AI狼人杀评分系统优化
一、前言
我根据设计的测评系统,我们进行了多轮测试,在测试过程中,我们发现这个系统的打分效果比较差,于此同时,在测评时因为大量的llm调用,测评时间也比较久。所以,我们对这个评分系统进行了一下修改,我们要设计函数来进行打分,不能都调用大模型,这样确实太耗费时间了。只有对于那些打分比较模糊的,我们再去调用大模型来进行打分,这样既可以节省时间,也可以提升准确度。
二、架构优化
这里,我还是设计了Three-Tier Per-Step Decision Scoring(三档逐决策瀑布式评分)。规则评分、轻量llm评分、三方llm评分。这样减少了大模型的调用,可以大大提升测评的效率。
核心思想是这样的:
> 95% 的决策其实可以用确定性规则打分。
剩下 5% 里,大部分用一个轻量 LLM 就能搞定。
真正需要三方专家仲裁的,不到 1%。
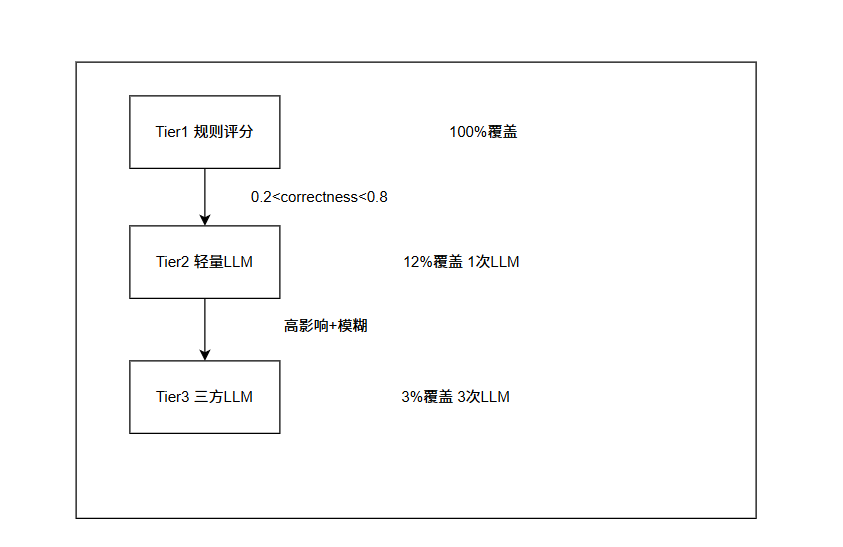
在这个架构下,与其给每条发言都拉三方专家,不如先把规则能确定的事情解决掉,大大提升了系统运行效率。
三、具体实现
3.1Tier 1 规则评分
我写了三个方法:score_vote/score_speech/score_night,
每个都是纯函数式的,输入是decision + state,输出是DecisionScore。
每条决策都是从四个维度打分:
| 维度 | 权重(投票) | 权重(发言) | 权重(夜间) | 含义 |
| correctness | 50% | 40% | 55% | 决策是否正确 |
| reasoning_quality | 25% | 35% | 20% | 推理过程质量 |
| timeliness | 10% | 10% | 10% | 决策时效性 |
| impact | 15% | 15% | 15% | 对局势影响程度 |
那么核心评分机制(拿score_vote举例):
correct = 0.95 if 投给狼人 else (0.15 if 投给强神 else 0.35)
overall = round(
0.50 * correct +
0.25 * reasoning_quality +
0.10 * timeliness +
0.15 * impact,
3,
)其中reasoning_quality我用了几个简单的特征:
文本长度(>80字符+0.15,>200字符+0.10)
包含"因为/所以/如果"等逻辑词+0.10
包含"X 号"或"BotX"等具体玩家引用+0.10
发言质量中我还加入了防止身份泄露的,如果有时候ai泄露自己身份会扣除部分得分。这个规则能抓到很多 AI 玩家白天自爆的低级错误。
for w in ["我是预言家", "我是女巫", "我昨晚毒了"]:
if w in text:
risk_flags.append(f"泄漏身份: {w}")
correct = max(0.10, correct - 0.30)4.2 Tier 2 轻量 LLM
只在correctness ∈ (0.2, 0.8)(或者类似区间)时才升级到 LLM。具体到我们的这个项目,调用本项目已有的 LLMSpeechEvaluator。如果引入新的客户端就会触发重复初始化(~5 秒的开销)。这样可以减少五秒的开销,提升速度。
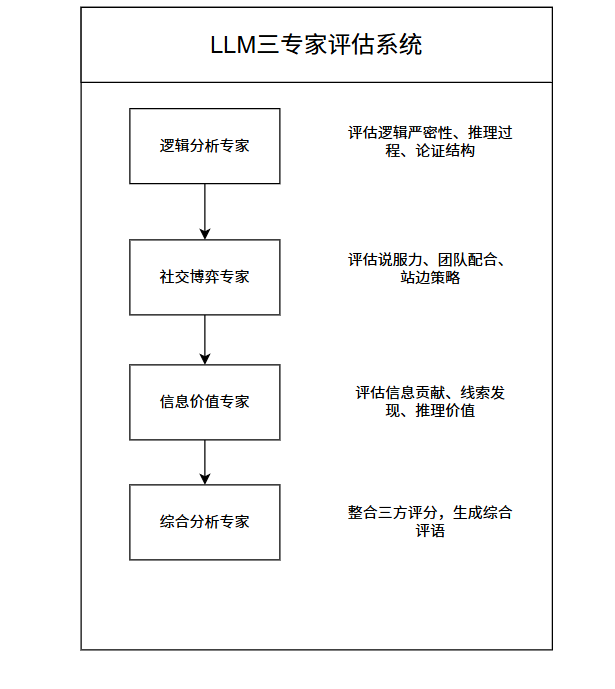
这里我们是复用的之前的三专家系统来进行打分。相较于之前把所有的都调用三专家,我们这里只有部分评分模糊的才会调用。
代码如下:
def _score_with_light_llm(self, score, action, state):
if self._llm is None:
return score
try:
result = self._llm.evaluate(
player_id=score.player_id,
speech_content=text,
...
)
llm_score = max(0.0, min(1.0, result.final_score / 100.0))
score.light_llm_score = llm_score
score.scoring_tier = "light_llm"
except Exception as e:
score.metadata.setdefault("llm_error", str(e))
return score每个专家输出结构化的 ExpertScore ,包含分数、理由、优缺点和改进建议。三专家的平均分归一化到 [0, 1] 后覆盖 Tier 1 的 overall_score 。
4.3 Tier 3 重 LLM 评分(3-Judge Panel)
Tier 3 是为高影响 + 高模糊的决策设计的终极评分层。
需要两个条件同时满足:
1. 模糊 :Tier 1 拿不准(correctness ∈ (0.2, 0.8))
2. 高影响 :该决策对局势影响大(impact > 0.5)
if s.needs_light_llm and s.impact > 0.5:
s.needs_heavy_llm = TrueTier 3 的核心是 3 次独立评估取中位数 :
为什么用中位数而不是平均数?因为 LLM 评估存在随机性,单次评估可能因为 prompt 理解偏差产生离群值。中位数对单个离群 judge 更鲁棒。
# 关闭缓存,强制 3 次评估独立
self._llm.cache_enabled = False
for run_idx in range(3):
result = self._llm.evaluate(...)
judge_scores.append(result.final_score / 100.0)
# 中位数(而非平均数)—— 对离群 judge 更鲁棒
sorted_scores = sorted(judge_scores)
median = sorted_scores[1]
# 一致性指标
spread = max(judge_scores) - min(judge_scores)
agreement = 1.0 - spread四、总结
三层瀑布式评分系统的核心思想是 分级评估、按需升级 ——用确定性规则覆盖大部分决策,只在模糊地带才引入 LLM 评估,在评分精度和计算成本之间取得平衡。这种架构不仅适用于狼人杀,也可以推广到其他不完全信息博弈场景的 AI 评估中。
在本次方法优化中,我也学到了确定性优先于随机性。能用规则解决的,不要丢给 LLM。这样可以大大节约成本和时间。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 8
8 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)