昇腾AutoFuse算子自动融合,在推荐领域的性能优化实践
作者:昇腾实战派
知识地图:https://blog.csdn.net/Lumos_Lovegood/article/details/161601003
0 前言
为了有效处理高维稀疏的用户和物品特征,并通过非线性建模捕捉复杂的交互关系,推荐系统(gitcode.com)模型普遍采用 Embedding + MLP 架构。Embedding(嵌入)将高维稀疏的离散特征(用户ID、商品ID、类别等)映射为低维稠密向量,便于深度神经网络进行处理。MLP(Multilayer Perceptron,多层感知机) 是一种经典的前馈神经网络。它通过对输入特征进行非线性组合,学习高阶交互并预测评分,一般由多个全连接层(Fully Connected Layers)堆叠而成,每层通常包含线性变换 + 非线性激活函数(如 ReLU)。Embedding + MLP 架构包含大量轻量级算子(如 Add、ReLU、LayerNorm 等),这些算子在特征处理中频繁出现,形成高密度、低计算强度的子图。由于数据依赖紧密但计算量小,若单独执行会导致频繁调度与中间结果读写,严重拖累性能。
传统手工融合方法依赖预定义模式或手写内核,需要定制开发融合算子,难度和工作量大,且难以覆盖复杂多变的模型结构,尤其在面对长尾结构时可维护性和适应性差。在 NPU 等异构硬件上,还需兼顾硬件并行性和带宽特性,使手工优化更加困难。
因此,昇腾提出AutoFuse自动融合框架,一种具备结构泛化能力的自动融合机制,能在图级别自动识别可融合子图,并生成适配 NPU 架构的高效执行路径,从而显著提升推荐系统性能。
1 简介
AutoFuse(www.hiascend.com)是基于Ascend C的自动融合框架,支持自动融合范围识别、自动算子代码生成、Auto Tiling优化、动态shape及混合精度等特性;在算法网络中,由于存在大量的Vector计算,各个Vector计算之间会产生大量的内存搬运,导致Memory Bound问题。而AutoFuse通过自动将多个算子融合为一个算子,减少网络中的算子数量和内存搬运,从而缓解了Memory Bound问题,释放昇腾算力,提升模型的执行性能。以ETA网络为例,通过自动融合开启前后的profiling比较可以看出,算子耗时下降35.4%。
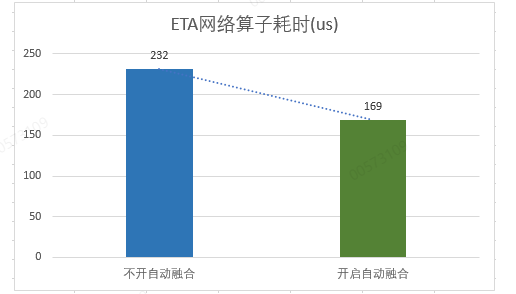
收益原理如下图所示,自动融合通过将多个算子合并为单个算子,理论上在MTE搬运、动态Shape调度开销都会有一定的受益,对于小shape、MTE bound的推荐网络,一般都能获得不错的优化效果。
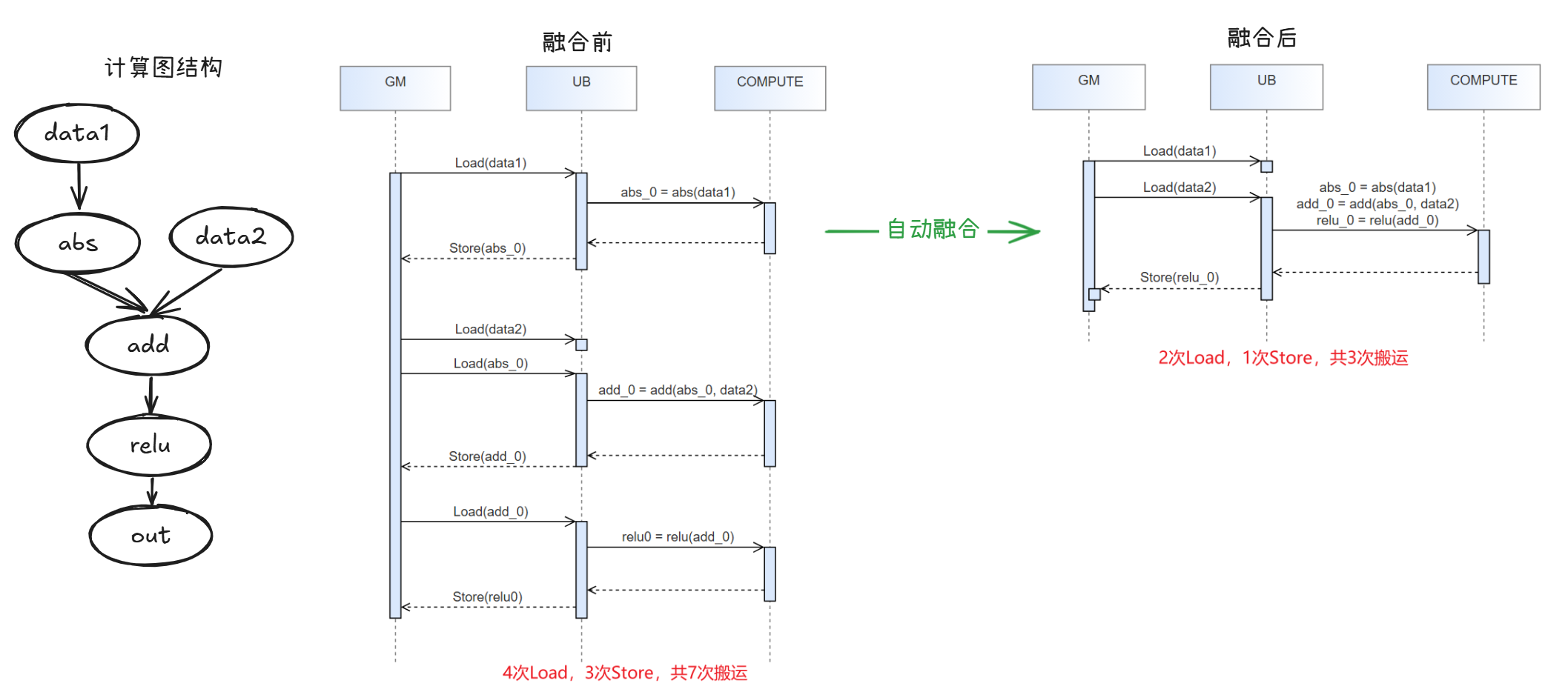
2 技术路线
自动融合方案基于昇腾NPU底层统一的AscendC IR(下称AscIR)Schedule与代码生成能力,构建了两条融合实现路径,如下图。
- 第一条路径基于昇腾自研的GE框架,注重NPU的亲和性,核心包括三部分能力:
- Ascend IR(Ascend Intermediate Representation)的符号化shape推导,通过变量符号表达动态变化的shape,从而在编译时基于符号化的shape进行代码生成。
- Ascend IR到AscIR的Lowering实现,使用低层级的AscIR表达Ascend IR的计算逻辑,确定融合结构。
- 融合策略,结合AscIR的特点与约束,进行融合结构间的循环轴合并,获得融合最优解。
- 第二条路径则对接PyTorch Inductor,聚焦于生态支持,复用Inductor的融合能力,将Inductor IR表达的融合结构转换为Ascend C IR图,进行代码生成。当前版本不支持该技术路线,后续版本支持中。
3 AutoFuse实现原理
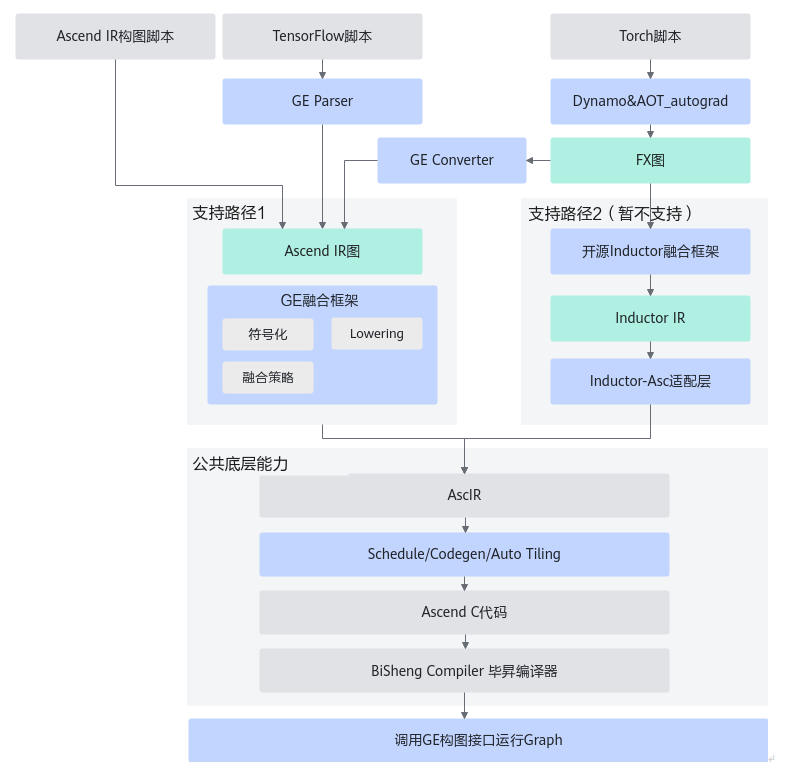
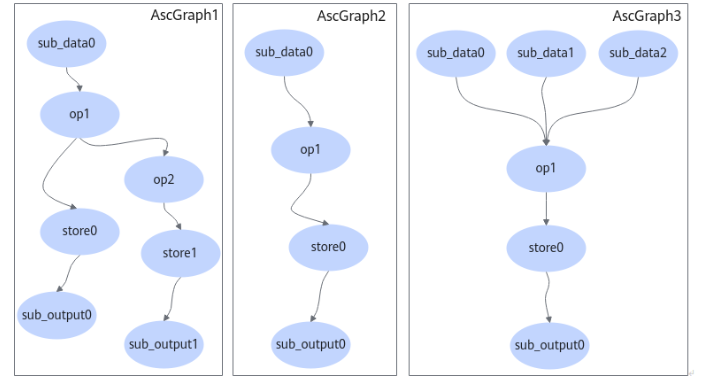
自动融合的实现包含两部分,自动确定融合范围和根据融合范围自动生成融合kernel源码及kernel二进制。前者称为自动融合前端,后者称为自动融合的后端(对应技术路线图中的公共底层能力)。前端的实现主要是根据一定规则或配置判断哪些算子能够融合,确定一个融合算子的融合范围,融合范围用FusedGraph来表达,如下图所示。
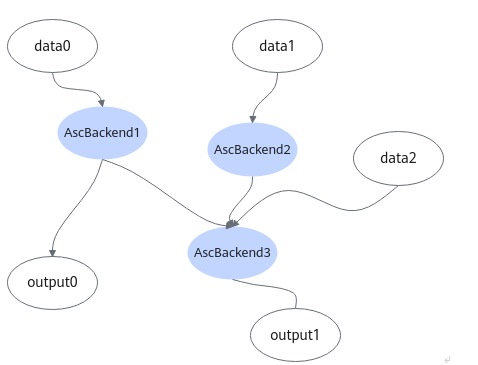
FusedGraph内部包含>=1个AscBackend节点,AscBackend可以理解为一个类似于ge::op::partitionedcall的Ascend IR算子,其携带一个子图对象,一个AscBackend节点携带一个AscGraph属性,一个AscGraph内包含多个AscIR节点。AscBackend对应的AscGraph子图结构如下图所示。
后端的实现包含Schedule/Codegen/Auto Tiling等,后端接收到FusedGraph后,Schedule首先针对计算/搬运类节点分别生成对应的TilingGroup,并通过TilingGroup合并策略,构建适用于整个融合算子的归一化TilingGroup。最终基于该归一化TilingGroup来生成FusedGraph的Tiling策略。经过Codegen实现和Auto Tiling,生成kernel源码、tiling_func源码、tiling_data源码、并编译生成Host和Device交付件。
4 优化实践
4.1 环境准备
1、硬件:Atlas 800I A2 1台
2、软件准备
| 软件 | 版本 | 下载链接参考 |
|---|---|---|
| Python | 3.7.5 | www.python.org |
| TensorFlow | 1.15.0 | pypi.org |
| TensorFlowAdapter | Ascend-cann-tfplugin_8.3.RC1.alpha003 | www.hiascend.com |
| CANN | Ascend-cann-toolkit_8.3.RC1.alpha003_linux-x86_64.run | www.hiascend.com |
| Firmware | Ascend-hdk-910b-npu-firmware_7.7.0.6.236.run | www.hiascend.com |
| Driver | Ascend-hdk-910b-npu-driver_25.2.0_linux-aarch64.run | www.hiascend.com |
4.2 实战演练
1、按如下准备demo.py代码
import tensorflow as tf
import numpy as np
## TF1.X environment
from npu_bridge.npu_init import *
if __name__ == "__main__":
# 构造输入
data1 = tf.placeholder(tf.float32, shape=[128])
input_data1 = np.random.rand(128).astype(np.float32)
data2 = tf.placeholder(tf.float32, shape=[192, 128])
input_data2 = np.random.rand(192, 128).astype(np.float32)
# 构造计算图结构
abs_0 = tf.abs(data1)
add_0 = tf.add(abs_0, data2)
relu_0 = tf.nn.relu(add_0)
# 配置会话参数
sess_config = tf.ConfigProto(allow_soft_placement=True, log_device_placement=False)
custom_op = sess_config.graph_options.rewrite_options.custom_optimizers.add()
custom_op.name = "NpuOptimizer"
custom_op.parameter_map["use_off_line"].b = True
custom_op.parameter_map["graph_run_mode"].i = 0
custom_op.parameter_map["profiling_mode"].b = True
# 采集任务轨迹数据,并配置profiling性能数据的保存路径
custom_op.parameter_map["profiling_options"].s = tf.compat.as_bytes('{"output":"./output","task_trace":"on"}')
feed_dict = {data1: input_data1, data2: input_data2}
# 运行100次迭代
step = 100
# 执行模型
with tf.compat.v1.Session(config=sess_config) as sess:
for _ in range(step):
sess.run(relu_0, feed_dict=feed_dict)
2、设置环境变量
source /usr/local/Ascend/driver/bin/setenv.sh # 用户自己的CANN包安装路径
source /usr/local/Ascend/latest/bin/setenv.sh # 用户自己的driver包安装路径
export AUTOFUSE_FLAGS="--enable_autofuse=true;--autofuse_enable_pass=reduce,concat,slice;" # --enable_autofuse=true表示启动自动融合, --autofuse_enable_pass=reduce,concat,slice表示使能自动融合的算子范围
export AUTOFUSE_DFX_FLAGS="codegen_compile_debug=true;" # 保留融合算子生成时的中间过程文件
export DUMP_GE_GRAPH=2 # 保存不含有权重等数据的基本版dump图
export DUMP_GRAPH_LEVEL=1 # 保存所有dump图
export DUMP_GRAPH_PATH="./dump_graph" # dump图保存路径
3、执行
python3 demo.py
4、执行后会在output生成profiling数据,需要使用msprof命令解析并导出性能数据
msprof --export=on --output=./output/PROF_XXX # 使用自己profiling的路径
5、当不开启自动融合(不配置AUTOFUSE_FLAGS)时,查看op_summary_xxx.csv文件,可以得到每次迭代算子总耗时为15.56us。开启自动融合时,查看op_summary_xxx.csv文件,所有算子融合为一个autofuse_pointwise_0_Cast_Abs_Cast_Add_Relu_Cast算子,算子总耗时为6.04us,提升比达到61.18%,性能对比如下:

5 总结与未来展望
通过使能自动融合AutoFuse,可以自动将多个单算子进行融合成一个融合算子,从而减少MTE搬运和动态Shape调度开销,获得性能受益。在Atlas 800I A2上经过实测,通过使能AutoFuse,推荐模型ETA的算子总耗时下降35.4%,MMOE模型的算子总耗时下降10%,GR模型的算子总耗时下降44.6%。下一步计划支持PyTorch Inductor路线,同时支持昇腾最新一代昇腾950 系列芯片。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 2
2 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)