从dify、coze、飞书、obsidian看rag架构
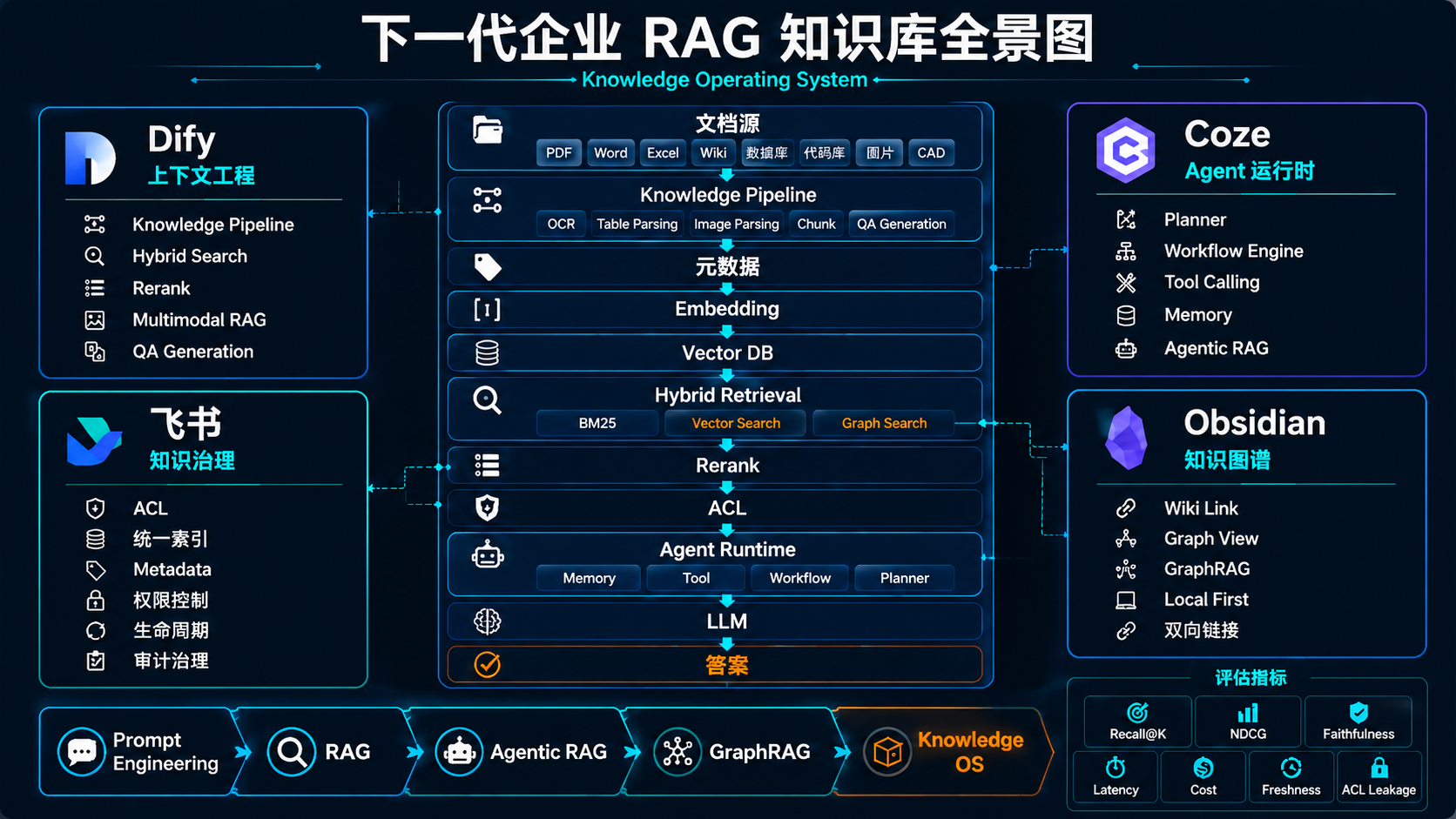
从 Dify、Coze、飞书、Obsidian 看下一代 RAG 知识库架构
引言
过去两年,RAG(Retrieval-Augmented Generation,检索增强生成)成为企业构建 AI 知识库的主流方案。然而,大量企业在投入数月时间建设知识库后,发现最终效果并不理想:
- 检索结果不准确
- 回答内容存在幻觉
- 权限控制缺失
- 知识更新困难
- Agent 能力不足
问题往往不在于大模型本身,而在于知识库架构设计。
本文通过分析 Dify、Coze、飞书知识库、Obsidian 四类典型产品,尝试总结下一代企业知识库的发展方向。
说明:文中穿插的代码片段并不是这些产品的真实源码,而是用于解释其架构思想的简化实现。
一、Dify:从 RAG 到 Context Engineering
Dify 是目前最流行的开源 LLM 应用开发平台之一。
很多人认为 Dify 的核心能力是 Workflow 或 Agent,但实际上其最大的技术价值在于:
Context Engineering(上下文工程)
1.1 Knowledge Pipeline
传统 RAG 流程:
Document
↓
Chunk
↓
Embedding
↓
Vector DB
Dify 的 Knowledge Pipeline:
Document
↓
OCR
↓
Table Parsing
↓
Image Parsing
↓
Metadata Enrichment
↓
Chunk
↓
QA Generation
↓
Embedding
相比传统方案,Dify 更关注数据预处理质量。
其核心思想:
Garbage In, Garbage Out
检索效果差,很多时候并不是 Embedding 模型的问题,而是知识库预处理质量不足。
1.2 Hybrid Search
早期 RAG 大多采用:
Vector Search
生产环境中往往会出现:
- 专有名词召回失败
- 精确关键词匹配失败
- 数字类内容检索效果差
因此 Dify 引入:
BM25
+
Vector Search
形成:
Hybrid Search
架构如下:
Query
│
├── BM25
│
└── Vector Search
│
▼
Merge
│
▼
Rerank
│
▼
Top-K
1.3 Rerank
仅依赖向量相似度排序存在明显问题:
Query:
SpringBoot 分库分表方案
可能召回:
SpringCloud
Spring Security
Spring MVC
虽然语义接近,但不符合真实需求。
因此引入:
Cross Encoder
进行二次排序:
Retriever
↓
Top 50
↓
Rerank
↓
Top 5
这已经成为企业级 RAG 的标准配置。
1.4 一个简化的混合检索代码示例
下面这段代码体现的正是 Dify 这一类产品强调的核心思想:先尽量把候选集召回全,再通过重排提高最终相关性。
from typing import Any
def hybrid_retrieve(query: str, top_k: int = 5) -> list[dict[str, Any]]:
sparse_hits = bm25.search(query, top_k=20)
dense_hits = vector_store.search(
embedding_model.embed_query(query),
top_k=20,
filters={"status": "published"},
)
merged_hits = reciprocal_rank_fusion([sparse_hits, dense_hits])
reranked_hits = reranker.rerank(query=query, documents=merged_hits)
return reranked_hits[:top_k]
def answer(query: str) -> str:
docs = hybrid_retrieve(query)
context = "\n\n".join(doc["content"] for doc in docs)
prompt = f"基于以下上下文回答问题。\n\n上下文:\n{context}\n\n问题:{query}"
return llm.generate(prompt)
这个实现对应了典型的企业级检索链路:
- 稀疏检索负责关键词命中
- 向量检索负责语义召回
- 融合算法负责合并候选集
- Reranker 负责把真正有用的内容推到前面
1.5 对应的 Mermaid 时序图
1.6 Multimodal RAG
下一代知识库正在从:
Text RAG
向:
Multimodal RAG
演进。
支持:
Text → Text
Text → Image
Image → Text
Image → Image
例如:
- 产品说明书
- UI 设计图
- CAD 图纸
- 医学影像
- 运维架构图
均可统一纳入知识库。
这意味着知识库不再只是“段落检索系统”,而更像“多模态上下文编排系统”。
二、Coze:从 RAG 到 Agent Runtime
很多人误以为 Coze 是知识库平台。
实际上:
Coze ≠ RAG
Coze = Agent Runtime
其核心价值在于 Agent 编排能力。
2.1 Agent Runtime
传统聊天机器人:
User
↓
LLM
↓
Answer
Coze:
User
↓
Planner
↓
Workflow
↓
Tool
↓
Knowledge
↓
Memory
↓
LLM
核心思想:
Agent = LLM + Tool + Memory + Planning
2.2 Workflow Engine
Coze 大量能力建立在 DAG 工作流之上。
Start
↓
Knowledge Search
↓
Condition
├── Tool A
└── Tool B
↓
Answer
相比传统 Prompt:
Prompt Engineering
Coze 更强调:
Workflow Engineering
2.3 Memory 机制
Agent 与普通 RAG 的最大区别:
Memory
典型设计:
Short-Term Memory
Redis
保存最近对话。
Long-Term Memory
Vector DB
保存长期用户信息。
Knowledge Base
企业知识库
保存业务知识。
最终形成:
Memory
+
Knowledge
+
Tool
三层架构。
2.4 一个简化的 Agent Runtime 代码示例
如果把 Coze 的设计思想翻译成代码,大致会长这样:
class AgentRuntime:
def __init__(self, planner, memory, knowledge, tool_executor, llm):
self.planner = planner
self.memory = memory
self.knowledge = knowledge
self.tool_executor = tool_executor
self.llm = llm
def run(self, user_id: str, query: str) -> str:
plan = self.planner.create_plan(query)
memory_context = self.memory.load(user_id)
knowledge_context = self.knowledge.search(query, user_id=user_id)
tool_result = None
if plan.need_tool:
tool_result = self.tool_executor.invoke(
plan.tool_name,
plan.tool_args,
)
prompt = build_agent_prompt(
query=query,
plan=plan,
memory=memory_context,
knowledge=knowledge_context,
tool_result=tool_result,
)
answer = self.llm.generate(prompt)
self.memory.save_turn(user_id, query, answer)
return answer
这里最关键的不是“调用了一次 LLM”,而是把规划、记忆、工具、知识检索都纳入统一执行上下文。
2.5 对应的 Mermaid 时序图
2.6 Coze 真正解决的不是“能不能答”,而是“能不能执行”
普通 RAG 的目标通常是:
Find Answer
而 Coze 这类 Agent 平台的目标更接近:
Understand Intent
→ Plan
→ Retrieve
→ Use Tool
→ Complete Task
因此,它的竞争力并不在检索本身,而在“任务闭环能力”。
三、飞书:企业知识库的本质是知识治理
很多开源 RAG 项目关注:
Embedding
Chunk
Vector DB
但企业真正关心的是:
权限
3.1 ACL 权限模型
普通 RAG:
Query
↓
Retriever
↓
Answer
企业级 RAG:
User
↓
ACL Filter
↓
Retriever
↓
Rerank
↓
Answer
先过滤权限。
再执行检索。
3.2 企业知识统一索引
企业知识往往分散在:
Wiki
Word
Excel
PDF
数据库
会议纪要
代码仓库
飞书的思路:
统一索引
即:
Document Layer
↓
Search Layer
↓
Knowledge Layer
3.3 Metadata 驱动治理
企业知识库不仅需要存储内容:
Content
还需要维护:
Owner
Department
Permission
Tag
Category
UpdateTime
形成:
Metadata Driven Architecture
3.4 为什么很多企业 RAG 项目失败
根本原因通常不是:
模型不够强
而是:
权限混乱
知识无人维护
文档过期
因此:
企业知识库首先是知识治理系统,其次才是 AI 系统。
3.5 一个简化的 ACL 检索代码示例
下面这段代码体现了企业级知识库与普通 Demo 最大的差异:检索不是从“问题”开始,而是从“用户身份”开始。
def search_with_acl(user, query: str, top_k: int = 5):
allowed_scopes = acl_service.resolve_scopes(
user_id=user.id,
departments=user.departments,
groups=user.groups,
)
filters = {
"department": {"$in": allowed_scopes.departments},
"doc_status": "published",
"security_level": {"$lte": user.security_level},
}
hits = retriever.search(
query=query,
filters=filters,
top_k=30,
)
reranked = reranker.rerank(query, hits)
return reranked[:top_k]
这里最重要的工程原则是:
- 权限过滤要尽量前置
- 检索层要支持 metadata filter 下推
- 最终答案最好附带引用来源,便于审计与追责
3.6 对应的 Mermaid 时序图
3.7 飞书这一类产品真正强的地方
飞书知识库这一类产品最强的部分,常常不是模型能力,而是以下几个“非模型能力”:
- 原生组织架构
- 文档权限体系
- 审批与流程能力
- 文档生命周期管理
- 多来源统一索引
这些能力看起来“不性感”,却恰恰决定了企业知识库能不能真正上线。
四、Obsidian:知识图谱驱动的第二大脑
Obsidian 最大的创新不是 Markdown。
而是:
Wiki Link
4.1 双向链接
例如:
[[SpringBoot]]
[[Kafka]]
[[Milvus]]
自动形成:
Knowledge Graph
4.2 Graph View
知识之间的关系天然是:
Graph
而不是:
Tree
例如:
Java
│
├── Spring
│ └── SpringBoot
│
└── Kafka
形成图结构。
4.3 GraphRAG
传统 RAG:
Embedding Search
GraphRAG:
Embedding Search
+
Graph Traversal
例如:
Java
↓
Spring
↓
SpringBoot
↓
MyBatis
系统能够发现隐含关联。
4.4 Local First
Obsidian 强调:
Local First
特点:
- Markdown 存储
- 本地数据
- 用户完全控制
- 插件扩展
未来个人知识库很可能采用:
Obsidian
+
GraphRAG
+
Local LLM
模式。
4.5 一个简化的 GraphRAG 代码示例
GraphRAG 的关键不是“把图数据库接进来”这么简单,而是先用语义检索找到种子节点,再沿图结构做关系扩展。
def graph_rag(query: str, seed_top_k: int = 5, hop: int = 2):
seed_docs = vector_store.search(query=query, top_k=seed_top_k)
expanded_nodes = []
for doc in seed_docs:
expanded_nodes.extend(
graph_store.expand(
node_id=doc["node_id"],
max_hop=hop,
edge_types=["reference", "belongs_to", "depends_on"],
)
)
candidates = deduplicate(seed_docs + expanded_nodes)
ranked_docs = graph_aware_reranker.rerank(query, candidates)
return ranked_docs[:8]
这样的好处是,系统不仅能找到“相似文本”,还能够找到“结构上相关”的知识节点。
4.6 对应的 Mermaid 时序图
4.7 Obsidian 带来的启发
Obsidian 的意义在于提醒我们:
知识库不一定只能围绕“文档分块”构建,也可以围绕“知识节点关系”构建。
这对企业研发知识库、专家经验库、项目复盘库尤其重要,因为这些场景中的知识往往高度依赖上下游关系。
五、下一代企业知识库架构
综合四类产品的设计思想,可以得到一个更完整的企业级知识库架构。
┌──────────────┐
│ Documents │
└──────┬───────┘
│
Knowledge Pipeline
│
▼
Metadata Layer
│
▼
Embedding Layer
│
▼
Vector Database
│
┌───────────────┼───────────────┐
│ │ │
▼ ▼ ▼
BM25 Vector Search Graph Search
│ │ │
└────── Hybrid Retrieval ───────┘
│
▼
Rerank
│
▼
ACL Layer
│
▼
Agent Runtime
│
┌─────────────┼─────────────┐
│ │ │
▼ ▼ ▼
Memory Tool Workflow
│
▼
LLM
│
▼
Answer
这一架构的核心不再是单点优化,而是多层协同:
- Dify 提供高质量上下文构建能力
- Coze 提供 Agent 运行时和流程编排能力
- 飞书提供权限、治理、索引与组织体系能力
- Obsidian 提供图谱化组织知识的思路
从这个角度看,下一代企业知识库已经不只是“检索系统”,而是在向“Knowledge Operating System”演进。
六、真正决定成败的评估指标
很多团队做 RAG 时,只看“回答像不像”,但上线后真正要看的,往往是下面这些指标。
6.1 检索指标
- Recall@K:该召回的文档有没有召回到
- MRR / NDCG:真正有价值的文档排得靠不靠前
- Top-K Hit Rate:前 K 个候选里是否包含正确证据
6.2 生成指标
- Faithfulness:回答是否忠于引用内容
- Citation Accuracy:引用是否准确
- Hallucination Rate:是否存在脱离知识库的编造
6.3 工程指标
- P95 Latency:高峰期响应时间是否可接受
- Cost Per Query:单次问答成本是否可控
- Freshness SLA:文档更新后多久能被检索到
6.4 安全指标
- ACL Leakage Rate:是否出现越权命中
- Sensitive Data Exposure:是否泄露敏感信息
- Auditability:是否能追溯答案来源与处理链路
一句话总结:
没有评估体系,就没有真正可持续优化的 RAG 系统。
七、不同团队该怎么选
如果把这四类产品放到真实场景里,大致可以这样理解:
| 场景 | 更适合的思路 | 原因 |
|---|---|---|
| 中小团队搭内部问答助手 | Dify 型 | 上手快,适合快速搭建检索问答 |
| 想做复杂任务闭环、自动执行流程 | Coze 型 | 重点在 Agent Runtime 和 Workflow |
| 大企业统一搜索、权限严格、系统众多 | 飞书型 | 重点在 ACL、治理、统一索引 |
| 个人知识管理、研究笔记、专家知识沉淀 | Obsidian 型 | 重点在图谱关系与 Local First |
很多项目失败,并不是“选错了工具”,而是“用知识问答的目标,去选 Agent 平台”,或者“用 Demo 级工具,去做企业治理问题”。
八、未来技术趋势
第一阶段
Prompt Engineering
代表:
- ChatGPT
第二阶段
RAG
代表:
- Dify
- LangChain
第三阶段
Agentic RAG
代表:
- Coze
- AutoGen
- CrewAI
第四阶段
GraphRAG
代表:
- Microsoft GraphRAG
- Obsidian Graph
第五阶段
Knowledge Operating System
特点:
- Knowledge Pipeline
- Hybrid Retrieval
- GraphRAG
- ACL
- Agent Runtime
- Long-term Memory
总结
通过分析 Dify、Coze、飞书和 Obsidian 可以发现:
| 产品 | 核心思想 |
|---|---|
| Dify | Context Engineering |
| Coze | Agent Runtime |
| 飞书 | Knowledge Governance |
| Obsidian | Knowledge Graph |
未来企业知识库的发展路径大概率为:
RAG
→ Agentic RAG
→ GraphRAG
→ Knowledge Operating System
真正优秀的知识库系统,不仅需要向量检索能力,更需要知识治理、权限控制、工作流编排、长期记忆以及知识图谱等能力的协同支撑。
如果再往前看一步,企业知识库最终拼的也许不是“谁接了更多模型”,而是“谁能把组织知识以最低成本、最高可信度、最可治理的方式持续运转起来”。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 10
10 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)