PyTorch DDP分布式训练踩坑实录:5个隐蔽Bug让我的对比学习模型“静默死亡“
引子:"训练跑完了,但模型好像啥也没学会"
事情是这样的。
我最近在做的一个项目——Text-to-CAD检索,就是根据文字描述去搜3D CAD模型。核心思路是用对比学习把文本和CAD模型的BRep拓扑图对齐到同一个向量空间。模型架构很常规:BRepFormer图编码器 + 文本编码器,CLIP-style对称对比损失。
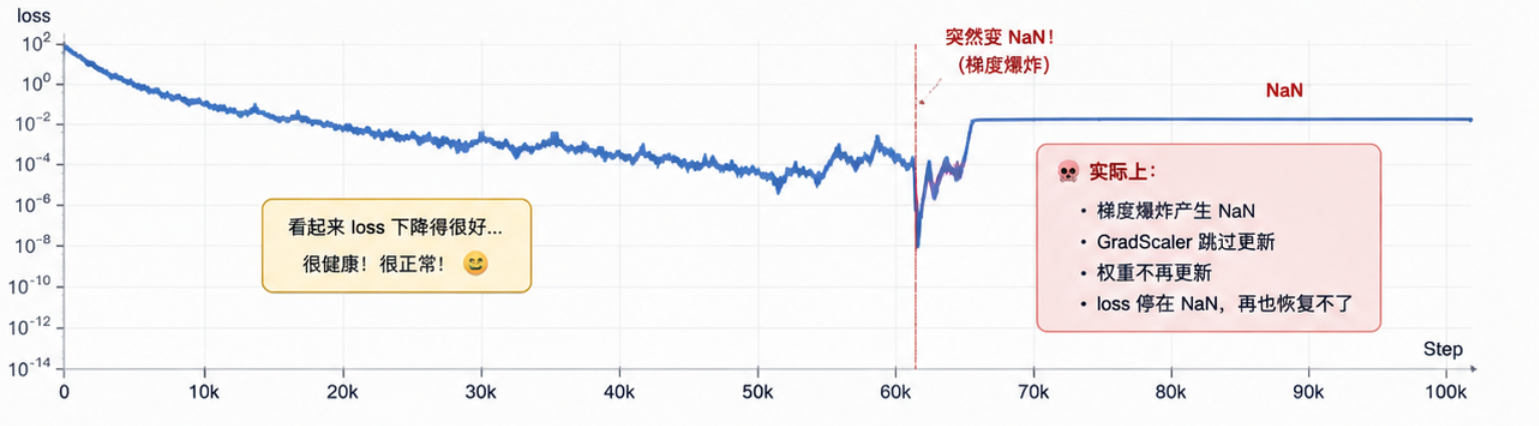
训练了一天一夜,loss从4点多降到了2出头,checkpoint乖乖地每轮保存,一切看起来岁月静好。然后我跑了一下测试集——
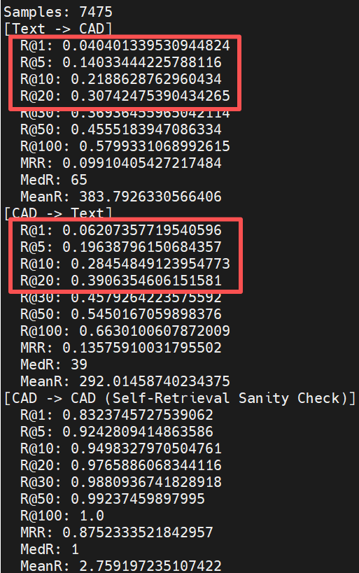
R@1 = 0.013%
你没看错,0.013%。总共7475个测试样本,意味着平均每轮只"蒙对"了1个。更诡异的是,Text→CAD、CAD→Text、甚至CAD→CAD自检索,三个方向的R@1全都是0.013%。
熟悉对比学习的同学应该知道,CAD→CAD自检索就是把每个CAD向量跟所有CAD向量算相似度取最大。L2归一化后自己和自己的点积恒为1.0,所以哪怕模型完全随机初始化,这个指标的R@1也应该是1.0才对。
这说明了一个可怕的事实:7475个测试样本的CAD嵌入向量,全部——一模——一样。
一、追凶:谁是"静默杀手"?
我加了几行诊断代码,把checkpoint里的权重挨个扫了一遍,结果触目惊心:
[Check] BrepEncoder: 5,095,777 float params
[BrepEncoder] layers.0.feed_forward.w1.weight: 12.50% NaN
[BrepEncoder] layers.0.feed_forward.w3.weight: 12.50% NaN
[BrepEncoder] layers.1.feed_forward.w1.weight: 25.00% NaN
... (还有几十个参数含 NaN)
BrepEncoder里大量权重变成了NaN!但整个训练过程中,竟然没有任何报错或警告。
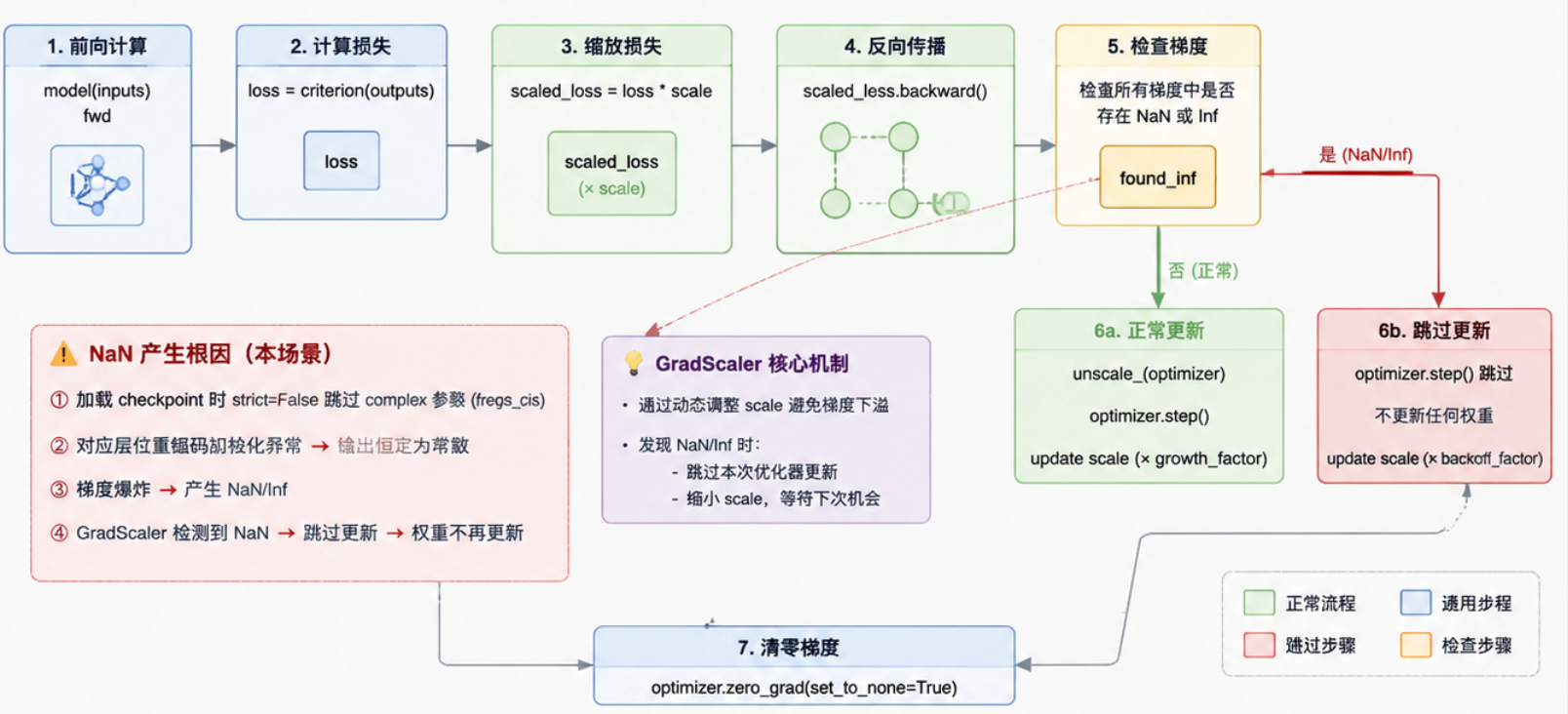
罪魁祸首是AMP混合精度中的GradScaler。
GradScaler在检测到NaN loss时的行为是——静默跳过optimizer.step(),降低scale值,然后继续下一个iteration。不报错,不打印,不打断训练。本意是防止梯度下溢导致训练中断,但在某些情况下反而帮了倒忙。
我们的场景是这样的:BRepFormer预训练checkpoint里用了一个complex张量(freqs_cis)做RoPE位置编码,但DDP的NCCL后端根本不支持complex类型。虽然加载时strict=False跳过了这个key,但对应层的初始化就出了问题。某些层输出恒定为常数,导致梯度爆炸→loss=NaN→GradScaler静默跳过→权重再也得不到更新。
最讽刺的是:torch.save()可以愉快地把NaN张量写入文件,不报错不警告。你第二天来一看:loss降了!checkpoint有了!——但权重已经全废了。
插入AMP GradScaler NaN跳过机制流程图
TensorBoard上loss突然变NaN示例
二、第一阶段修复:不让NaN"静默过关"
修复其实就三行逻辑:
# 在 loss.backward() 之前显式检测 NaN
if torch.isnan(loss) or torch.isinf(loss):
if is_main:
print(f"[Warning] Step {step}: loss={loss}, 跳过!")
optimizer.zero_grad()
scheduler.step()
continue
同时修复了预训练权重的加载逻辑——把complex张量拆成real/imag两个buffer。
另一个更重要的改进是给评测脚本加上了"自检"功能——在输出R@K指标之前,先打印嵌入向量的统计诊断信息,一眼就能看出问题:
[Diagnostic] 嵌入向量诊断 (n=7475)...
[CAD_t2c] NaN=False, mean_col_std=0.035, pairwise_cos=0.039
[Text] NaN=False, mean_col_std=0.015, pairwise_cos=0.821 ← 0.82!!
⚠️ 所有文本嵌入几乎完全相同!
Text侧pairwise_cos=0.821意味着CAD描述挤在嵌入空间的同一个点上。这是因为我们之前用冻结的CLIP编码CAD技术描述,CLIP根本没见过这种语言分布。后面我们又换成了DeBERTa-v3文本编码器,这又是一个七拐八拐的路程了,后面再说。
三、上多卡:从单卡到DDP,又踩了三个坑
单卡修好了,训练太慢。上torchrun --nproc_per_node=4启动多卡训练,然后——卡死了。
"卡死"比"报错"更可怕。报错给堆栈,卡死你连日志都只有半截。
坑1:HuggingFace模型加载文件锁死锁
现象:4个DDP进程同时执行到AutoModel.from_pretrained(),日志永久停在这一行。
原因:safetensors底层用mmap映射权重文件,mmap有文件锁。4个进程同时抢同一个文件的读锁——全死了。
修复:用torch.distributed.barrier()让Rank 0先加载,其他人等着。
if world_size > 1:
torch.distributed.barrier() # 一起到起跑线
if rank != 0:
torch.distributed.barrier() # 非 Rank 0 等待
model = AutoModel.from_pretrained(...) # 只有 Rank 0 在加载
if world_size > 1:
if rank == 0:
torch.distributed.barrier() # 通知大家·我好了
torch.distributed.barrier() # 一起继续
坑2:DDP + Gradient Checkpointing = "parameter marked as ready twice"
修完坑1,启动训练,几秒后又炸了:
RuntimeError: Expected to mark a variable ready only once.
Parameter encoder.layer.11.output.LayerNorm.weight
has been marked as ready twice.
这个问题比较深。Gradient Checkpointing会丢弃中间激活,反向传播时重新计算,导致backward对同一批参数多次访问。DDP默认不允许同一个参数在一步中被标记两次"ready"。
DDP的static_graph=True参数就是为这个场景设计的。PyTorch官方文档角落里提过一句,但99%的人不知道。解决方案:
self.model = DistributedDataParallel(
model,
device_ids=[rank],
find_unused_parameters=True,
static_graph=True, # ← 兼容 gradient checkpointing
)
坑3:AllGather自定义算子 + Tensor不连续
我们写了一个自定义AllGather算子跨GPU拼接负样本(对比学习负样本越多效果越好)。前向传播正常,一跑backward就报"Tensors must be contiguous"。
HuggingFace模型的某些layer输出在内存里并不是连续的,原生DDP不会帮你调contiguous。DeepSpeed、FSDP这些高层框架倒是会隐式处理,但裸DDP不会。
修复就一行:
return _AllGather.apply(tensor.contiguous(), world_size, rank)
"遇事不决加contiguous"——PyTorch老传统了。
四、修复前后的差距
所有bug修完后,重新训练一下的结果:
|
指标 |
修复前(NaN权重) |
修复后 |
|
R@1 |
0.013%(随机瞎猜) |
4% |
|
R@5 |
0.067% |
14% |
|
R@10 |
0.134% |
21% |
|
Loss |
NaN(被GradScaler静默吞掉) |
正常收敛 |
这一步效果还没有很好,但总算是正常了,后面改了clip模型效果还有进一步提升
五、5条实战建议
1. 训练循环里加NaN检测,别信GradScaler会告诉你
GradScaler的设计哲学是"在不打断训练的前提下自救",但有些场景它救不了。自己写两行if torch.isnan(loss)的判断,踏踏实实。
2. 加载checkpoint后先"体检"
拿一段小脚本扫一遍state_dict里有没有NaN/Inf。没有哪个框架会帮你做这件事。
3. 评测先看CAD→CAD自检索的R@1
如果这个指标接近随机水平(1/N),说明所有嵌入完全相同,checkpoint是废的。不需要再看其他指标了。
4. HuggingFace模型+DDP训练,from_pretrained前加barrier
文件锁死锁是DDP最常见但也最隐蔽的问题。用barrier让Rank 0先加载,其他等待。
5. Gradient Checkpointing + DDP = static_graph=True
这是PyTorch官方文档提了但没强调的"隐藏常识"。加上就对了。
写在最后
这次调试让我最大的感受是:深度学习框架的"容错哲学"是一把双刃剑。GradScaler静默跳过NaN、torch.save能存NaN权重、DDP文件锁死了不报错只卡住——这些设计的出发点都是"不要打断训练",但反而让问题藏得更深,排查起来更痛苦。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 8
8 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)