。
那到底什么活下来,什么被丢
绕了一圈,回到最关键的问题:压完之后,什么留下了,什么没了?

活下来的:CLAUDE.md 和系统提示、工具定义、你当前在干的任务、最近改过的文件、最近的报错和解法、你说过的原话、还没做完的待办。
被丢掉的:你在开头立的规矩(「这个文件千万别动」「输出用这个格式」)、中间做选择的理由(为什么选了方案 A 而不是 B)、几十条消息之前讨论过的具体代码、还有那些你没明说、但希望它照做的细微偏好。
把这个不对称看明白,你就理解 AI 为什么会「失忆」了——
它能可靠地记住「接下来要做什么」,却会系统性地忘掉「当初为什么这么做」。 做决策时的那个「为什么」,几乎总是第一个被牺牲掉的。因为压缩的设计目标,就是「让任务能接着往下跑」,而不是「留住你们一路走来的来龙去脉」。
这也解释了一个很常见的坑:你前面跟它反复确认「咱们就用这个方案,因为另一个有坑」,压缩一下,它把「用这个方案」记住了,把「因为另一个有坑」忘了——过会儿它可能又兴冲冲给你绕回那个坑里去。
各家的压法,其实分几个流派
上面这套主要以 Claude Code 为例。但不同 agent,压法差挺多的,大致分几派——不管你用的是国外的还是国产工具,对照着看就清楚了。

主动摘要派:Claude Code 是代表,OpenHands 也是。OpenHands 的做法更有意思——它的摘要专门盯着「用户的目标、已经做到哪了、还剩啥没做、关键的文件和失败的测试」,而且它允许 agent 自己喊「我觉得该压了」,主动触发。
先删后压派:OpenCode、Kilo 走这条。它把流程拆成两段——先把旧的工具输出删掉(不调模型,便宜),如果这样还不够,再上 LLM 摘要。而且它有个规矩:除非能腾出足够多的地方(比如两万 token 以上),否则不值当地动手。
绕开压缩派:有的工具干脆尽量不压。Gemini CLI 靠的是把窗口堆到很大(上百万),能塞就硬塞。Codex 和 Aider 则换个思路——不把整个项目都塞进去,而是按需去取:Aider 特别巧,它用代码解析给你整个仓库画一张「地图」,只标出有哪些关键的类和函数、在哪个文件,把这张轻量地图发给模型,模型要看哪个文件的细节,再单独去取。
外部记忆派:还有一招是把关键信息写到上下文之外——存到硬盘上的文件里,清空之前先存好,之后要用再读回来。这其实就是给 AI 配一个外部档案。
这几派底下,是同一个权衡:在「省钱省地方」和「别丢关键信息」之间,各家选了不同的折中点。
还有一个容易被忽略、但很关键的区别:删除和转存不是一回事。

删除是永久没了;转存是把内容挪到外部、在原地留个「指针」,需要时还能取回来。一个不可逆,一个可逆。好的压缩,会尽量把「可能还要用的」转存,而不是直接删掉。
说到底,没有「无损压缩」
聊了这么多机制,我想说一句可能扫兴的话:别信「无损压缩」这个词。
只要是把多的压成少的,就一定有损,这写死在信息这件事的本质里。区别只在于——丢的是不是你正好要用的那部分。
而麻烦在于:自动压缩的时候,是机器替你做这个取舍,它经常丢错。 它会把你觉得重要的架构决策概括没了,却留着一堆没用的中间输出。有评测专门测过,让各种压缩方法记住「这一轮到底改过哪些文件」,结果普遍很差。
所以,与其指望它压得准,不如你主动配合它。
你能做的几件事
知道了它怎么压,就知道怎么不被它坑:
把关键信息放到「压不掉的层」。 这是最重要的一条。项目级的规矩、绝不能错的约束,别只在聊天里说一次——写进 CLAUDE.md 这种系统级的地方(前面说过,压缩动不了它);重要的事实和数据,存到外部文件里。聊天历史是最容易被压掉的一层,别把身家性命押在那。

别等它自动压,自己挑时机压。 自动压总在快撑爆的时候才触发,那会儿它慌、压得糙。你不如在一个任务刚告一段落、上下文还算干净的时候,手动触发压缩,并且明确告诉它「这次重点保留关于 XX 的部分」。你指定的,比它瞎猜的准。
重要结论,自己复述一遍钉下来。 既然工具输出会被第一个删掉,那从一大堆输出里得出的关键结论,让它(或你自己)用一句话总结、明确写下来——这句话会留下,原始那一大坨会被清掉。
长任务拆开干。 别赌一个上下文从头扛到尾。拆成几段,每段干完、确认好,再开下一段。
最后
回到开头那个「正在压缩」的瞬间。
我现在的理解是:所谓自动压缩,不是 AI 变聪明了、能记住更多东西。恰恰相反——它是 AI 学会了有策略地遗忘。
它替你做的每一次取舍,本质都是一次赌注:赌你接下来,不需要它扔掉的那部分。赌赢了,你觉得它聪明又省心;赌输了,你就撞上一次莫名其妙的「失忆」。
你没法让它不遗忘——上下文有限,遗忘是必然的。但你能决定,把什么钉在它忘不掉的地方,把什么放心交给它去忘。
看懂这套取舍逻辑,AI 的「失忆」就不再是个让你措手不及的玄学,而是一件你能预判、能管理、甚至能利用的事。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 0
0 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)