AI 写代码越快,为什么 Code Review 越不能省?
现在整个前端圈都在享受自动化提效的红利。在掘金或者微信技术群里,大家都在分享 Claude Code 或者 Codex 有多高效。几行简短的提示词,成百上千行的复杂业务逻辑瞬间生成。
速度确实很快。但在自动化红利背后的阴暗角落里,无数个一线小伙伴正在默默承受风险,频繁地给这些 AI 生成的隐患代码善后🤷♂️。
之前团队里一位经验尚浅的开发,通过大语言模型全自动生成了一个带有复杂联动的商品筛选组件。
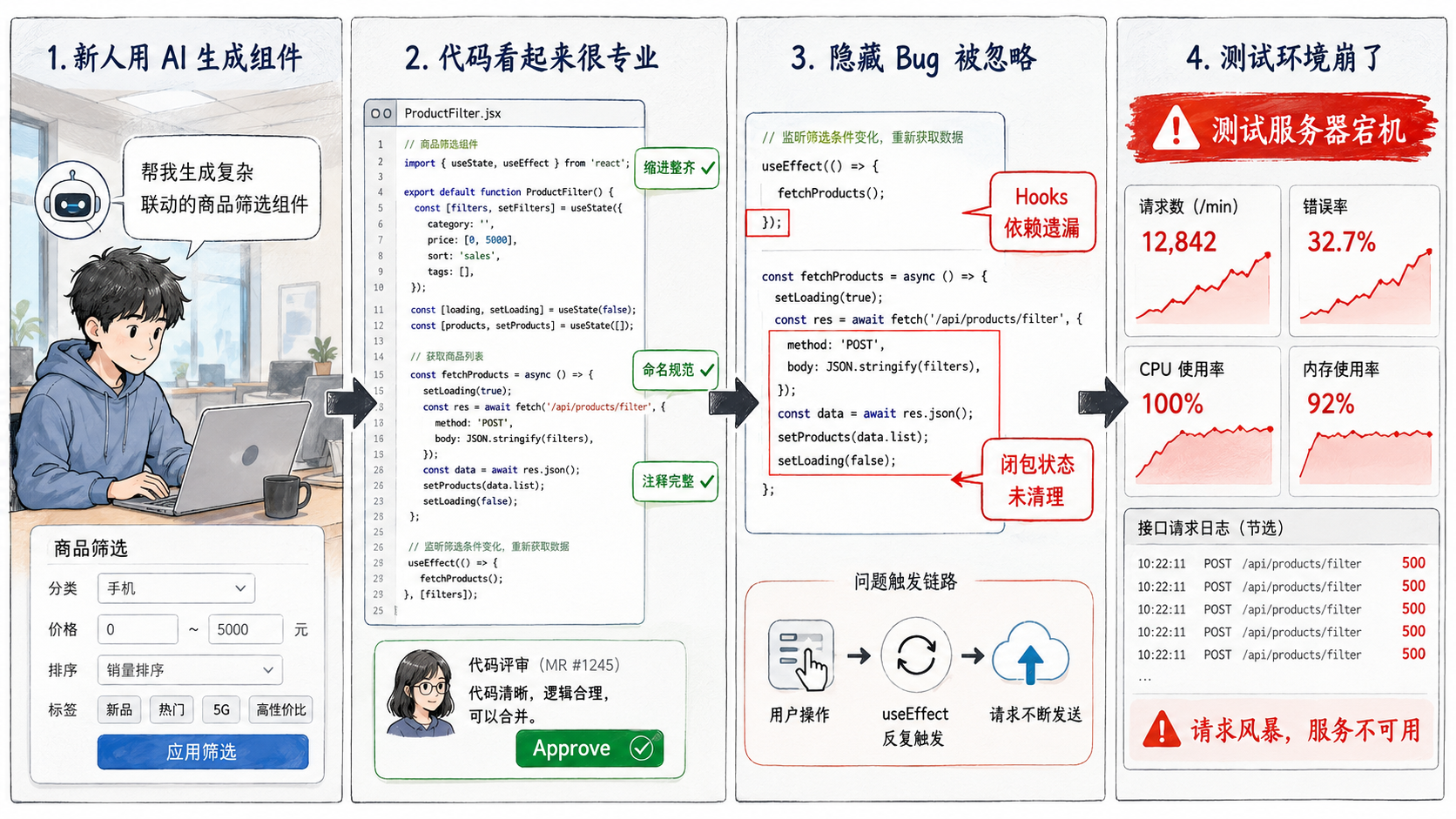
代码表面看着简直无懈可击:缩进完美,变量命名规范,甚至还极其贴心地带了标准的注释。这种极其专业的代码卖相,让很多人在做代码合并审查时,下意识地放松了警惕。
结果推到测试环境,直接引发了灾难。因为 Hooks 的依赖数组遗漏,再加上复杂的闭包状态未清理,导致后端接口在特定操作下被疯狂死循环请求,测试服务器直接宕机。
这就是摆在我们面前最真实的 P0 级风险:AI 写代码越快,你离线上业务瘫痪可能就越近🤔。
为什么传统的纯人工审查一定会失效?
很多技术主管认为,既然自动化工具有缺陷,我们在 Merge Request(MR) 环节加强人工代码审核不就行了?
这条路根本走不通。致命弱点在于 AI 生成的代码欺骗性太强了😖。
人类大脑在看代码时是存在启发式偏见的。当我们看到一段排版错乱的代码时,会本能地警惕并逐行排查逻辑。但面对格式完美、看似逻辑完全自洽的代码时,大脑的防御机制会自动降级,主观认定这段代码是安全的。
更要命的是产出规模的暴增😢。
以前一个前端开发一天最多产出几百行核心逻辑,现在借助 AI 工具,单日可以提交数千行。面对呈几何倍数增长的 MR,技术负责人的精力根本无力应对,最终一定是被迫疲劳妥协,看两眼没有语法报错就直接通过😢。
单纯依靠人力去审核 AI 的海量产出,注定会被这种低效的协作模式拖垮。
用 AI 校验 AI?
真正高级的工程思维,是懂得转移防御阵地。既然代码是 AI 批量生成的,那校验代码底层逻辑的重任,也必须前置交给 AI🫵。
不要再去人工排查低级的类型推断和语法遗漏,必须把约束前置到 ESLint 和 TypeScript 的最严格模式里。在代码推送到远端代码托管平台之前,直接用本地自动化流水线拦截 AI 产生的幻觉。
下面这段配置,是我们专门针对 AI 编码习惯加入的底层安全防线:
// tsconfig.json
{
"compilerOptions": {
// 严禁为了省事随手生成隐式 any,必须给出确切类型
"noImplicitAny": true,
// 强制处理 null 和 undefined 的边界情况
"strictNullChecks": true,
// 防止捏造不存在的可选属性
"exactOptionalPropertyTypes": true,
// 强制清理未使用的本地变量
"noUnusedLocals": true,
"noUnusedParameters": true
}
}
// eslint.config.js - 针对自动化代码常见漏检的强力规则
module.exports = {
rules: {
// 极容易为了规避警告而乱删依赖数组,必须强制报错阻断
'react-hooks/exhaustive-deps': 'error',
// 防止忘写 await 导致异步状态彻底失控,这是极其常见的低级错误
'@typescript-eslint/no-floating-promises': 'error',
// 拦截随手硬编码的魔法数字
'no-magic-numbers': ['warn', { ignore: [0, 1, -1] }]
}
};
建立这套铁板一块的工程基建去兜底。哪怕工具写得再快,只要踩了团队的安全红线,在提交代码的瞬间就会被拦截报错。人类无需为这种可以被静态分析精准识别的低级错误买单✌️。
AI 最喜欢挖的三个无声陷阱
哪怕过了各种严格的静态检查规则,自动化生成的代码依然隐藏着致命的业务逻辑死角。
在排查了数万行 AI 产出的代码后,我总结了 AI 最爱挖的三个深水区大坑。这也是我们在人工审核阶段真正应该死守的防线。
它会无视弱网与竞态条件🤷♂️
大模型生成的业务逻辑往往是绝对理想主义的。它总是假设网络永远通畅,接口永远毫秒级返回,并且用户的操作总是按部就班的。
比如写一个搜索框的异步模糊匹配请求,它百分之九十会给你这样毫无防御措施的代码:
import { useState, useEffect } from 'react';
import { fetchSearchResults } from '@/api/search';
export const useSearch = (keyword: string) => {
const [results, setResults] = useState([]);
useEffect(() => {
if (!keyword) return;
// 致命缺陷:没有请求防抖,也没有底层请求取消机制
fetchSearchResults(keyword).then(res => {
setResults(res.data);
});
}, [keyword]);
return results;
};
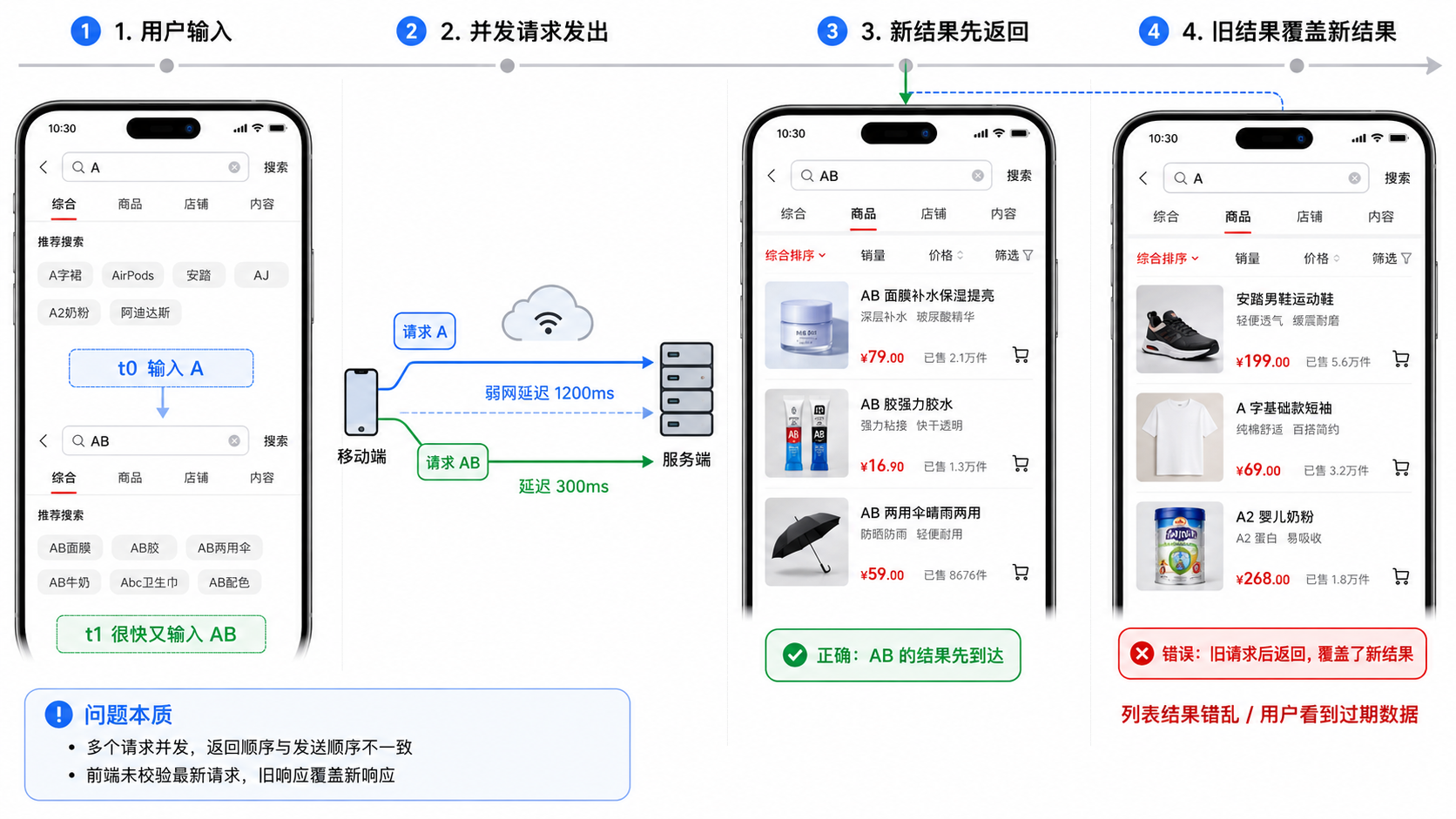
这段代码在开发者的本地极速网络下跑完全没问题。但在实际的移动端弱网环境下,如果用户快速输入 A 后再输入 B,由于网络抖动,A 的响应完全可能比 B 晚到。最后输入框里明明是 AB,但页面列表展示的却是 A 的老数据。(我觉得这种场景大家都遇到过🤷)
资深架构师在审核时,必须强行补全 AbortController 以及完善的异常捕获兜底:
import { useState, useEffect, useRef } from 'react';
import { fetchSearchResults } from '@/api/search';
import { message } from 'antd'; // antd 弹窗组件
// 严格定义返回的数据结构
interface SearchResult {
id: string;
name: string;
}
export const useSearch = (keyword: string) => {
const [results, setResults] = useState<SearchResult[]>([]);
const [loading, setLoading] = useState<boolean>(false);
const debounceTimer = useRef<NodeJS.Timeout | null>(null);
useEffect(() => {
if (!keyword) {
setResults([]);
return;
}
// 必须引入原生的中断控制器,防范竞态
const controller = new AbortController();
// 加入防抖处理,避免对服务端发起高频无效请求
if (debounceTimer.current) clearTimeout(debounceTimer.current);
debounceTimer.current = setTimeout(() => {
setLoading(true);
fetchSearchResults(keyword, { signal: controller.signal })
.then(res => {
if (res?.code === 200) {
setResults(res.data);
} else {
message.error(res?.message || '获取数据失败');
}
})
.catch(err => {
// 忽略被业务主动取消的报错,防止向上抛出未捕获的 Promise 异常
if (err.name === 'AbortError') return;
console.error('搜索接口异常:', err);
message.error('网络发生抖动,请稍后重试');
})
.finally(() => {
setLoading(false);
});
}, 300);
// 组件卸载或 keyword 变化时,立刻掐断上一个仍在进行的请求
return () => {
controller.abort();
if (debounceTimer.current) clearTimeout(debounceTimer.current);
};
}, [keyword]);
return { results, loading };
};
只管挂载不管清理的内存泄漏
AI 生成的代码就像是一个极度缺乏责任心的新人。它特别喜欢使用全局的事件监听或者 WebSocket 长连接操作,但有极高的概率,它会完全忘记在组件生命周期结束时把这些副作用安全地清理掉。
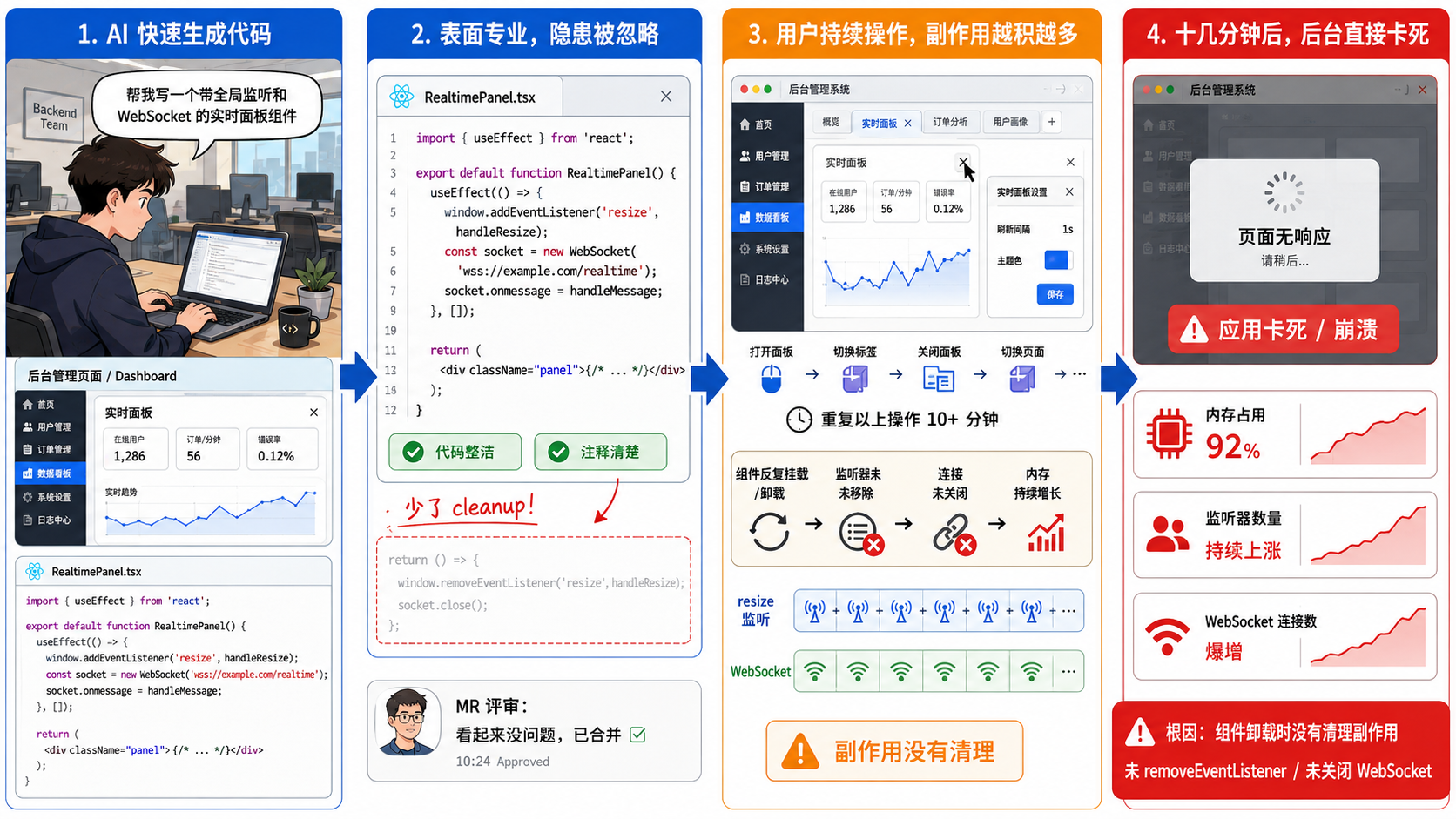
如果不在人工审核阶段把这个隐患揪出来,用户在这个复杂的后台系统里连续操作十几分钟,浏览器的内存栈就会直接被塞满,导致整个应用彻底卡死崩溃。这种动态的内存陷阱,自动化工具很难提前预判,必须靠人工去严防死守:所有的副作用都在组件卸载时彻底清理干净了吗?
为了逻辑自洽而捏造包名, AI 幻觉?
这是最细思极恐的安全隐患。
当 AI 遇到一个复杂的业务算法时,为了让代码看起来简洁且逻辑自洽,它会凭空捏造一个根本不存在的内部方法,甚至是一个完全虚假的 NPM 依赖包。
比如 import { deepMerge } from 'lodash/deepMerge'。这段代码结构看起来极其合理,但 Lodash 库根本没有这种路径导出方式。如果在审核时没有仔细核对第三方依赖项,不仅会导致生产构建打包直接阻断,更可怕的是引入了名称极其相似但实际被注入木马的恶意依赖库,直接导致整个项目的权限大范围暴露,给公司带来毁灭性的打击。
真正的全栈,是做好工程把关人
在这行敲了快十年的代码,见证了从原生开发到 React 再到如今的 AI 编程时代。
作为国内技术团队的负责人,我非常支持大家使用先进的 AI 工具来极速提效。但我们必须重新定义人与 AI 的协作边界。
永远要把这些工具当作一个不知疲倦、极度高产,但极其缺乏真实业务场景和底层安全意识的应届生。
试问,应届实习生刚写完的代码,你能闭着眼睛直接合并发布到线上生产环境吗?
绝对不行的😖🤔。
好了,今天分享到这里🙌


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 5
5 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)