盘点|李飞飞团队2026上半年研究:具身智能的五个关键落子

「从数据、生成到操作」
目录
在探讨具身智能时,空间智能是一个核心议题。它要求系统不仅能解析二维图像,还要能理解三维空间的物理规律,并据此规划动作。
目前的AI系统在处理静态图像或生成文本方面表现出色,但在真实物理世界中与物体进行可靠交互时,仍面临数据匮乏、计算效率低下以及物理状态估计困难等瓶颈。
2026年上半年,斯坦福大学视觉实验室(Stanford Vision Lab)在李飞飞教授的指导下,发表了多项相关研究。
本文盘点李飞飞作为末位大通讯作者的5篇2026年研究,涵盖数据基座、生成模型架构、机器人3D操作三大方向,为观察当前具身智能的空间智能探索提供一个切面。
此前我们还盘点了2025年李飞飞团队的工作:李飞飞团队 2025 年研究大盘点:从视觉理解到具身智能的全景图谱
01 视觉生成的基础数据:GPIC
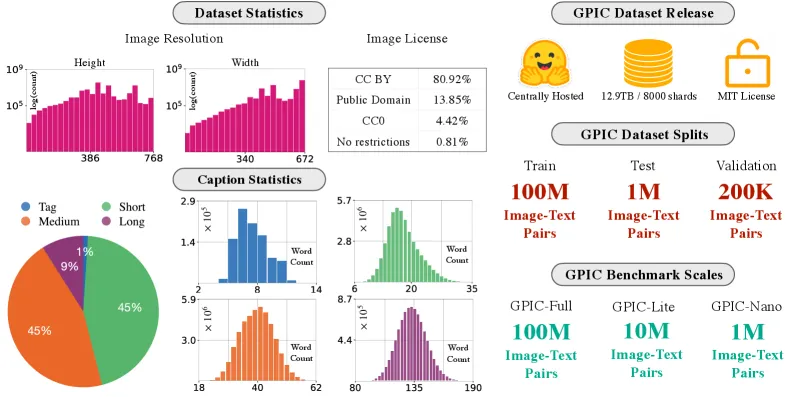
图1 | GPIC数据集统计信息,包含1亿张图片,提供多种长度的VLM标注描述。
论文标题: GPIC: A Giant Permissive Image Corpus for Visual Generation
现存问题:当前视觉生成模型的训练高度依赖海量数据。然而,长期作为基准的ImageNet-1K已难以满足现代模型对数据规模和多样性的需求,且存在模型在基准上过拟合的问题。同时,工业界使用的大规模数据集往往受限于版权争议或数据链接失效,难以作为公开的科学比较基准。
论文方法:为了应对这一问题,研究团队推出了 GPIC。这是一个包含约28万亿像素、1亿张训练图片的语料库。
GPIC的主要特点是其明确的许可属性。数据集中的图片来源于Flickr和Wikimedia,许可类型包括CC BY和Public Domain等,允许用于学术研究和商业开发。在数据处理上,团队通过过滤低分辨率图片、使用SSCD特征进行去重,并利用Qwen3-VL大模型为图片生成了从标签(Tag)到长文本四种不同粒度的描述。
GPIC为视觉生成模型提供了一个规避版权风险、规模庞大且开源的训练基准。对于具身智能而言,高质量的视觉数据是训练稳健认知模型的前提。
02 应对未知动态的机器人操作:RAPiD
图2 | RAPiD方法流程。在仿真中利用特权信息训练策略,随后在真实世界中依靠视觉观察推断物体动态属性。
论文标题: Rapid Adaptation of Particle Dynamics for Generalized Deformable Object Mobile Manipulation(ICRA 2026)
现存问题:机器人操作可变形物体(Deformable Objects,如衣物、线缆)是一个长期挑战。这类物体的物理动态(如形变、弯曲)在操作前往往是未知的,且在交互过程中会发生复杂变化。传统的显式状态估计方法在面对遮挡时容易失效。
核心内容:因此,团队提出了 RAPiD方法,旨在提高机器人对未知动态的适应能力。RAPiD采用两阶段学习策略:首先在仿真环境中,利用特权信息(如物体的质量、真实的粒子位置)训练一个视觉运动策略;随后,训练一个适应模块,使其能够仅通过机器人的视觉观察和历史动作,推断出这些隐藏的物理参数。
将该策略部署到22自由度的移动机械臂上后,机器人在面对未见过的可变形物体时,在两项特定任务中的成功率超过80%。这种隐式推断物理参数的方法有效规避了复杂的显式建模。
03 优化像素空间生成的轨迹:Latent Forcing
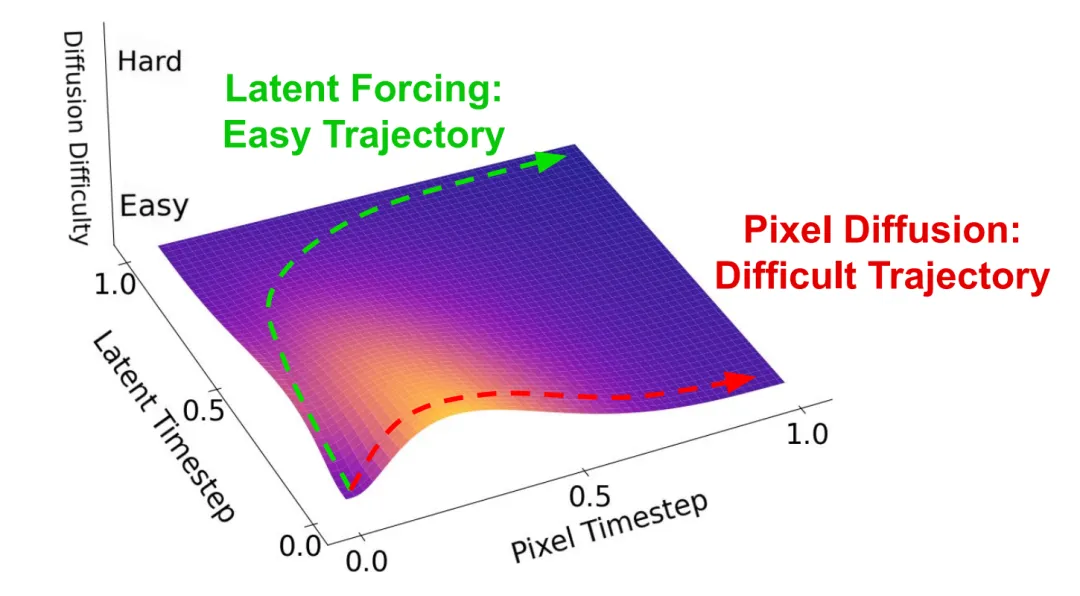
图3 | Latent Forcing概念图。通过让潜在特征(Latents)和像素(Pixels)在不同的时间变量下共同扩散,重排去噪轨迹。
论文标题: Latent Forcing: Reordering the Diffusion Trajectory for Pixel-Space Image Generation(ICML 2026)
现存问题:在图像生成中,潜在扩散模型通过将图像压缩至潜在空间进行生成,提高了计算效率,但压缩过程会导致高频细节(如人脸、文本)的丢失。直接在像素空间进行扩散生成虽然无损,但计算成本高且难以收敛。
核心内容:因此,团队提出了 Latent Forcing,试图在两者之间寻找平衡。Latent Forcing并未放弃像素空间,而是重新设计了生成过程的顺序。该方法让潜在特征(Latents)和像素(Pixels)在同一个扩散模型中联合处理,但赋予它们独立的时间调度。模型首先利用Latents生成高层的结构信息,随后再生成高频的像素细节。生成结束后,Latents信息会被丢弃。
该方法在保留端到端像素生成优势的同时,获得了接近潜在扩散模型的收敛效率。在ImageNet基准测试中,Latent Forcing在同等算力下提升了Diffusion Transformer像素生成的表现。
04 提升长视频理解的数据策略:VideoWeave
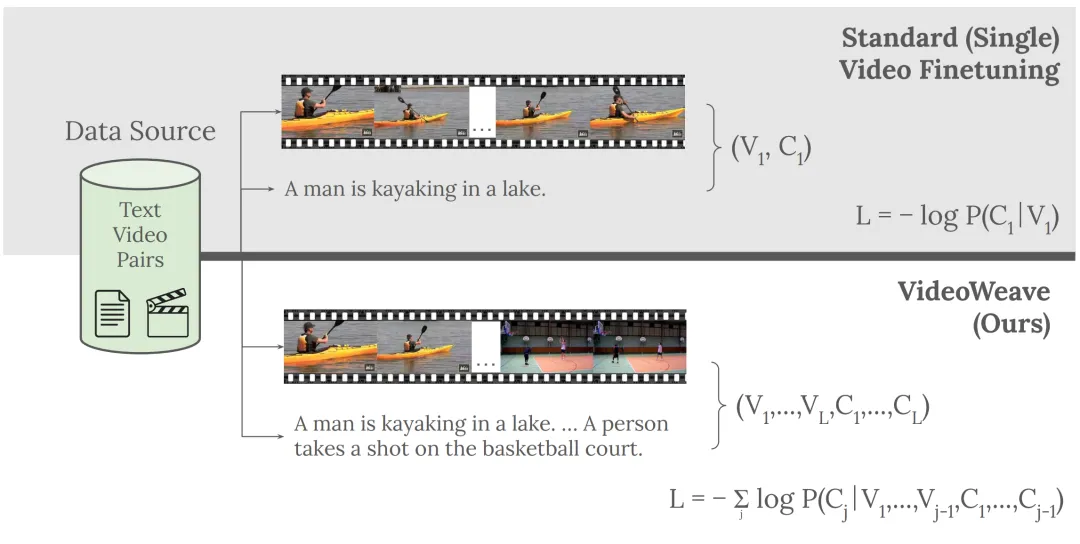
图4 | VideoWeave方法示意图。将多个短视频及其描述拼接成一个单一的长输入样本。
论文标题: VideoWeave: A Data-Centric Approach for Efficient Video Understanding
现存问题:训练能够理解长视频的视觉语言模型面临两个问题:一是长视频标注数据极其匮乏,现存数据集多为短片段;二是处理多帧视频输入需要消耗巨大的计算资源。
核心内容:团队提出了一种以数据为中心的方法——VideoWeave,试图在不增加人工标注成本的情况下解决上述问题。VideoWeave的做法是将现有的多个短视频片段及其对应的标注文本直接串联,拼接成合成的长上下文训练样本。这种方法在不增加总帧数的情况下,增加了输入样本在时间维度上的复杂性,从而减少了模型训练所需的迭代次数。
在固定的计算预算下,使用VideoWeave训练的模型在长视频问答任务(如VideoMME基准)上表现优于传统的单视频微调方法。这是一种极具性价比的数据增强策略。
05 统一状态与动作的3D世界模型:PointWorld
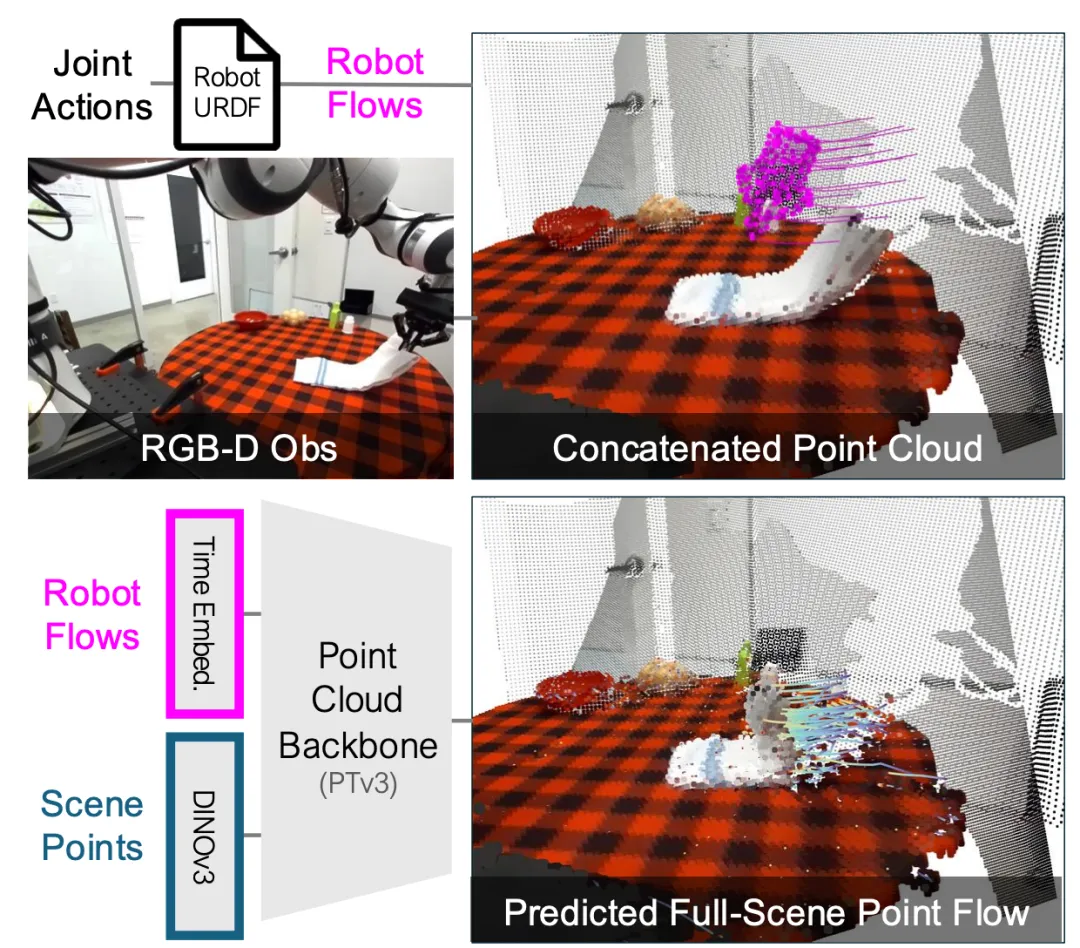
图5 | PointWorld方法概览。将RGB-D图像和机器人动作转换为3D点流,通过点云骨干网络预测全场景的3D变化。
论文标题: PointWorld: Scaling 3D World Models for In-The-Wild Robotic Manipulation(CVPR 2026)
现存问题:为了让机器人在真实世界中进行可靠的操作,系统需要预测动作在3D空间中会引发的物理变化。传统的2D视频预测模型难以提供精确的三维空间信息。
核心内容:团队提出了一个大规模预训练的3D世界模型。PointWorld的核心在于其表示方法的统一:将"环境状态"和"机器人动作"全部表示为3D点流。给定部分观察到的RGB-D图像和计划执行的动作指令,模型能够预测场景中每个3D点在未来的位移。这种表示方法隐式地包含了物体的分割、材质和接触关系,且不依赖于特定的机器人形态,从而能够利用海量不同来源的机器人交互数据进行预训练。
PointWorld展示了从单张图像预测3D物理交互结果的潜力。在预训练模型的支持下,真实机器人能够在无需额外微调的情况下完成推箱子等操作任务。这为空间智能的实现提供了一个有力的架构。
06 具身智能的破局与边界
这五项研究共同描绘了当前具身智能探索的一个重要侧面。
它们系统性地解决了从数据基础到物理交互的多个核心挑战:
- GPIC 确保了训练数据的合规与规模;
- Latent Forcing 和 VideoWeave 探索了在有限计算资源下提升视觉生成和长视频理解效率的创新路径;
- PointWorld 和 RAPiD 则直接聚焦于物理世界的复杂性,通过统一的3D表征和隐式物理参数推断,增强了机器人在未知环境中的操作鲁棒性。
这些工作表明,具身智能的突破正依赖于跨越传统计算机视觉和机器人学的界限,构建更具物理感知和因果推理能力的“世界模型”。
尽管在实现完全开放环境下的通用智能体仍面临长时程规划和实时计算效率的挑战,但这些研究为构建更可靠、更具空间智能的机器人系统奠定了关键的数据和方法论基础。
References:
[1] Keshigeyan Chandrasegaran, et al. "GPIC: A Giant Permissive Image Corpus for Visual Generation." arXiv:2605.30341 (2026).
[2] Bohan Wu, et al. "Rapid Adaptation of Particle Dynamics for Generalized Deformable Object Mobile Manipulation." arXiv:2603.18246 (2026 ).
[3] Alan Baade, et al. "Latent Forcing: Reordering the Diffusion Trajectory for Pixel-Space Image Generation." arXiv:2602.11401 (2026 ).
[4] Zane Durante, et al. "VideoWeave: A Data-Centric Approach for Efficient Video Understanding." arXiv:2601.06309 (2026 ).
[5] Wenlong Huang, et al. "PointWorld: Scaling 3D World Models for In-The-Wild Robotic Manipulation." arXiv:2601.03782 (2026 ).

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 11
11 0
0- 0



 已为社区贡献78条内容
已为社区贡献78条内容

所有评论(0)