AI编程能力上限由谁决定?90%开发者都搞错了模型和工具的关系
收藏:⭐⭐⭐⭐⭐ 硬核避坑干货,彻底告别AI编程无效试错
前言
很多程序员都有一个致命误区:
疯狂换各种AI编程工具,Trae、Cursor轮番试,免费付费全折腾,结果写代码还是漏洞多、复杂Bug查不出、逻辑写不明白。
忙活半天效率没提升,完全找错了核心重点。
今天说一句颠覆90%人的真话:
AI编程的能力上限,和工具无关,只由模型决定。
工具只是外壳,模型才是真正的内核。内核性能不行,换再多花哨工具,都是换汤不换药。
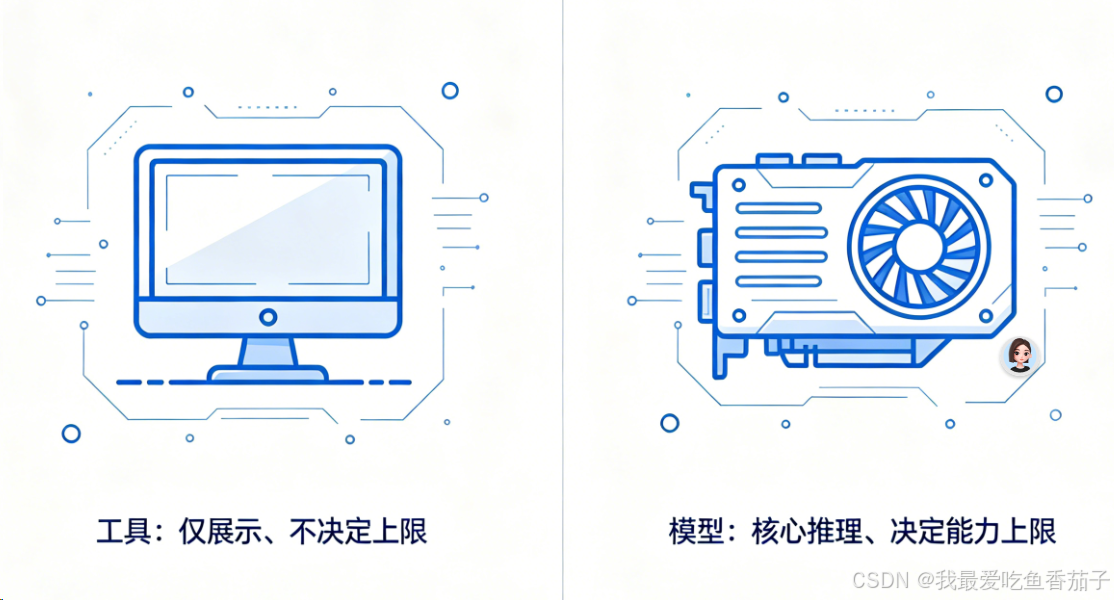
一、通俗硬核类比:模型=显卡,工具=显示器
一句话彻底看透本质:
显示器再高清、功能再丰富,显卡性能拉胯,永远跑不动大型游戏。
对应我们日常AI编程开发,逻辑完全一致:
- 编程工具(Trae/Cursor):只是交互载体,负责展示界面、管理文件、优化交互,不提升核心推理能力;
- AI模型(DeepSeek/Claude):负责代码逻辑推理、Bug溯源、架构设计、漏洞审计,直接锁定能力天花板。
这就是为什么很多人用AI写小代码飞快,一遇到复杂业务、疑难Bug就频繁翻车:
不是你工具用得不对,是你用的轻量化模型,本身就没有深度推理的能力。
二、主流代码模型三大梯队,真实能力精准拆解
目前国内开发者常用的代码模型,没有乱七八糟的选择,严格分为三个梯队,梯队差距碾压级,适配场景完全不重叠。
✅ 第一梯队:极速轻量化|DeepSeek-V4-Flash(日常摸鱼首选)
核心定位:速度极致、免费低成本、高频轻量开发专属
百分百适配场景:
- 单行代码补全、基础语法错误修复
- 简单CRUD模板生成、临时测试脚本编写
- 轻量业务迭代、微小Bug快速修复
致命短板(重点避坑):
- 多层复杂业务逻辑推理薄弱,极易出现逻辑漏洞
- 无法识别隐藏Bug、内存泄漏、线程并发安全问题
- 长对话、多文件项目极易失忆,丢失上下文定义
- 完全hold不住项目重构、代码安全审计等复杂工作
适配人群:学生党、日常轻度开发、快速迭代写基础代码
✅ 第二梯队:工程均衡型|DeepSeek-V4-Pro / DeepSeek-Coder(项目开发标配)
核心定位:代码专项优化、工程能力均衡、性价比天花板
专门基于万亿级真实工程代码、线上报错日志、算法竞赛题库专项训练,是专为程序员打造的编程专精模型。
百分百适配场景:
- 中小型正式商业项目开发
- 常规逻辑Debug、代码性能优化、冗余代码重构
- 数据结构、算法刷题与业务算法实现
- 业务逻辑梳理、模块功能迭代开发
小幅短板:超大型分布式项目架构梳理、百万级超长上下文审计弱于顶级模型
适配人群:后端开发、全职程序员、日常项目迭代开发
✅ 第三梯队:顶级全能型|Claude 3.5 Sonnet/Opus(疑难攻坚神器)
核心定位:当前民用AI编程综合能力天花板
拥有百万级超长上下文窗口、顶级逻辑推理能力,不止会写代码,更懂工程架构、底层原理和安全漏洞。
百分百适配场景:
- 老旧项目疑难杂症Bug排查、隐藏逻辑漏洞挖掘
- 内存泄漏、线程死锁、并发安全、代码漏洞审计
- 大型项目整体重构、架构优化、技术方案梳理
- 多模块、多文件联动调试、全局代码改造
小幅短板:响应速度慢于轻量化模型,调用成本相对更高
适配人群:资深开发、架构师、项目疑难问题攻坚
三、一键抄作业!模型选型终极公式
不用盲目试错,根据开发场景直接选,效率直接拉满:
- 日常快速敲代码、改小Bug、写脚本 → DeepSeek-V4-Flash
- 正式项目开发、算法编码、常规调试优化 → DeepSeek-V4-Pro
- 排查疑难Bug、重构老项目、代码安全审计 → Claude 3.5
四、核心总结(建议反复品读)
1、模型决定AI编程的能力上限,工具永远无法突破模型的固有短板,代码写得烂、Bug查不出,优先换模型,别瞎折腾工具;
2、轻量化模型只适合快节奏轻开发,复杂工程、疑难问题,必须上高阶模型;
3、选对适配场景的模型,比切换十个工具,更能提升十倍开发效率。
下期预告:同款模型效果天差地别?Trae与Cursor的底层核心差距,终于讲透了!
觉得有用点赞+收藏+关注,持续更新AI编程实战硬核干货!

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 8
8 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)