AI Infra 硬件体系与编程模型:16. CUDA编程基础:Warp级协作的矩阵运算
深入CUDA Tensor Core与WMMA:从基础原理到高性能混合精度矩阵乘实战
在CUDA性能优化的进阶路径上,Tensor Core是一道必须跨越的门槛。从深度学习大模型到高性能科学计算,现代GPU绝大多数的算力增长都来自Tensor Core——它能将矩阵运算的吞吐量提升一个数量级,是当前GPU性能红利的核心来源。
很多开发者对Tensor Core的认知停留在“AI专用硬件”,觉得它只能通过cuBLAS、cuDNN等黑盒库调用。实际上,CUDA提供了WMMA(Warp Matrix Multiply Accumulate)原生API,让我们可以在自定义核函数中直接操控Tensor Core,实现各类定制化的混合精度矩阵运算。
本文将从硬件原理出发,系统讲解Tensor Core的工作机制、WMMA编程模型与核心API,并通过递进式优化,带你实现一个高性能的混合精度矩阵乘法,彻底搞懂Tensor Core的编程方法论。
一、为什么要掌握Tensor Core与WMMA?
在正式开始之前,我们先明确一个核心认知:现代GPU的算力主体已经从CUDA Core转向了Tensor Core。
以NVIDIA A100 GPU为例:
- CUDA Core的FP32峰值算力:19.5 TFLOPS
- Tensor Core的FP16峰值算力:312 TFLOPS
两者相差16倍。如果你的程序中矩阵运算占比很高,却没有调用Tensor Core,就相当于浪费了GPU 90%以上的算力。
对于开发者而言,掌握WMMA的价值在于:
- 突破库的限制:当cuBLAS等标准库无法满足定制化需求(如融合算子、特殊数据布局、自定义数值逻辑)时,可以手动调用Tensor Core
- 理解性能本质:搞懂Tensor Core的工作原理,才能真正理解高性能库的性能边界,做出合理的技术选型
- 掌握混合精度:WMMA是混合精度计算的最佳实践载体,能帮你深入理解精度与性能的权衡
二、Tensor Core核心原理:专用硬件的矩阵加速引擎
2.1 Tensor Core是什么?
Tensor Core是NVIDIA从Volta架构(V100)开始引入的专用硬件加速单元,它和CUDA Core同属SM(流式多处理器),但定位完全不同:
- CUDA Core:通用标量计算单元,支持任意算术、逻辑、分支指令,灵活性高,但单单元算力低
- Tensor Core:专用矩阵运算单元,只能执行固定的矩阵乘累加运算,灵活性低,但单单元吞吐量极高
打个通俗的比方:CUDA Core是通用螺丝刀,什么螺丝都能拧,但拧大螺丝效率低;Tensor Core是专用电动扳手,只能拧特定规格的螺丝,但速度快几十倍。
2.2 核心运算:融合矩阵乘累加(MMA)
Tensor Core只做一件事,并且做到了极致:融合矩阵乘累加(Matrix Multiply-Accumulate, MMA),数学表达式为:
D=A×B+C D = A \times B + C D=A×B+C
其中:
- A、B为输入矩阵,通常为低精度(FP16/BF16/TF32/INT8)
- C为累加矩阵,通常为高精度(FP32)
- D为输出矩阵,与C精度一致
注意这是融合运算:乘法和加法在硬件中一次性完成,没有中间结果的读写开销,这也是它性能极高的核心原因之一。
2.3 精度与架构支持
不同代架构的Tensor Core支持的精度和运算能力持续演进:
| 架构 | 计算能力 | 支持精度 | 典型WMMA尺寸 |
|---|---|---|---|
| Volta | sm_70 | FP16 | 16×16×16 |
| Turing | sm_75 | FP16、INT8/INT4 | 16×16×16、8×8×16 |
| Ampere | sm_80/sm_86 | FP16、BF16、TF32、INT8 | 16×16×16、32×8×16、8×32×16 |
| Hopper | sm_90 | FP16、BF16、TF32、FP8、INT8 | 多尺寸支持 |
| Blackwell | sm_100 | FP16、BF16、TF32、FP8、INT4 | 多尺寸支持 |
其中 16×16×16(M×N×K) 是所有支持Tensor Core的架构都兼容的基础尺寸,也是入门学习的最佳选择。
三、WMMA编程模型:Warp级协作的矩阵运算
Tensor Core不是给单个线程用的,它采用Warp级协作的执行模型,这是WMMA编程最反直觉、也最核心的设计。
3.1 Warp级协作机制
我们知道,GPU以warp(32个线程)为基本执行单元。Tensor Core的运算由一整个warp的32个线程协同完成:
- 一个16×16的矩阵块,被拆分后分布在32个线程的寄存器中
- 每个线程只持有矩阵块的一小部分元素
- 对于 A 或 B 矩阵(输入):每个线程持有 8 个元素。(FP16)
- 对于 C 或 D 矩阵(累加器/结果):每个线程持有 8 个元素。(FP32)
- 调用WMMA指令时,32个线程同步触发Tensor Core硬件,共同完成一次完整的矩阵乘累加
关键结论:WMMA是warp级原语,必须由整个warp的线程同步调用,参数完全一致。单个线程无法独立调用Tensor Core,也无法访问其他线程持有的矩阵元素。
3.2 核心数据结构:Fragment(矩阵片段)
WMMA引入了fragment(片段)的概念,它是存储在线程寄存器中的小矩阵块,是Tensor Core运算的基本操作数。
wmma::fragment 是一个轻量级的 C++ 类型标记(type tag),它告诉编译器和硬件:每个线程应该如何在其私有寄存器中存储和解释矩阵数据,以便 Tensor Core 能够正确读取。
它不是一个容器(不是 std::vector 或数组),不分配额外的内存,不存储布局信息。它本质上是一个编译时元数据,附在一组寄存器上。
fragment有三种类型,对应MMA运算的三个操作数:
matrix_a:左乘矩阵A的片段,低精度输入matrix_b:右乘矩阵B的片段,低精度输入accumulator:累加矩阵C/D的片段,高精度累加
在计算下图的中D的一个16*16 block 时,wmma调用次数 = K/16。
每次调用 wmma 计算每个 fragment时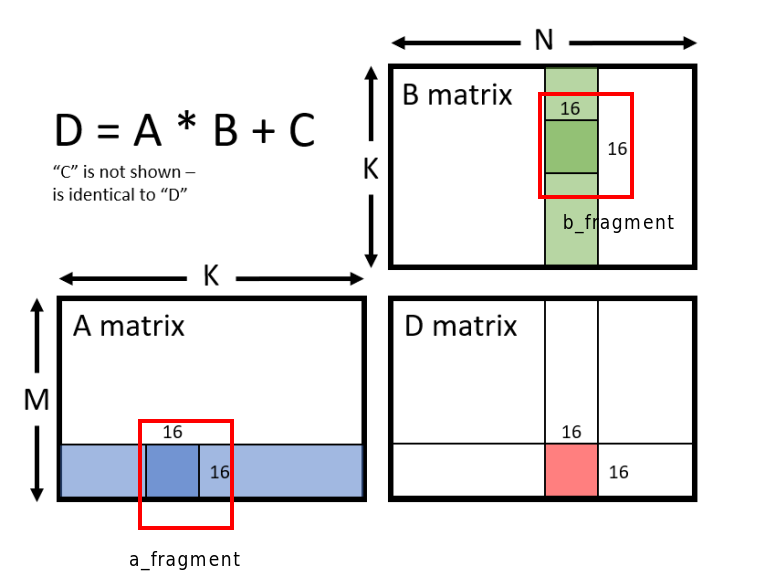
fragment是C++模板类型,完整声明如下:
template <typename Use, int m, int n, int k, typename T, typename Layout = void>
class fragment;
模板参数说明:
-
Use:片段类型,取值为matrix_a/matrix_b/accumulator -
m, n, k:矩阵块的维度,对应WMMA的尺寸,最常用16, 16, 16 -
T:元素数据类型,如half(FP16)、bfloat16_t(BF16)、float(FP32) -
Layout:内存布局,取值row_major(行主序)或col_major(列主序)
行主序(Row-Major)和列主序(Column-Major)是线性内存中存储多维数组(如矩阵)的两种不同逻辑顺序。由于计算机内存是一维线性的,而矩阵是多维的,这两种方式决定了如何将多维索引映射到一维地址。-
行主序 (Row-Major)
- 定义:先存储第一行的所有元素,接着存储第二行的所有元素,依此类推。同一行的元素在内存中是连续的。
- 适用语言/库:C/C++、Python (NumPy 默认)、Go、Swift。
- 示例:对于 2×32 \times 32×3 矩阵 [123456]\begin{bmatrix} 1 & 2 & 3 \\ 4 & 5 & 6 \end{bmatrix}[142536],内存中的排列顺序为:
1, 2, 3, 4, 5, 6。 - 地址计算公式:若矩阵大小为 M×NM \times NM×N,元素 A[i][j]A[i][j]A[i][j] 的地址偏移量为 i×N+ji \times N + ji×N+j 。
-
列主序 (Column-Major)
- 定义:先存储第一列的所有元素,接着存储第二列的所有元素,依此类推。同一列的元素在内存中是连续的。
- 适用语言/库:Fortran、MATLAB、R、Julia、LAPACK/BLAS 库、cuBLAS。
- 示例:同样的 2×32 \times 32×3 矩阵,内存中的排列顺序为:
1, 4, 2, 5, 3, 6。 - 地址计算公式:若矩阵大小为 M×NM \times NM×N,元素 A[i][j]A[i][j]A[i][j] 的地址偏移量为 j×M+ij \times M + ij×M+i 。
-
示例声明:
#include <mma.h>
using namespace nvcuda::wmma;
// 行主序FP16的A矩阵片段
fragment<matrix_a, 16, 16, 16, half, row_major> a_frag;
// 列主序FP16的B矩阵片段
fragment<matrix_b, 16, 16, 16, half, col_major> b_frag;
// FP32精度的累加器片段
fragment<accumulator, 16, 16, 16, float> c_frag;
3.3 关于Fragment的重要注意事项
- 分布式存储:整个fragment的数据分布在warp内32个线程的寄存器中,单个线程只能访问自己持有的部分元素,无法遍历整个矩阵块
- 不支持随机访问:不能像普通数组那样通过下标随意访问fragment内的元素,只能通过官方API进行加载、运算和存储
- 寄存器占用:fragment会占用大量寄存器,使用时需要注意寄存器压力,避免溢出到本地内存
3.4 WMMA 的执行机制
当每次调用WMMA进行计算时,问题就变成了两个 16*16 的矩阵相乘。
虽然上面的讨论中我们一直在说“调用一次 wmma”,但在硬件层面,一次 wmma::mma_sync 的调用是由一个 Warp(32个线程)共同协作完成的,而不是单个线程完成的。
WMMA 的设计哲学是:将矩阵乘法(MMA)(16*16)操作外包给硬件单元(Tensor Core),但数据和指令需要由线程束(Warp)来调度。
1. 准备工作:Fragment 的“隐藏”分布
你看到的 a_frag, b_frag, d_frag 虽然是代码里的变量,但在物理上,它们并不是存储在一个线程的寄存器里的完整 16x16 矩阵。
实际上,这 16x16 的数据被打散存储在该 Warp 的所有 32 个线程的寄存器中。
- 持有方式:Warp 中的每个线程只持有这 16x16 矩阵的一小部分(例如 4 个 float/element)。
- 举例:一个 16x16 的矩阵总共有 256 个元素。这 256 个元素由 32 个线程共同“持有”,大约平均每个线程持有 8 个元素。具体的布局(Layout)取决于 WMMA 策略(如
row_major等,但通常内部有自己的优化排列)。
2. 关键指令:wmma::mma_sync
当你调用 wmma::mma_sync 时,编译器会生成一条特殊的 PTX 指令(并行线程执行指令):
mma.sync.aligned.shape.cta.sem // 类似于这样的伪代码,实际更复杂
这条指令的神奇之处在于:
- Warp 同步:它强制 Warp 内的所有线程同步(不是线程块同步)。只有当一个 Warp 里的 32 个线程都准备好数据(都在自己的寄存器片段里)时,这个指令才会被激活。
- 广播到硬件单元:Warp 的 32 个线程会共同向 Tensor Core 发送请求。Tensor Core 是专门为低精度矩阵乘法设计的硬件电路。
- 物理计算:Tensor Core 接收这 32 个线程提供的、分散在寄存器中的数据,在硬件内部将它们重组成 16x16x16 的矩阵,并进行矩阵乘法((A \times B))。
- 结果回写:计算完成后,Tensor Core 将结果(16x16 矩阵)拆解回 32 个线程的寄存器中,完成累加。
核心要点总结
- 不是单线程执行:
wmma::mma_sync是 Warp-level 指令,Warp 内所有 32 个线程必须同时到达该指令。 - Tensor Core 是引擎:它利用的是 GPU 上专门的矩阵运算硬件,而不是普通的 ALU(算术逻辑单元)。
- 16x16x16 是硬件尺寸:这个尺寸是硬件优化的最小单位。每次调用都会让硬件进行一次完整的 16x16x16 乘法运算。
- Fragment 是视角:在代码里你看到的是
fragment(片段),但在硬件层面这是 warp 寄存器的协同。
四、WMMA API全解析:四个函数玩转Tensor Core
WMMA API非常精简,核心只有四个函数,覆盖了矩阵运算的全流程。所有函数都定义在nvcuda::wmma命名空间中,需要包含头文件<mma.h>。
4.1 fill_fragment:常量填充
template <typename Use, int m, int n, int k, typename T, typename Layout>
void fill_fragment(fragment<Use, m, n, k, T, Layout>& frag, const T& value);
- 功能:用一个常量值填充整个fragment
- 典型用途:初始化累加器为0,是矩阵乘运算的必备步骤
- 示例:
fragment<accumulator, 16, 16, 16, float> acc; fill_fragment(acc, 0.0f); // 累加器初始化为0
4.2 load_matrix_sync:从内存加载到寄存器
template <typename Use, int m, int n, int k, typename T, typename Layout>
void load_matrix_sync(fragment<Use, m, n, k, T, Layout>& frag,
const T* ptr,
int ldm);
void load_matrix_sync(fragment<...> &frag, const T* ptr, unsigned ldm, layout_t layout);
- 功能:从全局内存或共享内存中加载矩阵块到fragment
- 参数说明:
frag:目标fragmentptr:源内存地址,指向矩阵块的左上角元素ldm:Leading Dimension,即矩阵的“领先维度” 。指相邻两行(行主序)或两列(列主序)之间的元素个数跨度。ldm 乘以元素大小必须是 16字节的倍数(例如 __half 类型需为 8 的倍数,float 类型需为 4 的倍数)- 行主序下:表示矩阵一行有多少个元素
- 列主序下:表示矩阵一列有多少个元素
layout:仅当 frag 是累加器 accumulator 时才需要显式指定。对于 matrix_a 或 matrix_b,布局从 fragment 的定义中推断
- 关键要求:必须整个warp同步调用,所有线程传入的参数一致
4.3 mma_sync:触发Tensor Core运算
template <int m, int n, int k, typename T, typename LayoutA, typename LayoutB>
void mma_sync(fragment<accumulator, m, n, k, float>& d,
const fragment<matrix_a, m, n, k, T, LayoutA>& a,
const fragment<matrix_b, m, n, k, T, LayoutB>& b,
const fragment<accumulator, m, n, k, float>& c);
- 功能:执行融合乘加运算
d = a * b + c,这是真正调用Tensor Core硬件的函数 - 混合精度特性:输入a、b为低精度(如FP16),累加c和输出d为高精度(FP32),完美契合混合精度范式
- 注意:该运算会覆盖d的值,若要实现累加,可将c和d传入同一个fragment
4.4 store_matrix_sync:将结果写回内存
template <typename Use, int m, int n, int k, typename T, typename Layout>
void store_matrix_sync(T* ptr,
const fragment<Use, m, n, k, T, Layout>& frag,
int ldm,
Layout);
- 功能:将fragment中的结果写回全局内存或共享内存
- 参数含义与
load_matrix_sync一致,最后一个参数显式指定内存布局
五、混合精度矩阵乘的递进式优化之路
掌握了基础API,我们从最简版本开始,一步步优化出高性能的混合精度矩阵乘法。优化思路和普通矩阵乘一脉相承,但结合了Tensor Core的特性。
我们的目标:实现 C = A * B,其中A为M×K的FP16行主序矩阵,B为K×N的FP16列主序矩阵,C为M×N的FP32行主序矩阵。
5.1 版本1:基础WMMA版(全局内存直接访问)
这是最朴素的实现:每个warp负责计算输出矩阵C的一个16×16块,循环加载A和B的对应块,逐次累加。
__global__ void wmma_v1(const half* __restrict__ A,
const half* __restrict__ B,
float* __restrict__ C,
int M, int N, int K)
{
// 每个warp计算一个16x16的C块
int warp_row = blockIdx.y;
int warp_col = blockIdx.x;
// 初始化累加器为0
fragment<accumulator, 16, 16, 16, float> acc;
fill_fragment(acc, 0.0f);
// 沿K维度遍历所有16x16块
for (int k = 0; k < K; k += 16) {
fragment<matrix_a, 16, 16, 16, half, row_major> a_frag;
fragment<matrix_b, 16, 16, 16, half, col_major> b_frag;
// 从全局内存加载A和B的块
load_matrix_sync(a_frag, A + warp_row * 16 * K + k, K);
load_matrix_sync(b_frag, B + k * N + warp_col * 16, N);
// 调用Tensor Core执行乘累加 acc = a_frag * b_frag + acc
mma_sync(acc, a_frag, b_frag, acc);
}
// 将结果写回全局内存
store_matrix_sync(C + warp_row * 16 * N + warp_col * 16, acc, N, row_major);
}
存在的问题:
- 全局内存访问量巨大,和朴素矩阵乘一样,每个元素被加载K/16次
- 性能受限于全局内存带宽,无法发挥Tensor Core的算力
- 每个线程块只有一个warp,SM利用率极低
5.2 版本2:共享内存分块优化
借鉴普通矩阵乘的分块(Tiling)思想,我们引入共享内存:将A和B的分块先加载到共享内存中,再让warp从共享内存加载fragment,大幅减少全局内存访问次数。
核心思路:
- 每个线程块处理32×32的输出块(包含2×2个WMMA块,共4个warp)
- 沿K维度迭代时,每次将A和B的32×16、16×32块加载到共享内存
- 块内的4个warp都从共享内存加载数据,全局内存只需要加载一次
#define BLOCK_M 32
#define BLOCK_N 32
#define BLOCK_K 16
__global__ void wmma_v2(const half* __restrict__ A,
const half* __restrict__ B,
float* __restrict__ C,
int M, int N, int K)
{
// 共享内存:存储A和B的当前块
__shared__ half s_A[BLOCK_M][BLOCK_K];
__shared__ half s_B[BLOCK_K][BLOCK_N];
int tid = threadIdx.x;
int warp_id = tid / 32; // 线程块内的warp编号 0~3
int warp_row = warp_id / 2; // 0~1
int warp_col = warp_id % 2; // 0~1
// 当前线程块负责的C块左上角坐标
int c_block_row = blockIdx.y * BLOCK_M;
int c_block_col = blockIdx.x * BLOCK_N;
// 初始化累加器
fragment<accumulator, 16, 16, 16, float> acc;
fill_fragment(acc, 0.0f);
// 沿K维度迭代
for (int k = 0; k < K; k += BLOCK_K) {
// ========== 协作加载共享内存 ==========
// 每个线程加载2个元素,填满32x16的s_A
for (int i = tid; i < BLOCK_M * BLOCK_K; i += blockDim.x) {
int row = i / BLOCK_K;
int col = i % BLOCK_K;
int g_row = c_block_row + row;
int g_col = k + col;
if (g_row < M && g_col < K) {
s_A[row][col] = A[g_row * K + g_col];
} else {
s_A[row][col] = 0.0_h;
}
}
// 每个线程加载2个元素,填满16x32的s_B
for (int i = tid; i < BLOCK_K * BLOCK_N; i += blockDim.x) {
int row = i / BLOCK_N;
int col = i % BLOCK_N;
int g_row = k + row;
int g_col = c_block_col + col;
if (g_row < K && g_col < N) {
s_B[row][col] = B[g_row * N + g_col];
} else {
s_B[row][col] = 0.0_h;
}
}
__syncthreads();
// ========== 从共享内存加载并计算 ==========
fragment<matrix_a, 16, 16, 16, half, row_major> a_frag;
fragment<matrix_b, 16, 16, 16, half, col_major> b_frag;
load_matrix_sync(a_frag, &s_A[warp_row * 16][0], BLOCK_K);
load_matrix_sync(b_frag, &s_B[0][warp_col * 16], BLOCK_N);
mma_sync(acc, a_frag, b_frag, acc);
__syncthreads();
}
// 将结果写回全局内存
store_matrix_sync(
C + (c_block_row + warp_row * 16) * N + warp_col * 16,
acc, N, row_major
);
}
优化收益:
- 全局内存访问量降低为原来的1/16(BLOCK_K=16),大幅缓解带宽瓶颈
- 每个线程块有128个线程(4个warp),SM利用率显著提升
5.3 版本3:消除共享内存Bank冲突
在之前的共享内存优化文章中我们讲过,共享内存有32个Bank,多线程同时访问同一个Bank会产生Bank冲突,导致性能下降。
WMMA从共享内存加载数据时,是warp级的连续访问,默认布局下很容易产生Bank冲突。解决方法和之前一致:添加填充(Padding)。
只需要修改共享内存的声明,在列维度多加1个元素:
// 修改前,有Bank冲突
__shared__ half s_A[BLOCK_M][BLOCK_K];
__shared__ half s_B[BLOCK_K][BLOCK_N];
// 修改后,无Bank冲突
__shared__ half s_A[BLOCK_M][BLOCK_K + 1];
__shared__ half s_B[BLOCK_K][BLOCK_N + 1];
仅仅增加1个元素的填充,就能让共享内存的访问性能提升一倍以上,是投入产出比极高的优化。
5.4 版本4:双缓冲预取
为了进一步隐藏内存访问延迟,我们可以引入**双缓冲(Double Buffering)**技术:使用两组共享内存缓冲区,一组用于当前计算,另一组预加载下一个K块的数据,让计算和数据加载完全重叠。
双缓冲的实现思路:
- 声明两组共享内存
[2][BLOCK_M][BLOCK_K+1] - 预加载第一个块到缓冲区0
- 循环中:计算当前缓冲区的同时,预加载下一个块到另一个缓冲区
- 切换缓冲区,进入下一轮迭代
双缓冲可以几乎完全隐藏共享内存的加载延迟,让Tensor Core持续满负载运行,进一步提升算力利用率。
5.5 更多优化方向
- 寄存器分块:每个warp计算多个输出块,增加计算密度,减少共享内存加载次数
- 扩大分块尺寸:使用64×64的输出块,进一步提高数据复用率
- 向量化加载:使用
half2等向量类型加载全局内存,提升访存效率 - 调整线程块大小:根据GPU架构调整warp数量,平衡寄存器、共享内存和计算资源
六、编译、验证与性能测试
6.1 编译要求
使用WMMA需要满足两个编译条件:
- 架构必须 ≥ sm_70(Volta及以上)
- 包含头文件
<mma.h>
编译命令示例:
nvcc -arch=sm_80 -O3 -o wmma_matmul wmma_matmul.cu
6.2 正确性验证
手写WMMA矩阵乘很容易因为布局、索引错误得到错误结果,一定要和FP32基准结果做对比:
- 先用cuBLAS的SGEMM生成FP32基准结果
- 运行WMMA版本得到结果
- 计算平均误差和最大误差,确认在可接受范围内
FP16输入+FP32累加的混合精度模式,相对误差通常在1e-3级别,绝大多数场景都能满足要求。
6.3 性能参考
在RTX 3060(sm_86)上,1024×1024×1024的矩阵乘法:
- 朴素CUDA Core FP32版本:约1.2 TFLOPS
- 优化后WMMA FP16混合精度版本:约18 TFLOPS
- cuBLAS Tensor Core版本:约22 TFLOPS
手写WMMA可以达到官方库80%左右的性能,对于自定义算子来说已经非常优秀。
七、常见坑点与最佳实践
7.1 常见坑点
- 单线程调用WMMA:WMMA是warp级原语,必须32个线程同步调用,否则行为未定义
- 布局搞反:行主序/列主序不匹配会得到完全错误的结果,且很难排查
- ldm参数传错:Leading Dimension是矩阵的实际行/列数,不是块的大小,边界处容易出错
- 忘记同步:共享内存加载后必须
__syncthreads(),否则会读到未完成的数据 - 累加器用低精度:绝对不要用FP16做累加器,误差会快速累积到不可接受的程度
7.2 最佳实践
- 优先用官方库:标准矩阵运算优先用cuBLAS,自定义算子再考虑手写WMMA
- 标准混合精度范式:低精度输入 + FP32累加,平衡性能与精度
- 16的倍数对齐:矩阵尺寸尽量对齐到16的倍数,避免边界处理开销
- 共享内存必加填充:从一开始就写带填充的共享内存,避免后续排查Bank冲突
- 做好边界处理:非对齐尺寸用0填充边界,保证WMMA运算的正确性
八、总结
Tensor Core是现代GPU的算力核心,而WMMA API是我们直接操控这一强大硬件的桥梁。它的编程模型虽然和传统CUDA有差异,但核心优化思想一脉相承——通过分块提升数据复用,通过隐藏延迟提升硬件利用率。
本文我们从硬件原理出发,系统讲解了WMMA的编程模型、核心API,并通过递进式优化实现了高性能混合精度矩阵乘法。掌握了这些知识,你就具备了开发自定义Tensor Core算子的能力,可以在标准库无法满足需求时,充分释放GPU的算力潜力。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 9
9 0
0- 0



 已为社区贡献21条内容
已为社区贡献21条内容

所有评论(0)