对话李鸿升教授:填补行业空白,大晓Kairos-HomeWorld给家居机器人造一个中国家庭训练场
家庭,是具身智能最有想象力的终局场景之一,也是最难训练机器人的场景之一。
家居机器人迟迟难以规模化训练面临一个核心矛盾:它要进入最复杂、最个性化的真实家庭,却很难先获得足够大规模、足够高质量、足够可交互的家庭训练数据。
近日,大晓机器人联合香港中文大学多媒体实验室、深圳河套学院发布了世界模型 Kairos-HomeWorld,试图从另一个方向解决这个问题。
Kairos-HomeWorld 是全球首个实现全屋生成、个体物体全交互的世界模型统一框架。它不只是生成一个“看起来像家”的三维空间,而是要生成一个机器人真正可以在其中导航、抓取、开门、整理、放置物品的可操作环境。
这意味着,家居机器人训练不再局限于过去常见的单桌面任务、单房间导航,而是被推向更复杂的全屋长程任务:比如从客厅走到厨房拿一听可乐;或者把刚买回来的物品,按照用途分别放进厨房、冰箱、卧室和阳台。这样的任务背后,是对空间理解、任务分解、路径规划、物体识别和物理交互的综合能力。
更重要的是,Kairos-HomeWorld 专为中国家庭环境打造。团队基于30万套中国真实住宅户型数据,构建出5000套通过算法生成的全屋三维环境。接下来,大晓团队计划将这些数据集全面开源。
大晓机器人成立于2025年12月,是一家商汤系的生态企业,也是在世界模型方向动作最密集的中国创新团队之一。
从团队背景看,大晓机器人由商汤科技联合创始人、执行董事王晓刚出任董事长,世界级AI科学家陶大程院士担任首席科学家,团队汇聚了一批青年AI科学家和产业界专家。公司愿景是让机器人拥有聪明的“大脑”和有趣的“灵魂”。
围绕这一目标,大晓机器人首创ACE研发范式,构建起“环境式数据采集—开悟世界模型3.0—泛化具身模组”的全链路技术体系,试图解决具身智能行业长期面临的数据荒、常识弱、泛化难和落地断层等核心问题。其中,开悟世界模型Kairos是其最关键的技术底座之一。
不久前,大晓机器人开悟世界模型 Kairos 在 RoboTwin 2.0、LIBERO-Plus、WorldModelBench Robot、DreamGen 四项具身智能世界模型评测中均取得第一,验证了其在双臂操作、物理建模、场景泛化等维度上的能力。同步推出的“具身超级大脑模组A1”,也显示出大晓机器人正在尝试打通“模型—硬件—场景”的产业闭环,加速具身智能在安防、巡检、服务等场景中的商业化落地。
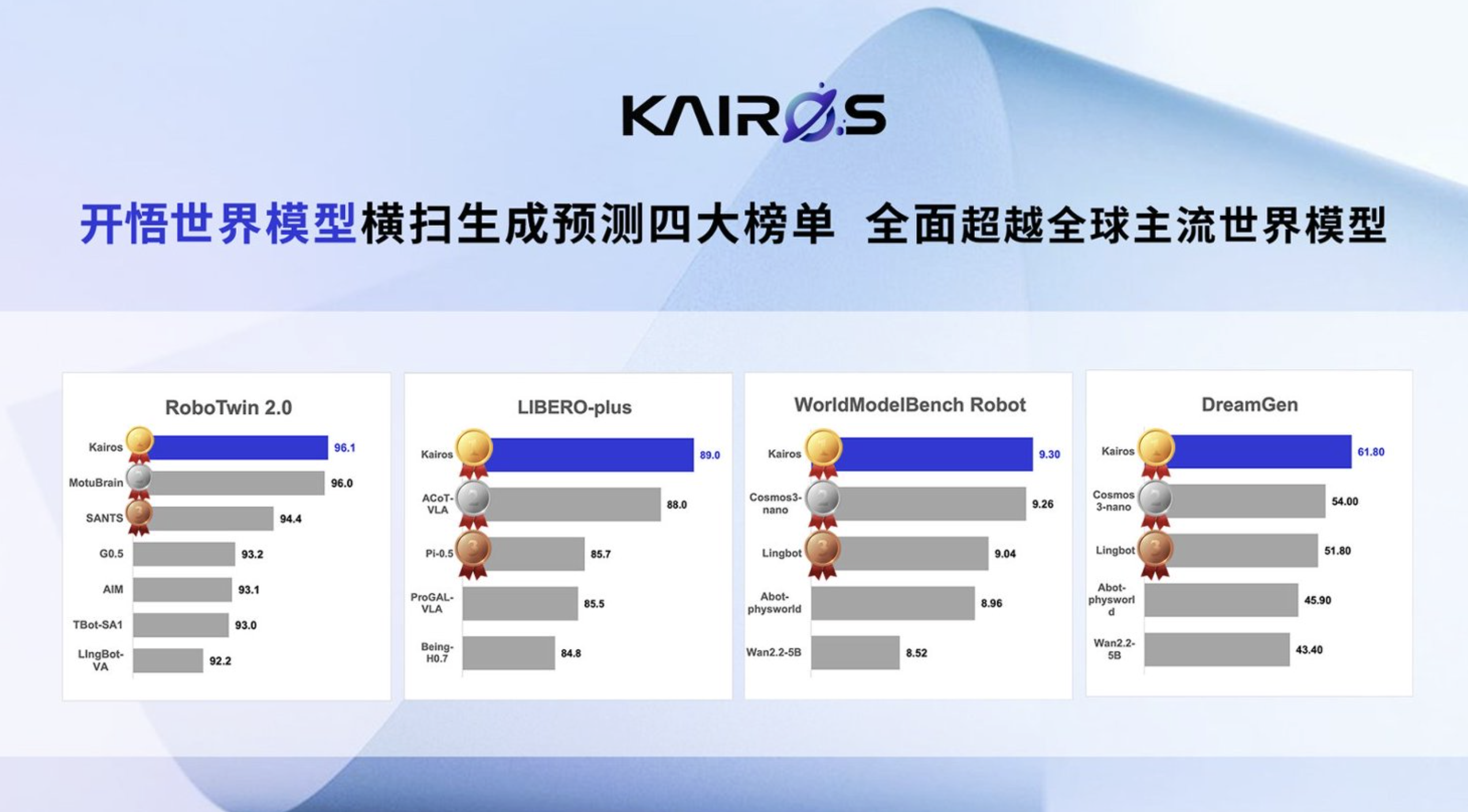
因此,Kairos-HomeWorld 并不是一个孤立的研究成果,而是大晓机器人世界模型技术栈在家居机器人场景的重要延伸。
作为 Kairos-HomeWorld 的核心研究者,李鸿升教授是大晓机器人具身大模型科学家,同时担任香港中文大学多媒体实验室(CUHK MMLab)教授。他长期深耕多媒体计算、计算机视觉与具身智能交叉方向,连续四年入选斯坦福大学“全球前2%顶尖科学家”,也是 AI 2000 计算机视觉领域最具影响力学者之一。
近日,「智能进化论」采访了李鸿升教授。我们重点聊了几个话题:为什么家居机器人不能只依赖真实入户采集数据?中国家庭数据集为什么重要?“物体全交互”究竟意味着什么?仿真数据和真机数据是替代关系,还是互补关系?以及,世界模型距离真正支撑家居机器人进入家庭,还有多远?
Kairos-HomeWorld要解决的,不只是如何生成一个三维家庭空间,而是让机器人在进入真实家庭之前,先在一个足够真实、多样、可交互的中国家庭环境中完成训练。

大晓机器人具身大模型科学家,香港中文大学多媒体实验室(CUHK MMLab)教授 李鸿升
技术突破与核心创新
智能进化论:Kairos-HomeWorld最核心的技术突破体现在哪些方面?
李鸿升:它是全球首个房屋级别全屋生成,且房屋中所有的物体能够全交互的统一的机器人虚拟训练场,符合中国家庭环境。通过这个技术可以生成成千上万的不同户型,为机器人构建海量的训练数据。
智能进化论:现有室内场景生成大多只能覆盖单房间,缺乏全局一致性,你们是如何攻克"全屋一键生成"这一行业瓶颈的?
李鸿升:首先,我们收集了很多中国家庭专属的户型数据。现在开源的网上数据,不管是户型数据还是三维重建数据,基本上都是以欧美家庭户型为主。因此我们第一个要解决的就是获得有中国家庭特色的训练数据。
有了训练数据后,我们构建了一个比较长的管线,在不同的阶段,训练了不同的AI模型出来。
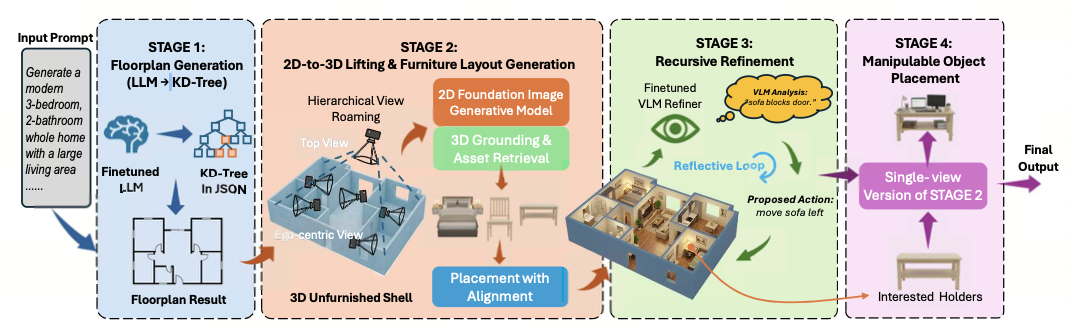
第一阶段,就像造房子那样,先训练了一个大语言模型,能够生成符合我们中国家庭特色的户型图,比如我现在需要一个两房一厅,需要帮我布置客厅、餐厅在哪,房间、卫生间在哪。
布置好了以后进入第二阶段,我们会用比较好的生图模型,生成符合室内场景的家居照片,再基于家居照片,把家具摆放到这些三维环境中去。同时也要去做一些多视角一致性的校验工作。
第三阶段,通过VLM这种多模态大模型,对家具冲突或者尺寸问题做一些修正。
第四阶段,摆放物体,包括生成这些物体的物理属性。实际上是使用了不同的AI模型,构建了整个数据管线,这样能够比较顺畅地生成各种各样的全屋三维模型。
智能进化论:物体全交互这一块,我们现在能做到什么程度?
李鸿升:我们用大晓另外一个算法来构建物体的物理属性和关联特征。比如机器人看到一个冰箱的话,它会推理冰箱门的门轴在哪里,以及碰哪个位置才能最顺畅地把冰箱门打开。
智能进化论:全球首个全屋可操作物体生成的统一框架,统一如何理解?
李鸿升:统一是说整体生成出来的户型,跨户型之间,跨物体之间,都是统一的接口,统一的规则,物品的物理属性都是兼容的,所有房间里面的东西都是可以互相交互的,不是说有的东西能交互,有的东西不能交互。
数据集与开源战略
智能进化论:我们最初的数据集选择了中国家庭,为什么要选择这个方向?
李鸿升:目前开源的数据集是以欧美为主的,这样训练出来的,不管是导航的算法,或者是一些长程空间智能的算法,都是更适配欧美家庭的场景。
我们肯定还是希望家居机器人能够更好的服务中国家庭,因此专门做了这样一套数据集。
这样可以为具身行业有一些示范性的作用,如果其他厂家感兴趣,可以用我们发布的数据。我们正准备要做数据的开源工作,先会开源三十万套中国家庭的户型数据,数据都是经过清理和脱敏的。随后也会开源5000套通过算法构建的全屋三维环境。包括每步的算法,以及整体数据构建的管线,陆续都会开源出来。

智能进化论:开源数据集出于什么样的考量?
李鸿升:我们希望推动中国家居环境机器人的发展。对于长程的家居任务,希望其他企业或机构能够用上这些训练数据,和他们自己真实采集的数据搭配起来,进行家居机器人的任务训练。
目前来看,机器人在商业、工业环境可能是最先落地的,有可能家居环境落地的时间是最晚的。不管是从安全、隐私,整体任务落地的难易程度,成本各方面来讲,基本上家居机器人都是相对靠后的。
比如现在机器人即使比较轻的30公斤,如果没有电了突然倒在家里其实也容易把人砸伤。而且用户对家居和工商业场景的预期不同。机器人进到家里面,用户预期是家里所有活都能帮我干,但是所有的家务都能干本身挑战性很大。
因此我们愿意把这套数据开源出来,推动行业针对家居机器人算法的开发。
智能进化论:您认为这套数据集以及开源对于具身智能的国产化落地有什么样的意义?
李鸿升:我觉得还是挺重要的。如果都是以欧美家庭的户型数据去训练,算法会有水土不服。
即使是以东亚家庭为例,像日本的家庭,一般一进门是一个带台阶的玄关,进门会有一个卫生间,和中国家庭是不一样的。
机器人如果理解不了不同区域户型的特征,特别是在做无图导航的时候,它就会本来想去卫生间,结果进了厨房。所以为了机器人更高效的做空间推理,中国家庭特色的数据还是很重要的。
智能进化论:最初30万套户型和5000个可交互的仿真场景,这些数据是如何采集清洗的?
李鸿升:户型数据噪声比较大,我们采用了人与模型互相配合的方式,人工打标,模型做分割识别。
全球视野与路线对比
智能进化论:目前家居机器人训练数据有真实场景采集和仿真两条路线,能否科普一下他们的差异和优劣?
李鸿升:真实场景采集一般是用传统的扫描重建方式,通过相机或者三维扫描设备,对全屋进行扫描,之后进行三维重建。这种方式整体成本比较高,速度比较慢。
首先,最大的问题是有多少用户同意进到家里面去采集数据。
重建在自动驾驶里面是能做的,因为自动驾驶的道路都是公开的。我开了100万公里的道路,就获得了100万公里的数据。
但是房屋重建最大的问题就是用户意愿。如果能够获得1万个用户的同意,已经非常困难了,而且做1万个房屋的重建扫描工作量是非常大的。但对于AI训练来说,1万的量级相对还是比较小的。如果要训练比较好的AI模型,往往需要几十万或者几百万量级。所以我们通过仿真这条路径,主要还是希望解决数据scaling up的问题。
其次,采集后还要做很多后处理。如果只是做三维重建,实际上只会得到一个Mesh(三维网格),或者是一整块点云(Point Cloud,用一堆三维空间里的点来描述物体或环境的形状)。比如房间里有桌子,桌上面有杯子,那么杯子就会粘在桌上面,桌子也会粘在地面上。真机采集数据虽然是比较真实的,但后续要做很多处理工作,才能把所有单一可交互的物品分开,再建模。
智能进化论:即使能采到百万级数据,物品的拆分也是一个难点?
李鸿升:是的,真实采到百万场景是非常困难的,即使采出来,还要做很多后处理的工作。每个物品不仅要做分割,还要给每个物品赋予物理属性,重量、体积、表面摩擦力系数等特征,注入之后才能变成机器人能够训练使用的数据。重建出来,到机器人训练能够用上,还是有很大gap的。
智能进化论:目前行业内真机数据和仿真数据的应用分别是什么情况?
李鸿升:现在大部分具身工作其实都是小范围场景,比如单一桌面场景任务为主。这种目前还是以真机数据为主,仿真数据为辅。
但如果把这些任务扩展到全屋,比如用户给机器人下指令,让它去厨房拿一听可乐回来,就需要全屋环境的训练。这种全屋级的、长程任务,真机数据采集基本上比较困难,也不大可能做scaling up。Kairos-HomeWorld主要还是想解决全屋级的长程任务。
智能进化论:国外像Figure AI走的是真机采集路线,宣称要采集10万套真实住宅,从效果上我们和他们的差异在什么地方?
李鸿升:10万套户型分布在全美不同地方,即使有一个数据采集的组全美国到处都飞,成本还是非常大的。当然从光照的角度来讲,真实入户采集肯定会更真实。
但是他们一般都是上个租户退租后,在下个租户进来前去采集,一般采集的都是干干净净的房间数据,房间里不会有很多可交互的物品。后期如果想要构建机器人的训练场,还是只能走仿真路线,再摆很多物品进到重建的三维环境中去。对于机器人可操纵物品的训练,包括长程物品的训练,还是需要真实数据和仿真数据结合。
智能进化论:真实环境采集和仿真这两条路线,您认为是什么关系,替代还是融合?
李鸿升:这两种类型的数据肯定是互补的关系,从数据比例来讲,肯定是根据不同任务的属性,还有数据采集的难易程度来做配比。
比如物品操控这样的任务,基本上都是以真机数据为主。现在物品操纵场景公开的数据集慢慢也多起来,能够达到几万小时量级。
如果是全屋长程的任务,现在确实没有真机数据可以支持训练,这种只能是以仿真数据为主,真机数据为辅。长程任务的真机采集,效率相对来说更低。
落地应用与商业价值
智能进化论:模型训练好了之后,如何迁移到现实的家居环境中?
李鸿升:首先,Sim to real的gap肯定都有的。现在不管任何机器人模型,基本上还是需要做少量的真机数据微调,才能让模型更好的适配真实环境。现在当我们有大量的仿真数据以后,真机数据有可能就会少一到两个数量级,减少真机场景的采集。
第二,我们也在进一步提升仿真数据的视觉仿真度,把gap进一步往下压。
智能进化论:Kairos-HomeWorld模型已经用于大晓机器人的训练了,能否分享一些训练成果或者案例?
李鸿升:现在基于全屋的仿真环境,我们已经可以训练机器人完成一些跨房间的比较长程的复杂任务。比如把买的杂物根据用途进行全屋分配,有的东西应该摆到卧室,买的菜应该放进厨房或冰箱。它不仅需要理解物品,还要理解整个房屋的三维架构,才能把任务完成的比较好。
智能进化论:大晓机器人在这种长程任务的实际表现如何?
李鸿升:在全屋导航层面的提升是比较大的,这是看到最明显的一个性能提升。因为此前的全屋导航基本上都是基于一些公开数据做的,数据量级是比较小,就几千套。因为我们数据量比较大,所以对全屋导航的精度提升比较大。
操作方面和现有的具身在同一桌面的挑战是类似的。未来我们计划更好的用灵巧手去抓一些形状各异的物品,也会做一些 VLA模型的开发。
智能进化论:长程的复杂任务,我们有没有进行分类,先训练哪一类?
李鸿升:我们最先做的一大类任务是 grab and place,抓一个东西再把它放到一个地方去。传统的grab and place都是在同一个桌面上做的,现在我们可以放到全屋不同的目的地。
基于全屋的环境,当然还可以做一些传统的小范围工作,比如全屋的清洁、拖地、整理桌面等,也都可以通过全屋的仿真环境完成训练。
智能进化论:家居机器人的benchmark是什么?我们在这方面有什么规划?
李鸿升:一方面是从训练数据集来讲,我们希望做一个自动的构建。比如指令的自动生成,对应指令的 GT的自动生成,还有指令完成的自动评估。自动评估不仅是作为Benchmark使用,也可以把评估结果作为一些强化学习训练的奖励信号进行模型的训练。这三个层面都比较重要。
智能进化论:Kairos-HomeWorld模型下一步的规划是什么?
李鸿升:第一希望做自动任务的生成,还有自动的任务完成度的评估,再构建一些大规模的训练集,还有评测的benchmark出来。
第二加入更多环境的可变化度,包括各种光照,更多的物品,以及各种动态主体,比如家庭成员,进到虚拟仿真环境中去,这是未来中近期的一些开发计划。
智能进化论:您对家居机器人规模化落地的时间有什么样的预期?
李鸿升:这个比较难做判断。家居机器人真正落地的话,应该是一系列能力都要做到极致的状态,功能性、安全性都需要打满。
严格来说,我们现在还在做整个链条上单点的攻破。很多商业、工业场景的机器人应该是先落地的,很多技术栈是相通的,比如很多grab and place任务,当在工业商业场景做好了,自然而然相同的能力可以迁移到家居机器人中来。
合作生态与人才培养
智能进化论:这次技术突破是大晓机器人,香港中文大学多媒体实验室,与深圳河套学院三方的合作成果,三方分别承担了什么角色?
李鸿升:大晓机器人会给一些更具挑战性、更贴近实用的问题。
我们也是进行了分析,确实是在大学里面自己是没有关注这些偏现实的问题。也没有像传统分工分的非常明确,三方是一起协作起来完成的。
智能进化论:回顾您的学术历程,哪段研究经历或者关键节点让您笃定要投身具身模型这一方向?
李鸿升:大模型慢慢成熟以后,包括一些Agent出现之后,目前具体的操作都还是偏虚拟的操作为主。随着人工智能进一步发展,我们肯定还是希望能够脱虚向实,做更多辅助人类工作的任务。
我们关注的点也不仅仅是家居机器人,对于办公场景、商业场景、工业环境的构建,以及任务的生成,是感兴趣的。
现阶段从研究的层面来讲,家居不管是从训练数据的获取,还有任务的定义,相对更容易获得。很多任务,相同的技术栈在商业、工业环境也都可以用。未来我们会继续往商业、工业环境数据的采集,任务的收集这个方面去做。
智能进化论:对于世界模型,您认为现在处于什么阶段?下一个突破式的进展可能是什么?
李鸿升:世界模型现在还在快速发展的阶段。最开始的世界模型,主要以像素级别的视频生成为主。慢慢开始关注,能不能推理出未来场景的动态,学习到更好的物理规律,理解机器人的各种状态等等。
世界模型会有更多的数据模态需要引入,比如触觉数据。如果主要还是用灵巧手来操纵物体,触觉信号还是比较重要的。
智能进化论:您实验室招聘博士生,最看重同学的哪些特质?
李鸿升:我会更看重学生是否有相关研究经历,这样上手会更快。但更重要的是,他不能只是为了发论文而来,而是要真正做出别人愿意使用、能够产生实际影响力的技术创新。
智能进化论:对于投身具身智能领域的年轻人,有什么建议?
李鸿升:具身智能对知识面的要求更广,既要懂软件,也要懂硬件,很多工作还需要上真机验证,所以周期会比传统AI大模型更长。也正因为如此,年轻人更需要耐心,真正把工作做到真实场景里,影响力才会更大。
END
本文为「智能进化论」原创作品。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 0
0 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)