STM32 新手必踩坑:CubeMX 生成代码后,哪些地方可以改,哪些地方别乱改
STM32 新手必踩坑:CubeMX 生成代码后,哪些地方可以改,哪些地方别乱改
很多 STM32 新手第一次用 CubeMX,都会遇到一个很崩溃的问题:
我明明在 main.c 里写了代码。
后来回 CubeMX 改了一个引脚,再点 Generate Code。
结果代码没了。
这不是你操作错了,也不是 VSCode 或 Keil 坏了。
CubeMX 本来就是一个“代码生成器”。你每次点 Generate Code,它都会根据 .ioc 配置重新生成一部分代码。问题在于:你写的代码有没有放在 CubeMX 允许保留的位置。
这一篇不讲新外设,只讲一个非常基础但非常重要的工程习惯:
CubeMX 生成代码后,哪些地方可以改?
哪些地方别乱改?
USER CODE BEGIN / END 到底是干什么的?
这件事看起来小,但越早养成习惯,后面写 LED、按键、USART、定时器、PWM、ADC、DMA 都会省很多痛苦。
本篇目标
读完这篇,你至少要能判断:
-
哪些代码写在
USER CODE BEGIN/END之间; -
哪些 CubeMX 自动生成的代码不要直接改;
-
为什么自己写的
app_led.c、app_uart.c更安全; -
CubeMX 重新生成代码前后应该检查什么;
-
代码被覆盖后,应该怎么排查和补救。
本篇不写新的外设工程,只解决一个工程习惯:
让你的代码能经得起 CubeMX 反复 Generate Code。
CubeMX 生成代码时到底做了什么
你可以把 CubeMX 想象成一个工人。
.ioc 文件是施工图纸。
你点 Generate Code,CubeMX 就按照这张图纸重新铺线、重新生成初始化函数、重新更新 main.h 里的引脚宏。
它很勤快,但它不一定知道哪些代码是你后来手写的。
所以 ST 在生成的文件里预留了一些安全区域:
/* USER CODE BEGIN xxx */
/* 你自己的代码写在这里 */
/* USER CODE END xxx */
CubeMX 重新生成代码时,一般会保留这些区域里的内容。
不在这些区域里的手写代码,就可能被覆盖。
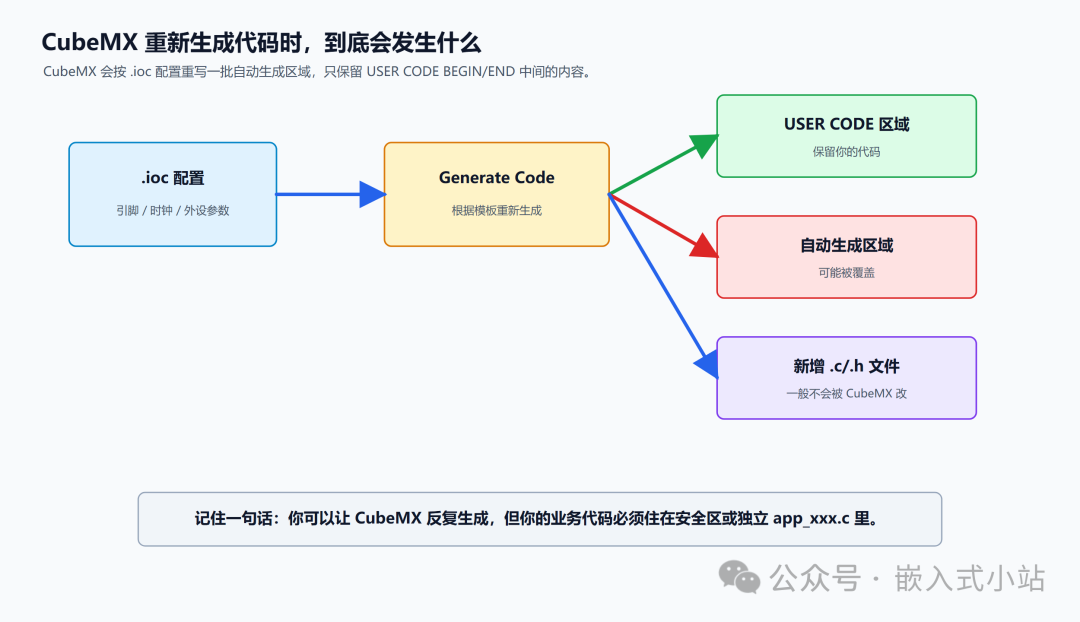
一句话:
CubeMX 负责生成框架。
你负责在它给你的安全区里补业务代码。
USER CODE BEGIN/END 是什么
看一个最常见的例子。
CubeMX 生成的 main.c 里会有很多类似这样的标记:
/* USER CODE BEGIN Includes */
/* USER CODE END Includes */
它的意思不是普通注释。
它更像 CubeMX 和你之间的一个约定:
这两行中间的内容归用户。
下次 Generate Code 时,我尽量不动这里。
所以你要写自己的 [#include](javascript:;),应该这样写:
/* USER CODE BEGIN Includes */
#include "app_led.h"
#include "app_key.h"
#include "app_uart.h"
/* USER CODE END Includes */
不要写成这样:
#include "main.h"
#include "app_led.h" /* 不建议直接插在自动生成区域 */
因为下一次 CubeMX 重新生成 main.c 时,它可能重新整理 include 区域,你手插进去的内容就有机会消失。
main.c 里最常用的几个安全区
新手不用一下子记住所有 USER CODE 区域。
先记住下面 6 个就够用了。
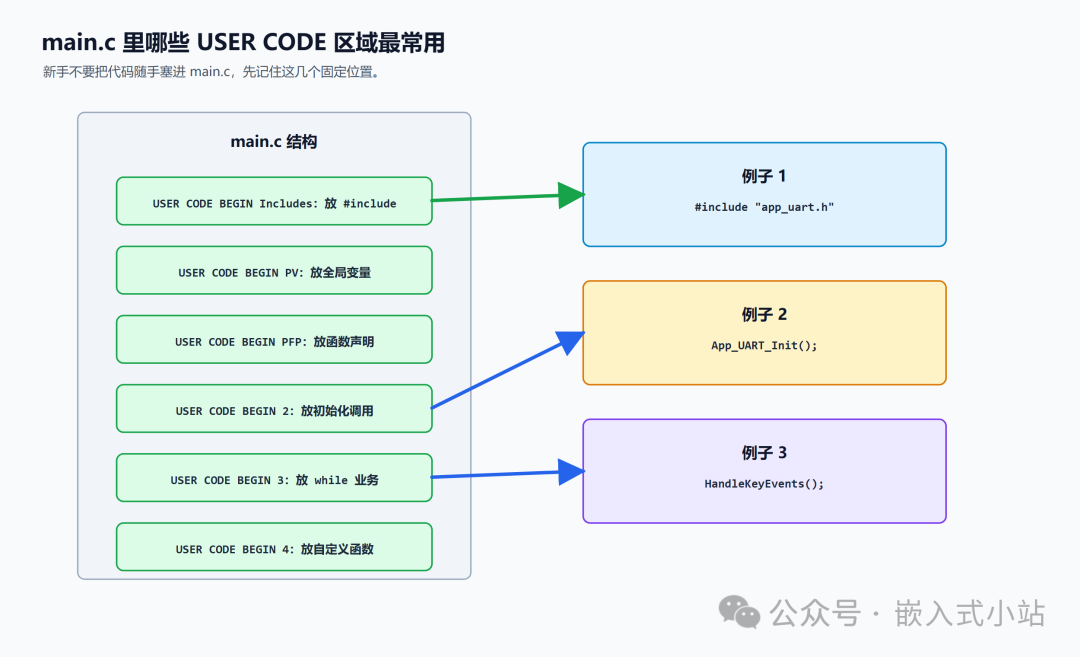
1. Includes 区域:放头文件
位置:
/* USER CODE BEGIN Includes */
/* USER CODE END Includes */
适合放:
#include "app_led.h"
#include "app_key.h"
#include "app_uart.h"
#include <stdio.h>
不要把自己的头文件随手插到自动生成的 include 中间。
2. PV 区域:放全局变量
位置:
/* USER CODE BEGIN PV */
/* USER CODE END PV */
PV 可以理解成 Private Variables。
适合放:
static uint32_t s_print_tick = 0;
static uint8_t s_led_mode = 0;
static App_Key s_key1;
static App_Key s_key2;
这些变量只给 main.c 自己用,不需要暴露给别的文件。
3. PFP 区域:放函数声明
位置:
/* USER CODE BEGIN PFP */
/* USER CODE END PFP */
PFP 可以理解成 Private Function Prototypes。
适合放:
static void PrintStatus(void);
static void HandleKeyEvents(void);
如果你在 main.c 底部写了一个 static 函数,而上面提前调用了它,就需要在这里声明。
4. USER CODE BEGIN 2:放初始化调用
位置一般在 main() 里,各种 MX_xxx_Init() 后面:
MX_GPIO_Init();
MX_USART1_UART_Init();
/* USER CODE BEGIN 2 */
App_LED_Init();
App_UART_Init();
printf("hello\r\n");
/* USER CODE END 2 */
这块非常常用。
你的应用层初始化,一般都放这里。
为什么要放在 MX_xxx_Init() 后面?
因为 CubeMX 生成的初始化函数要先把 GPIO、USART、TIM 等外设配置好,你自己的应用层代码才能使用这些外设。
5. USER CODE BEGIN WHILE / BEGIN 3:放主循环业务
CubeMX 生成的 while (1) 大概长这样:
while (1)
{
/* USER CODE END WHILE */
/* USER CODE BEGIN 3 */
/* USER CODE END 3 */
}
一般业务代码放在 USER CODE BEGIN 3 里:
/* USER CODE BEGIN 3 */
App_Key_Tick();
if (App_Timer_IsElapsed(&s_print_tick, 1000)) {
printf("running\r\n");
}
/* USER CODE END 3 */
你可能会问:为什么不是放在 USER CODE BEGIN WHILE?
两个位置都在循环里,但为了系列教程统一,我们默认把主循环业务放在 USER CODE BEGIN 3。这样后面看文章、查代码都不乱。
6. USER CODE BEGIN 4:放自定义函数
位置在 main.c 后半部分:
/* USER CODE BEGIN 4 */
/* USER CODE END 4 */
适合放:
static void PrintStatus(void)
{
printf("status\r\n");
}
void HAL_TIM_PeriodElapsedCallback(TIM_HandleTypeDef *htim)
{
App_Timer_OnPeriodElapsed(htim);
}
很多 HAL 回调函数也会放这里。
比如:
-
HAL_GPIO_EXTI_Callback() -
HAL_UART_RxCpltCallback() -
HAL_TIM_PeriodElapsedCallback() -
HAL_ADC_ConvCpltCallback()
但有个原则要记住:
回调函数可以放这里。
复杂业务不要全塞这里。
复杂业务最好封装到 app_xxx.c。
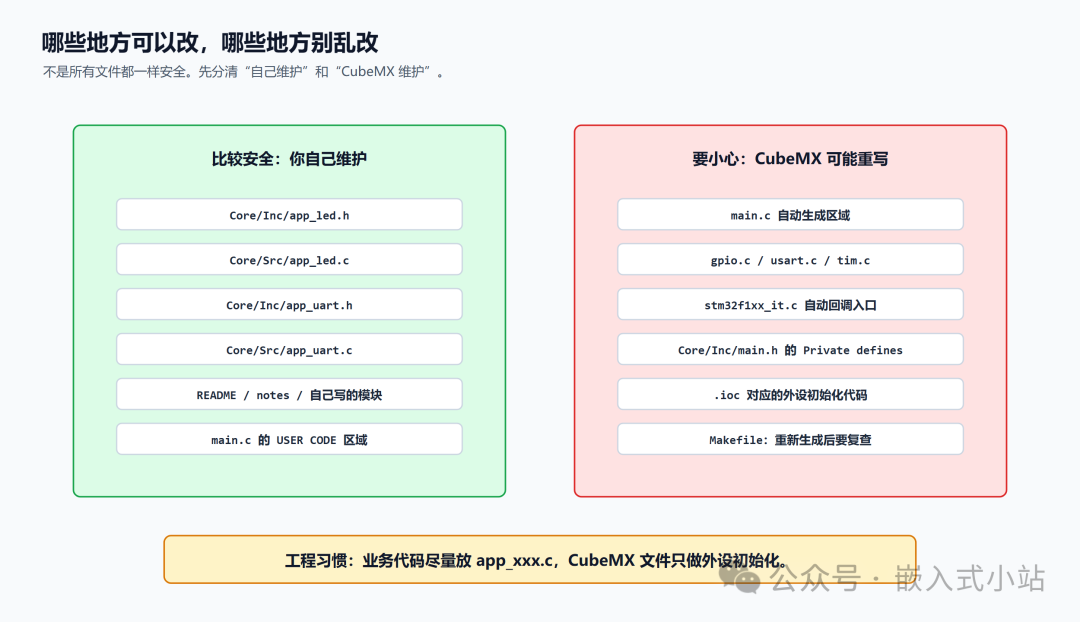
哪些地方可以改,哪些地方别乱改
先给一个最实用的表。
|
位置
|
能不能改
|
建议
|
| — | — | — |
| USER CODE BEGIN/END
中间
|
可以改
|
推荐写自己的代码
|
|
自己新建的 app_xxx.h/.c
|
可以改
|
最推荐放业务逻辑
|
| .ioc
文件
|
可以改
|
用 CubeMX 改,不建议手写
|
| main.c
自动生成区域
|
不建议改
|
可能被覆盖
|
| gpio.c/usart.c/tim.c
里的 MX_xxx_Init()
|
不建议手改
|
回 CubeMX 改配置
|
| main.h
自动生成的引脚宏
|
不建议手改
|
回 CubeMX 改 User Label
|
| stm32f1xx_it.c
中断入口
|
谨慎改
|
一般只让它调用 HAL IRQHandler
|
| Makefile |
可以改但要记得复查
|
加 .c 文件常要改,重新生成可能变化
|
最推荐的代码组织方式
我建议你以后都按这个方式写:
CubeMX 负责:
GPIO 初始化
USART 初始化
TIM 初始化
ADC/I2C/SPI/CAN 初始化
你自己负责:
app_led.c
app_key.c
app_uart.c
app_timer.c
app_xxx.c
main.c 负责:
include 你的 app 头文件
调用 app 初始化函数
在 while 里调度 app 任务
也就是:
CubeMX 文件:外设底层初始化
app_xxx 文件:你的业务封装
main.c:把模块串起来
这样做的好处是:
-
CubeMX 重新生成代码时,业务逻辑不容易丢;
-
换板子时,主要改 CubeMX 配置和少量宏;
-
main.c不会越写越乱; -
每个模块可以单独理解、单独排查。
比如串口项目里:
usart.c -> CubeMX 生成 USART1 初始化
app_uart.c -> 你写 printf 重定向、接收行缓冲
main.c -> 调用 App_UART_Init(),处理命令
不要把 app_uart.c 里的所有逻辑都塞进 main.c。
一开始看起来省事,后面一定会乱。
具体例子:include 应该放哪里
错误写法:
#include "main.h"
#include "app_uart.h" /* 随手插在自动生成 include 区域 */
推荐写法:
/* USER CODE BEGIN Includes */
#include "app_uart.h"
#include "app_led.h"
#include <stdio.h>
/* USER CODE END Includes */
为什么?
因为 CubeMX 知道这个区域是用户写的,会尽量保留。
具体例子:初始化调用应该放哪里
错误写法:
HAL_Init();
App_UART_Init(); /* 太早了,此时 USART 可能还没初始化 */
SystemClock_Config();
MX_GPIO_Init();
MX_USART1_UART_Init();
推荐写法:
HAL_Init();
SystemClock_Config();
MX_GPIO_Init();
MX_USART1_UART_Init();
/* USER CODE BEGIN 2 */
App_UART_Init();
printf("hello stm32\r\n");
/* USER CODE END 2 */
原则是:
先让 CubeMX 初始化硬件外设。
再让你的 app 模块使用这些外设。
具体例子:while 里应该怎么写
错误写法:
while (1)
{
HAL_Delay(1000);
printf("hello\r\n");
}
这段不一定会被 CubeMX 覆盖,但它的问题是:后面加按键、串口接收、定时任务时,HAL_Delay() 会让程序卡住。
更推荐写成:
/* USER CODE BEGIN PV */
static uint32_t s_print_tick = 0;
/* USER CODE END PV */
while (1)
{
/* USER CODE END WHILE */
/* USER CODE BEGIN 3 */
if (HAL_GetTick() - s_print_tick >= 1000) {
s_print_tick = HAL_GetTick();
printf("hello\r\n");
}
/* USER CODE END 3 */
}
这不是本篇重点,但你要提前习惯:
业务代码既要放对位置,也要尽量别阻塞主循环。
具体例子:回调函数应该放哪里
比如你要写串口接收完成回调:
void HAL_UART_RxCpltCallback(UART_HandleTypeDef *huart)
{
App_UART_OnRxCplt(huart);
}
推荐放在:
/* USER CODE BEGIN 4 */
void HAL_UART_RxCpltCallback(UART_HandleTypeDef *huart)
{
App_UART_OnRxCplt(huart);
}
/* USER CODE END 4 */
不要去改 stm32f1xx_it.c 里的:
void USART1_IRQHandler(void)
{
HAL_UART_IRQHandler(&huart1);
}
这类 IRQHandler 一般保持 CubeMX/HAL 生成的结构就行。HAL 会在合适的时候调用你的回调函数。
新手容易把中断入口和 HAL 回调混在一起。
你先记住:
xxx_IRQHandler:中断真正入口,通常在 stm32f1xx_it.c
HAL_xxx_Callback:HAL 分发后的用户回调,通常写在 USER CODE 区
为什么不建议直接改 MX_GPIO_Init
你可能会想:
CubeMX 生成的 GPIO 初始化不就是 C 代码吗?
我直接改不行吗?
短期看可以。
长期看不建议。
比如你在 MX_GPIO_Init() 里手动加了一段:
GPIO_InitStruct.Pin = GPIO_PIN_5;
GPIO_InitStruct.Mode = GPIO_MODE_OUTPUT_PP;
HAL_GPIO_Init(GPIOB, &GPIO_InitStruct);
后来你回 CubeMX 改了一个引脚,再点 Generate Code,这段手写配置就可能被重新整理甚至覆盖。
更好的做法是:
引脚模式、上下拉、复用功能:回 CubeMX 配
业务层开关、翻转、状态判断:写到 app_led.c
CubeMX 管“这个脚是什么功能”。
你的代码管“什么时候让它工作”。
什么时候可以改 Makefile
VSCode + Makefile 工程里,有一个地方比较特殊:Makefile。
如果你新建了:
Core/Src/app_uart.c
但没有加到 C_SOURCES,编译时可能会报:
undefined reference to `App_UART_Init'
这时候你需要把它加进去:
C_SOURCES = \
Core/Src/main.c \
Core/Src/gpio.c \
Core/Src/usart.c \
Core/Src/app_uart.c
所以 Makefile 是可以改的。
但要注意:
CubeMX 重新 Generate Code 后,Makefile 可能被更新。
每次生成后,都要复查自己加的 app_xxx.c 还在不在 C_SOURCES 里。
这也是为什么你每篇教程里都经常看到一句:
如果 undefined reference,先检查 app_xxx.c 有没有加入 Makefile。
每次重新生成代码前后,建议这样做
不要怕 CubeMX 重新生成代码。
真正稳的做法是建立流程。
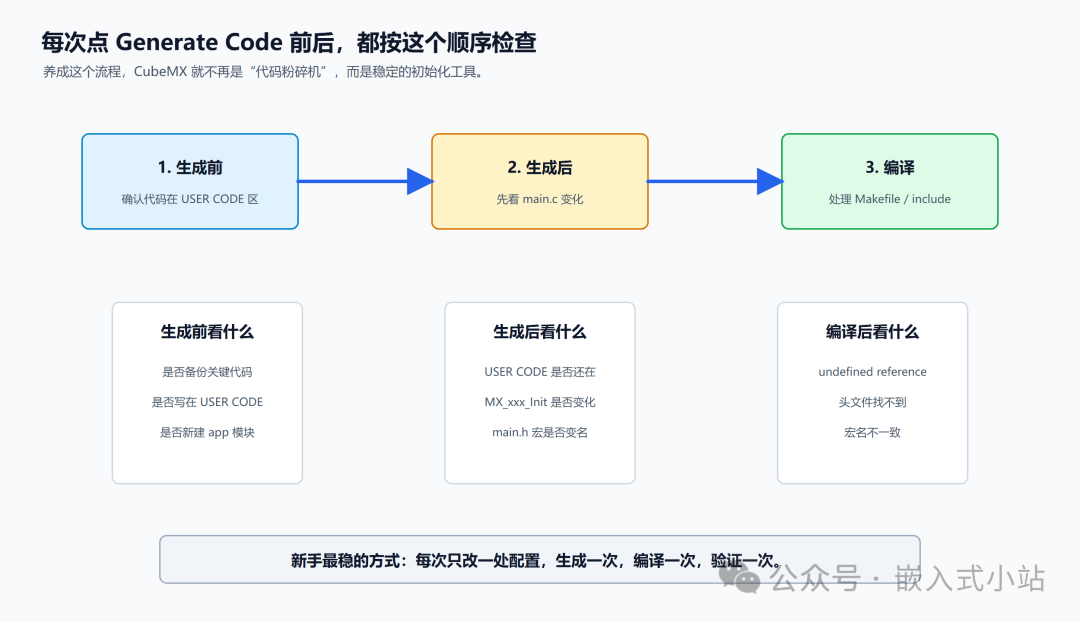
生成前
先看三件事:
-
你最近写的代码是不是都在
USER CODE区域; -
复杂逻辑是不是已经放到
app_xxx.c; -
Makefile 里有没有你手动加过的内容。
如果不放心,就先复制一份当前工程,或者用 Git 提交一下。
生成后
先别急着继续写。
先检查:
-
main.c的USER CODE内容还在不在; -
main.h里的引脚宏有没有改名; -
MX_xxx_Init()有没有因为 CubeMX 配置变化而改变; -
Makefile 里的
app_xxx.c是否还在; -
编译有没有新错误。
编译后
常见错误按这个思路看:
|
错误
|
常见原因
|
| — | — |
| undefined reference to App_xxx | .c
文件没加入 Makefile
|
| app_xxx.h: No such file or directory |
头文件路径或文件位置不对
|
| LED_Pin undeclared |
CubeMX 的 User Label 改了,宏名变了
|
| huart1 undeclared |
USART1 没启用,或句柄名不是 huart1
|
|
程序能编译但没现象
|
初始化调用顺序不对,或外设没启动
|
一个适合新手的写代码流程
以后你新加一个功能,可以按这个顺序:
这个流程看起来慢,但非常稳。
新手最怕的是同时改太多地方:
CubeMX 配了外设
main.c 改了一堆
Makefile 改了一堆
app_xxx.c 也新建了
然后一编译 20 个错误
一旦这样,你就不知道是哪一步弄错了。
所以要养成:
每次只改一小步。
改完就编译。
常见问题排查
1. CubeMX 重新生成后,我写的代码没了
优先检查:
-
代码是不是写在
USER CODE BEGIN/END外面; -
是不是直接改了
MX_xxx_Init(); -
是不是把代码写进了 CubeMX 自动维护的区域。
补救方法:
-
如果有备份或 Git,先找回;
-
没有备份,只能重新写;
-
重新写时放到正确的 USER CODE 区域或
app_xxx.c。
2. 我写在 USER CODE 里了,为什么还是不见了
常见原因:
-
不小心删掉了
USER CODE BEGIN/END标记; -
自己改了标记名字,比如
USER CODE BEGIN Includes改成别的; -
手动复制代码时破坏了结构;
-
CubeMX 版本或工程文件异常。
正常情况下,不要改这两行标记本身。
你可以改中间内容,但别改边界。
3. app_xxx.c 没丢,但编译说找不到函数
大概率是 .c 文件没有加入 Makefile。
检查:
C_SOURCES
确认里面有:
Core/Src/app_xxx.c
4. 头文件找不到
比如:
fatal error: app_uart.h: No such file or directory
先确认文件是不是放在:
Core/Inc/app_uart.h
再确认 Makefile 里 C_INCLUDES 是否包含:
-ICore/Inc
一般 CubeMX 生成的 Makefile 默认会有 Core/Inc,所以大多数时候是文件放错目录或文件名拼错。
5. 引脚宏名不对
比如代码里写:
LED_Pin
LED_GPIO_Port
但 main.h 里实际是:
LED_Red_Pin
LED_Red_GPIO_Port
这说明 CubeMX 的 User Label 和你的代码不一致。
解决方法有两个:
-
回 CubeMX 把 User Label 改成代码期望的名字;
-
或者改代码里的宏名。
系列教程更推荐第一种:User Label 统一,应用层代码少改。
本篇小结
这一篇你要记住几句话:
CubeMX 生成框架,不负责保护你乱写的位置。
自己的代码尽量写进 USER CODE 区域。
复杂业务尽量放到 app_xxx.h / app_xxx.c。
外设初始化回 CubeMX 改,业务逻辑在 app 层写。
重新 Generate Code 后,先编译,先检查 Makefile 和宏名。
如果你刚开始学 STM32,不要急着完全摆脱 CubeMX。
你先做到:
CubeMX 负责底层初始化。
我负责 app 层业务代码。
main.c 只做模块连接和任务调度。
这一步做好了,后面不管继续学 USART、TIM、PWM、ADC,还是以后做 Bootloader、RTOS,工程都会稳很多。
下一篇可以写什么
下一篇我建议继续拆已有工程,不急着开新外设:
printf 为什么会跑到 fputc?
这也是新手很容易“会用但不理解”的地方。把它讲清楚,你对 USART 打印这条链路就会扎实很多。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 7
7 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)