山东大学项目实训个人纪实(5)——降低对话延迟
在初步实现了“医患沟通评价系统”的 AI 对话功能后,我很快遇到了一个严重影响交互体验的问题——对话延迟过高。
当时系统的运行链路是:前端采集音频 -> 后端语音转文字(ASR) -> 后端大模型(LLM)生成文本 -> 后端文本转语音(TTS) -> 前端读取音频并播放。
这种传统的链条存在两个明显的延迟瓶颈:
-
非流式输出:系统必须等待大模型和语音合成完整生成后,才能将音频整体输出给前端,导致单次对话的延迟高达 10 秒左右。
-
磁盘文件锁:由于音频文件是作为 WAV 格式存储在电脑本地的,频繁的读写操作带来了不可忽视的磁盘 I/O 延迟与文件锁等待。
为了改善这一体验,我决定尝试“全链路流式传输”的方案:消灭本地文件读写,将数据流完全保留在内存中,并让大模型和语音实现流式输出。
第一步:大模型与 TTS 的流式对接
首先,我开启了 DeepSeek 的流式输出。后端在接收到文本流后,通过标点符号进行切片,并同步送入 TTS 进行语音合成。
在技术调研中我发现,阿里云的 TTS 可以返回 Base64 编码的原始 PCM 数据。为了避免磁盘读写带来的延迟,我省去了保存本地文件的步骤,选择直接将这串 Base64 编码的字符通过网络发送给前端。
第二步:前端异步接收 SSE 数据
在前后端通信方面,我计划使用 SSE(Server-Sent Events)。但比较棘手的是,虚幻引擎常用的 VaRest 插件以及官方的 HTTP 蓝图节点并不支持 SSE 协议。
没有现成的轮子可用,我只能自己编写了一个支持 SSE 异步接收数据的 C++ 程序,并将接口通过蓝图暴露出来(也就是图中的 ConnectToSSE 函数)。这样,一旦后端有音频切片发出,前端就能立刻捕捉到信号并进入下一步处理。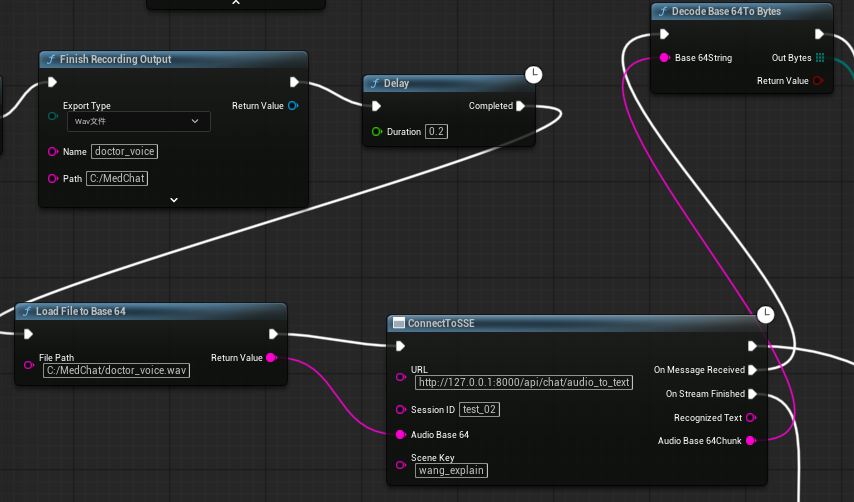
第三步:攻克前端内存数据转换(Base64 转 SoundWave)
数据顺利传到了前端,但由于接收到的是 Base64 字符,为了避免写入磁盘,我需要直接在内存中将其还原为虚幻引擎能够识别并播放的 SoundWave。
这一步成为了整个开发过程中最让我头疼的坎。翻遍了国内外的技术资料,几乎找不到现成的插件,也没有现成的实现方案,只能自己硬着头皮去摸索底层的实现机制。
原本我打算使用 RuntimeAudioImporter 插件,但很快就碰了壁。因为 Audio2Face 插件在底层有一个硬性限制:它需要对音频进行实时的多线程代理分析(CreateSoundWaveProxy),而虚幻引擎的官方源码明确规定,程序化音频(Procedural)是不允许创建分析代理的。不幸的是,上述插件生成的恰恰就是程序化音频。
走通无望后,我只能去剖析 SoundWave 的底层架构,尝试手动去构建一个兼容的 SoundWave。
研究后发现,SoundWave 内部有两个关键的数据结构:
-
RawPCMData:虚幻引擎音频组件读取并用于播放声音的区域。
-
RawData:Audio2Face 插件读取并用于计算唇形同步的区域(且要求为 WAV 格式)。
为了能同时实现“听到声音”和“嘴型对上”,我需要将解码后的二进制数据同时注入到这两个 buffer 中。经过反复的调试,这个内存直接写入的方案终于跑通了。
阶段性反馈与后续规划
经过这一轮的延迟专项优化,系统的整体对话延迟从原先的 10 秒以上,缩短到了约 3 秒。虽然还做不到即时响应,但在日常的人机对话中,已经属于勉强可容忍的范围了。
不过,这也暴露出了一些新的问题,成了我下一步需要着手解决的方向:
-
通过肢体动作缓解等待焦虑:从人机交互设计的角度出发,我打算为虚拟角色制作一些肢体动作或等待阶段的手势。适当的动态反馈可以在视觉上分散用户的注意力,从而从侧面缓解等待延迟带来的负面感受。
-
唇形同步的性能优化:目前这套方案对硬件配置的要求非常苛刻。我手头 16GB 内存的笔记本运行起来有明显的卡顿,换到 64GB 内存的台式机上才能勉强保持流畅。下一步我需要调研是否有性能开销更低、更轻量级的口型同步替代方案,争取把运行门槛降下来。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 9
9 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)