影刀RPA与ChatGPT联动实战:AI+RPA打造智能办公助手
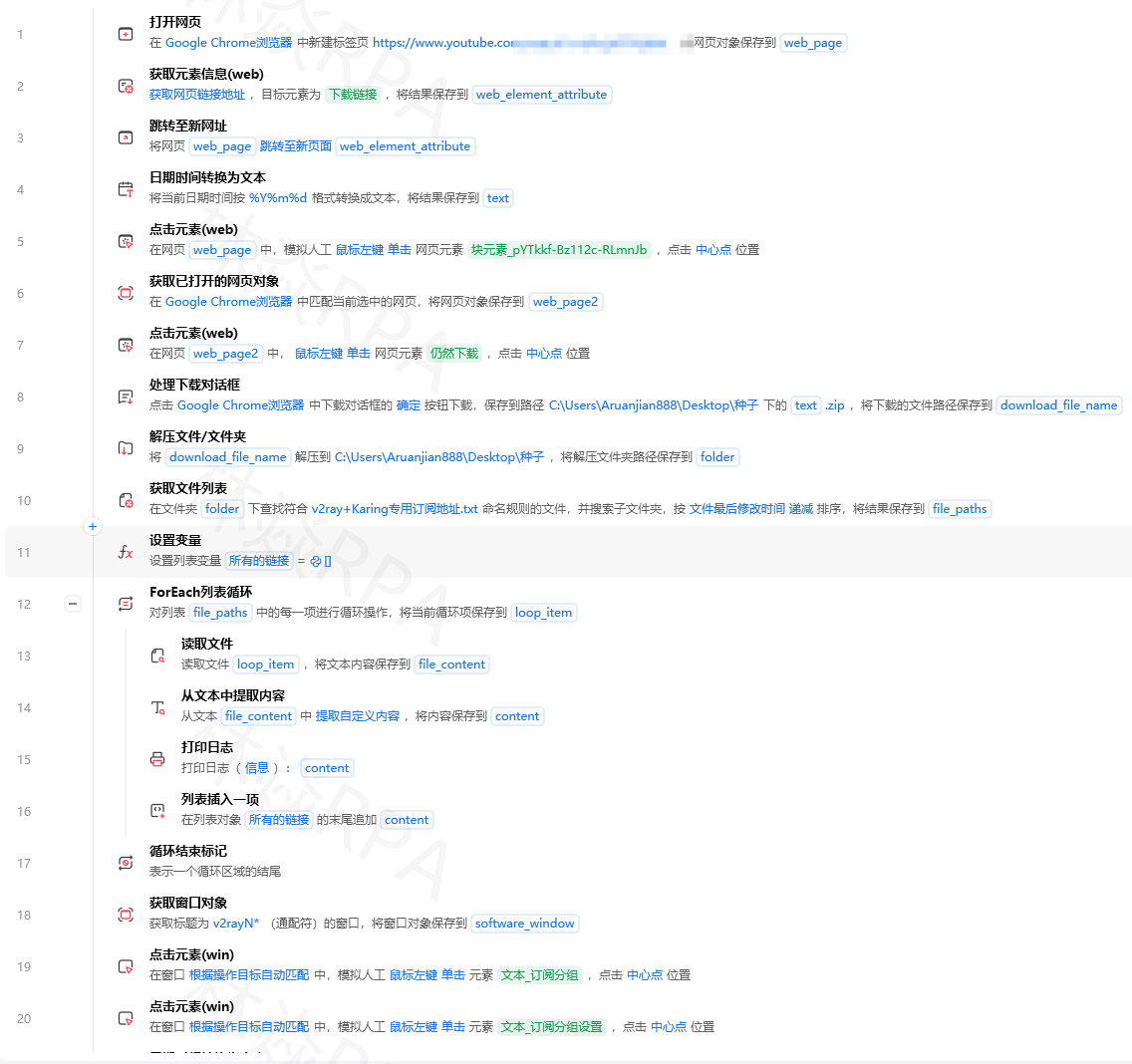
影刀RPA与ChatGPT联动实战:AI+RPA打造智能办公助手
当RPA的自动化能力遇上ChatGPT的智能理解能力,会发生什么?答案是:你的RPA机器人不再只是机械执行指令的工具,而是真正能"理解"内容、"思考"对策、"生成"方案的智能助手。本文手把手教你用影刀RPA对接ChatGPT,实现5个实战场景。
作者:林焱
为什么需要RPA+AI
传统RPA有一个明显短板:只能做"规则明确"的事。遇到需要理解语义、判断意图、生成内容的场景就束手无策了。
举个例子: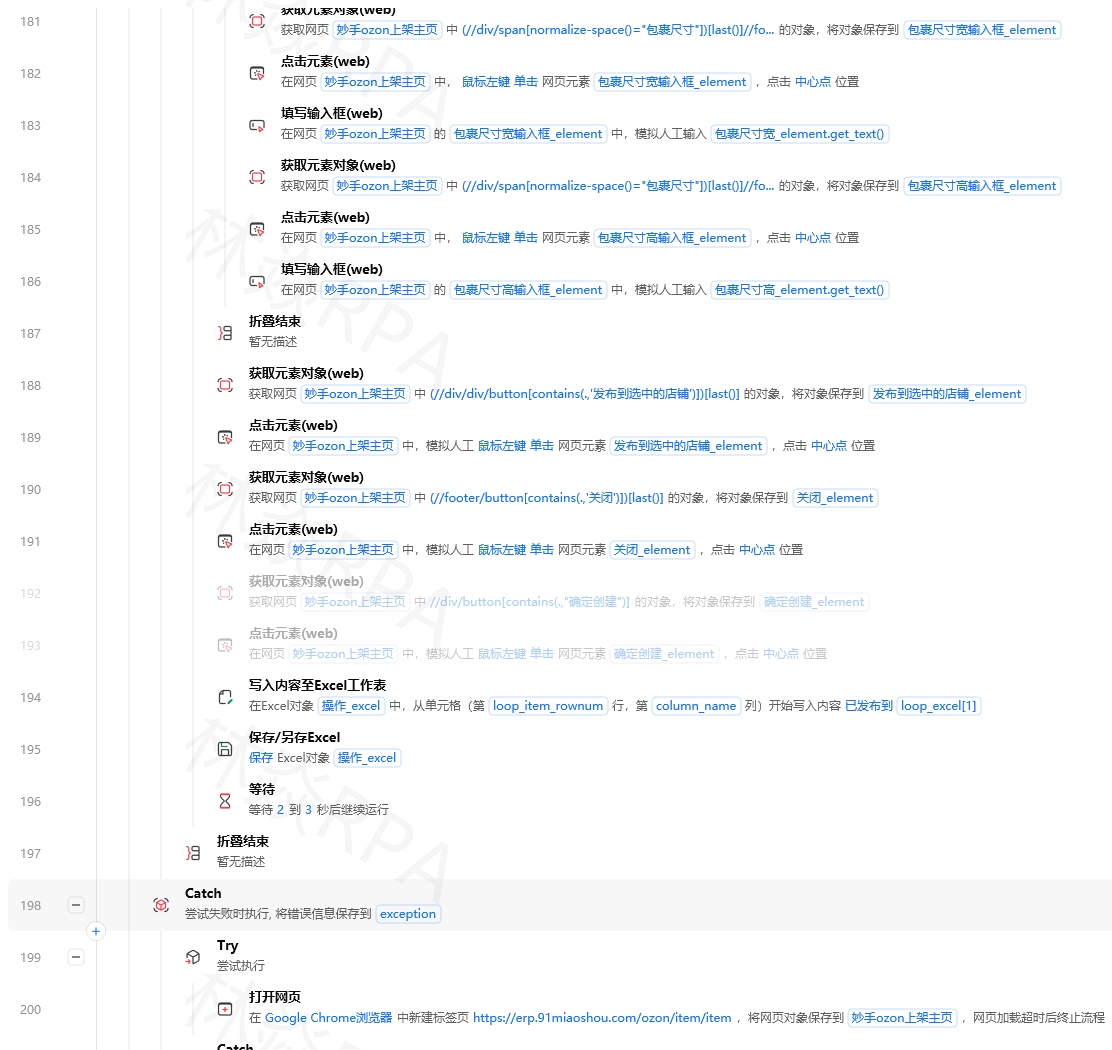
- RPA可以从邮件中提取文本,但无法判断邮件是"投诉"还是"咨询"
- RPA可以采集商品评论,但无法自动分析评论的"情感倾向"
- RPA可以获取会议纪要文本,但无法自动生成"待办事项清单"
接入ChatGPT后,这些都不是问题了。RPA负责"做",AI负责"想"——这就是AI+RPA的核心价值。
对接方案:影刀RPA调用ChatGPT API
方案架构
数据源 → 影刀RPA采集 → 构造Prompt → HTTP请求ChatGPT API → 解析响应 → 后续处理
基础封装函数
先封装一个通用的ChatGPT调用函数,后面所有场景都会用到。
# 影刀RPA Python代码块 - ChatGPT API调用封装
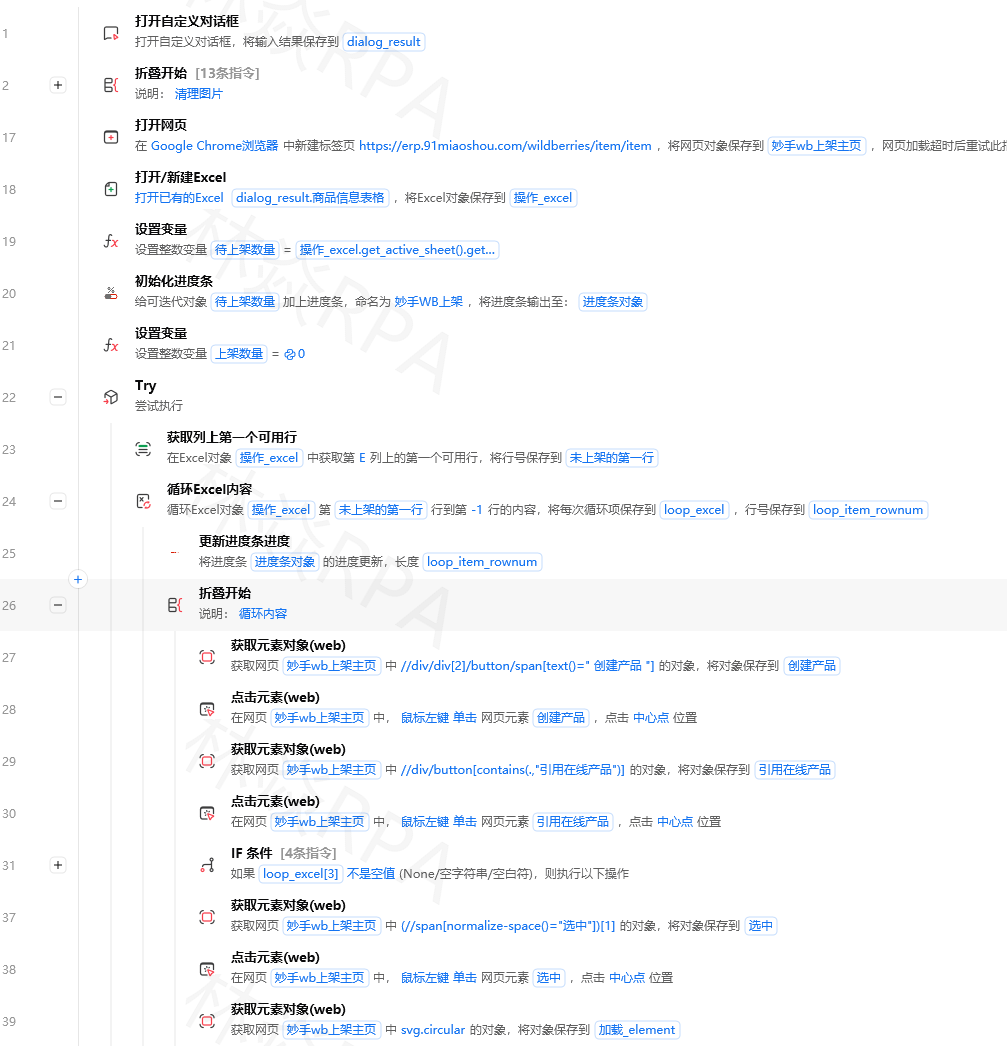
import json
import requests
def call_chatgpt(messages, model="gpt-3.5-turbo", temperature=0.7, max_tokens=2000):
"""
调用ChatGPT API的通用函数
参数:
messages: 对话消息列表 [{"role": "system/user/assistant", "content": "..."}]
model: 模型名称
temperature: 创造性参数(0-2,越高越随机)
max_tokens: 最大返回token数
"""
api_key = "your-api-key" # 建议从配置文件读取
url = "https://api.openai.com/v1/chat/completions"
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {api_key}"
}
payload = {
"model": model,
"messages": messages,
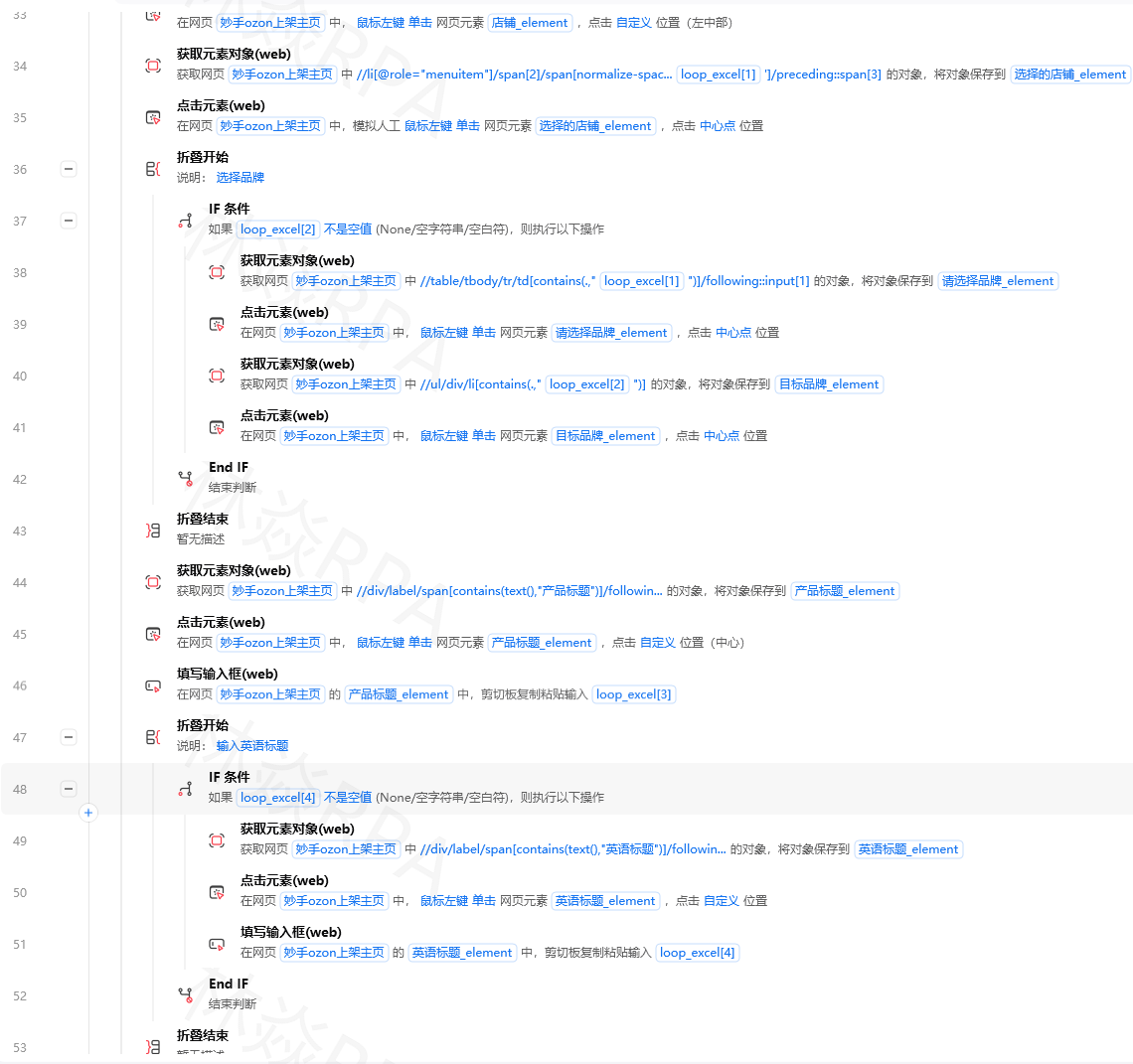
"temperature": temperature,
"max_tokens": max_tokens
}
try:
response = requests.post(url, headers=headers, json=payload, timeout=60)
response.raise_for_status()
result = response.json()
return result["choices"][0]["message"]["content"]
except requests.exceptions.Timeout:
return "错误:请求超时"
except requests.exceptions.RequestException as e:
return f"错误:{str(e)}"
# 简化版:单次提问
def ask_chatgpt(prompt, system_prompt="你是一个专业的办公助手。"):
"""单次提问,快速获取回答"""
messages = [
{"role": "system", "content": system_prompt},
{"role": "user", "content": prompt}
]
return call_chatgpt(messages)
安全提示
API Key千万不要硬编码在代码里! 建议使用影刀RPA的配置文件管理功能:
# 从配置文件读取API Key
import json
def get_api_key():
with open("D:\\RPA配置\\api_config.json", "r", encoding="utf-8") as f:
[video(video-0mUgoBZc-1781675974856)(type-csdn)(url-https://live.csdn.net/v/embed/526818)(image-https://v-blog.csdnimg.cn/asset/582d14c3bd0451c5399cd990b56e2a0d/cover/Cover0.jpg)(title-拼多多店群自动化报活动上架!)]
config = json.load(f)
return config["openai_api_key"]
实战场景一:智能邮件分类与自动回复
场景描述
每天收到几十封客户邮件,手动分类再回复太耗时间。用RPA读取邮件→AI分类→自动生成回复→人工确认后发送。
完整实现
# 步骤1:RPA读取未读邮件
import win32com.client
outlook = win32com.client.Dispatch("Outlook.Application")
namespace = outlook.GetNamespace("MAPI")
inbox = namespace.GetDefaultFolder(6)
messages = inbox.Items.Restrict("[Unread]=True")
for msg in messages:
subject = msg.Subject
body = msg.Body
sender = msg.SenderEmailAddress
# 步骤2:AI分类
classify_prompt = f"""
请将以下邮件分类到以下类别之一:
- 投诉:客户不满、要求赔偿、威胁投诉监管部门
- 咨询:询问产品功能、价格、使用方法
- 合作:商务合作、渠道代理、投资意向
- 技术:Bug反馈、功能异常、部署问题
- 其他
邮件主题:{subject}
邮件内容:{body[:500]}
请只输出类别名称,不要其他内容。
"""
category = ask_chatgpt(classify_prompt).strip()
# 步骤3:AI生成回复草稿
reply_prompt = f"""
你是客服经理,收到一封"{category}"类邮件。
请生成专业、礼貌的回复。
发件人:{sender}
主题:{subject}
内容:{body[:1000]}
要求:
- 语气专业友好
- 针对具体问题回复
- 如需转交,说明后续处理流程
- 200字以内
"""
reply_content = ask_chatgpt(reply_prompt)
# 步骤4:创建回复草稿(不自动发送,人工确认)
reply = msg.Reply()
reply.Body = reply_content
reply.Save() # 保存到草稿箱
# 步骤5:标记分类(移动到对应文件夹)
folder_map = {
"投诉": "投诉处理",
"咨询": "客户咨询",
"合作": "商务合作",
"技术": "技术支持",
"其他": "其他"
}
target_folder = inbox.Folders(folder_map.get(category, "其他"))
msg.Move(target_folder)
print(f"✅ 分类:{category} | 主题:{subject}")
实战场景二:商品评论情感分析
场景描述
电商运营需要了解用户对产品的真实评价。用RPA批量采集评论→AI分析情感→自动生成分析报告。
完整实现
# 步骤1:RPA采集商品评论
def scrape_reviews(product_url, max_pages=5):
"""采集商品评论"""
reviews = []
web.open(product_url)
for page in range(max_pages):
# 获取评论列表
comment_elements = web.find_elements(".comment-item")
for elem in comment_elements:
review = {
"用户": web.get_text(".user-name", elem),
"评分": web.get_text(".score", elem),
"内容": web.get_text(".comment-text", elem),
"日期": web.get_text(".comment-date", elem),
}
reviews.append(review)
# 翻页
if not web.click(".next-page"):
break
return reviews
# 步骤2:批量情感分析
def analyze_sentiment_batch(reviews, batch_size=10):
"""批量分析评论情感"""
results = []
for i in range(0, len(reviews), batch_size):
batch = reviews[i:i+batch_size]
# 构造批量分析Prompt
reviews_text = "\n".join([
f"{j+1}. {r['内容']}"
for j, r in enumerate(batch)
])
prompt = f"""
请分析以下{len(batch)}条商品评论的情感倾向。
对每条评论,输出:
1. 情感:正面/中性/负面
2. 关键词:提取2-3个关键词
3. 痛点(仅负面评论):用户不满的具体原因
评论列表:
{reviews_text}
请用JSON格式输出:
[
{{"id": 1, "sentiment": "正面/中性/负面", "keywords": ["关键词1", "关键词2"], "pain_point": ""}},
...
]
"""
analysis = ask_chatgpt(prompt, temperature=0.3)
try:
parsed = json.loads(analysis)
for j, item in enumerate(parsed):
batch[j]["情感"] = item.get("sentiment", "未知")
batch[j]["关键词"] = ", ".join(item.get("keywords", []))
batch[j]["痛点"] = item.get("pain_point", "")
except json.JSONDecodeError:
for r in batch:
r["情感"] = "解析失败"
r["关键词"] = ""
r["痛点"] = ""
results.extend(batch)
return results
# 步骤3:生成分析报告
def generate_report(analyzed_reviews, product_name):
"""生成情感分析报告"""
# 统计
total = len(analyzed_reviews)
positive = sum(1 for r in analyzed_reviews if r["情感"] == "正面")
neutral = sum(1 for r in analyzed_reviews if r["情感"] == "中性")
negative = sum(1 for r in analyzed_reviews if r["情感"] == "负面")
# 提取负面痛点
pain_points = [r["痛点"] for r in analyzed_reviews if r["痛点"]]
# AI生成总结
summary_prompt = f"""
请根据以下数据分析报告生成一份专业的产品评论分析报告:
产品:{product_name}
总评论数:{total}
正面评论:{positive}条({positive/total*100:.1f}%)
中性评论:{neutral}条({neutral/total*100:.1f}%)
负面评论:{negative}条({negative/total*100:.1f}%)
主要痛点:{'; '.join(pain_points[:5])}
请包含:
1. 整体评价概述
2. 用户满意点
3. 需要改进的问题
4. 改进建议
"""
report = ask_chatgpt(summary_prompt, temperature=0.5)
# 写入报告文件
with open(f"D:\\评论分析\\{product_name}_情感分析报告.md", "w", encoding="utf-8") as f:
f.write(f"# {product_name} 评论情感分析报告\n\n")
f.write(f"**分析时间**:{datetime.now().strftime('%Y-%m-%d %H:%M')}\n\n")
f.write(f"**数据概览**:共{total}条评论,正面{positive}条,中性{neutral}条,负面{negative}条\n\n")
f.write(report)
return report
# 主流程
product_url = "https://item.jd.com/12345678.html"
reviews = scrape_reviews(product_url)
analyzed = analyze_sentiment_batch(reviews)
report = generate_report(analyzed, "智能手表Pro")
实战场景三:智能文档摘要生成
场景描述
每天要处理大量长文档——合同、报告、论文,手动阅读耗时巨大。用RPA读取文档→AI生成摘要→快速了解核心内容。
完整实现
# 影刀RPA + ChatGPT 文档摘要系统
def summarize_document(file_path, summary_type="详细"):
"""智能文档摘要"""
# 步骤1:读取文档内容
if file_path.endswith(".docx"):
from docx import Document
doc = Document(file_path)
text = "\n".join([p.text for p in doc.paragraphs])
elif file_path.endswith(".pdf"):
import fitz # PyMuPDF
pdf = fitz.open(file_path)
text = "\n".join([page.get_text() for page in pdf])
elif file_path.endswith(".txt") or file_path.endswith(".md"):
with open(file_path, "r", encoding="utf-8") as f:
text = f.read()
else:
return "不支持的文件格式"
# 步骤2:处理长文档(分段摘要)
max_chunk = 3000 # 每段最大字符数
chunks = [text[i:i+max_chunk] for i in range(0, len(text), max_chunk)]
if len(chunks) == 1:
# 短文档直接摘要
prompt = f"请对以下文档生成{summary_type}摘要:\n\n{text[:3000]}"
return ask_chatgpt(prompt)
else:
# 长文档分段摘要再合并
chunk_summaries = []
for i, chunk in enumerate(chunks):
prompt = f"这是文档的第{i+1}/{len(chunks)}部分,请生成摘要:\n\n{chunk}"
summary = ask_chatgpt(prompt, temperature=0.3)
chunk_summaries.append(summary)
# 合并所有段落的摘要
combined = "\n\n".join(chunk_summaries)
final_prompt = f"以下是文档各部分的摘要,请整合为一份完整的{summary_type}摘要:\n\n{combined}"
return ask_chatgpt(final_prompt, temperature=0.3)
# 批量处理文件夹中的文档
import os
doc_dir = "D:\\待处理文档\\"
for filename in os.listdir(doc_dir):
if filename.endswith((".docx", ".pdf", ".txt")):
filepath = os.path.join(doc_dir, filename)
summary = summarize_document(filepath, "详细")
# 保存摘要
summary_file = f"D:\\文档摘要\\{filename}_摘要.md"
with open(summary_file, "w", encoding="utf-8") as f:
f.write(f"# {filename} 摘要\n\n{summary}")
print(f"✅ 已生成摘要:{filename}")
实战场景四:智能数据录入校验
场景描述
从各种渠道收集的客户信息需要录入系统,但数据格式混乱、可能有错误。用AI来智能校验和修正。
完整实现
# 影刀RPA + ChatGPT 智能数据校验
def validate_and_correct(record):
"""AI智能校验数据记录"""
prompt = f"""
请校验以下客户数据记录,检查并修正错误:
原始数据:
{json.dumps(record, ensure_ascii=False, indent=2)}
检查项:
1. 姓名格式是否正确(2-4个中文字符)
2. 手机号是否有效(11位,1开头)
3. 邮箱格式是否正确
4. 地址是否完整(省-市-区-详细地址)
5. 公司名称是否规范(去除多余空格、统一格式)
请输出JSON格式的校验结果:
{{
"is_valid": true/false,
"errors": ["错误描述1", "错误描述2"],
"corrected_data": {{修正后的完整数据}},
"confidence": 0.0-1.0
}}
"""
result = ask_chatgpt(prompt, temperature=0.2) # 低temperature保证准确性
try:
return json.loads(result)
except json.JSONDecodeError:
return {"is_valid": False, "errors": ["AI返回格式错误"], "corrected_data": record, "confidence": 0}
# 批量校验
import pandas as pd
df = pd.read_excel("客户数据_待校验.xlsx")
validated_records = []
for _, row in df.iterrows():
record = row.to_dict()
result = validate_and_correct(record)
if result["is_valid"]:
# 校验通过,使用修正后的数据
validated_records.append(result["corrected_data"])
else:
# 校验失败,标记问题
record["校验状态"] = "异常"
record["问题描述"] = "; ".join(result["errors"])
validated_records.append(record)
# 输出校验结果
result_df = pd.DataFrame(validated_records)
result_df.to_excel("客户数据_已校验.xlsx", index=False)
实战场景五:智能报表解读
场景描述
每周要给领导发报表,但纯数字报表领导看不懂。用AI自动生成"人话版"的报表解读。
完整实现
# 影刀RPA + ChatGPT 智能报表解读
def generate_report_narrative(excel_path, sheet_name="Sheet1"):
"""将Excel报表转为自然语言解读"""
import pandas as pd
df = pd.read_excel(excel_path, sheet_name=sheet_name)
# 步骤1:提取关键数据统计
stats = {
"行数": len(df),
"列名": list(df.columns),
"数值列统计": {}
}
for col in df.select_dtypes(include=["number"]).columns:
stats["数值列统计"][col] = {
"总和": round(df[col].sum(), 2),
"平均值": round(df[col].mean(), 2),
"最大值": round(df[col].max(), 2),
"最小值": round(df[col].min(), 2),
}
# 步骤2:AI生成解读
prompt = f"""
你是数据分析顾问。请根据以下数据统计生成一份通俗易懂的报表解读。
数据概况:
- 总记录数:{stats['行数']}
- 字段:{stats['列名']}
- 数值统计:{json.dumps(stats['数值列统计'], ensure_ascii=False)}
要求:
1. 用通俗易懂的语言描述数据整体情况
2. 指出关键趋势和异常值
3. 给出业务建议
4. 300字以内,分段落,重点加粗
"""
narrative = ask_chatgpt(prompt, temperature=0.6)
# 步骤3:组装完整报告
report = f"""
# 周报解读 - {datetime.now().strftime('%Y年第%W周')}
## 数据概览
- 总记录数:{stats['行数']}条
- 数据字段:{', '.join(stats['列名'])}
## 智能解读
{narrative}
## 关键数据
| 指标 | 总和 | 平均值 | 最大值 | 最小值 |
|------|------|--------|--------|--------|
"""
for col, values in stats["数值列统计"].items():
report += f"| {col} | {values['总和']} | {values['平均值']} | {values['最大值']} | {values['最小值']} |\n"
# 步骤4:自动发送
send_email(
to="boss@company.com",
subject=f"周报解读 - {datetime.now().strftime('%Y年第%W周')}",
body=report
)
return report
成本控制与优化建议
ChatGPT API是按Token计费的,批量处理时要注意控制成本:
1. 控制输入长度
# 截断过长的文本
def truncate_text(text, max_chars=2000):
if len(text) > max_chars:
return text[:max_chars] + "...(内容已截断)"
return text
2. 使用更便宜的模型
# 简单任务用GPT-3.5,复杂任务用GPT-4
def smart_call(prompt, complexity="simple"):
model = "gpt-3.5-turbo" if complexity == "simple" else "gpt-4"
return call_chatgpt([{"role": "user", "content": prompt}], model=model)
3. 缓存结果
TEMU店群矩阵自动化运营核价报活动
# 对相同输入缓存结果,避免重复调用
import hashlib
import json
cache = {}
def cached_ask(prompt, system_prompt="你是一个专业的办公助手。"):
cache_key = hashlib.md5(f"{system_prompt}:{prompt}".encode()).hexdigest()
if cache_key in cache:
return cache[cache_key]
result = ask_chatgpt(prompt, system_prompt)
cache[cache_key] = result
return result
4. 批量处理
# 将多条记录合并成一次请求
def batch_process(items, prompt_template):
"""批量处理,减少API调用次数"""
batch_text = "\n".join([f"{i+1}. {item}" for i, item in enumerate(items)])
prompt = prompt_template.format(count=len(items), items=batch_text)
return ask_chatgpt(prompt, temperature=0.2)
常见问题
Q:ChatGPT API访问不稳定怎么办?
国内访问OpenAI API可能不稳定,建议:
- 使用稳定的代理服务
- 设置合理的超时时间和重试机制
- 考虑使用国内大模型API替代(如通义千问、文心一言),接口兼容
Q:AI生成的内容不准确怎么办?
AI输出存在"幻觉"问题,建议:
- 对关键数据做二次校验
- 使用较低的temperature参数(0.2-0.3)
- 在Prompt中明确要求"只基于提供的信息回答"
- 重要场景采用"AI生成→人工确认"的流程
Q:处理速度慢怎么办?
ChatGPT API单次请求通常需要2-5秒。对于批量处理:
- 使用异步并发请求
- 适当增大batch_size,减少请求次数
- 使用更快的模型(gpt-3.5-turbo比gpt-4快3-5倍)
总结
影刀RPA + ChatGPT的联动,本质上是在RPA的自动化流程中嵌入"AI大脑",让机器人从"只会执行"进化为"能理解、会判断、可生成"。
5个实战场景覆盖了最常见的AI+RPA应用:
- 智能邮件分类:理解语义,自动归类
- 评论情感分析:批量分析用户情绪
- 文档摘要生成:长文档快速阅读
- 数据录入校验:智能纠错,提高数据质量
- 报表智能解读:数据变人话,领导看得懂
核心原则:RPA负责干活,AI负责动脑,人负责把关。
作者:林焱 | 如果这篇文章对你有帮助,欢迎点赞收藏,关注我获取更多RPA自动化教程

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 13
13 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)