Spring AI Agents 智能体模式实战
Spring AI Agents:从固定流程到智能协作
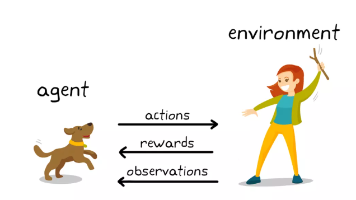
在 AI 应用里,Agent 不是一个会聊天的接口,也不是简单地把大模型套进业务系统。更准确地说,Agent 是一种能够围绕目标自主工作的智能软件实体。它可以接收环境输入,理解任务意图,规划执行路径,并在需要时调用工具或外部服务,最终完成用户交给它的目标。
比如用户只说:“帮我把项目的单元测试覆盖率提升到 80%。”普通聊天模型可能会给出建议,而 Agent 更进一步:它会查看代码结构、判断缺失测试的位置、补充测试用例、运行构建、分析失败原因,再继续修正,直到目标接近完成。这里的关键不是“模型更聪明”,而是流程的控制权开始由大模型动态参与。
Agent 和 Workflow 的区别
Workflow 更像提前写好的流程。步骤清晰、顺序固定、由代码驱动,适合客服工单处理、审批流、报表生成这类边界明确的任务。只要输入满足预期,流程就能稳定执行。
Agent 则更适合开放式问题。它不一定事先知道完整步骤,而是根据任务和中间结果不断判断下一步该做什么。遇到异常时,它可以调整方向;发现信息不足时,它可以补充检索;需要行动时,它可以调用工具。
可以这样理解:
| 类型 | 控制方式 | 特点 | 适用场景 |
|---|---|---|---|
| Workflow | 代码驱动 | 流程固定,步骤预设 | 明确、可拆解、可重复的任务 |
| Agent | LLM 动态决策 | 自主规划,灵活调整 | 开放问题、多步骤推理、复杂协作 |
当多个 Agent 按照角色分工协同工作时,就形成了 Agents,也就是多智能体系统。它不是让一个“全能助手”包办所有事,而是把任务拆给不同角色:有的负责规划,有的负责执行,有的负责评估,有的负责优化。
Chain Workflow:把复杂任务拆成有序链路
链式工作流适合处理步骤之间有强依赖关系的任务。每一步只做一件事,前一步的输出会作为后一步的输入,最终形成一条稳定的数据处理链。
一个典型例子是分析季度业务总结:
- 从原始文本中提取指标和数值。
- 将分数、百分比、小数统一成标准格式。
- 按数值从高到低排序。
- 输出 Markdown 表格。
这种模式的价值在于降低单次推理难度。与其让模型一次性完成“理解、提取、转换、排序、排版”所有动作,不如把任务拆成多个更小的 LLM 调用。每次调用都只关注一个目标,准确率和可控性都会更好。
在 Spring AI 中,可以通过 ChatClient 依次执行多个系统提示词。实现时通常维护一个 response 变量,初始值是用户输入,每轮把上一次结果和当前提示词组合后发送给模型,最后返回经过多轮加工的结果。
这种方式适合数据清洗、结构化提取、报告整理、内容改写等任务。它的代价是延迟更高,因为需要多次调用模型,所以更适合质量优先的场景。
Parallelization Workflow:让独立任务并发执行
并行化工作流适合多个子任务彼此独立的情况。比如要分析数字化转型对销售部、技术部、人力资源部、财务部的影响,这些输入之间没有依赖关系,可以同时发起多个 LLM 调用。
常见实现方式是使用 ExecutorService 和 CompletableFuture:
ExecutorService executor = Executors.newFixedThreadPool(nWorkers);
List<CompletableFuture<String>> futures = inputs.stream()
.map(input -> CompletableFuture.supplyAsync(() ->
chatClient.prompt(prompt + "\nInput: " + input)
.call()
.content(), executor))
.toList();
CompletableFuture.allOf(futures.toArray(CompletableFuture[]::new)).join();
并行化的重点有三个:
- 控制线程池大小,避免瞬间压垮模型服务或触发限流。
- 保持结果顺序,让输出与原始输入一一对应。
- 做好异常包装和资源释放,确保任务失败时问题可追踪。
这种模式适合批量分类、批量摘要、多部门分析、多候选方案生成等任务。它不能提升单个模型请求的速度,但能显著缩短整体批处理时间。
Routing Workflow:先判断类型,再交给专家
路由模式的核心是“先分类,再处理”。系统先判断用户请求属于哪一类,再选择最合适的提示词、模型、工具或业务流程。
比如客服系统中,用户的问题可能来自不同方向:
| 输入类型 | 处理路径 |
|---|---|
| 账单、扣费、退款 | 财务助手 |
| 登录失败、系统报错 | 技术支持 |
| 密码重置、安全验证 | 账户助手 |
| 功能咨询、使用建议 | 产品顾问 |
如果把所有问题都丢给同一个提示词处理,模型容易回答得泛泛而谈。路由模式让系统先理解意图,再分发给对应的“专家模块”,回答会更稳定,也更贴近业务。
实现时可以让模型输出结构化 JSON,例如:
{
"reasoning": "用户提到忘记密码和无法登录,属于账户访问问题",
"selection": "账户"
}
拿到 selection 后,再选择对应提示词进行二次处理。这个模式的关键是分类必须足够可靠,并且要为无法判断的情况准备兜底路径。
Orchestrator-Workers:先规划,再分工
编排器和工作者模式更接近多智能体协作。它通常包含三个步骤:
- Orchestrator 分析任务,拆解成多个子任务。
- Workers 分别处理各自负责的方向。
- 系统聚合多个输出,形成最终结果。
比如用户要求“为一款新型环保可重复使用的保温杯撰写产品介绍文案”。编排器可以把任务拆成“专业参数版”“亲民体验版”“电商转化版”。不同 Worker 根据不同风格生成内容,最终系统把结果统一交付。
这种模式特别适合无法提前确定子任务数量和方向的场景。与链式工作流不同,它不是预先写死每一步,而是由编排器根据任务动态拆解。它比单次调用更灵活,也比纯 Agent 更容易控制。
需要注意的是,Worker 并不一定真的要部署成多个服务。在早期实现中,它们可以只是多次 ChatClient 调用,但在架构上已经具备多角色协作的思想。
Evaluator-Optimizer:让结果在反馈中变好
评估和优化循环用于解决“一次生成不够好”的问题。它引入两个角色:
| 角色 | 职责 |
|---|---|
| Generator | 生成初稿或解决方案 |
| Evaluator | 根据标准评估质量,并给出反馈 |
流程通常是:
- Generator 根据任务生成结果。
- Evaluator 判断结果是
PASS、NEEDS_IMPROVEMENT还是FAIL。 - 如果没有通过,就把历史尝试和反馈重新交给 Generator。
- 循环迭代,直到结果合格或达到最大次数。
这类模式很适合高质量文案、正式邮件、数据分析报告、合规回复等任务。它让 AI 不再只是一次性回答,而是像写作一样经历“初稿、批改、修改”的过程。
不过工程上必须设置最大迭代次数。否则一旦评估器过于严格,系统可能陷入无限循环。并且每轮都要调用模型,成本和延迟都会增加,所以要根据业务价值决定是否使用。
如何选择合适的模式
选择模式时,可以从任务特征出发:
| 任务特征 | 推荐模式 |
|---|---|
| 步骤固定,前后强依赖 | Chain Workflow |
| 多个任务互不依赖 | Parallelization Workflow |
| 输入类型差异明显 | Routing Workflow |
| 任务复杂,需要动态拆解 | Orchestrator-Workers |
| 对质量要求高,需要反复打磨 | Evaluator-Optimizer |
真正的 AI 工程不是把所有能力都塞进一个提示词里,而是根据任务特点设计合适的执行结构。Spring AI 提供的这些基础模式,本质上是在帮助我们把大模型从“问答组件”升级为“可编排、可协作、可优化”的智能系统。
当业务流程明确时,用 Workflow 保持稳定;当任务开放且需要自主判断时,引入 Agent;当问题复杂到单个角色难以完成时,再进一步组合多个智能体。这样设计出来的 AI 应用,才更接近真实生产环境需要的可靠形态。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 1
1 0
0- 0



 已为社区贡献16条内容
已为社区贡献16条内容

所有评论(0)