PP-OCRv6 太强了:50种语言一套模型,本地离线部署我帮你整理好了
这几天,PP-OCRv6 正式发布。根据官方发布信息,新版本已于 2026 年 6 月 11 日上线,在内部多场景综合评估集上,PP-OCRv6_medium 相比 PP-OCRv5_server 识别精度提升 5.1%、检测精度提升 4.6%,同时 GPU 推理速度提升 2.37×,继续刷新 OCR 方向的公开成绩。

如果最近在关注 PDF 解析、票据识别、多语言 OCR、古籍 OCR、工业字符识别(电路板、CAD、数码管、喷码点阵) 这些方向,那么 PP-OCRv6 这一版确实值得单独拿出来聊一聊。因为它不是单纯的小修小补,而是在真实文档和工业场景能力上继续往前推了一步。
更重要的是,这类模型现在已经不只是“看起来很强”,而是真的越来越适合本地部署和工程化接入。本文就从新版能力、适用场景、本地部署方式三个部分展开,最后再介绍一个可直接上手的本地项目:pp-ocrv6-local,支持一键本地部署 PP-OCRv6,页面效果基本按官方风格复刻,适合直接拉代码部署。
PP-OCRv6 更新了什么
从官方使用教程来看,PP-OCRv6 的核心信号非常明确:
-
检测精度 +4.6%,识别精度 +5.1%
-
GPU 推理速度提升 2.37×
-
CPU 上端到端时延 1.40s,速度是 PP-OCRv5_server 的 5.2 倍
-
tiny 档在浏览器环境端到端延迟仅 97ms
-
单模型支持 50 种语言(PP-OCRv5 单模型仅 4 种)
-
新增多种工业场景:电路板、数码管、CAD 图纸、喷码点阵字符
这意味着它不只是继续擅长常规文本抽取,还在更复杂的版面元素、多语言文档和真实工业场景中进一步补强了短板。
PP-OCRv6 首次推出三档模型,全算力覆盖:
-
Tiny(1.5M):端侧 / IoT / 浏览器,极致速度
-
Small(7.7M):移动端 / 桌面端,性价比最高
-
Medium(34.5M):服务端 / 数据处理,主力模型
对开发者来说,这种能力升级带来的最大好处就是:面对真实 PDF、扫描件、拍照文档、复杂排版材料、工业字符时,模型产出的文本结果会更稳定,后面的数据处理也会更轻松。尤其是当文档里混有多语言、模糊字、倾斜文本、工业字符时,新版本的价值会比普通 OCR 更明显。这里我展示一些之前PP-OCRv5版本和现在PP-OCRv6版本ocr效果对比大家就明白升级在哪里了
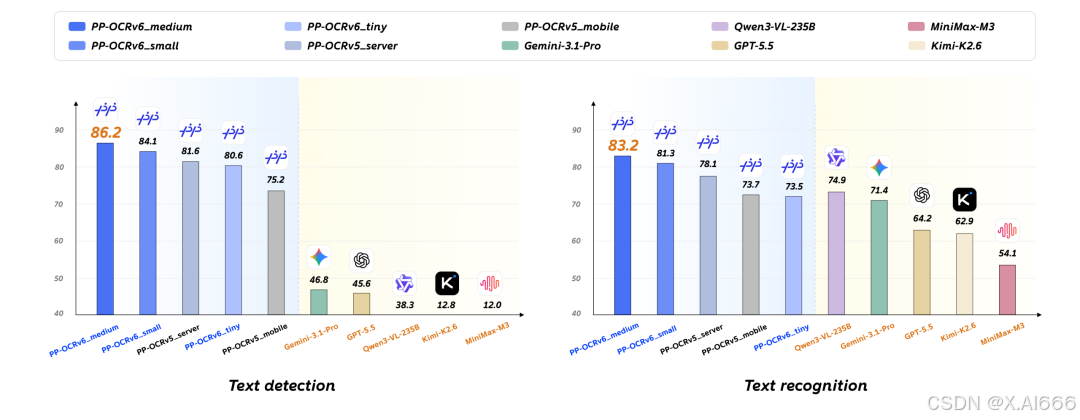
PP-OCRv5 已经能完成常规 OCR 任务,而 PP-OCRv6 更像是面向真实复杂场景升级后的版本。它不仅能识别普通文档,也更擅长处理手写、工业字符、低对比文字、点阵字、数码管、PCB 小字这类过去容易翻车的场景。
1.文本检测(与PP-OCRv5和部分大模型的对比)

2.端到端识别(与PP-OCRv5的对比)



为什么它最近这么火
原因并不复杂,主要是因为真实业务里的文档越来越复杂,而传统 OCR 的边界越来越明显。
过去很多 OCR 工具擅长识别整齐文本,但一遇到:
-
复杂版面、跨栏排版
-
多语言混排(中 + 英 + 日 + 法文等)
-
古籍、手写体、生僻字
-
电路板、CAD、数码管、喷码点阵等工业字符
结果就容易出错。
而 PP-OCRv6 这类 OCR 模型的思路更接近“把页面先理解,再做识别”。官方对 PP-OCR 的总体定位也很明确:它不仅是 OCR 工具包,更是连接图片、PDF 与结构化数据的重要桥梁。
这也是为什么很多人会把它当作文档智能、知识提取、票据处理、合同审阅、企业资料归档、OCR + RAG 数据构建等场景里的基础组件。对这类场景来说,真正有价值的从来不只是文本识别率,而是“能不能把文档完整地拆成可用结果”。
适合哪些场景
PP-OCRv6 适合的场景其实非常广,尤其适用于那些“文档复杂、版面不规整、手工处理成本高”的任务。
常见的落地方向包括:
-
多语言资料处理:中英日混排、海外资料整理(50 种语言统一模型)
-
票据与表单抽取:发票、收据、报销单、合同
-
财报、论文、说明书、合同、票据等复杂材料处理
-
古籍、生僻字、手写体识别
-
工业字符识别:电路板、数码管、CAD 图纸、喷码点阵字符(PP-OCRv6 新增方向)
如果只是做简单截图 OCR,普通方案可能已经够用;但如果希望一个系统能真正“稳定识别各种复杂文档中的文字”,那么 PP-OCRv6 的优势就会非常明显。
为什么建议本地离线部署
虽然官方已经提供了可用的教程和部署方式,但在实际开发中,很多人最关心的仍然是:
能不能本地跑?能不能给一个可视化页面?能不能方便演示和二次开发?
官方文档显示,PP-OCRv6 支持:
-
Windows / Linux / Mac
-
NVIDIA GPU / Intel CPU / 昇腾等硬件
-
浏览器、安卓、iOS 跨平台部署
这本身就说明它在工程化落地上已经走得比较深。
本地部署的价值主要有几个:
-
数据更可控:适合合同、财务、内部资料等敏感文档处理
-
调试更方便:可以直接改接口、换模型、接入自己的后端逻辑
-
演示更直接:尤其适合给团队、客户或业务方展示效果
-
更适合沉淀成自己的文档处理平台:而不是只停留在命令行测试阶段
所以真正有经验的开发者,到最后往往都会回到一个问题:
不是“模型能不能跑”,而是“能不能把它变成一个真正可用的本地系统”。
一个更省事的方案:paddleocr-local
如果只是想体验 PP-OCRv6 的模型能力,直接去官网或 GitHub 看官方教程当然没问题。
但如果你的目标是快速搭一个 可本地离线使用、交互完整、页面观感接近官方 OCR Demo 的系统,那么直接使用 paddleocr-local 会省很多时间。
项目地址:
https://github.com/CHEN010325/paddleocr-local这个项目的核心思路很简单:
把本地部署、前端交互和 OCR 结果展示一起整理好,让用户不必从零开始搭页面、拼接口、做上传组件、调预览区域,再一点点对齐官方展示效果。
对于很多想快速试用、内网演示、项目复现或者后续二开的开发者来说,这种现成工程会更实用。
尤其是从页面形式上看,一个完整的 OCR 系统通常不只是“调用一次接口”这么简单,它还需要:
- 文件上传
- 图片 / PDF 预览
- OCR 识别结果展示
- 原图和识别结果对齐
- 重新识别
- JSON 结果查看
- 结果导出
- 本地任务记录
这些都自己从头做一遍,其实很花时间。
paddleocr-local 已经把这些基础交互整理好了。对于 PP-OCRv6 来说,它可以直接作为一个本地 OCR 可视化工作台使用:上传文件、选择 PP-OCRv6、查看识别结果、对照原图位置,整个流程会比单纯跑命令行直观很多。
目前项目支持:
- 本地部署 PP-OCRv6
- WebUI 上传 / 预览 / 识别结果展示
- PP-OCRv6 JSON 原始结果查看
- OCR 结果可视化对齐展示
- API 调用
- Docker 部署
- 后续二次开发
本地部署教程
这部分不说废话,直接上最重要的信息:
去 GitHub 拉代码,按仓库说明跑起来即可。
1. 克隆仓库
git clone https://github.com/CHEN010325/paddleocr-local
cd paddleocr-local2. Windows 一键部署
需要准备:
- NVIDIA GPU
- NVIDIA Driver
- Docker Desktop
- Docker Desktop 支持 GPU
进入仓库目录:
cd D:\paddleocr-local执行一键部署:
powershell -ExecutionPolicy Bypass -File .\scripts\windows-one-click.ps1脚本会自动检查 Docker、GPU、Compose 配置,并完成镜像构建和服务启动。第一次启动会下载模型和镜像,时间可能会比较久,后续会复用本地缓存。
启动完成后访问:
WebUI:http://localhost:8000PP-OCRv6 健康检查地址:
http://localhost:8082/health3. 手动 Docker 部署
如果不用一键脚本,也可以手动执行:
docker compose --env-file env.txt pull paddleocr-vlm-server paddleocr-vl-api
docker compose --env-file env.txt build paddleocr-ocr-api pandocr-web
docker compose --env-file env.txt up -d --no-start
docker compose --env-file env.txt start pandocr-web进入页面后,在右上角模型选择里切换到:
PP-OCRv6系统会启动 PP-OCRv6 对应服务。
常用命令:
docker compose --env-file env.txt ps
docker compose --env-file env.txt logs -f pandocr-web
docker compose --env-file env.txt logs -f paddleocr-ocr-api
docker compose --env-file env.txt down4. 启动项目
项目启动后,在浏览器打开:
http://localhost:8000上传图片或 PDF,选择 PP-OCRv6 后,就可以进入一个接近官方风格的 OCR 页面。
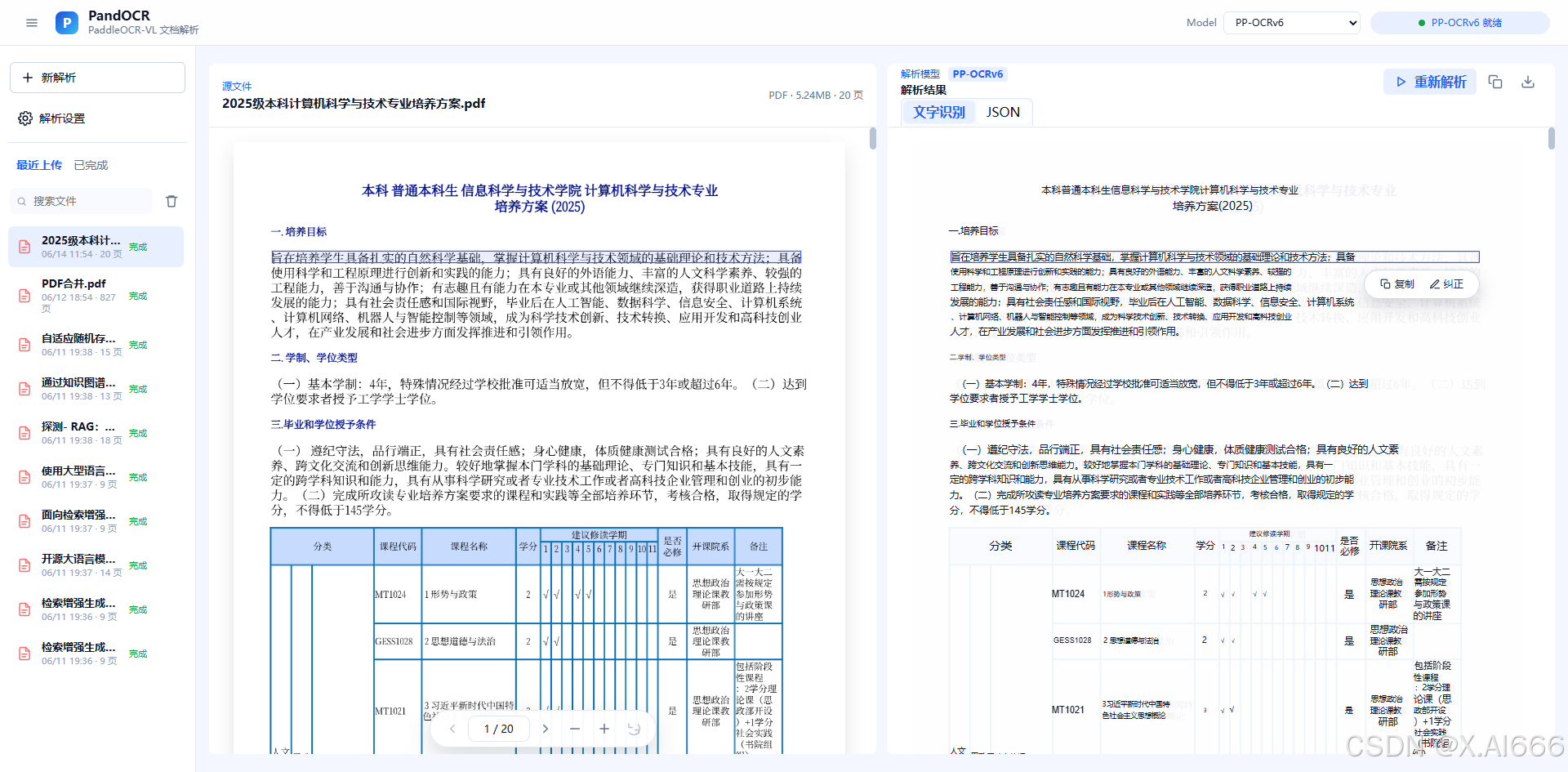
页面会展示左侧原始文件预览和右侧识别结果区域,适合直接做功能验证、效果展示、内网演示和后续集成。
结尾
PP-OCRv6 这次值得关注的地方,不只是“模型又更新了”,而是它把 OCR 继续往实用场景里推进了一步。
如果你只是想了解模型能力,看官方文档就够了。
但如果你想在本地快速搭一个可用页面,把上传、预览、识别、结果展示和 API 调用都完整跑起来,那么最省事的办法就是直接拉 paddleocr-local:
https://github.com/CHEN010325/paddleocr-local照着 README 部署,基本就能快速上手。
如果你觉得这个项目对你有帮助,也欢迎帮我点一个 Star。
如果你觉得这篇文章对你有帮助,也欢迎给我一个三连击:点赞、转发和在看;如果可以,再帮我点一个⭐️。谢谢你看到这里,我们下篇再见。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 17
17 0
0- 0



 已为社区贡献26条内容
已为社区贡献26条内容

所有评论(0)