基于 RFM 模型实现淘宝用户精细化分层与营销分析
一、项目背景 & 业务问题
-
业务场景:电商用户运营
-
核心问题:谁是高价值客户?用户有什么特征?如何差异化营销?
-
解决方案:经典 RFM 用户分层模型
二、数据准备
-
数据表结构说明
-
orders订单主表(核心分析表)字段名 数据类型 说明 order_id varchar(255) 订单唯一 ID user_id varchar(255) 用户 ID,关联用户表 product_id varchar(255) 商品 ID,关联商品表 quantity varchar(255) 购买数量 order_date varchar(255) 下单时间 order_status varchar(255) 订单状态(已完成 / 已付款 / 已收货等) payment_method varchar(255) 支付方式 unit_price varchar(255) 商品单价 total_amount varchar(255) 订单总金额 discount varchar(255) 优惠金额 actual_payment varchar(255) 实付金额(RFM 模型 M 指标) delivery_date varchar(255) 发货时间 receive_date varchar(255) 收货时间 review_score varchar(255) 评价评分 review_content varchar(255) 评价内容 -
users用户基础信息表字段名 数据类型 说明 user_id varchar(255) 用户唯一 ID age varchar(255) 用户年龄 gender varchar(255) 用户性别 province varchar(255) 所在省份 city varchar(255) 所在城市 registration_date varchar(255) 注册时间 member_level varchar(255) 会员等级 account_balance varchar(255) 账户余额 credit_score varchar(255) 信用评分 -
user_features用户特征统计表字段名 数据类型 说明 user_id varchar(255) 用户唯一 ID total_spent varchar(255) 累计消费总额 order_count varchar(255) 累计订单数 completed_orders varchar(255) 已完成订单数 avg_order_amount varchar(255) 平均订单金额 browse_count varchar(255) 累计浏览次数 click_count varchar(255) 累计点击次数 favorite_count varchar(255) 累计收藏次数 cart_count varchar(255) 累计加购次数 days_since_last_order varchar(255) 距离上次下单天数 order_frequency varchar(255) 下单频率 repurchase_indicator varchar(255) 复购标识 purchase_intent varchar(255) 购买意向 consumption_level varchar(255) 消费等级 member_level_score varchar(255) 会员等级评分 -
products商品基础信息表字段名 数据类型 说明 product_id varchar(255) 商品唯一 ID product_name varchar(255) 商品名称 category varchar(255) 商品分类 brand varchar(255) 商品品牌 price varchar(255) 商品单价 sales_count varchar(255) 累计销量 -
product_features商品特征统计表字段名 数据类型 说明 product_id varchar(255) 商品唯一 ID total_revenue varchar(255) 累计营收 total_sales varchar(255) 累计销量 completed_count varchar(255) 已完成订单数 cancel_count varchar(255) 取消订单数 加购_count varchar(255) 累计加购次数 收藏_count varchar(255) 累计收藏次数 浏览_count varchar(255) 累计浏览次数 点击_count varchar(255) 累计点击次数 conversion_rate varchar(255) 转化率 avg_review_score varchar(255) 平均评价评分 popularity_score varchar(255) 商品热度评分 -
user_behaviors用户行为日志表字段名 数据类型 说明 behavior_id varchar(255) 行为记录 ID user_id varchar(255) 用户 ID product_id varchar(255) 商品 ID behavior_type varchar(255) 行为类型(浏览 / 点击 / 收藏 / 加购等) behavior_time varchar(255) 行为发生时间 duration_seconds varchar(255) 行为持续时长(秒) orders订单表是本次 RFM 分析的核心数据源,其中actual_payment、order_date、order_id分别对应 M、R、F 三个核心指标。 -
开发环境:Python + MySQL + Pandas + Matplotlib
三、整体分析流程
数据采集 → 数据清洗 → 探索分析 → RFM 指标计算 → 用户分层 → 用户画像 → 可视化 → 业务策
四、代码实现
-
环境与数据库配置
# 1. 导入依赖库 + 全局环境配置 from datetime import datetime import pymysql import pandas as pd import numpy as np import matplotlib.pyplot as plt import seaborn as sns import warnings # 全局关闭所有警告(字体、运行警告等,保证界面整洁) warnings.filterwarnings("ignore") # 2.Matplotlib 中文乱码 + 负号显示配置 # 解决Python绘图中文方框、负数不显示问题(Windows系统通用配置) plt.rcParams['font.sans-serif'] = ['SimHei', 'Microsoft YaHei', 'PingFang SC', 'Arial Unicode MS'] plt.rcParams['font.family'] = 'sans-serif' plt.rcParams['axes.unicode_minus'] = False # 3. 数据库连接配置(MySQL) DB_CONFIG = { "host": "localhost", # 数据库地址(本地固定localhost) "user": "root", # MySQL账号 "password": "************", # MySQL密码 "database": "taobao_analysis", # 数据库名 "charset": "utf8mb4" # 字符集(支持表情、特殊字符) } # 创建数据库连接函数 def create_conn(): conn = pymysql.connect(**DB_CONFIG) return conn # 4. 通用工具函数封装 def read_sql_data(sql): """执行SQL查询,返回DataFrame数据表""" conn = create_conn() df = pd.read_sql(sql, conn) conn.close() return df -
数据采集
def clean_column_names(df): """清洗列名:移除隐藏字符、去除首尾空格""" df.columns = [col.replace("\ufeff", "").strip() for col in df.columns] return df # 1)订单主表(核心表,计算RFM唯一数据源) sql_orders = "SELECT * FROM orders" df_orders = read_sql_data(sql_orders) df_orders = clean_column_names(df_orders) # 2)用户基础信息表(年龄、性别、城市、会员等级等画像) sql_users = "SELECT * FROM users" df_users = read_sql_data(sql_users) df_users = clean_column_names(df_users) # 3)用户特征统计表(客单价、浏览量、复购指标等) sql_user_feat = "SELECT * FROM user_features" df_user_feat = read_sql_data(sql_user_feat) df_user_feat = clean_column_names(df_user_feat) # 4)商品相关表 + 用户行为表(备用,本次RFM分析暂不使用) sql_products = "SELECT * FROM products" df_products = read_sql_data(sql_products) df_products = clean_column_names(df_products) sql_prod_feat = "SELECT * FROM product_features" df_prod_feat = read_sql_data(sql_prod_feat) df_prod_feat = clean_column_names(df_prod_feat) sql_user_behavior = "SELECT * FROM user_behaviors" df_user_behavior = read_sql_data(sql_user_behavior) df_user_behavior = clean_column_names(df_user_feat) # 输出数据体量,做基础盘点 print(f"订单表原始数据量:{len(df_orders)} 条") print(f"用户表原始数据量:{len(df_users)} 条")
-
数据清洗
清洗目标:去重、过滤无效订单、异常值处理、缺失值处理、字段类型转换 清洗逻辑:只保留【已完成】有效订单,剔除脏数据
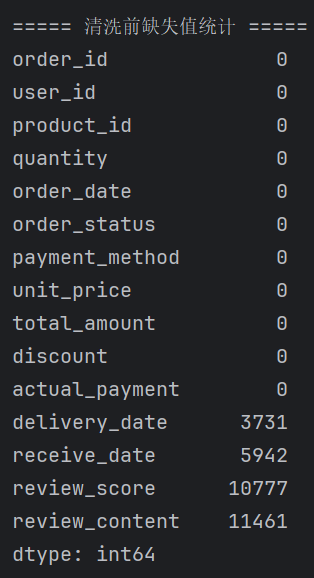
# 复制原表,避免修改原始数据 df_orders_clean = df_orders.copy() # 查看清洗前列名、数据类型、缺失值 print("\n===== 清洗前字段类型 =====") print(df_orders_clean.dtypes) print("\n===== 清洗前缺失值统计 =====") print(df_orders_clean.isnull().sum())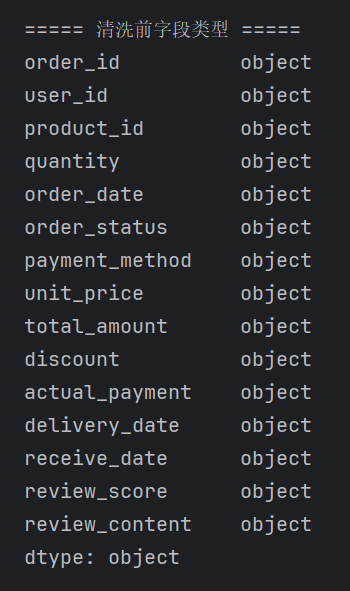
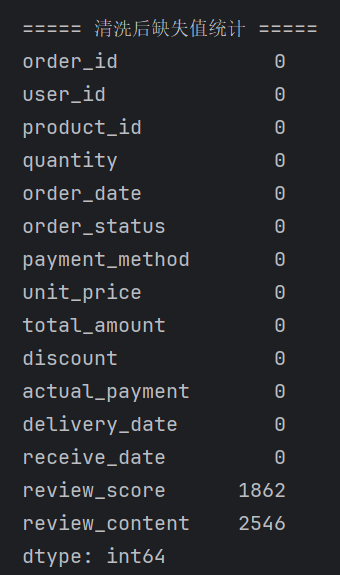
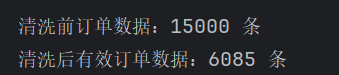
# 7.1 字段类型转换:文本转数值、文本转时间 # 数值字段:数量、单价、金额、折扣、评分 num_cols = ["quantity", "unit_price", "total_amount", "discount", "actual_payment", "review_score"] for col in num_cols: df_orders_clean[col] = pd.to_numeric(df_orders_clean[col], errors="coerce") # 时间字段:下单时间、发货时间、收货时间 time_cols = ["order_date", "delivery_date", "receive_date"] for col in time_cols: df_orders_clean[col] = pd.to_datetime(df_orders_clean[col], errors="coerce") # 7.2 数据去重:根据订单唯一ID去重,删除重复订单 df_orders_clean = df_orders_clean.drop_duplicates(subset=["order_id"], keep="first") # 7.3 过滤无效数据:只保留 已完成 订单(取消/待支付订单无分析价值) df_orders_clean = df_orders_clean[df_orders_clean["order_status"] == "已完成"] # 7.4 过滤异常值:实付金额不能为负数 df_orders_clean = df_orders_clean[df_orders_clean["actual_payment"] >= 0] # 7.5 缺失值处理:核心字段为空直接删除(用户ID、下单时间、实付金额) key_cols = ["user_id", "order_date", "actual_payment"] df_orders_clean = df_orders_clean.dropna(subset=key_cols) print("\n===== 清洗后字段类型 =====") print(df_orders_clean.dtypes) print("\n===== 清洗后缺失值统计 =====") print(df_orders_clean.isnull().sum()) # 输出清洗前后数据对比 print(f"\n清洗前订单数据:{len(df_orders)} 条") print(f"清洗后有效订单数据:{len(df_orders_clean)} 条")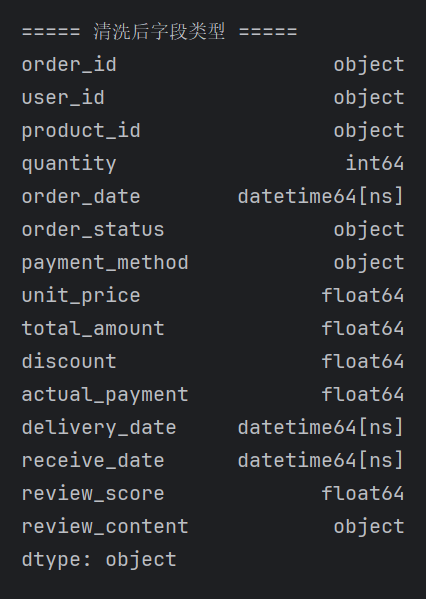
-
EDA 探索分析
作用:掌握整体订单规模、时间范围、平均消费,为后续分层做铺垫
# 统计订单时间跨度 min_order_time = df_orders_clean["order_date"].min() max_order_time = df_orders_clean["order_date"].max() print(f"订单统计时间范围:{min_order_time} ~ {max_order_time}") # 整体消费指标:总交易额、单订单平均金额 total_pay = df_orders_clean["actual_payment"].sum() avg_pay = df_orders_clean["actual_payment"].mean() print(f"平台累计交易总额:{total_pay:.2f} 元") print(f"单订单平均实付金额:{avg_pay:.2f} 元")
-
RFM 指标计算
R(Recency):最近一次消费距离当前的天数 → 越小=用户越活跃 F(Frequency):统计周期内有效订单数 → 越大=消费频次越高 M(Monetary):累计实付总金额 → 越大=消费能力越强
# 按用户分组,聚合计算R/F/M df_rfm = df_orders_clean.groupby("user_id").agg( Recency=("order_date", lambda x: (now_date - x.max()).days), # 最近消费天数 Frequency=("order_id", "nunique"), # 消费频次(订单数) Monetary=("actual_payment", "sum") # 累计消费金额 ).reset_index() # 简化列名,方便后续使用 df_rfm.rename(columns={"Recency":"R", "Frequency":"F", "Monetary":"M"}, inplace=True) # 输出RFM结果预览 print("RFM指标数据预览(前5行):") print(df_rfm.head()) print(f"参与统计有效用户总数:{len(df_rfm)} 人")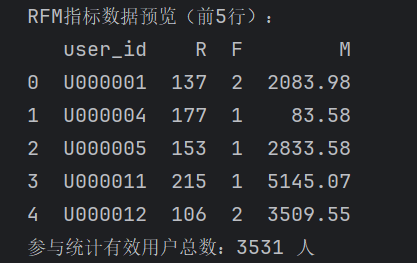
-
RFM五档打分 + 用户分层(核心建模环节)
业务规则: 1. R:天数越小越活跃 → 倒序打分 5~1分 2. F/M:数值越大价值越高 → 正序打分 1~5分 技术方案:使用百分比排名rank,解决重复值导致分箱报错问题 分层规则:8大类经典用户分层模型
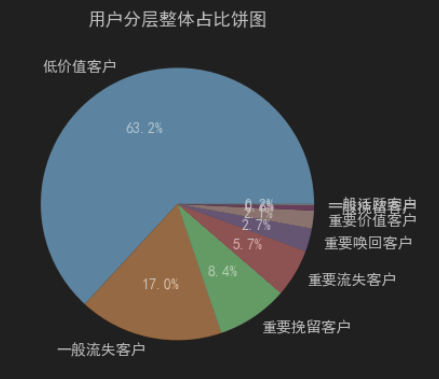
# R打分 df_rfm["R_pct"] = df_rfm["R"].rank(pct=True, ascending=False) df_rfm["R_score"] = pd.cut(df_rfm["R_pct"], bins=5, labels=[5,4,3,2,1]) # F打分 df_rfm["F_pct"] = df_rfm["F"].rank(pct=True, ascending=True) df_rfm["F_score"] = pd.cut(df_rfm["F_pct"], bins=5, labels=[1,2,3,4,5]) # M打分 df_rfm["M_pct"] = df_rfm["M"].rank(pct=True, ascending=True) df_rfm["M_score"] = pd.cut(df_rfm["M_pct"], bins=5, labels=[1,2,3,4,5]) # 拼接RFM分数编码(辅助标识) df_rfm["RFM_code"] = df_rfm["R_score"].astype(str) + df_rfm["F_score"].astype(str) + df_rfm["M_score"].astype(str)def get_user_segment(row): r = row["R_score"] f = row["F_score"] m = row["M_score"] if r >= 4 and f >= 4 and m >= 4: return "重要价值客户" elif r >= 4 and f <= 2 and m >= 4: return "重要流失客户" elif r <= 2 and f >= 4 and m >= 4: return "重要挽留客户" elif r <= 2 and f <= 2 and m >= 4: return "重要唤回客户" elif r >= 4 and f >= 4 and m <= 2: return "一般活跃客户" elif r >= 4 and f <= 2 and m <= 2: return "一般流失客户" elif r <= 2 and f >= 4 and m <= 2: return "一般挽留客户" else: return "低价值客户" # 执行全量用户分层 df_rfm["user_segment"] = df_rfm.apply(get_user_segment, axis=1)segment_stat = df_rfm["user_segment"].value_counts().reset_index() segment_stat.columns = ["用户分层", "用户数量"] segment_stat["占比(%)"] = round(segment_stat["用户数量"] / len(df_rfm) * 100, 2) # 输出分层结果 print("===== 各用户分层人数 & 占比统计 =====") print(segment_stat)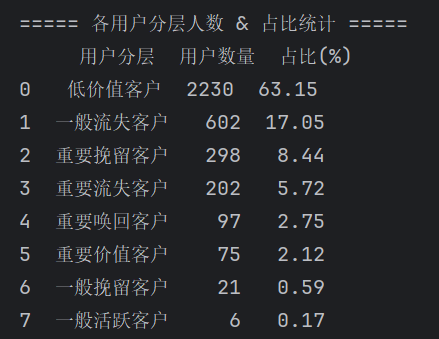
-
用户画像分析(特征解读)
关联表:RFM分层表 + 用户基础表 + 用户特征表 分析维度:分层群体的RFM均值、平均客单价、性别分布
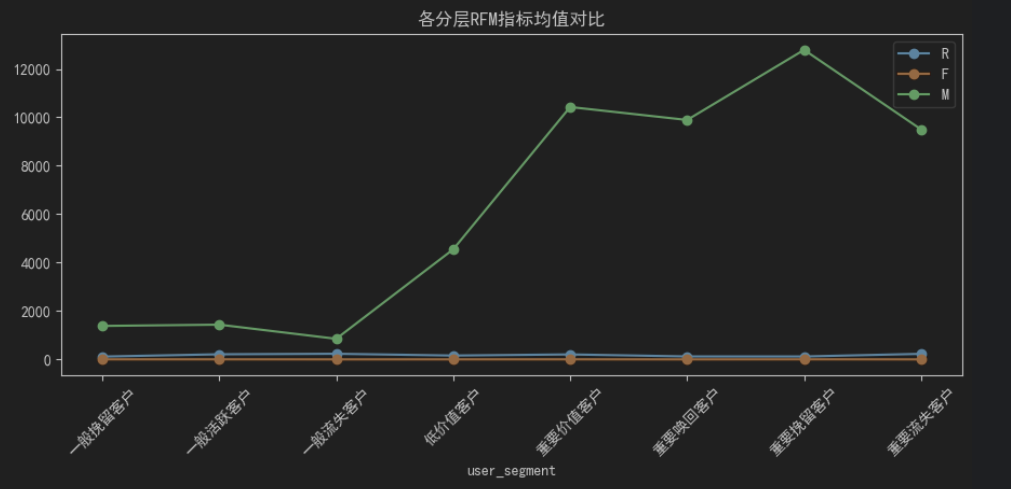
# 清洗关联主键user_id,保证三表匹配一致 df_rfm = clean_column_names(df_rfm) key_col = "user_id" df_rfm[key_col] = df_rfm[key_col].astype(str).str.strip() df_users[key_col] = df_users[key_col].astype(str).str.strip() df_user_feat[key_col] = df_user_feat[key_col].astype(str).str.strip() # 左连接:保留所有分层用户,匹配用户属性 df_user_all = pd.merge(df_rfm, df_users, on=key_col, how="left") df_user_all = pd.merge(df_user_all, df_user_feat, on=key_col, how="left") # 客单价字段类型转换(支持数值计算) df_user_all["avg_order_amount"] = pd.to_numeric(df_user_all["avg_order_amount"], errors="coerce") # 1)各分层RFM指标均值(核心价值特征) portrait_rfm = df_user_all.groupby("user_segment")[["R", "F", "M"]].mean(numeric_only=True).round(2) print("===== 各分层RFM指标均值 =====") print(portrait_rfm) # 2)各分层平均客单价 portrait_order = df_user_all.groupby("user_segment")["avg_order_amount"].mean(numeric_only=True).round(2) print("\n===== 各分层平均客单价 =====") print(portrait_order) # 3)各分层性别分布占比 gender_dist = pd.crosstab(df_user_all["user_segment"], df_user_all["gender"], normalize="index") print("\n===== 各分层性别占比(%) =====") print(round(gender_dist * 100, 2))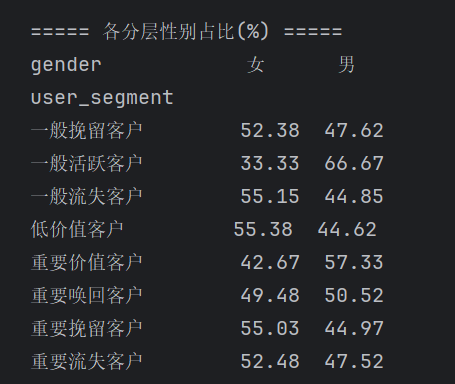
-
数据可视化
fig = plt.figure(figsize=(18, 8)) # 子图1:各分层用户数量柱状图 ax1 = plt.subplot(2, 2, 1) ax1.bar(segment_stat["用户分层"], segment_stat["用户数量"]) ax1.set_title("各价值分层用户数量分布", fontsize=12) ax1.tick_params(axis="x", rotation=45) # 子图2:各分层RFM指标均值对比折线图 ax2 = plt.subplot(2, 2, 2) portrait_rfm.plot(kind="line", marker="o", ax=ax2) ax2.set_title("各分层RFM指标均值对比", fontsize=12) ax2.tick_params(axis="x", rotation=45) # 子图3:用户分层占比饼图 ax3 = plt.subplot(2, 2, 3) ax3.pie(segment_stat["用户数量"], labels=segment_stat["用户分层"], autopct="%1.1f%%") ax3.set_title("用户分层整体占比饼图", fontsize=12) plt.tight_layout() plt.show()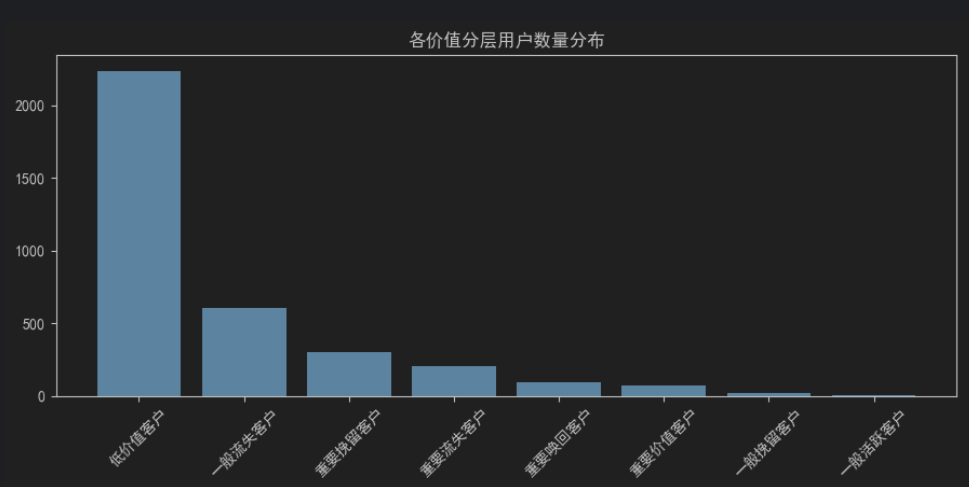
五、业务结论 & 运营策略
-
各分层用户特征总结
-
重要价值客户 最近消费时间近、下单频次高、累计消费金额高,是平台消费能力与活跃度双优的核心群体。该类用户会员等级普遍偏高,客单价高于整体平均水平,对平台认可度强,复购意愿稳定。
-
重要流失客户 消费总额处于高位,具备极强消费潜力,但近期不再产生订单,用户活跃度大幅下滑。属于 “高价值沉睡用户”,一旦持续流失会直接影响平台营收规模。
-
重要挽留客户 历史消费金额高、下单频次稳定,但最近消费间隔拉长,活跃度开始下降。用户还未彻底流失,处于摇摆阶段,是重点挽留对象。
-
重要唤回客户 过往消费能力突出,但长期未在平台消费,属于深度沉睡的高价值用户。用户基数通常较少,但单用户价值极高,唤醒后可快速贡献营收。
-
一般活跃客户 近期下单频繁、活跃度拉满,但累计消费金额偏低,客单价处于下游。这类用户基数大、粘性尚可,但消费潜力未被挖掘。
-
一般流失客户 活跃度和消费能力均偏低,且近期已停止下单。用户本身价值有限,流失对平台影响较小。
-
一般挽留客户 有固定复购习惯,活跃度小幅下降,整体消费金额不高。属于平台常规存量用户,增长空间有限。
-
低价值客户 消费频次、消费金额、近期活跃度三项指标均垫底,多为一次性尝鲜用户,几乎无法为平台创造有效收益。
-
八大群体差异化营销策略
-
重要价值客户 定位:核心营收支柱。推出专属会员权益、积分加倍、新品优先购、专属客服服务;搭建私域社群,定期推送定制化内容与福利,最大化提升用户留存与生命周期价值。
-
重要流失客户 定位:高价值召回对象。定向推送大额专属优惠券、爆款组合套餐,采用短信、站内信多渠道触达;针对高等级用户可进行人工回访,了解流失原因,提升召回成功率。
-
重要挽留客户 定位:重点防流失群体。推送短期复购券、续购立减活动,结合其历史消费偏好做商品推荐;通过会员积分提醒、权益到期提醒等方式,刺激用户继续下单。
-
重要唤回客户 定位:沉睡高价值用户。搭配 “满减 + 限时折扣” 组合福利,推送平台经典爆款商品;采用低成本批量触达方式唤醒,控制营销成本的同时撬动存量价值。
-
一般活跃客户 定位:增量潜力群体。主打搭配购、加价购、组合套餐,引导用户增加购买品类与购买数量,拉高客单价;利用高频活动持续维持用户活跃度。
-
一般流失客户 定位:低优先级群体。仅推送平台通用普惠优惠券,不投入高额人力、物料成本,以轻量化运营为主。
-
一般挽留客户 定位:常规存量用户。引导用户升级会员体系,推荐高性价比引流商品;以基础福利维持复购,不做深度营销投入。
-
低价值客户 定位:边缘用户。仅参与平台全平台常规活动推送,严控营销资源投入,避免资源浪费。
-
整体运营建议
- 资源倾斜:将核心营销资源、优质活动、专属权益优先向重要价值客户倾斜,守住平台基本盘。
- 攻坚破局:把重要流失、重要挽留两类高价值风险用户作为短期运营攻坚重点,制定专项召回、挽留活动,减少优质用户流失。
- 挖掘增量:依托庞大的一般活跃客户群体,通过套餐营销、场景化推荐等方式提升客单价,打造营收第二增长曲线。
- 成本管控:对低价值、低潜力用户简化运营流程,减少不必要的营销投放,提升整体投入产出比。
- 长效监控:建立 RFM 分层定期复盘机制,按月 / 周更新用户分层数据,跟踪群体流转情况(如活跃用户变流失用户),及时调整运营策略。
六、项目总结
RFM 是电商、零售、会员行业经典的用户分层模型,本次项目借助该模型完成用户价值细分,解决了“分不清用户价值、运营一刀切”的行业痛点。 通过 R(最近消费)、F(消费频次)、M(消费金额) 三个核心维度,量化每一位用户的活跃度与消费能力,实现从 “粗放式运营” 到 “精细化运营” 的转变。同时模型逻辑简单、落地成本低,可长期复用在用户运营、活动营销、会员管理等业务场景中。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 7
7 1
1- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)