02-架构篇-前端怎么反客为主把AI编排权拿回到自己手里
前端怎么"反客为主":把 AI 编排权拿回到自己手里
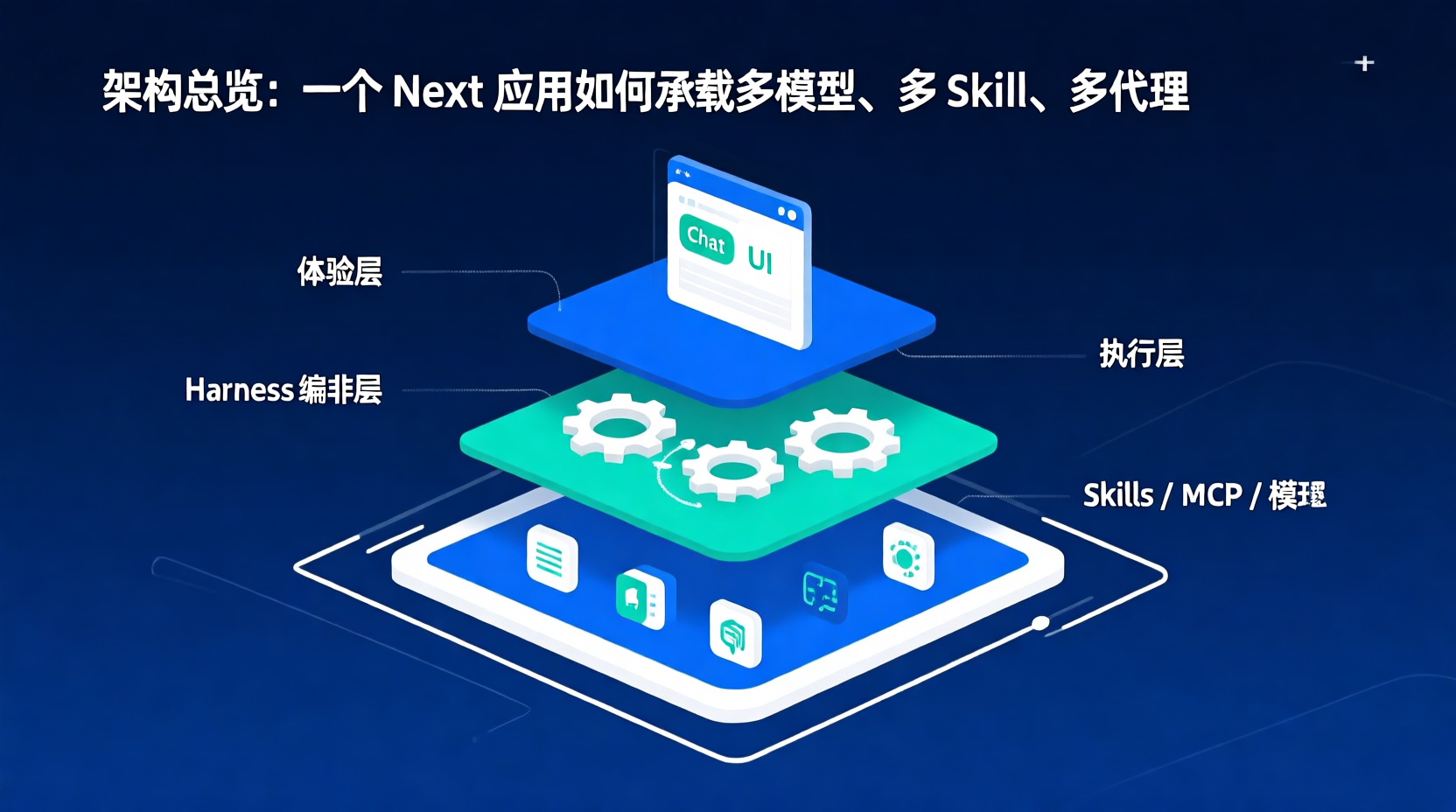
副标题:三层分层 + Harness + Skills + Vault + 写保护——把"轻辔"项目的架构完整摊开,看看一个前端工程能在 AI-Native 工具里掌控到什么程度。
一、一个让我难受了半年的问题
上一篇我们从设计哲学谈起,这一篇直接进架构。
先抛一个问题:
如果模型供应商明天涨价 10 倍,我换得了吗?如果今天用 OpenAI 明天换 Claude 后天换 DeepSeek,我的代码要改多少?
第一次问出来的时候我心虚了——当时我们的代码里,"调 OpenAI"这件事散落在十几个文件,业务逻辑、prompt 拼接、tool 注册、流式解析全缠在一起。
轻辔重做之后的答案是:两小时换完一家。
这个答案不是吹出来的,是设计出来的。下面把它拆开。
二、三层分层:不是新鲜词,但 AI 产品里 90% 没做对
先给一张图,这就是轻辔的真实分层(简化版):
┌─────────────────────────────────────────┐
│ 体验层 Experience (src/app, features/chat/ui)
│ - Chat UI / 设置抽屉 / 任务简报面板
│ - 只组合,不写编排规则
└─────────────────────────────────────────┘
↓
┌─────────────────────────────────────────┐
│ 编排层 Harness (src/lib/harness, lib/chat)
│ - buildHarnessPlan(text) → 调度表
│ - task-flow / capability-routing / subagent-hint
│ - 不直接调模型
└─────────────────────────────────────────┘
↓
┌─────────────────────────────────────────┐
│ 执行层 Execution (src/lib/ai, features/chat/server, features/skills)
│ - providers: anthropic / deepseek / openai / cursor
│ - streamText + tools / Cursor Agent SDK
│ - Skills(generate_image / video / coding / ...)
│ - 写保护 + 路径白名单
└─────────────────────────────────────────┘
依赖方向严格单向:app → features → lib → config,lib 不准 import features。这是前端做了二十年的分层,在 AI-Native 里意外地重要——模型是流动的,业务是稳定的,稳定的东西必须放在底层。
每一层在 AI-Native 里有它独特的语义:
体验层 = 你熟悉的前端src/app/、src/features/chat/ui/。它甚至不应该知道"这一轮是 GCCD 还是闲聊",它只把 metadata 翻译成视觉,把视觉翻译成事件。
编排层 = AI-Native 的"路由器"src/lib/harness/ 和 src/lib/chat/。它做四件事:这一轮走哪种任务流?挂哪些工具?要不要叫子代理?system prompt 怎么拼?这层完全不调模型,只产出"计划"。
执行层 = 跟具体厂商打交道的脏活src/lib/ai/providers/ 下是 Anthropic、DeepSeek、OpenAI 的实现;src/features/chat/server/stream-chat-cursor.ts 是 Cursor Agent 路径。各家 API 长得不一样、能力不一样、限流策略不一样。但只要这一层守好了,编排层和体验层永远不需要知道你今天用的是哪家。
三、Harness 是什么?用前端的话说就是"中间件 + 路由器"
很多人听到 Harness、Agent、Orchestration 就头大。其实没那么玄。
Harness 大概等于:Express 的中间件链 + React Router 的路由匹配 + Redux 的 reducer。
每一轮对话,Harness 干这几件事(伪代码,但接近真实形态):
// src/lib/harness/plan-core.ts
export function buildHarnessPlanCore(
routingText: string,
env: HarnessPlanEnv = DEFAULT_HARNESS_PLAN_ENV,
): HarnessPlan {
const raw = classifyTaskFlow(text); // ← 任务分流(none/gccd/chain)
const mode = resolveHarnessTaskFlowMode(raw, env);
const capability = getCapabilityIntent(text); // ← 能力路由(image/video/coding/...)
const subagent = resolveSubagentHint(core); // ← 子代理建议(explore/code-reviewer)
return { taskFlow, capability, subagent, ... };
}
这个 plan 本身不调任何模型——它就是一份纯函数算出来的"调度表",80% 是关键词正则,20% 留给模型兜底(很短的 prompt,只让它 yes/no)。
好处显而易见:
- 95% 的请求,在路由阶段就分流了,不浪费 token
- 路由逻辑是纯函数,可以单元测试,可以快照回归
- 改路由规则不用动模型代码,反之亦然
我们项目有个命令叫 pnpm harness:eval,跑一遍 Harness 规则的回归——完全不调模型,纯逻辑测试,几秒跑完几百个 case,用例就放在 src/lib/harness/eval/cases.ts。这是前端工程师才会想到的事:把 AI 编排测得像测纯函数一样。
OpenAI / DeepSeek 路径走 streamText + tools(Vercel AI SDK 6),Cursor 路径走 @cursor/sdk 的 Agent 流——两条路径共用同一个 plan。这就是分层的红利:换执行,不动编排。
四、Skills:把"能力"做成 npm 包的样子
Skills 是项目里我个人最喜欢的设计,因为它把"AI 工具"这个抽象概念,做成了前端工程师最熟悉的形态——插件。
每个 Skill 长这样:
features/skills/<id>/
├── SKILL.md # 元数据(用 frontmatter 写 routing_hint / keywords / auto_route)
├── skill.ts # 实现(注册到 catalog)
└── (可选)evals/ # 该 Skill 的回归用例
举一个真实的 SKILL.md 头(generate_video):
---
id: generate_video
description: 统一生视频:文生视频 / 图生视频(硅基流动 Wan 系列)。
routing_hint: 用户明确要生成、制作视频/短片/动画片段...DeepSeek/OpenAI 必须调用 generate_video_create。
auto_route: keywords
keywords: 生成视频, 制作视频, 文生视频, 图生视频, 视频生成, AI视频, ...
---
和写一个 npm 包没区别。SKILL.md 就是 package.json + README,skill.ts 是 index.ts,src/features/skills/catalog.ts 是 node_modules(注册表)。
目前 catalog 里 19 个 Skill,从 coding / host_workspace / quick_dev 这种重型工作区能力,到 generate_image / generate_video / agent_browser 这种媒体能力,到 desktop_control / desktop_messenger / reminder 这种本机能力,到 self_update / skill_evolve 这种自我演化能力。
这种设计带来的好处比想象的大:
1. 按需挂载
聊到"画一只猫",才把 generate_image 的 SKILL.md 内容加载到 system prompt 里。其他 18 个 Skill 一行字都不进上下文。这是 code-splitting 在 system prompt 这个新"包"上的复刻。
2. 关键词自路由
看 auto_route: keywords 那行——SKILL.md 自己声明命中规则,前端规则引擎(src/features/skills/keyword-routing.ts)读它就行,模型不参与决策。pnpm harness:eval 同时回归这部分。
3. 独立测试
每个 Skill 是个文件夹,有自己的输入输出契约,可以单测。quick_dev/evals/ 就是 Skill 自带的回归集。
4. 第三方扩展
Skill 协议定下来,不仅团队内可以加,理论上社区也可以加。这是不是和 VSCode 插件、和 webpack loader 一个味儿?是的,前端十几年沉淀出来的"开放封闭原则"在 AI 时代会重演一遍。
5. 权限隔离
某个 Skill(比如 self_update、host_workspace)风险高?走 env 门禁(CHAT_SKILL_IDS、CHAT_SKILL_AUTO_ROUTER),默认关闭。这思路前端做权限路由用过一万次。
五、状态:放在该放的地方
AI 产品里"状态"比传统前端复杂得多。轻辔的拆分是这样的:
| 状态 | 该放哪 | 前端类比 |
|---|---|---|
| 当前对话流 | React state + SSE 流 | 临时 UI 状态 |
| 历史会话 | 本地加密 Vault(~/.local/share/ai-native-studio) |
LocalStorage 升级版 |
| 会话索引 | dexie(IndexedDB) |
老熟人 |
| 用户偏好 | LocalStorage + 服务端摘要(规划) | 老熟人 |
| 模型上下文窗口 | 服务端组装(Harness 决定),前端不碰 | 等同 SSR 状态 |
| 工具调用结果 | UIMessage 的 parts | 类似 Redux 的 entities |
我想强调的两条线,都是前端味道极重的设计:
第一条:Vault 是文件系统,不是数据库src/lib/local-vault/paths.ts 里这段代码:
export function defaultExternalDataRoot(): string {
return path.join(os.homedir(), ".local", "share", "ai-native-studio");
}
会话历史落在用户家目录下的一个加密 Vault 里,默认不上云。前端启动时本地秒读,需要换设备再用同步。这件事完全可以前端主导——你不需要等后端给你设计跨设备方案,你先把本地体验做满了再说。
为什么?因为 AI 产品的体验瓶颈八成在"等"。用户每等一秒都想知道:之前说过什么、上一轮代码贴在哪、上次输出去哪了。如果这些都要去后端拉,你就输了。
第二条:dexie 做索引,文件做存储
长会话内容大,放 IndexedDB 会爆 quota;放后端会慢。轻辔的做法是:dexie 只存索引(session id、title、最近一条预览、时间戳),正文写到加密文件。打开应用先列索引,点开某个会话才解密读正文。
这跟前端做"图片懒加载 + 缩略图"的策略一模一样,只是对象换成了对话。
六、写保护:把"AI 改文件"这件事关进笼子
讲到这里就要碰一个不少 AI 产品翻车的话题:模型乱写文件。
只要你的 AI 工具有写文件能力,模型一定会有失误的时刻——它会试图把代码写到 node_modules、写到 .next、写到一个不存在的路径、写一个 800KB 的"完整重构版本"覆盖你 80 行的工具函数。
轻辔的回答叫 src/lib/workspace/write-guard.ts,核心两个机制:
1. 字节上限
export const MAX_WRITE_BYTES = 800_000;
模型一次最多写 800KB。超出就 reject。这一条挡掉的事故占了我们半年里写文件类问题的 60%——大模型有时候会突发奇想"我把整个项目重写给你看"。
2. 路径白名单 + 黑名单src/lib/workspace/paths.ts 维护"允许写入的根目录"列表,同时 BLOCKED_RELATIVE_PATTERNS 把 .next/、node_modules/、.local/、.self-update/ 这些运行时路径全拉黑。模型递交一个 patch,Guard 先扫一遍路径,任何一条命中黑名单就整个 reject 掉。
3. 占位符检测
模型最爱的"伪代码"如 // ... rest of the code // 省略,Guard 会扫一遍写入内容,带占位符的拒收。
这套机制在 host_workspace skill 里强制走、在 self_update 流程里强制走。它的代码量不到 200 行,但它是轻辔敢让模型直接动你仓库的底气。
这件事跟前端做 XSS 净化、CSRF 防护、URL 白名单是完全一样的洁癖。前端工程师对"输入永远不可信"这件事的本能,在 AI 产品里直接变成核心竞争力。
七、可替换性:不绑模型,不绑供应商,不绑 SDK
回到开篇那个问题:模型涨价 10 倍我换得了吗?
轻辔的设计里有几个前端味儿很冲的设计支撑了"两小时换一家":
1. 一份统一的 LanguageModel 抽象
不管是 Anthropic、DeepSeek、OpenAI,在执行层之上看到的都是 Vercel AI SDK 6 的 LanguageModel 接口。新接一家,实现一个 src/lib/ai/providers/<id>.ts 就完事。
src/lib/ai/providers/
├── anthropic.ts # @ai-sdk/anthropic
├── deepseek.ts # @ai-sdk/deepseek
└── openai.ts # @ai-sdk/openai
Cursor 因为是 Agent SDK,走独立路径 src/features/chat/server/stream-chat-cursor.ts,但对前端透明。
2. 流式协议归一化
每家厂商的 SSE 格式、tool_use 协议、reasoning 字段都不一样。我们在执行层把这些统一翻译成同一种 UIMessage 格式喂给前端。前端永远只渲染一种数据结构。
3. system prompt 与代码解耦
prompt 是配置不是代码。CHAT_SYSTEM_PROMPT 这种 env 直接覆盖默认 prompt,换模型经常需要换 prompt 风格,这件事不该让你改代码部署。
4. 能力发现走配置GET /api/chat/config 这个接口,前端启动时拉一次,知道"今天哪些能力是就绪的、哪些没配 key"。前端按这份配置渲染 UI 标签——“生图就绪”/“生视频未配置”/“自我更新已禁用”。换供应商?改 env、重启,前端自动适配。
这套东西是不是有点像 Webpack 的 loader 体系、Vue 的 plugin 机制、Next.js 的 App Router?是的,前端这二十年最大的成就之一,就是发明了一整套"如何让东西可替换"的方法论。AI-Native 工具最缺的就是这套方法论。
八、最难的事:“边界”
讲到最后,架构最难的事不是分好层,而是画好边界。
前端和后端的合作,在 AI 产品里很容易出现错位:后端觉得"调模型是我的事",前端觉得"渲染是我的事",中间那一大块"编排"成了无主之地。
我的建议是,前端要主动把编排层抢过来。
理由有三:
- 编排层离用户最近——每个调度决定都变成用户感知(等待、视觉、错误恢复)。这些事后端没那么敏感。
- 编排层是 TS 友好的——现代前端工具链跑 TS、跑测试、跑 lint,都比后端快。轻辔的
pnpm harness:eval几秒跑完,这种节奏后端服务很难做到。 - 编排层迭代频繁——AI 产品每周都有新规则、新意图、新模式。前端的发布节奏适合这种迭代。
这不是"什么都前端做"。模型 API 调用、密钥管理、写文件、调命令行——这些必须服务端。但计划生成、意图分类、能力路由、UI 渲染、状态管理——这些前端工程师完全可以拿下。
下一篇,我会进入最实操的部分:调试和优化——AI 产品到底怎么调?怎么知道哪里慢?怎么选模型?怎么不让账单爆炸?会用轻辔里几个具体的命令(pnpm harness:eval、pnpm dev:mem、/api/chat/config)做样本,把整个工程闭环讲透。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 1
1 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)