Vibe Coding狂飙带来的生产安全危机:AI生成后端代码的分层韧性工程——Skills、Harness与工程防线
摘要: 2026 年,AI 编码助手已能生成"看起来正确"的后端代码,但生产环境正爆发一场"静默危机"——N+1 查询在凌晨拖垮数据库,竞态条件导致重复扣款,连接池泄漏让服务假死。新兴的 Skills(结构化知识包)和 Harness(AI 工程控制框架,含 Hooks、Guardrails、State Persistence 等)提供了第一层防线,但无法替代确定性工程工具。本文基于 GitHub Issues、Reddit 事故复盘、Snyk 安全研究和真实企业案例,深度剖析问题本质与分层破局方案。
一、引言:当"Vibe Coding"撞上生产环境
2026 年,"Vibe Coding"(氛围编程)已成为开发者日常。你描述需求,AI 生成代码,本地测试通过,合并,部署——一切看起来顺利。直到凌晨 3 点,PagerDuty 尖叫:数据库 CPU 100%,支付系统重复扣款,连接池耗尽导致级联故障。
这不是虚构。根据 Snyk 2026 年 2 月的 ToxicSkills 研究,AI 生成的代码中 36.8% 存在安全缺陷,13.4% 含关键级别问题。Semgrep 组织委托 Claude Code (Sonnet 4) 和 OpenAI Codex 扫描 11 个开源 Python Web 应用的研究显示,Claude Code 安全审查的真阳性率仅 14%,假阳性率高达 86%。运行相同提示三次,结果从 3 个到 11 个发现不等——非确定性审查正在试图守护非确定性代码。
更讽刺的是,AI 安全工具本身也成了攻击目标。2026 年 1 月的 ClawHavoc 事件中,数百至上千个恶意 AI Skill(不同安全团队报告数量从 341 到 1,200+ 不等) 通过看似无害的 SKILL.md 文件,诱导用户输入系统密码,进而窃取浏览器凭证、SSH 密钥和加密货币钱包数据。
这不是 AI 的错。这是工程范式的错配——我们用单线程、小数据量、无并发的本地测试,去验证将在高并发、网络抖动、硬件故障的真实世界中运行的代码。
二、问题的本质:为什么 AI 代码"看起来正确"却生产爆炸
2.1 测试环境与生产环境的"维度差异"
|
维度 |
本地测试 |
生产环境 |
|---|---|---|
| 并发 |
单线程/低并发 |
数千 QPS,竞态条件 |
| 数据量 |
百级记录 |
千万级,深分页杀死性能 |
| 网络 |
本地 127.0.0.1 |
跨可用区延迟、丢包、超时 |
| 时间 |
秒级运行 |
小时/天级,内存泄漏累积 |
| 依赖 |
全部健康 |
下游服务随时故障 |
| 输入 |
预期值 |
恶意构造、边界条件、乱码 |
AI 在训练时见过无数代码模式,但它没有见过你的生产环境。它生成的代码在"平均情况"下正确,但工程系统的可靠性取决于"最坏情况"下的表现。
2.2 AI 的"认知盲区"
基于对 GitHub Issues、Reddit r/programming、Hacker News 和多个企业事故复盘的分析,AI 生成代码存在系统性盲区:
盲区一:并发与分布式状态AI 理解"锁"的概念,但不理解分布式锁的过期时间、锁被覆盖后的超卖、Redis 主从切换时的锁丢失。它生成的库存扣减代码通常是 UPDATE stock SET count = count - 1,这在单线程下正确,在并发下就是灾难。
盲区二:资源的时间维度AI 知道"要关闭连接",但生成的代码可能在异常分支中忘记释放。它不理解连接池泄漏是渐进式的——运行 5 小时后才暴露,而本地测试只跑 30 秒。
盲区三:故障的级联效应AI 知道"失败了要重试",但生成的重试逻辑往往是固定间隔、无退避、无熔断。它不理解重试流量放大效应:在级联重试架构中,若每层服务对下游发起多次重试,底层服务可能面临数倍甚至数量级的流量压力。例如,上游 3 次重试叠加下游 3 次重试,流量可被放大一个数量级,直接打垮故障服务。
盲区四:业务的隐性约束AI 不理解状态机不能跳过中间态(created → shipped 跳过 paid),不理解优惠券不能重复使用,不理解库存不能为负数——这些需要领域知识,而领域知识不在训练数据中。
三、2026 年的"静默危机":真实事故全景
3.1 数据库层:N+1 查询与深分页
事故:某电商平台使用 AI 生成的订单列表接口,本地 100 条数据测试响应 200ms。上线后,大促期间数据库 CPU 飙升至 100%,服务不可用。
根因:AI 使用了 ORM 的懒加载模式,循环遍历订单列表时,每条订单触发一次关联查询。100 条订单 = 1 次主查询 + 100 次关联查询。生产环境 10,000 条订单时,数据库连接池瞬间耗尽。
AI 的盲区:它知道"要优化查询",但默认选择了最直观的实现方式。它不会主动分析执行计划,不会问"这个查询在大数据量下会怎样"。
3.2 并发层:重复扣款与库存超卖
事故:某 SaaS 平台使用 AI 生成的支付代码,上线第一周遭遇 14 万美元重复扣款。
# AI 生成的"正确"代码
if not order.processed:
charge()
order.processed = True两个并发请求同时读到 processed=False,同时执行 charge()。AI 没有生成分布式锁、没有数据库唯一约束、没有幂等性校验。
更隐蔽的变体:AI 生成了 Redis 分布式锁,但锁过期时间固定为 5 秒。业务执行超时后锁被其他线程获取,导致超卖 100 瓶茅台。
3.3 资源层:连接池泄漏与请求挂起
事故:某金融应用使用 AI 生成的批量处理作业,部署后 5 小时连接池耗尽,12,000 用户受影响,损失 $45,000。
根因:AI 在异常分支中忘记释放数据库连接。更致命的是,AI 调用外部 API 时没有设置超时,网络抖动时请求永久挂起,连接池被僵尸请求占满。
真实案例:Claude Code MCP Server 因无超时机制,挂起 16+ 小时,产生 70+ 僵尸进程。
3.4 架构层:级联故障与重试风暴
事故:某微服务架构在下游支付服务故障时,整个系统崩溃。
根因:AI 为每个服务生成了"健壮"的重试逻辑:
for (let i = 0; i < 3; i++) {
await paymentAPI.retry(order);
}没有指数退避、没有熔断器、没有幂等性。下游故障时,重试请求在级联架构中逐层放大,底层服务可能面临数倍至一个数量级的流量压力,形成重试风暴(Retry Storm)。
四、破局之道:从"单点防御"到"分层韧性"
2026 年的 AI 工程安全不是单一工具能解决的。它需要Harness 工程——围绕 AI Agent 构建的完整控制框架——与传统工程工具的深度协作。
Harness 工程的五组件模型(源自 Anthropic Engineering 2026 年 3 月的 canonical post):
|
组件 |
功能 |
对应本文中的工具层 |
|---|---|---|
| Control Loop |
管理 Agent 的决策循环、预算、迭代次数 |
CI/CD 流水线、审批流程 |
| State Persistence |
每 N 步持久化状态,支持崩溃后恢复 |
版本控制、数据库 |
| Crash Recovery |
从最近持久化状态自动恢复 |
混沌工程、故障演练 |
| Telemetry |
结构化日志、Token 消耗、工具调用监控 |
Sentry、Datadog、Hud |
| Guardrails |
硬限制:预算、时间、工具列表、禁止操作 |
Hooks、SAST、权限系统 |
本文将 Harness 中的 Guardrails(以 Hooks 为具体实现)作为第二层,与 Skills(第一层)、传统 SAST(第三层)、混沌工程(第四层)和运行时监控(第五层)共同构成分层防御体系。
4.1 第一层:Skills——给 AI 注入领域知识
2026 年兴起的 SKILL.md 格式,是跨平台的 AI Agent 可复用指令包。Claude Code、Codex、OpenClaw 等平台均支持。它不是简单的提示词,而是结构化的工程知识编码。
重要区分:Skills(SKILL.md)是跨平台通用的知识包格式;而 Hooks(如 pre_tool_use.py)是 Claude Code 的执行时拦截机制。两者互补但属于不同层次:Skills 提供"应该知道什么",Hooks 提供"必须遵守什么"。
安全审查 Skill 示例:
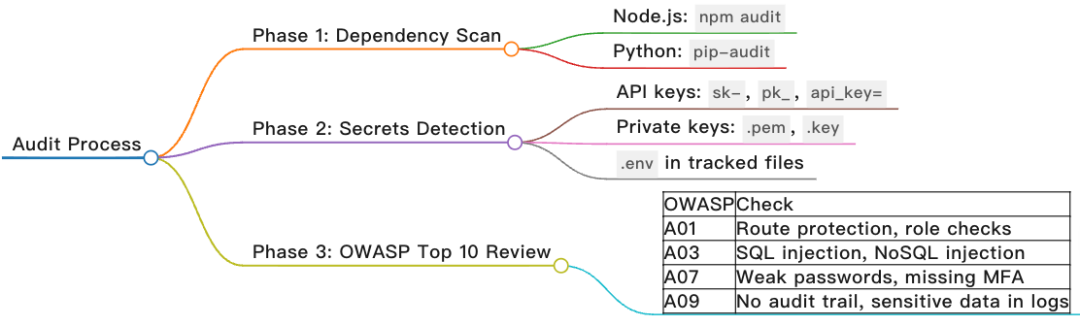
这张图展示了一个三阶段安全审计流程,从依赖扫描到 OWASP 合规审查:
|
阶段 |
目标 |
具体检查项 |
|---|---|---|
| Phase 1: Dependency Scan(依赖扫描) |
发现第三方组件漏洞 |
• Node.js: |
| Phase 2: Secrets Detection(密钥泄露检测) |
防止敏感凭证提交到代码库 |
• API keys: 检测 |
| Phase 3: OWASP Top 10 Review(OWASP 十大风险审查) |
对照行业标准检查常见安全缺陷 |
• A01 — 访问控制:路由保护、角色权限检查• A03 — 注入攻击:SQL 注入、NoSQL 注入防护• A07 — 认证缺陷:弱密码策略、缺失多因素认证(MFA)• A09 — 日志与审计:缺少审计追踪、日志中泄露敏感数据 |
核心思想:安全左移(Shift Left)——在开发阶段就嵌入安全检查,而非等到上线后。
数据库安全 Skill:

这张图列出了6 条数据库开发铁律,聚焦性能与稳定性:
|
规则 |
解读 |
|---|---|
| All queries use parameterized statements |
所有查询必须使用参数化语句(Prepared Statements),彻底杜绝 SQL 注入 |
| N+1 patterns detected and eliminated |
检测并消除 N+1 查询问题。解决方案:使用 JOIN 或批量加载(batch loading)减少数据库往返次数 |
| Deep pagination uses cursor-based pagination, not OFFSET |
深度分页必须使用游标分页(Cursor-based),禁止使用 |
| All external queries have timeout settings |
所有外部查询必须设置超时,防止慢查询拖垮整个系统 |
| Connection pool size configured and monitored |
连接池大小必须配置并监控,避免连接泄漏或池耗尽 |
| EXPLAIN ANALYZE run on all new queries |
所有新查询上线前必须执行 |
核心思想:数据库是系统的瓶颈和命脉,这些规则兼顾了安全性(防注入)、性能(防 N+1、深度分页优化)和稳定性(超时、连接池监控)。
并发安全 Skill:

这张图列出了分布式/高并发环境下的 5 条可靠性规则:
|
规则 |
解读 |
|---|---|
| Distributed locks have unique owner IDs and renewal mechanisms |
分布式锁必须有唯一持有者 ID 和续期机制。防止锁被其他实例误释放,或因持有者崩溃导致死锁 |
| All state transitions are atomic (database-level, not application-level) |
所有状态转换必须是数据库级原子操作,不能依赖应用层的事务逻辑。利用数据库的 ACID 特性保证一致性 |
| Retry logic uses exponential backoff with jitter |
重试逻辑必须使用指数退避 + 抖动。避免 thundering herd(惊群效应)——所有失败请求同时重试压垮服务 |
| Circuit breaker configured for all external calls |
所有外部调用必须配置熔断器(Circuit Breaker)。防止下游故障级联扩散到整个系统 |
| Idempotency keys used for all mutating operations |
所有写操作必须使用幂等键(Idempotency Keys)。确保网络超时或重试时不会导致重复处理 |
核心思想:在分布式系统中,网络不可靠、时钟不同步、故障常态化。这些规则通过锁、原子性、退避、熔断、幂等五大机制,构建系统的容错能力。
Skills 的价值:将团队的工程经验编码为 AI 的"肌肉记忆",减少常见错误的重复发生。Anthropic 内部数据显示,PR 安全相关评论减少 30-40%。
Skills 的局限:它是建议性的,不是强制性的。AI 可以"忘记"或"忽略" Skill 指令,尤其是在长会话后上下文压缩时。
4.2 第二层:Harness 工程——确定性强制执行
Harness 工程是 2026 年兴起的 AI 系统设计范式,指围绕 AI Agent 构建的完整控制框架,包含五个核心组件:Control Loop(控制循环)、State Persistence(状态持久化)、Crash Recovery(故障恢复)、Telemetry(可观测性)和 Guardrails(安全护栏)。Hooks 只是 Guardrails 在 Claude Code 中的具体实现之一。
与 Skills 的"建议"不同,Harness 中的 Hooks 是代码层面的执行拦截。Claude Code 的 Hooks 系统允许在 Agent 生命周期的关键点执行用户定义的 shell 命令。
"A system prompt is a request. A hook is closer to a guarantee—but not absolute."
注意:Hooks 在设计上意图在权限检查前拦截,但存在已知边界情况。例如 --dangerously-skip-permissions 模式下的行为在不同版本中表现不一致,GitHub Issues 上也有相关 bug 报告。Hooks 是强约束,但不是不可绕过的铁律。
Harness 的完整能力远不止 Hooks:状态持久化确保长时任务崩溃后可恢复;Telemetry 提供全链路可观测性;Control Loop 管理预算、迭代次数和工具调用速率——这些共同构成 AI 系统的"韧性骨架"。
PreToolUse Hook——危险操作物理阻断:
#!/usr/bin/env python3
# .claude/hooks/pre_tool_use.py
import json, sys, re
BLOCKED_PATTERNS = [
r"rm\s+-rf\s+/",
r"DROP\s+TABLE",
r"git\s+push\s+--force",
r">\s+/dev/sda"
]
PROTECTED_PATHS = [".env", ".git/", ".ssh/", "/etc/passwd"]
input_data = json.load(sys.stdin)
tool = input_data.get("tool", {})
command = tool.get("command", "")
# 阻断破坏性命令
for pattern in BLOCKED_PATTERNS:
if re.search(pattern, command, re.IGNORECASE):
print(json.dumps({
"decision": "deny",
"reason": f"Blocked dangerous command: {command}"
}))
sys.exit(0)
# 阻断敏感文件访问
for path in PROTECTED_PATHS:
if path in command:
print(json.dumps({
"decision": "deny",
"reason": f"Access to protected path: {path}"
}))
sys.exit(0)
print(json.dumps({"decision": "allow"}))关键特性:PreToolUse 的 deny 决策在权限模式检查之前评估,在标准模式下提供强约束。但需注意:GitHub Issues 上有报告表明 --dangerously-skip-permissions 等极端模式可能影响 Hooks 行为,Hooks 是强约束而非绝对保证。
PostToolUse Hook——自动质量门禁:
#!/usr/bin/env python3
# .claude/hooks/post_tool_use.py
import json, sys, subprocess
input_data = json.load(sys.stdin)
tool = input_data.get("tool", {})
if tool.get("name") in ["Edit", "Write"]:
file_path = tool.get("file_path", "")
# 自动格式化
if file_path.endswith(".py"):
subprocess.run(["black", file_path], capture_output=True)
# 类型检查
if file_path.endswith(".py"):
result = subprocess.run(
["mypy", file_path],
capture_output=True, text=True
)
if result.returncode != 0:
print(json.dumps({
"feedback": f"Type error in {file_path}: {result.stdout}"
}))
# 安全扫描
result = subprocess.run(
["semgrep", "--config=auto", file_path],
capture_output=True, text=True
)
if " findings" in result.stdout:
print(json.dumps({
"feedback": f"Security issue detected: {result.stdout}"
}))Stop Hook——回合结束安全审查:
#!/usr/bin/env python3
# .claude/hooks/stop.py
import json, sys, subprocess
# 获取本次会话的 git diff
result = subprocess.run(
["git", "diff", "HEAD"],
capture_output=True, text=True
)
diff = result.stdout
# 调用安全审查模型
if diff:
review = subprocess.run(
["claude", "security-review", "--stdin"],
input=diff, capture_output=True, text=True
)
print(json.dumps({
"feedback": f"Security review: {review.stdout}"
}))Hooks 的价值:将"人的审查"转化为"机器的执行",消除人为疏忽和疲劳。93% 的权限提示被用户习惯性批准——Hooks 不依赖人的注意力。
Hooks 的局限:
-
只能拦截已知的危险模式,无法发现未知的业务逻辑缺陷
-
无法验证运行时行为(竞态条件、性能瓶颈、内存泄漏)
-
配置复杂,需要维护 Hook 脚本本身的安全性
4.3 第三层:传统 SAST——确定性规则引擎
AI 审查 AI 是危险的。我们需要确定性的、可重复的、可审计的安全工具。
|
工具 |
核心能力 |
为什么不可替代 |
|---|---|---|
| Semgrep |
社区规则覆盖 30+ 语言,可自定义规则 |
规则是代码,不是提示词;结果 100% 可重复 |
| SonarQube |
深度安全扫描,合规检测(PCI、OWASP) |
支持 30+ 语言,企业级审计追踪 |
| CodeQL |
语义级查询,跨代码库查找模式 |
发现跨文件的 taint flow,AI 难以做到 |
| Bandit |
Python 专用,检测 assert 用于生产、弱加密 |
零配置,即装即用 |
关键差异:传统 SAST 的假阳性率可控,AI 审查的假阳性率不可控。在安全领域,"不可控"意味着不可信任。
4.4 第四层:混沌工程——在故障中验证韧性
"传统代码审查问:'这段代码是否做了它声称的事?' 混沌工程问:'当一切出错时,这段代码会做什么?'"
混沌工程实践:针对 AI 生成代码的韧性验证,需要专门的故障注入测试。现有工具链包括:
-
通用混沌工程平台:Chaos Mesh(云原生,注入 Pod 故障、网络分区、磁盘压力)、Gremlin(基础设施层故障注入)
-
LLM 特定测试:社区中有实验性项目(如 deepankarm/agent-chaos)尝试对 LLM API 注入 rate limit、timeout 等故障,测试 Agent 恢复能力,但尚未形成企业级标准工具
-
自定义脚本:团队可编写针对性测试,模拟下游服务延迟、数据库连接超时、网络分区等场景
关键测试场景:
-
下游服务延迟:检测无退避重试是否导致重试风暴
-
数据库连接超时:检测连接池是否泄漏
-
网络分区:检测分布式锁是否失效
-
内存压力:检测批量处理是否溢出
混沌工程的价值:发现 AI 代码在"最坏情况"下的行为,而 Skills/Hooks 只能验证"正常情况"。
4.5 第五层:运行时监控——生产环境的"最后防线"
|
工具 |
核心能力 |
为什么必须 |
|---|---|---|
| Hud |
函数级运行时数据流式传输到 AI 编码工具 |
连接运行时行为与代码路径 |
| Sentry |
自动检测慢 DB 查询,AI 分析根因 |
生产故障快速定位 |
| Datadog / ELK |
海量日志异常模式聚类 |
大规模日志分析 |
| Lightrun |
运行态动态注入探针,无需重启 |
怀疑变量值但无日志时的现场诊断 |
关键监控维度:
-
延迟:P50/P95/P99,识别长尾延迟
-
错误率:按错误类型分类,识别新模式
-
吞吐量:与资源使用率关联,识别瓶颈
-
连接池:活跃连接数、等待队列长度、泄漏检测
-
业务指标:订单成功率、支付重复率、库存准确率
五、企业级治理:从"个人工具"到"组织平台"
5.1 风险分级与 autonomy 拨盘
不是所有代码都需要同等审查。根据 行业通行的风险分级原则(参考 NIST AI RMF 和 OWASP 风险评级方法):
|
工作流 |
风险等级 |
AI 角色 |
安全要求 |
|---|---|---|---|
|
内部 FAQ 搜索 |
低 |
自动化 |
文档权限 |
|
客户支持回复草稿 |
中 |
辅助+人工审批 |
工单上下文、审计日志 |
|
CRM 线索评分 |
中 |
推荐 |
字段级访问 |
|
退款审批 |
高 |
草稿+人工审批 |
策略证据、限额阈值 |
|
支付发起 |
极高 |
禁止自动化 |
无自主操作 |
5.2 政策即代码(Policy as Code)
在 .claude/CLAUDE.md 中定义不可协商的规则:

|
序号 |
规则 |
安全威胁 |
实践方式 |
|---|---|---|---|
| 1 | All database queries MUST use parameterized statements. |
SQL 注入 |
禁止字符串拼接 SQL,强制使用 ORM 参数绑定或 PreparedStatement |
| 2 | API endpoints MUST have authentication middleware. |
未授权访问 |
所有路由默认拒绝,显式配置中间件后才开放;禁止"先开发后补认证" |
| 3 | No hardcoded secrets in configuration files. |
密钥泄露 |
使用环境变量、密钥管理服务(KMS)、或 Vault;代码扫描检测硬编码 |
| 4 | All external calls MUST have timeout and circuit breaker. |
级联故障、服务雪崩 |
调用下游 API 时必须同时配置超时时间和熔断策略 |
| 5 | All mutating operations MUST be idempotent. |
重复提交、数据不一致 |
支付、下单等写操作必须携带幂等键(Idempotency Key) |
| 6 | No eval() or child_process.exec() with user input. |
远程代码执行(RCE) |
永远不信任用户输入,禁止将其传入执行函数 |
5.3 CI/CD 安全流水线
# .github/workflows/security.yml
name: Security Pipeline
on:
pull_request:
push:
branches: [main]
jobs:
pre-commit:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- name: Secret Scanning
uses: gitleaks/gitleaks-action@v2
- name: Dependency Audit
run: npm audit --audit-level=moderate
sast:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- name: Semgrep Scan
uses: returntocorp/semgrep-action@v1
with:
config: >-
p/security-audit
p/owasp-top-ten
- name: SonarQube Scan
uses: sonarqube-quality-gate-action@master
ai-review:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- name: Claude Code Security Review
uses: anthropics/claude-code-security-review@main
with:
claude-api-key: ${{ secrets.CLAUDE_API_KEY }}
- name: Pact Contract Test
run: pact verify --provider-base-url http://localhost:8080
chaos:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- name: Chaos Engineering
run: |
agent-chaos --scenario=llm-api-failure
agent-chaos --scenario=database-timeout
agent-chaos --scenario=network-partition
deploy-gate:
needs: [pre-commit, sast, ai-review, chaos]
runs-on: ubuntu-latest
steps:
- name: Require Security Approval
run: |
if [ "${{ github.actor }}" != "security-team" ]; then
echo "Security approval required"
exit 1
fi5.4 技能供应链安全
基于 OWASP Agentic Skills Top 10 的治理:
-
清单管理:维护所有已安装 Skills 的清单,定期审计
-
来源验证:仅从 Skills.sh(Vercel + Snyk 扫描)等可信注册表安装
-
版本锁定:锁定 Skill 版本,防止更新漂移
-
权限最小化:使用
allowed-tools限制 Skill 的工具访问 -
签名验证:要求 Skill 发布者使用 ed25519 签名
六、未来展望:从"辅助编码"到"韧性工程"
6.1 AI 的进化方向
2026 年的 AI 编码助手正在从"代码生成器"进化为"工程伙伴":
-
上下文感知:理解整个代码库的依赖关系,而非单文件
-
运行时学习:从生产监控数据中学习,调整生成策略
-
多 Agent 协作:安全审查 Agent、性能优化 Agent、测试生成 Agent 协同工作
-
确定性输出:通过约束解码(Constrained Decoding)确保输出符合安全模式
6.2 人的角色转变
开发者从"代码编写者"转变为:
-
架构设计师:定义系统边界和约束
-
安全策略师:制定不可协商的规则
-
混沌工程师:设计故障场景,验证系统韧性
-
AI 训练师:编写高质量的 Skills,传授领域知识
6.3 终极愿景:自愈系统
未来的 AI 系统可能具备:
-
自监控:自动检测异常行为
-
自诊断:定位根因,关联代码变更
-
自修复:在人工审批下自动修复已知问题
-
自验证:通过混沌工程持续验证韧性
但这需要确定性基础——只有在 Hooks、SAST、混沌工程构成的坚实地基上,AI 的"创造力"才能安全释放。
七、结语:警惕"技术乐观主义"的陷阱
2026 年的 AI 编码革命是真实的。它确实提高了开发效率,降低了入门门槛。但效率的提升不能牺牲安全的底线。
历史在重复:
-
2010 年代,npm 生态的"依赖地狱"教会我们锁定版本
-
2020 年代,Log4j 漏洞教会我们供应链安全
-
2026 年代,AI 生成代码的"静默危机"正在教会我们分层韧性
Skills 和 Harness 工程是重要的一步,但不是最后一步。Skills 解决"应该知道什么"的知识传递问题;Harness 解决"必须遵守什么"的执行约束问题。但两者都无法替代"未知问题"的探索——这需要混沌工程、运行时监控和领域专家的持续投入。真正的安全来自于:
-
确定性工具(SAST、类型系统、混沌工程)处理可重复的问题
-
AI 工具(Skills、Hooks)处理模式化的知识传递
-
人类判断处理领域特定的、创造性的、伦理性的决策
"The best developers I know use all three poorly before they use any of them well." — 出自 2026 年 Cursor、Claude Code 与 OpenCode 的对比评测文章
在 AI 时代,怀疑精神是宝贵的工程素养。对 AI 生成的每一行代码保持警惕,对每一个"看起来正确"的假设保持质疑,对每一次"本地测试通过"保持谦逊——因为生产环境,永远比你想象的更复杂。
参考与延伸阅读
-
OWASP Agentic Skills Top 10 (2026) (https://owasp.org/www-project-agentic-skills-top-10/)
-
Snyk ToxicSkills Report (Feb 2026) (https://snyk.io/blog/toxicskills-malicious-ai-agent-skills-clawhub/)
-
Claude Code Security Documentation (https://code.claude.com/docs/en/security-guidance)
-
Anthropic Claude Code Security Best Practices (https://generalanalysis.com/guides/anthropic-claude-code-security-best-practices)
-
Semgrep: Finding vulnerabilities in modern web apps using Claude Code and OpenAI Codex (https://semgrep.dev/blog/2025/finding-vulnerabilities-in-modern-web-apps-using-claude-code-and-openai-codex)
-
NIST AI Risk Management Framework (https://www.nist.gov/artificial-intelligence)
本文基于 2026 年 6 月的公开资料、GitHub Issues、安全研究报告和企业实践整理。
创作不易,禁止抄袭,转载请附上原文链接及标题

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 5
5 0
0- 0



 已为社区贡献26条内容
已为社区贡献26条内容

所有评论(0)