深度学习与机器学习算法:损失函数设计-分类任务(1)
本篇文章讲一讲机器学习和深度学习模型算法常用的交叉熵损失,它的变形,以及常见应用场景和pytorch的代码适配情况(部分),很多都是自己做实践做项目和学习过程中的心得总结与经验分享,希望大家认真阅读。
开头之前先讲一讲Kimi非常务实,严格按照我给的生图指令,最后逗得我哈哈一笑。
目录
讨论1:关于具身智能中的Policy Model的输出(我 VS Deepseek)
4. 只含静态权重分配(αk)的多分类 Focal Loss(即 γ=0)(批量平均)
5. 只含 γ 系数(无类别权重)的多分类 Focal Loss(批量平均)
讨论2:关于Focal Loss在SAM相关模型和语义分割任务中的使用和发展情况(我 VS Deepseek)
6. 同时含类别权重 αk 和共享 γ 系数的多分类 Focal Loss(批量平均)
7. 标签平滑(Label Smoothing)后的多分类交叉熵损失(批量平均)
关于nn.CrossEntropy的默认设定(重要!影响损失估值和梯度反传)
参考文章
符号和变量说明
单样本形式的符号约定
- 二分类:真实标签 y∈{0,1},正类预测概率 p=sigmoid(z)
- 多分类:类别数 K,真实 one‑hot 标签 yk∈{0,1},预测概率 pk=softmax(zk)
- 正类权重w1,负类权重 w0;多分类静态权重 αk(αk>0)
- Focal Loss 调制因子指数 γ≥0;标签平滑参数 ε∈[0,1]
MBGD/BGD批量训练形式的符号约定
- 真实标签为 one‑hot 向量 ys,k∈{0,1},且
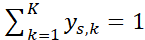
- 模型输出的概率为 ps,k(由 softmax 或 sigmoid 得到)
- 二分类时,
 ,
,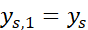 ,
,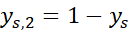 ,
,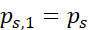 ,
,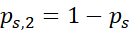
所有损失均以 单个样本的损失之和再除以批量大小 B![]() 给出,即:
给出,即:
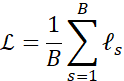
其中 ![]() 为内层对类别求和所得的样本损失。
为内层对类别求和所得的样本损失。
分类任务常用的损失函数(我总结出7大类)
1. 二分类 BCE 交叉熵损失基本公式(批量平均)
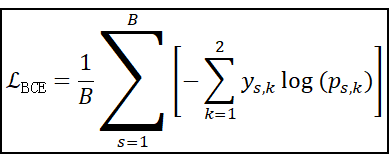
等价于常见的
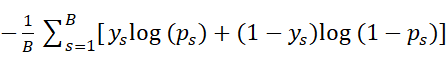
应用场景:简单的二分类任务,比如垃圾邮件分类箱、只有唯一人脸权限的密室准入人脸识别系统、特定时期特定行业股市行情是上涨还是下跌、特定场景的异常检测与简单模式识别(是否有人溺水、这个人是不是在走路)等等。
2. 加权二分类 BCE 损失公式(批量平均)
设正类权重为 w1,负类权重为 w0,则:
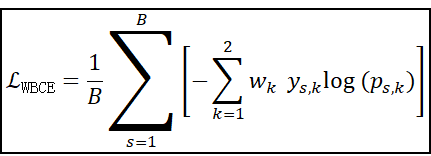
应用场景:总的来说就是对于信息分布不均衡的数据分类任务设计的,对于信息量不足的异常类别或者小概率类别,需要提升其在分类损失函数中的权重占比,从而让模型更能关注到这些样本。
相关评估指标其实还有P准确率、R召回率、F1-Score(或者Dice系数)(![]() ,值域[0,1])、IoU交并比(或者Jaccard系数)(
,值域[0,1])、IoU交并比(或者Jaccard系数)(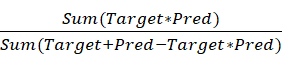 )。
)。
在医疗领域的医疗图像病变区域实例分割任务中,损失函数除了使用BCE,也可以设计成1-Dice_Coefficient的形式,通过最小化损失函数提升图像实例分割质量。在蛋白序列设计领域的蛋白序列突变或者结合位点检测的场景中,也可以设计一个用到BCE加权二分类交叉熵损失的任务。
但在合成生物学的蛋白序列同义密码子优化领域,训练一般使用接下来讲到的多分类CrossEntropy函数,评估也可以用到Jaccard系数。
3. 多分类交叉熵损失(CE)公式(批量平均)
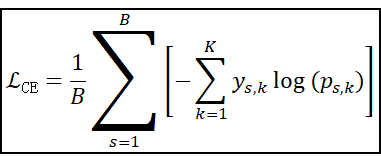
应用场景:经典的图像多分类任务(如经典的MNIST、FASHION_MNIST、CIFAR10、CIFAR100、ImageNet-1000等分类任务)、多模式/动作识别(比如你设计了一个和AI石头剪刀布的游戏,让AI总是输给你,你的成功率达到了100%,因为AI反应速度很快,你可能察觉不到这一点)、同义密码子优化、NLP自然语言处理、含有多个人脸注册信息的门禁系统等。
讨论1:关于具身智能中的Policy Model的输出(我 VS Deepseek)
📝 离散动作空间:可以理解为分类任务
当策略模型将电机控制指令限定在有限的、预先定义好的集合中时,其输出就是离散的。在这种情况下,可以将其视作一个分类任务。
- 工作方式:模型将每个离散动作看作一个独立的“类别”,通过分类器(如Softmax)输出属于各个动作类别的概率,并选择概率最高的那个来执行。
- 实际应用:这种方法在现实中很常见。例如,使用VQ-VAE变分自编码器等技术将连续动作空间离散化为有限的隐动作空间,或用Transformer以Auto Regressive自回归方式逐token生成离散动作。
- 优缺点:优点是问题简化,利于学习和训练;缺点是控制粗糙,无法实现精细操作。
🎛️ 连续动作空间:不能理解为分类任务
在更复杂的场景中,电机控制需要输出连续值,如精确的关节角度、力矩或速度。这时,它本质上是一个回归任务。
- 工作方式:模型直接输出一个向量(如7个关节的目标角度),这些值是连续的浮点数。
- 常见做法:主流方法如扩散策略(Diffusion Policy)和流匹配(Flow Matching),都是为生成连续动作而设计的。
- 优缺点:优点是控制精度高,能完成复杂操作;缺点是学习难度大,对数据和质量要求高。
4. 只含静态权重分配(αk)的多分类 Focal Loss(即 γ=0)(批量平均)
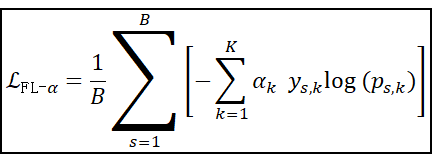
对于信息分布较不均匀的多分类任务可以使用。目前暂时没有想到具体的例子。
5. 只含 γ 系数(无类别权重)的多分类 Focal Loss(批量平均)
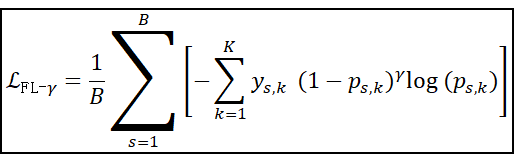
其实算是一种动态加权的多分类CE损失,如果说第4部分是算法工程师静态设定的数值,那么第5部分的γ系数通过在训练过程中对各个分类结果做非线性缩放损失,直接迫使CNN、ViT、LSTM、Transformer等模型关注到难分类的样本,好处是这种动态设定对于实际训练中的引导更有帮助,不需要人工设定,而静态设定很依赖于具体数据集的形式由算法工程师手动设定。
应用场景:语义分割任务,对于很多的、不同的类别不太方便指定静态权重,这个时候使用动态的Focal Loss往往取得更好的结果。其实现在很多更复杂的任务都是多个损失函数一起使用,比如【加权多分类CE+Dice Coefficient+Focal Loss(非线性系数gamma也可动态调整,相当于二级动态效果叠加)】。
讨论2:关于Focal Loss在SAM相关模型和语义分割任务中的使用和发展情况(我 VS Deepseek)
SAM模型训练时并未使用Focal Loss,主要采用的是BCE Loss。然而,许多基于SAM的改进工作都引入了Focal Loss来处理类别不平衡问题。
🧬 SAM系列模型中的应用
- Iris-SAM (虹膜分割):在微调SAM时引入Focal Loss,解决了虹膜像素与非虹膜像素的类别不平衡问题。实验证明,其效果优于Dice Loss和Triplet Loss。
- ResSAM (睑板腺分割):针对传统SAM的不足进行改进,采用了Focal Loss和Smooth IoU Loss的组合来优化训练。
- Co2SAM (弱监督语义分割):在其网络中明确使用了Focal Loss、Contrast Loss、Dice Loss和Template Loss的组合。
- Crack SAM (裂缝检测):在对比实验中,使用了Focal Loss、DiceCELoss和DiceFocalLoss对SAM进行微调。其中,DiceFocalLoss(Dice Loss与Focal Loss的结合)表现最佳。
🎯 更广泛的语义分割应用
Focal Loss因其处理数据不平衡和难易样本的能力,已成为语义分割领域的通用工具。
- 经典与骨干网络:如U-Net、DeepLabv3+、SegFormer等模型,都通过引入Focal Loss提升了分割精度。
- 特定场景应用:
- 遥感与农业:用于无人机桥梁点云分割、棉花生长状态分割等任务。
- 医学图像:用于脑肿瘤分割、磁瓦分割等。
- 工业与基础设施:用于路面裂缝检测等。
⚙️ 围绕 γ 的创新
研究者也在 γ 参数基础上做了许多创新:
- 自适应Focal Loss (A-FL):动态调整参数,更聚焦于小或不规则形状的困难样本。
- 像素级调制Focal Loss (APMFL):在像素级别上动态调整聚焦程度,以应对极度不平衡的数据。
- 类别频率感知Focal Loss (CFL):根据类别出现频率应用非线性权重,增强对 minority 类的学习。
- 统一Focal Loss:将Dice Loss和基于交叉熵的损失泛化,统一处理医学图像分割中的类别不平衡问题。
6. 同时含类别权重 αk 和共享 γ 系数的多分类 Focal Loss(批量平均)
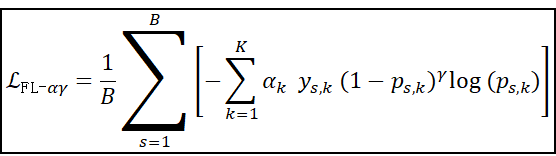
这个损失函数是完整版的Focal Loss损失函数形式,兼顾了静态设定的类别权重α和在训练任务中动态调整模型关注点的非线性γ系数。这个时候其实可以类比Transformer的头自注意力机制了。
7. 标签平滑(Label Smoothing)后的多分类交叉熵损失(批量平均)
平滑后的目标分布为:
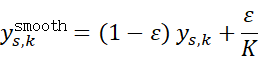
则损失为:
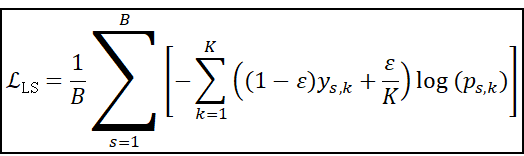
最后一个损失函数比较有意思,是我在看其他博主写的(参考文献(1))的时候看到的,关于nn.CrossEntropy()的实现,其实默认是平均处理过了的,同时可以传入label_smoothing参数,主要可以在以下三种情形使用:
- 数据有噪声时:作为对抗标签错误的缓冲。
- 类别模糊时:帮助模型学习更平滑的决策边界。
- 追求更强泛化性和多样性时:作为一项基础的正则化技术,与其他方法结合使用。在提示微调 (Prompt Tuning)领域,最新的研究(如ATLaS方法)探索将标签平滑用于提示微调,以增强模型对提示的泛化能力。
关于nn.CrossEntropy的默认设定(重要!影响损失估值和梯度反传)
默认情况下torch.nn的交叉熵损失采用的是批量内平均损失,输出标量,如果reduction:str=‘none’,返回向量,就需要调用l.mean().backward()转化成标量然后BP;如果reduction:str=‘sum’,返回标量和,BP前记得除以batchsize;如果reduction:str=‘mean’(默认设定),返回标量平均,直接调用l.backward()进行梯度反向传播就可以了。
如果遇到batch_sampler非均匀的情况(drop_last=False最后有一部分可能不足一个批量的样本,但这部分情况不在我说的这种情况内,因为影响不大)就需要按照样本来计算总损失和平均损失,这个时候就需要注意默认的mean要乘以len(labels)才是准确结果。
典型的例子在NLP或者语音处理任务中,长序列和短序列批量输入可以通过定制dataloader的batch_sampler来实现输入体量的均衡化。
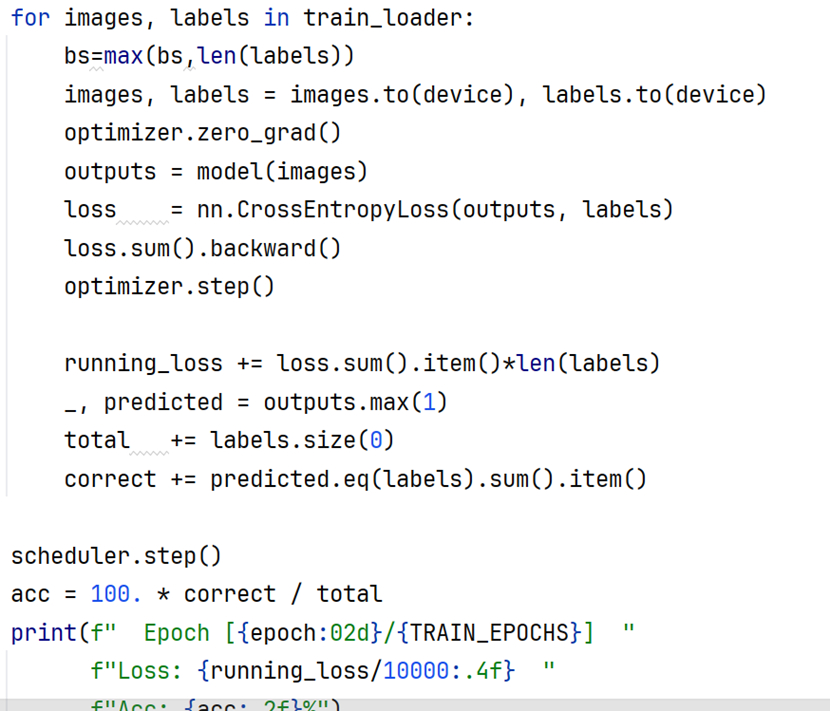
单轮模型训练的通用写法(指定数据迭代器、模型、损失函数、训练优化器、学习率调度器)
nn.CrossEntropy还支持传入weight(tensor)、label_smooth(float)参数。
此外,torch.nn库现在并不支持原生的Focal Loss损失函数版本,需要自行封装实现。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 11
11 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)