开源 RL 框架 SWITCH 论文解读:用两个边界 token 把潜空间推理拉回 GRPO 训练,Qwen3-8B 在 MATH-500 上 79.3% / GSM8K 89.2%
本期挑了一篇 2026 年 6 月刚挂上 arXiv、立刻把代码和 LoRA checkpoint 一起开源的工作:SWITCH(Demystifying Hidden-State Recurrence: Switchable Latent Reasoning with On-Policy Reinforcement Learning)。论文 arXiv 编号 2606.13106,官方仓库在 LARK-AI-Lab/SWITCH,MIT 协议,含三阶段训练脚本、Switch-GRPO 实现、Phase 3 LoRA 权重和数据集,是少见的「论文 + 代码 + 训练脚本 + 可复现 checkpoint」全开源 RL 工作。
一、这篇论文解决了什么问题
把可见的 chain-of-thought 压成连续的隐藏状态递归(latent CoT,代表工作是 Coconut),原本是为了节省 token、提高推理密度。但这种做法在工程上一直卡两个槽。
一是没法干净地接 on-policy RL。GRPO/PPO 这套优化都是在离散 token 上算 ratio 的,潜空间一旦走的是连续 hidden state,就丢了「每步动作的概率」,policy ratio 变得不再 well-defined,训练只能退回到 SFT 或者各种近似。
二是没法做机理分析。隐藏状态里到底发生了什么,是真在算东西还是只是个 placeholder,过去只能靠 probing 间接猜。
SWITCH 的解决方案出乎意料地小:在词表里加一对边界 token <swi> 和 </swi>,模型自己决定什么时候进入潜空间、什么时候退出。这两个边界是普通的离散 token,GRPO 的 ratio 在这两步上完全合法;同时它们也给探针和 causal intervention 提供了固定锚点,可以直接量出潜空间到底做了多少事。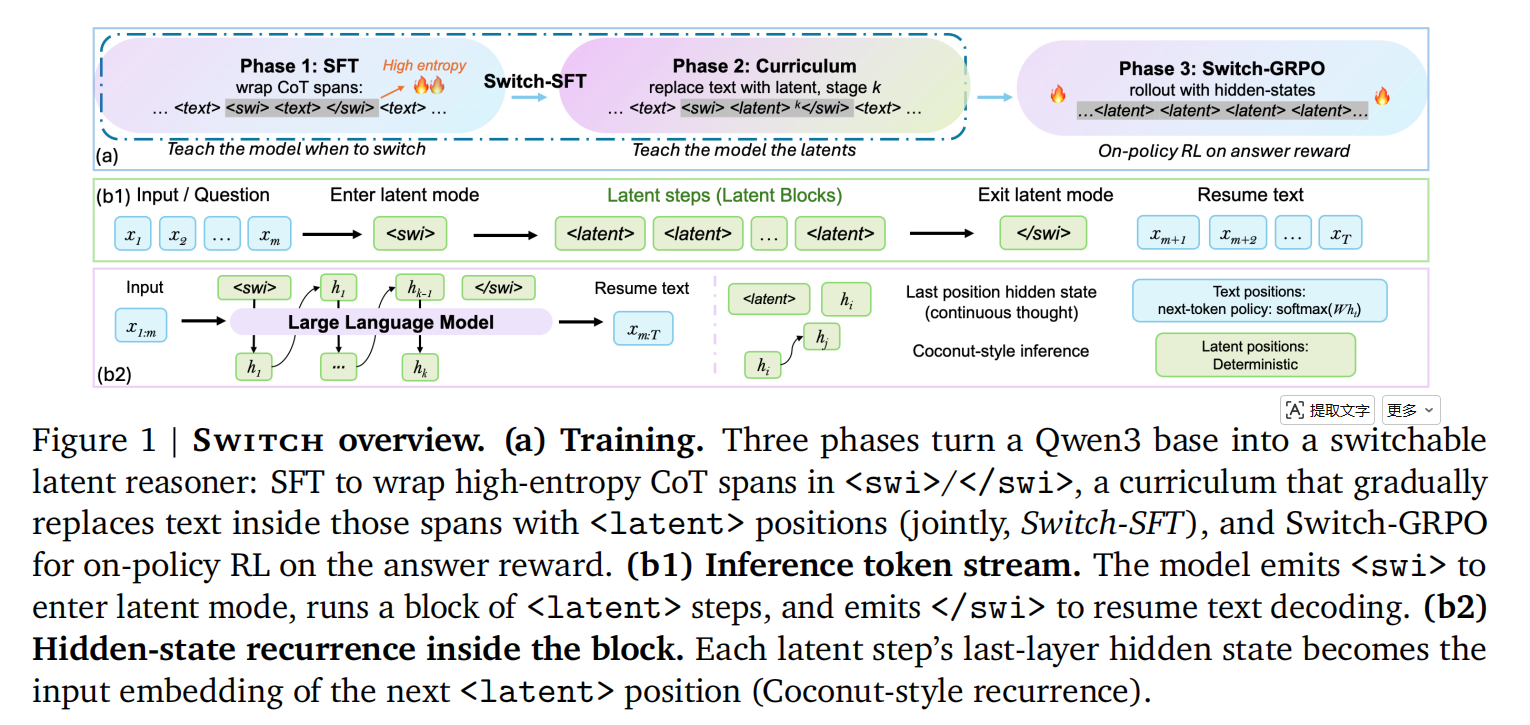
二、关键方法
2.1 边界 token 把潜空间推理离散化
模型词表里新增三个 special token:<swi>、</swi>、<latent>。<swi> 是「打开潜空间」的开关,</swi> 是「退出」的开关,中间用若干 <latent> 占位让 hidden-state 递归继续走。仓库里 src/setup_tokens.py 做的就是这套词表手术,配合 model.resize_token_embeddings(len(tokenizer)) 把 embedding 表扩开。
作者对这套设计的描述是:「Because the boundaries are ordinary discrete tokens, the GRPO policy ratio is well-defined at every decision point.」也就是说边界 token 既是行为开关,也是把 RL 重新接回潜空间的接口。
2.2 Switch-GRPO 与 Coconut 风格 hidden-state 注入
Coconut 包装层在 src/model/coconut_swi_model.py,负责在 <swi>...</swi> 区间内做 hidden-state 注入式的 forward rollout。RL 损失在 src/rl/grpo.py:标准 PPO clipped 目标 + KL 锚定,组采样大小 GROUP_SIZE=5,clip ε=0.2,KL 系数 0.001(来自 train_phase3_grpo.sh 默认值)。关键改动:rollout 路径用 CoconutSwiModel.generate_rl() 实际跑 hidden-state 注入,避免训练-评估目标错位。
2.3 奖励设计 + 三阶段训练课程
src/rl/reward.py 同时给四类信号:
- correctness:最终答案对错。
- format:边界 token 是否成对、是否合法收口。
- latent-usage:是否真用上了潜空间块。
- brevity:不让模型靠堆 token 拿分。
训练分三阶段,仓库 scripts/ 下都有现成 shell:
- Phase 1:
run_stage1_sft.sh,用 LLaMA-Factory 在 9030 条 OpenR1-Math 标注数据上做 QLoRA SFT,让模型学会「在哪里」插边界 token。 - Phase 2:
train_phase2_phase2-1.sh,潜空间课程学习,bf16 LoRA + DDP,把可见 CoT 段逐步替换成<swi>...</swi>潜块。 - Phase 3:
train_phase3_grpo.sh,Switch-GRPO on-policy 强化学习,8×H20,组采样 5、最小潜步数 8、最大新 token 2048、温度 1.0、top-p 0.95、学习率 1e-6。
三、实验结果
3.1 主基准 1:MATH-500
在 Qwen3-8B 同尺度上,SWITCH 的 Phase 3 (Switch-GRPO) LoRA 在 MATH-500 拿到 79.3%,比同规模下最强的 Coconut 风格 latent CoT baseline 高 +25.7 个百分点(来自仓库 README 的 TL;DR)。这是这篇文章里幅度最大的提升。
3.2 主基准 2:GSM8K
同一份 checkpoint 在 GSM8K 拿到 89.2%,说明边界 token + Switch-GRPO 不是只在数学竞赛风格题上 work,常规小学应用题层级也能保住。
3.3 消融与机理实验
作者用 scripts/interpret_swi.py 做了三组机理验证,每一组都是潜空间 RL 工作里少见的硬证据:
<swi>是学到的「切换策略」,不是风格化标签:在标注边界位置上 rank ≤ 2,在随机位置上 rank ≈ 10³,从晚层 hidden state 上线性可解码达到 ~91.9% 准确率。- 潜空间一步是有用的计算:把注入的 hidden state 直接置零,使用了潜推理的题目准确率掉约 2/3;换成同范数随机向量只掉几个点。
- 潜块里的「干活」集中在入口的那一次 hidden-state transition,由
K_min(最小潜步数)约束撑住,后续步几乎是确定性退出p(</swi>) ≈ 1。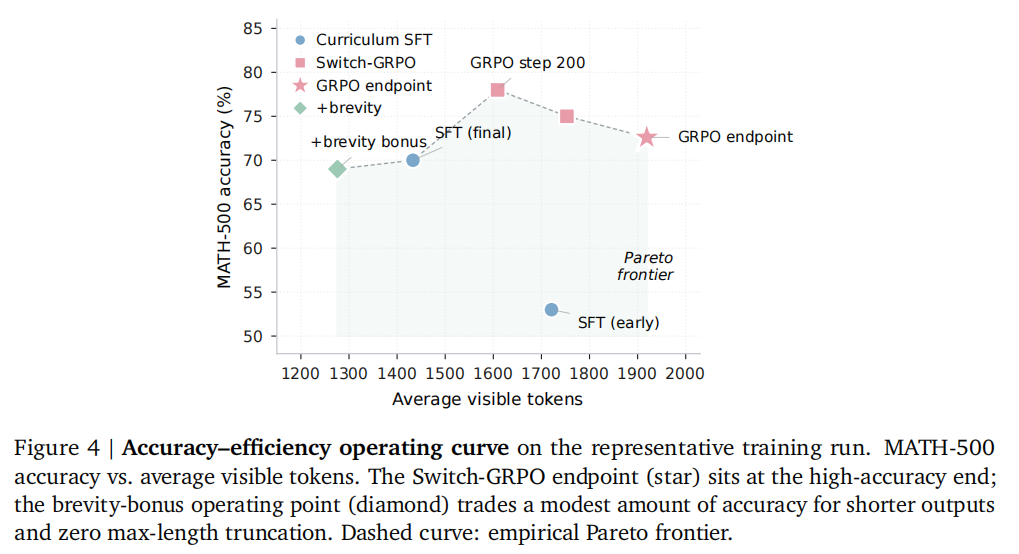
四、本地部署全流程
下面所有命令都直接来自仓库 README 与 scripts/run_stage1_sft.sh / scripts/train_phase2_phase2-1.sh / scripts/train_phase3_grpo.sh,没做改写。
4.1 环境要求
- Python 3.11,CUDA 12.8。
- 训练环境作者用的是 8×NVIDIA H20(96GB 一张)。
- 核心依赖:
torch>=2.4.0、transformers>=4.45.0、peft>=0.12.0、datasets>=2.20.0、accelerate>=0.34.0、safetensors>=0.4.0、tokenizers>=0.19.0、math-verify>=0.7.0、latex2sympy2_extended>=0.1.0、swanlab>=0.4.0、modelscope>=1.18.0(或huggingface_hub>=0.24.0)。
4.2 Step 1:创建环境
conda create -n switch python=3.11 -y
conda activate switch
4.3 Step 2:安装 PyTorch + CUDA
README 注明「PyTorch should be installed first via conda or pip with CUDA support」。按 CUDA 12.8 装即可:
pip install "torch>=2.4.0"
4.4 Step 3:安装关键依赖
pip install -r requirements.txt
4.5 Step 4:克隆仓库并安装
git clone https://github.com/LARK-AI-Lab/SWITCH
cd SWITCH
pip install -r requirements.txt
4.6 Step 5:准备数据
训练数据集已经发布到 HF:LARK-Lab/SWITCH-Math-Train,OpenR1-Math 子集,含 <swi>/</swi> 边界标注和 GRPO rollout prompt。Phase 1 用的是 math_openr1_swi_sft(9030 条),Phase 2/3 用的是 data_hf/data/math_openr1_all.jsonl。仓库自带 scripts/preprocess_sft_data.py,把数据落到 LLaMA-Factory 的 data/ 目录。
4.7 Step 6:训练
三阶段对应三个脚本:
# Phase 1: SFT,定位 <swi> 该插在哪儿(LLaMA-Factory,QLoRA + nf4)
bash scripts/run_stage1_sft.sh
# Phase 2: 潜空间课程,bf16 LoRA + DDP,可见 CoT 逐 span 替换成潜块
bash scripts/train_phase2_phase2-1.sh
# Phase 3: Switch-GRPO on-policy 强化学习
USE_MODELSCOPE=1 bash scripts/train_phase3_grpo.sh
Phase 1 默认超参(来自 run_stage1_sft.sh):LoRA r=32 / α=64,作用于全部线性层,4-bit nf4 + double quantization,per-device batch 1,grad accum 8,optim paged_adamw_32bit,余弦学习率,warmup 0.05,lr 1e-4,3 epoch,max_length 4096,bf16,启用 gradient checkpointing。Phase 3 默认超参(来自 train_phase3_grpo.sh):组采样 G=5,最小潜步数 8,最大新 token 2048,温度 1.0,top-p 0.95,lr 1e-6,3 epoch,clip ε=0.2,KL 系数 0.001,记录到 swanlab。
4.8 Step 7:评估
仓库 scripts/ 下提供了三个评估驱动:eval_gsm8k.py、eval_math500.py、eval_latent.py,分别覆盖 GSM8K、MATH-500、latent 一致性。机理验证另起一支:
python scripts/interpret_swi.py teacher-forced --adapter_path <CKPT>
python scripts/interpret_swi.py switch-window --adapter_path <CKPT>
python scripts/interpret_swi.py probe --adapter_path <CKPT>
python scripts/interpret_swi.py intervention --adapter_path <CKPT> --n 50
python scripts/interpret_swi.py logit-lens --adapter_path <CKPT>
<CKPT> 可以是 LARK-Lab/SWITCH-Phase3-GRPO-LoRA-Qwen3-8B,也可以是自己跑 Phase 3 后落到 outputs/phase3_grpo_v1 的 LoRA。
4.9 硬件建议
- 训练(Phase 1 QLoRA / Phase 2 bf16 LoRA / Phase 3 GRPO):作者环境 8×H20 96GB;如果只想跑 Phase 1,按脚本默认
CUDA_VISIBLE_DEVICES=1+ 4-bit nf4 + grad accum 8,单卡 24GB 也能起训。 - 推理:基础模型 Qwen3-8B + LoRA,bf16 加载约需 16GB 显存,单张 24GB 卡(4090/A10)足够;潜空间循环开销和 token 数线性相关,按
MAX_NEW_TOKENS=2048估时即可。
4.10 预训练模型
- 基模:Qwen/Qwen3-8B(也可走 ModelScope,脚本自带
USE_MODELSCOPE=1开关)。 - LoRA:LARK-Lab/SWITCH-Phase3-GRPO-LoRA-Qwen3-8B。
- 数据:LARK-Lab/SWITCH-Math-Train。
README 还给出最小推理片段:
from peft import PeftModel
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
BASE = "Qwen/Qwen3-8B"
ADAPTER = "LARK-Lab/SWITCH-Phase3-GRPO-LoRA-Qwen3-8B"
tokenizer = AutoTokenizer.from_pretrained(ADAPTER)
model = AutoModelForCausalLM.from_pretrained(
BASE, torch_dtype=torch.bfloat16, device_map="auto"
)
model.resize_token_embeddings(len(tokenizer))
model = PeftModel.from_pretrained(model, ADAPTER)
model.eval()
注意:model.generate(...) 会把 <latent> 当普通 placeholder 跑;要真正激活 Coconut 风格的 hidden-state 递归,必须走 src/model/coconut_swi_model.py 里的 SWITCH 推理循环。
五、为什么重要
RL 工程视角看,SWITCH 的价值不在 MATH-500 那个数字,而在它把潜空间推理这条路重新接回 GRPO 的标准流水线。过去想把 Coconut 类工作工业化,要么放弃 RL 只做 SFT,要么自己魔改 ratio 估计;现在多写两个 token 就行,PPO 那套数学完全保留,verl / OpenRLHF / TRL 这类框架几乎不用改就能跑。
另一个被低估的点是:边界 token 让潜空间变成可观测对象。RL 训练里最痛的事情之一是「不知道模型到底在学什么」,SWITCH 的探针 + 干预实验直接给了答案——<swi> 是策略、潜步是计算、计算集中在入口。这套观测框架可以直接套到其它 latent reasoning / token compression 工作上,做成标准的诊断手册。
六、适用场景与生态
6.1 适用场景
- 数学 / 代码 / 多步推理任务,希望压缩可见 CoT 长度但又不想丢掉 RL 训练的工作。
- 想做潜空间机理分析的研究:边界 token 提供了天然的探针锚点。
- 显存受限场景:Phase 1 走 QLoRA + 单卡,门槛比常规 RL pipeline 低。
6.2 已验证的训练框架 / 任务
- LLaMA-Factory(Phase 1 SFT,QLoRA nf4,作者已在 Qwen3-8B 上跑通)。
- 自研 Switch-GRPO 实现(Phase 3,PPO clipped + KL 锚定,与 verl 框架兼容;致谢里点名了 verl, Sheng et al. 2024)。
- 数据语料:OpenR1-Math 子集(带边界标注),评估覆盖 GSM8K、MATH-500、latent 一致性。
6.3 可迁移的方向
- 把
<swi>/</swi>直接迁到 DeepSeekMath / Qwen3 / Llama 等其它 base 模型上,词表手术脚本是通用的。 - 把 Switch-GRPO 替换成 DAPO、RLOO、Reinforce++ 等更强 RL 算法,框架改动几乎为零(边界 token 与具体 RL 算法解耦)。
- 用同一套探针 + 干预方法去诊断现有 latent reasoning / continuous-thought 工作,作为公共 baseline。
七、局限
- 评估只覆盖数学题(GSM8K / MATH-500),其它推理任务(代码、长上下文 QA、Agentic)未做实验。
- 训练成本仍然不低:Phase 3 默认 8×H20,组采样 5、max new tokens 2048,单次 rollout 显存压力大;潜步数变多时计算复杂度近似线性放大。
- 「计算集中在入口的一次 hidden-state transition」这个发现是 SWITCH 当前规模下的现象,潜步增多或换模型后是否仍成立,作者也没下定论。
- 边界 token 的位置目前还依赖 SFT 阶段的标注(基于 SwiReasoning 的标注流水线),完全 self-supervised 的
<swi>学习还没看到。
参考链接
- 论文 arXiv:https://arxiv.org/abs/2606.13106
- 官方仓库:https://github.com/LARK-AI-Lab/SWITCH
- Phase 3 LoRA:https://huggingface.co/LARK-Lab/SWITCH-Phase3-GRPO-LoRA-Qwen3-8B
- 训练数据集:https://huggingface.co/datasets/LARK-Lab/SWITCH-Math-Train
- 基模 Qwen3-8B:https://huggingface.co/Qwen/Qwen3-8B
关注我,每周更新论文深度解读 + 本地部署指南。
本文首发于公众号 AI 共享前沿

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 17
17 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)