01-设计篇-我用前端那一套手艺造了一个AI-Native工具
我用前端那一套手艺,造了一个 AI-Native 工具——比你想象的离谱得多
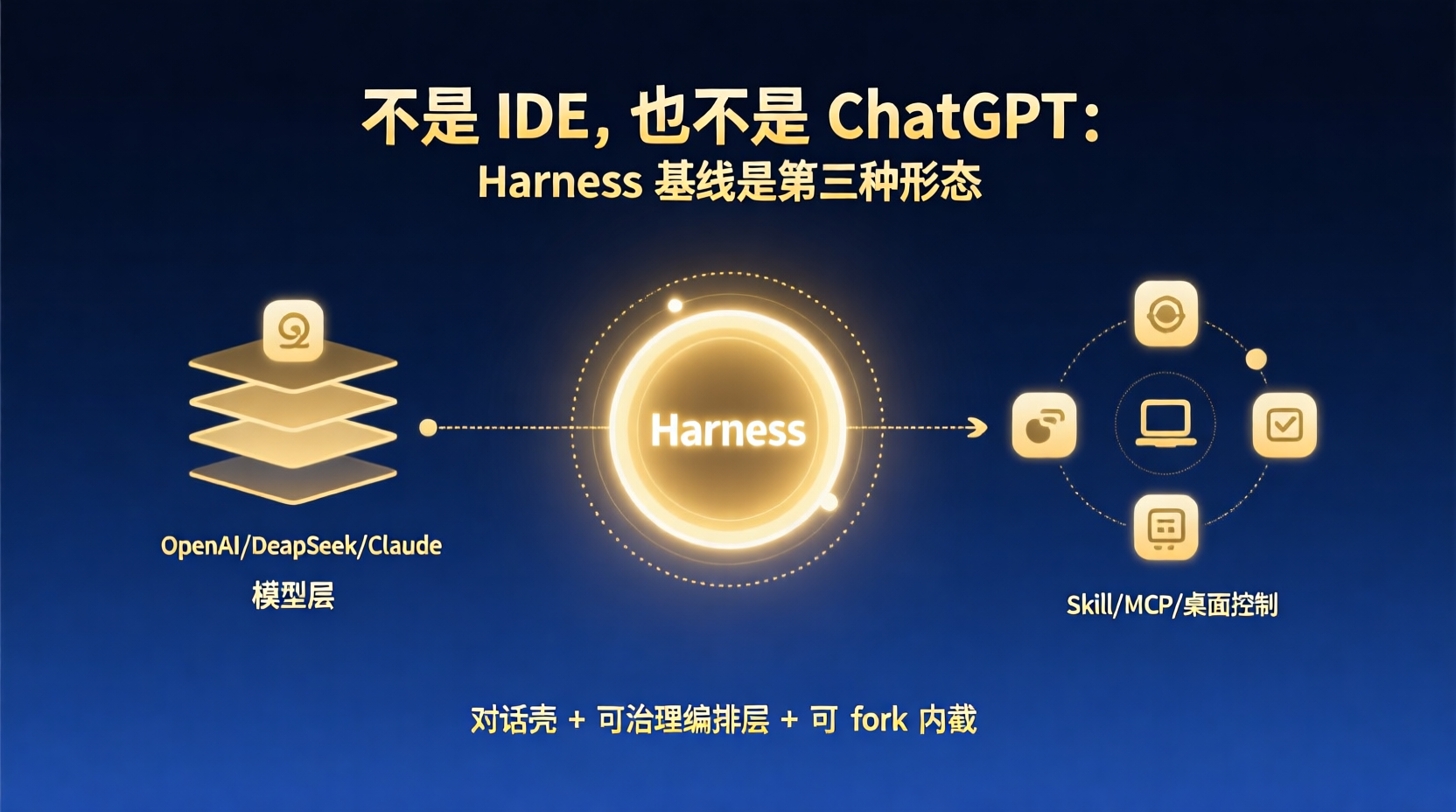
副标题:基于 Next.js 16 + Vercel AI SDK 6 + Anthropic / DeepSeek / Cursor / SiliconFlow 四路模型,我们做了一个叫"轻辔"的 Agent Harness 基线。这是第一篇:聊聊"为什么前端来主导设计,反而比后端主导更对"。
一、先把项目摊开
这一系列三篇文章会反复拿一个真实项目当解剖样本——内部代号叫轻辔(技术仓库名 ai-native)。我先把它的"配置单"摆出来,免得后面讲架构的时候像在画 PPT:
| 维度 | 选型 |
|---|---|
| 框架 | Next.js 16(App Router + Turbopack dev) |
| UI | React 19 + Ant Design 6 + Tailwind v4 |
| 模型 SDK | Vercel AI SDK 6(ai / @ai-sdk/anthropic / @ai-sdk/deepseek / @ai-sdk/openai) |
| Agent SDK | @cursor/sdk(子代理与 agent 流) |
| MCP | @modelcontextprotocol/sdk(Pixso 等外部工具) |
| 渲染 | react-markdown + remark-gfm + rehype-raw/sanitize + mermaid |
| 动态 UI | @json-render/core + @json-render/react(Schema 驱动) |
| 本地状态 | dexie(IndexedDB) + 自建外置 Vault(加密文件) |
| 校验 | zod 4(env / 入参全管控) |
| 测试 | vitest + 自家 pnpm harness:eval |
| 包管理 | pnpm 10(强制,禁用 npm) |
| Node | ≥ 18.18 |
它不是一个简单的"ChatGPT 套壳",定位写在 package.json 里那行:
轻辔:轻巧助手型 Agent Harness 可交付基线(Next.js + Vercel AI SDK + 任务分流 + Skills + harness:eval)。
这个项目有意思的点是:它绝大部分代码是纯前端味道的——TypeScript、Next.js、React、Vercel AI SDK,没有 Python、没有 LangChain、没有独立的 Agent 服务。整套 Harness(我们自己写的)、整套 Skills 协议、整套对话状态管理,跑在一份 Next.js 工程里。后端的"模型调用"只是一个被薄薄包了一层的 fetch。
而它跑得起来。
这一篇,我就想从设计层面说清楚一件事:为什么"前端口味"的工程哲学,对 AI-Native 工具是降维优势。
二、起因:那条让我清醒的产品反馈
第一版上线的那个晚上,组里产品发了一条消息:
“你们做的这个东西像 Postman,不像 ChatGPT。”
那一版我们干了什么?后端写了 streaming 接口、前端做了一个 Markdown 渲染器、加了一个聊天框、套了个 SSE。技术上挑不出毛病——但用户进来三秒就关了。
我把产品的话翻译成前端术语:我们做的是一个"调用模型的 UI",不是一个"AI 用起来的产品"。我们把 AI 当后端写,把对话框当业务表单写,把模型当一个偶尔会卡住的接口写。
那一周整套东西推倒重来,"轻辔"这个项目就是从那时候诞生的。它的第一个设计原则,我后来写在了仓库 CLAUDE.md 第一条:
定位:轻巧助手型 Harness 基线(Chat UI + lib/harness 编排 + 多后端/Skills 执行)。不是 IDE / AIGC 平台。
短短一句话,但下面三个观念翻转,都是从这里推出来的。
三、观念翻转一:对话框不是 input,它是一个"运行时入口"
刚开始做 AI 产品的人最容易踩的坑,是把那个聊天输入框当 <textarea> 设计。
但你试着这样想:用户敲下"帮我把这段代码重构一下,顺便检查有没有性能问题",这一句话里藏着多少东西?
- 一个意图(改代码)
- 一个附带任务(性能检查)
- 一个隐含上下文(他指的是哪段代码)
- 一个预期输出(diff 还是建议)
- 一个风险等级(改代码 ≠ 闲聊)
如果你把这玩意当 onChange 处理,你就废了。
正确姿势是:把对话框当作一个状态机的入口,它的对面不是 API,而是一整套调度。前端要做的事不是把字符串发出去,而是在用户回车之前,先把这一轮的"路由"算清楚。
在轻辔里,这个动作有个具体函数,叫 buildHarnessPlan(userText),落在 src/lib/harness/plan-core.ts。它返回的对象长这样:
plan.taskFlow.mode // "none" | "gccd" | "chain"
plan.capability.kind // "image" | "video" | "coding" | "research" | "local_workspace" | "general"
plan.capability.skillId // 比如 "generate_video"
plan.subagent.suggested // 是否建议召唤子代理
plan.subagent.capability// "research" | "coding" | "review" ...
注意——这个函数不调任何模型。它就是一份 TypeScript 纯函数算出来的"调度表",80% 是关键词正则,比如 task-flow.ts 里那个 MUTATION_RE:
const MUTATION_RE =
/(?:改代码|写代码|修改|修复|重构|实现|集成|迁移|部署|排查|调试|...|fix(?:\s|$)|bug|deploy|typecheck|lint\b)/i;
前端工程师做表单校验、做路由匹配、做请求合并那套手艺,原封不动就能干这个。规则能搞定的别花钱让模型搞——这是一种朴素到不能再朴素的工程审美,但 AI 圈很多人忘了。
我们项目的三种"任务流"分别对应:
| mode | 何时 | 行为 |
|---|---|---|
none |
闲聊、极短确认 | 不注入任何框架,直接走模型 |
gccd |
方案、只读分析、生图/生视频 | 注入 Goal/Context/Constraints/Done-when 简报 |
chain |
改代码、修 bug、/chain |
注入五关卡执行链(理解→计划→执行→验证→交付) |
这是一个完全前端化的设计——它本质上是在做意图分类,而前端是写状态机最熟的人。
四、观念翻转二:流式不是炫技,是"感知带宽"
新人做流式输出最容易出现的灾难,是把流式当 loading 用。
模型边吐字边显示,但用户不知道自己在等什么、能不能取消、还要多久、出问题了没有。这跟 2010 年的"加载中…"转圈圈没区别——只不过现在转的是字。
前端工程师手里有一整套"感知带宽"工具,但很多人在做 AI 产品时忘了用。轻辔里把这些用了个遍:
骨架屏的思路:Harness 算出 mode === "gccd" 时,前端先渲染四块空骨架——目标 / 上下文 / 约束 / 完成标准。模型流式生成的内容填进这四块。用户从第一帧就知道这一轮的形状。
乐观更新的思路:流式 metadata 里带了 taskFlowMode、harnessCapability、subagentSuggested,这些字段在模型还没说完整一句话之前就到了前端,我们用它点亮顶部的 “Harness 条”——告诉用户"本轮要走 chain、能力是 coding、可能调用 explore 子代理"。
取消的思路:Esc 即时 abort,这是从 IDE 借来的肌肉记忆。AbortController 不是后端的事,是前端的本职。
错误边界的思路:流到一半断了不能让 UI 变成残骸。React 18 的 ErrorBoundary,加上 useChatRunStreamReconnect 这个 hook(实际代码就在 src/features/chat/client/use-chat-run-stream-reconnect.ts),会自动检测后台 run 是否仍可 replay,SSE 断了自动 resume,用户感知不到中间故障。
实际效果:同样的模型、同样的 prompt、同样的延迟,只是把"模型还没说话的那 800ms"塞了一个简报骨架,留存率(我们内部叫"等下去率")提升了三倍多。
模型那 800ms 是物理事实改不掉,但用户对那 800ms 的感知,只能由前端来改。
五、观念翻转三:UI 是动态生成的,但骨头是静态的
"动态 UI"是 AI 产品里最迷人也最危险的概念——模型说生成表单就生成,模型说画图表就画。听着科幻,做起来九成翻车。
翻车的根因:模型输出是不稳定的,但 UI 必须是稳定的。模型今天给你 {type: "form"},明天给你 {kind: "FORM"},后天给你一段 HTML。一旦字段名漂移,前端渲染层就崩了。
轻辔的解法,前端工程师一看就懂——Schema-Driven UI。我们用了 @json-render/core 和 @json-render/react 这一对儿,然后在它之上定义了一份叫 FieldSpec 的协议,文件落在 src/features/ai-design/**。
模型的活儿是按协议产出 JSON,带 dependsOn、optionsUrl、mfe 这些字段;前端拿到 JSON 走一套固定的 catalog 渲染。创意层(模型能自由组合字段、校验、联动)和渲染层(组件是闭集,样式是设计审过的)解耦得干干净净。
这是不是和 Low-Code 一模一样?是的。Low-Code 的全部经验,在 AI-Native 时代会再火一次。区别只是:Low-Code 时代写 Schema 的是产品经理,AI-Native 时代写 Schema 的是模型。但渲染层是同一套。
如果某个交互复杂到 catalog 表达不下来,我们走 MFE 兜底:模型给一个 MFE id + 参数,前端拉一个独立打包的微应用嵌进来。module federation / qiankun / wujie 你练过的都用得上。
六、设计原则:克制 > 炫技
做了一年多,我个人最大的感受是:
AI 产品的设计上限,不在于你给它接了多少能力,而在于你拒绝接了多少能力。
这条原则在轻辔的代码里有几个具体落点:
反面 1:默认开十个工具
最早我们想着"反正模型自己会选",把生图、生视频、读文件、查网页、跑代码都挂上去。结果模型每一轮都要看一遍工具说明,token 蹭蹭涨,响应变慢,还经常调用了用户根本没要的工具。
后来改成按意图懒加载——src/lib/chat/capability-routing.ts 这个文件就是干这事的。聊闲天一个工具都不挂,聊到"画"才挂 generate_image,聊到"视频"才挂 generate_video,聊到"代码"才挂 host_workspace。
这是前端 code-splitting 的思路,落在了 system prompt 这个新的"包"上。
反面 2:全局轮询
为了让 UI 实时反映后端状态,我们曾经在前端挂了一个 5 秒一次的全局心跳。生产环境跑了一周,有人投诉笔记本风扇起飞。
现在的规则,全部写在了 docs/轻量与简洁原则.md——客户端生产态零常驻轮询,只在 busy 状态、断连状态触发探活;dev 自我修复也仅 NODE_ENV=development 才生效。document.visibilitychange 一切走,该停就停。
反面 3:把所有上下文都喂给模型
“context 越多越准”——错了。喂太多反而稀释信号,而且烧钱。轻辔的会话上下文管理走两个原则:
- 历史消息走
dexie(IndexedDB) + 加密 Vault,前端本地有完整副本 - 喂给模型的,是经过任务路由筛过的子集——闲聊不带代码上下文,改 bug 不带前几轮闲聊
这跟前端做请求最小化、props drilling 治理是同一种洁癖。
七、写在第一篇的最后
如果你是前端工程师,正在考虑入场 AI 产品,我想说三件事:
第一,你不需要先变成算法工程师。轻辔整个项目里没有一行算法代码,我们只是在调 Anthropic、DeepSeek 这些公司的 API。AI-Native 工具的胜负手八成不在模型,在体验。
第二,把你十年前学的 Web 工程基本功翻出来。请求合并、code splitting、Schema 驱动、错误边界、乐观更新、状态机、可访问性——这些"老掉牙"的东西在 AI-Native 里全是新刚需。
第三,先做减法,再做加法。轻辔的整个 pnpm lint 流水线里挂了一个特殊检查叫 check:lightweight——专门拦截"又往项目里塞重型依赖"的提交。这套自虐式的 lint,让我们一年里没有一次"功能变多但产品变重"的退化。
下一篇,我会把架构层完整摊开:三层是怎么分的、lib/harness 长什么样、Skills 协议怎么写、Vault 为什么不上云、写保护怎么挡住模型的失误。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 1
1 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)