RAG到底是什么?让AI拥有“外挂大脑“的技术
问AI一个问题,它到底是怎么"想"出来的?
很多人觉得AI回答问题就是"它知道答案所以说出来",其实不完全是。
AI大模型就像一个博览群书的天才,但是它读过的书有个截止日期,而且它从来没去过你公司,不知道你们内部那些弯弯绕绕。

你问它"我们公司报销流程是什么?",它只能瞎编。😅
那怎么办?
给它一本《公司内部工作手册》,让它现查现答。
这个"现查现答"的技术,就是RAG。
RAG的全称是Retrieval-Augmented Generation,翻译过来叫"检索增强生成"。名字听着唬人,其实逻辑特别简单:先去资料库里找相关内容,再拿着找到的内容去回答你的问题。
不是靠记忆,是靠查资料。就像你考试的时候,允许带参考资料,那就是开卷考试。不允许带,那就是闭卷——全靠背。
大部分AI,在没有RAG的情况下,都是闭卷考试。📖
RAG是怎么工作的?三步搞定
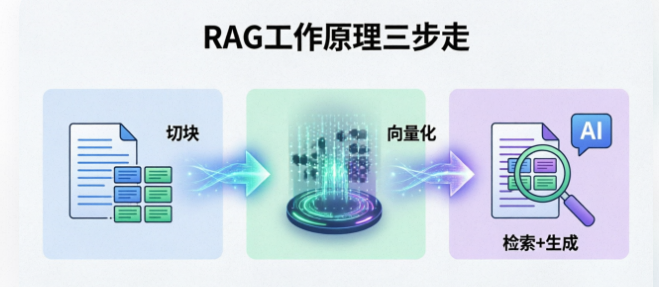
第一步:把你的资料变成AI能"秒查"的格式
假设你有1000份公司文档,PDF、Word、网页啥都有。AI不可能每次回答问题都把1000份文档从头读到尾,那太慢了。
所以要先做"预处理":
切块。 把每份文档切成一个个小段落,每段几百个字。就像把一本书撕成一页一页的笔记卡片。
向量化。 这是最关键的一步。用专门的模型,把每段文字转成一串数字(向量)。这个向量不是乱写的,它能代表这段话的"意思"。
比如"苹果很好吃"和"我喜欢吃水果",它们的向量很接近。而"iPhone很贵"和前两者的向量距离就比较远。
为啥要转成向量?因为向量可以同时比较"语义相似度"。你问"吃什么水果好",AI能找到"苹果很好吃"那段,哪怕字面不完全一样。
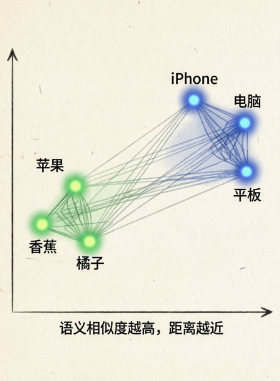
这就像你脑海里"水果"这个概念,跟"苹果""香蕉""橘子"都离得近,但跟"螺丝钉"离得远。向量的作用,就是在AI的"脑海"里建立这种距离关系。
存起来。 把所有文本块和它们的向量,存进一个"向量数据库"。这个数据库专门干一件事:给你一个向量,迅速找出最相似的几个向量对应的文本。
第二步:把你的问题也变成"向量"
你问"我们公司年假政策是什么?"
系统会用同一个向量化模型,把你的问题也转成向量。
现在你的问题和资料库里的所有文本块,都在同一个"向量空间"里了。
第三步:找最相关的内容,然后生成答案
拿着你的问题向量,去向量数据库里搜,找出语义最像的前几段(比如3-5段)。
然后,系统会把这几段相关文本,和你的问题拼在一起,形成一个"增强版提示词",大致长这样:
"请基于以下参考资料回答用户问题。如果参考资料里没有,就说不知道,不要编造。
参考资料:
- • 员工入职满一年,享有每年10个工作日年假
- • 年假需提前三天在OA系统申请
用户问题:我们公司的年假政策是什么?"
最后,AI模型出场。它不看自己训练数据里的东西,只盯着这个"增强版提示词",根据你给的参考资料组织答案。
整个流程,从你敲下问题到AI回复,通常就几秒钟。⚡
为什么RAG比"重新训练AI"划算多了?
有人会想:那我把公司资料直接喂给AI,让它重新学习不就行了?
行,但没必要。💸
重新训练一个大模型,成本可能是几百万美元,耗时几个月。而且你公司资料下个月又更新了,难道再训练一次?
RAG的好处是:资料和模型是分开的。资料随时更新,模型不用动。今天加一份新文档,明天AI就能引用。
这就是"外挂大脑"的意思——大脑(模型)不用改,外挂(知识库)随便换。
就像你玩游戏,角色本身不用重新练,换个装备就能提升战斗力。RAG就是给AI换装备。🎮
RAG能干什么?三个典型场景
场景一:企业内部知识助手
你公司有几万份技术文档、合同模板、产品手册。新员工问"这个接口怎么调用?",老员工也记不住,得翻半天。
有RAG,直接问,AI去知识库里找,秒回,还带原文引用。
我之前在一家公司,内部Wiki乱得跟屎一样,想找个东西全靠运气。要是当时有RAG,我也不至于每次找个文档都要花半小时。🙄
场景二:客服机器人(终于不智障了)
传统客服机器人靠关键词匹配,你问"怎么退款"它懂,你问"我不想要了能退吗"它就傻了。
就像那种只会按脚本走的客服,你稍微换个说法它就识别不出来了。
RAG版的客服,能理解你问题的意思,去产品手册、退款政策文档里找依据,然后给你一个像人话的答案。
而且它不会瞎编——如果知识库没有退款相关内容,它会老实说"这个问题我不确定,建议联系人工客服"。
虽然有时候它也会犯傻,但至少不会像以前那样,你问"A",它回答"B",还一脸自信。😂
场景三:个人知识库助手
你有几百篇笔记、PDF论文、会议记录。想不起来某件事写在哪了。
把这些都塞进知识库,然后直接问"我之前关于Token计费的想法是什么来着?",AI帮你找出来,还能总结。
这个我自己就在用。我的笔记散落在各个地方,有时候想找之前写的一段话,搜关键词都搜不到,因为我不记得 exact 的用词。但RAG能根据语义找,哪怕我不记得原话,也能找到。✅
RAG和联网搜索,不是一回事
很多人觉得"RAG不就是让AI能上网搜吗",其实差别挺大。
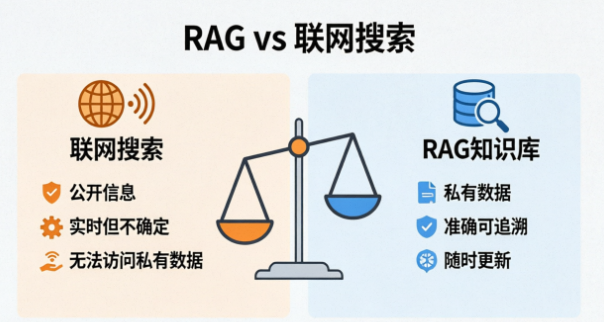
有几个事情,联网搜索做不到,但RAG可以:
处理私有数据。 你们公司的财务报表、客户合同、产品原型图,互联网上根本没有。但你可以把这些塞进知识库,让AI基于这些信息工作。
确保事实准确性。 联网搜出来的东西可能有误,或者把不同来源的信息混在一起。RAG可以让你点开答案里的引用,直接跳回原始文档核对。
比如你问"我们公司给离职员工的补偿金N+几?"联网可能搜到一堆劳动法的通用解释。但RAG可以直接引用你们公司《员工手册》第8章第3条,并高亮原文"N+1",让你立刻核对。📄
获取私有时效性信息。 联网能搜到"今天天气",但搜不到"昨天下午3点老板在周会上关于Q3战略的具体表述"——除非那个会议纪要公开了。但你随时可以把会议纪要扔进知识库。
现实中最强的用法:RAG + 联网搜索,一起上
聪明的AI应用,往往是"联网搜索 + 私有知识库 + 基础模型能力"三合一。
举个例子:你问"对比一下我们公司的新品X和竞品Y,列出Y近半年的负面新闻。"
- • 先查私有知识库:找出你们公司关于新品X的内部文档、评测报告
- • 再联网搜索:去网上搜"竞品Y 负面新闻"、"竞品Y 故障"
- • 最后综合生成:AI把内部数据和公开信息揉在一起,给你一个既有内情又有背景的完整答案
只用联网:能告诉你竞品Y的最新新闻,但不知道你们公司的新品X是什么。🔍
只用RAG:能告诉你新品X的详细参数,但不知道竞品Y最近出了什么事。
两个一起用:既能内部对比,又能掌握外界动态。这才是真正的"内外兼修"。💪
搭一个RAG知识库,难吗?
其实现在已经有很多工具能帮你搭,不需要从零写代码。
开源的有LangChain、LlamaIndex,帮你把"切块→向量化→存储→检索→生成"这条链路串起来。
直接用现成产品的有Notion AI、Obsidian插件、各种企业知识库平台,上传文档就能用。
最难的部分其实不是技术,是资料质量。你塞进去的文档如果本身乱七八糟、版本混乱,AI检索出来的结果也好不到哪去。
垃圾进,垃圾出。这句话在RAG上同样适用。♻️
我见过有人把公司几年的文档往知识库一扔,也不整理,然后抱怨AI回答不准确。这就好比你给天才实习生一本乱写乱画的笔记本,他还得先辨认字迹,能准确才怪。
所以,搭RAG之前,先把资料理清楚。该删的删,该更新的更新,该标注版本的标注版本。
这一步很烦,但值得。
关注小虾,一起成长,一起进化

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 7
7 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)