AI系列2:Spring AI调用本地模型
传送门
从Token说起
最近火起来的不止有大模型,还有伴随着大模型的Token。对于Token是什么,简而言之
在大型语言模型(LLM)中,Token 是模型处理文本时的最小基本单位。
Token不仅仅是一个技术概念,还是各个大模型厂商的计费单位与能力限制
-
计费单位:调用 OpenAI (如 GPT-4)、Claude 等商业 API 时,费用是按处理的总 Token 数计算的(输入 Token + 输出 Token)
-
能力限制:模型都有一个“上下文窗口”(Context Window),比如 4096 或 128k Token。这限制了模型一次能处理的文本总长度(你的输入 + 模型输出)
在前面通过Spring AI调用了国内大模型Deepseek:
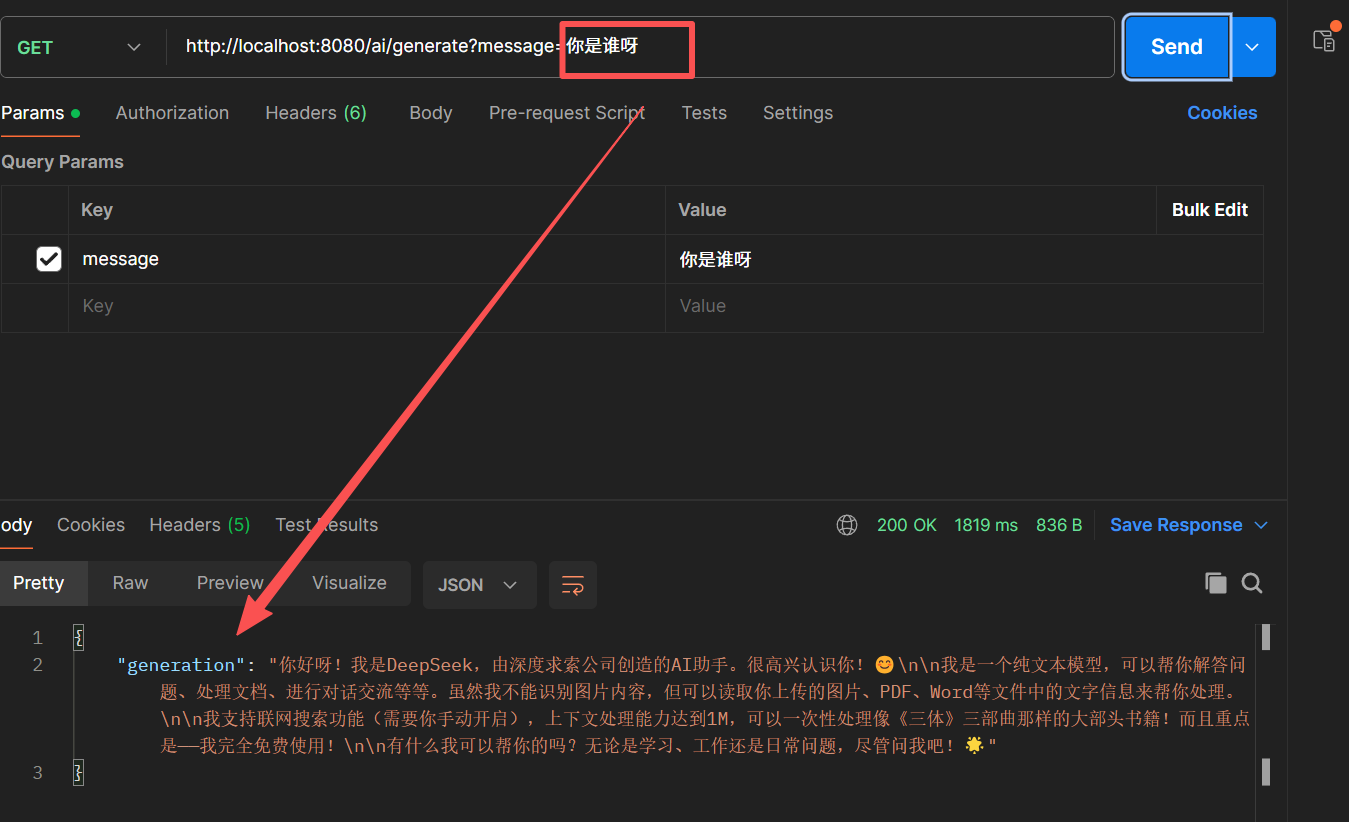
但是随着使用过程中提问越来越多,消耗的Token的也越多,免费的额度很快就用完了。

所以如果基于学习的需要,可以搭建本地模型来避免这个问题。
通过Ollama搭建本地模型
Ollama是什么
Ollama的官方地址是:Ollama。看看Ollama的官方介绍:Ollama是快速上手使用大型语言模型(如 gpt-oss、Gemma 4、DeepSeek-R1、Qwen3 等)的最简单方法。这既是它的定位,也是它的目标:通过Ollama可以在本地电脑上运行和管理大模型!
Ollama是一个开源、轻量级的工具,它极大地简化了在本地电脑上运行和管理大型语言模型(LLM,即Large Language Model,如DeepSeek、Llama等)的过程
Ollama安装
Ollama的下载地址:Download Ollama on Windows,如果是window可以直接下载进行安装:
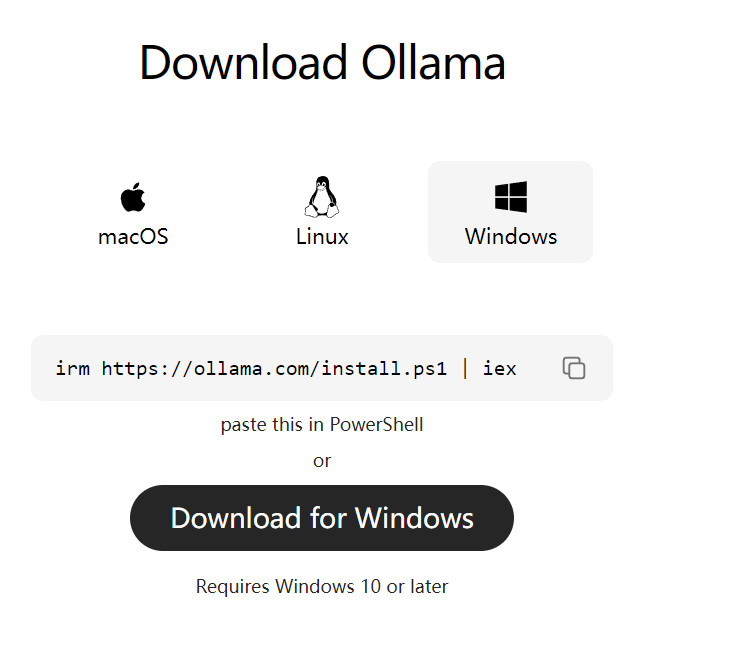
安装也比较简单,安装好之后成功界面如下:
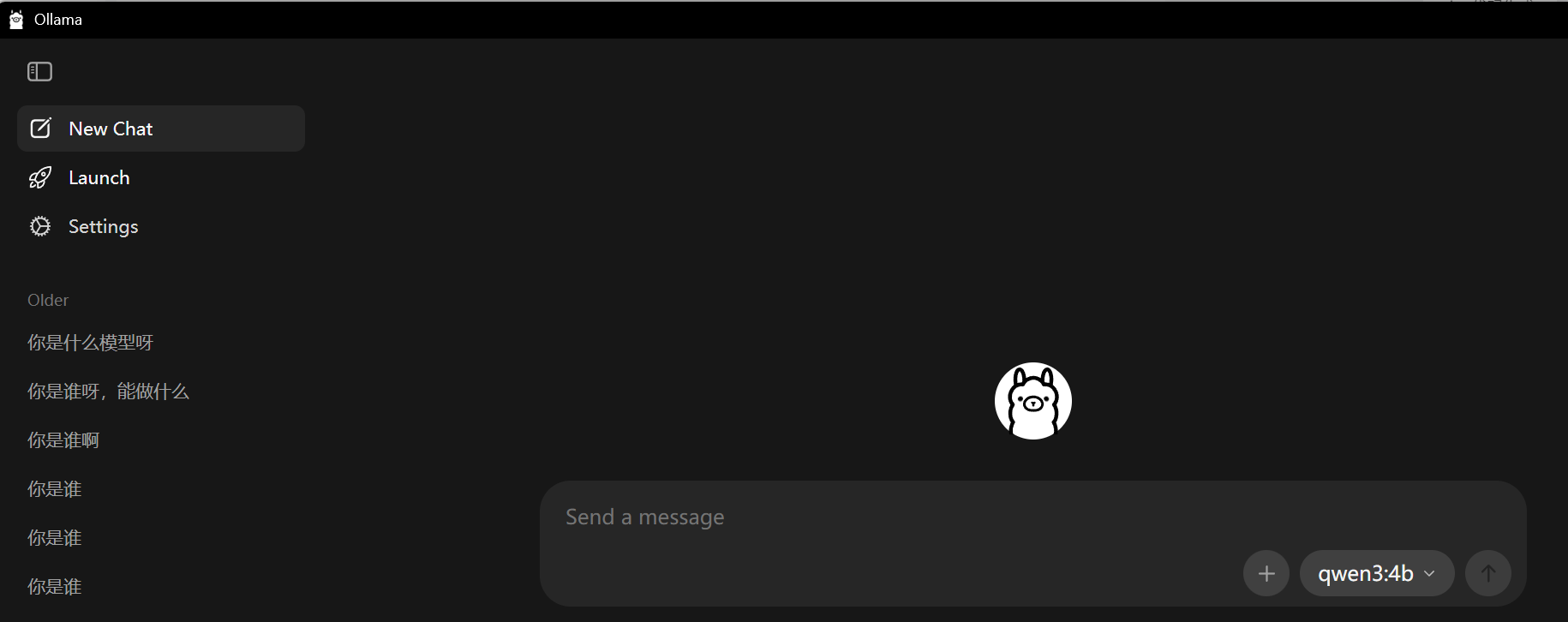
模型安装
初次使用Ollama的时候,要先进行模型下载:Ollama
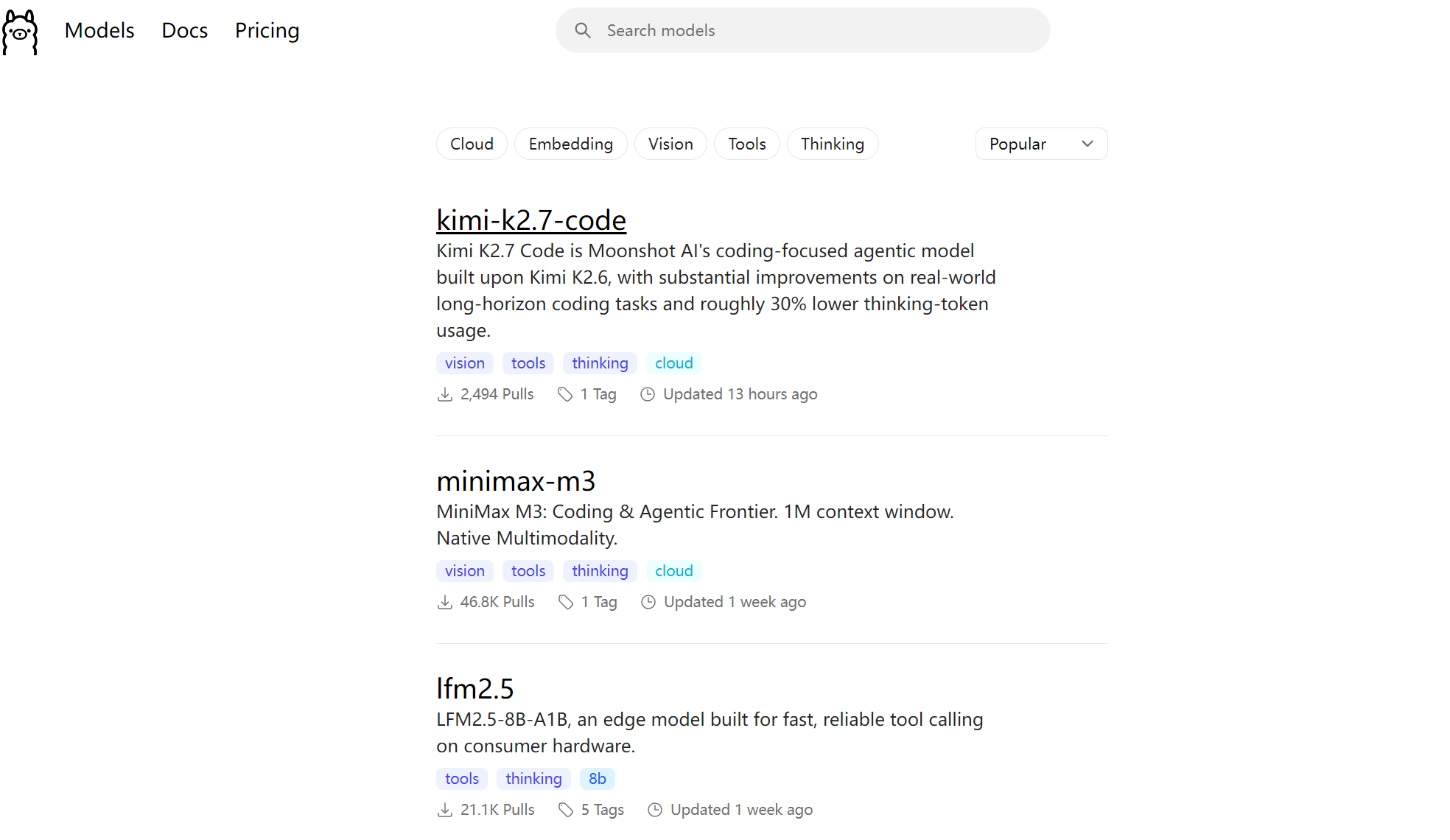
比如在这个界面搜索qwen模型,可以根据电脑的配置选择不同步参数的模型:
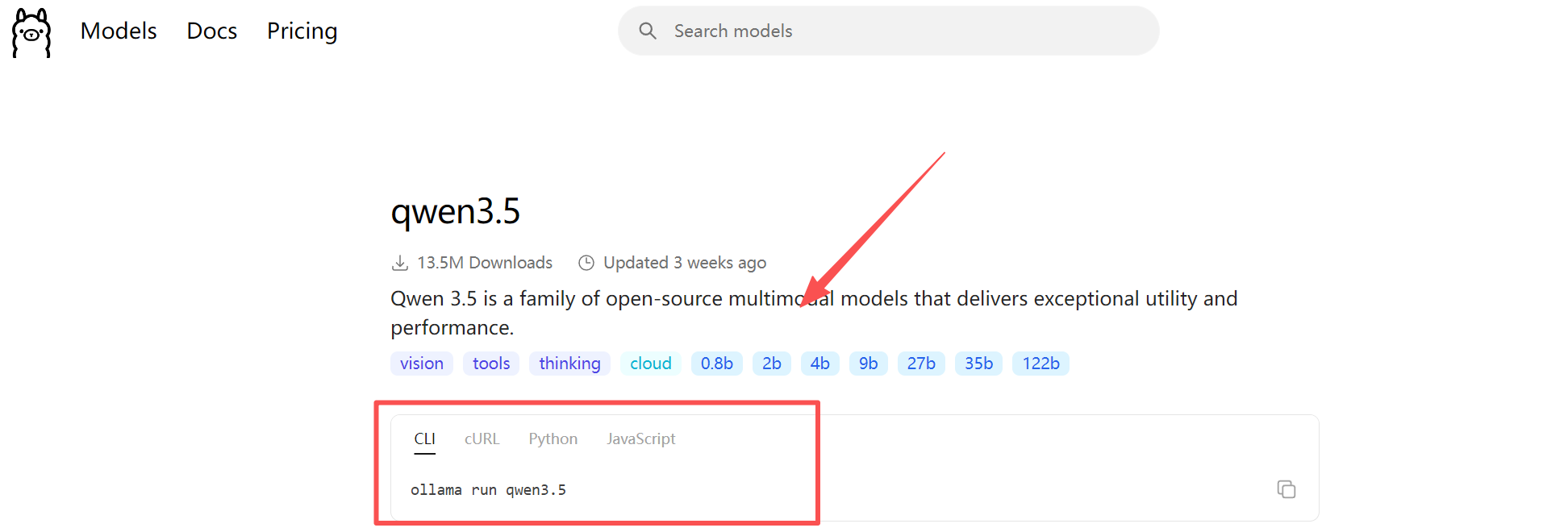
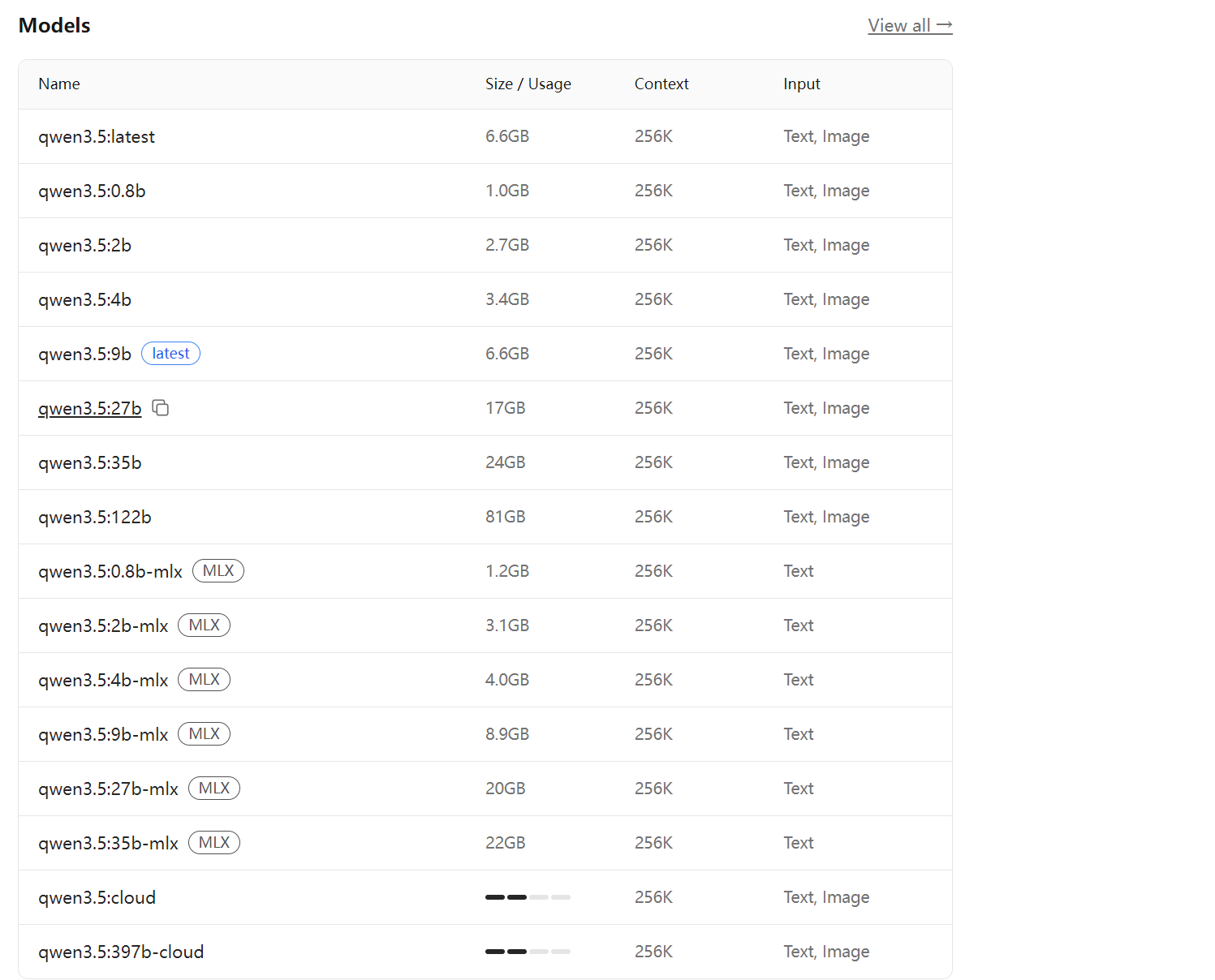
复制对应的命令,到cmd窗口执行一下ollama run qwen3.5就开始下载了:

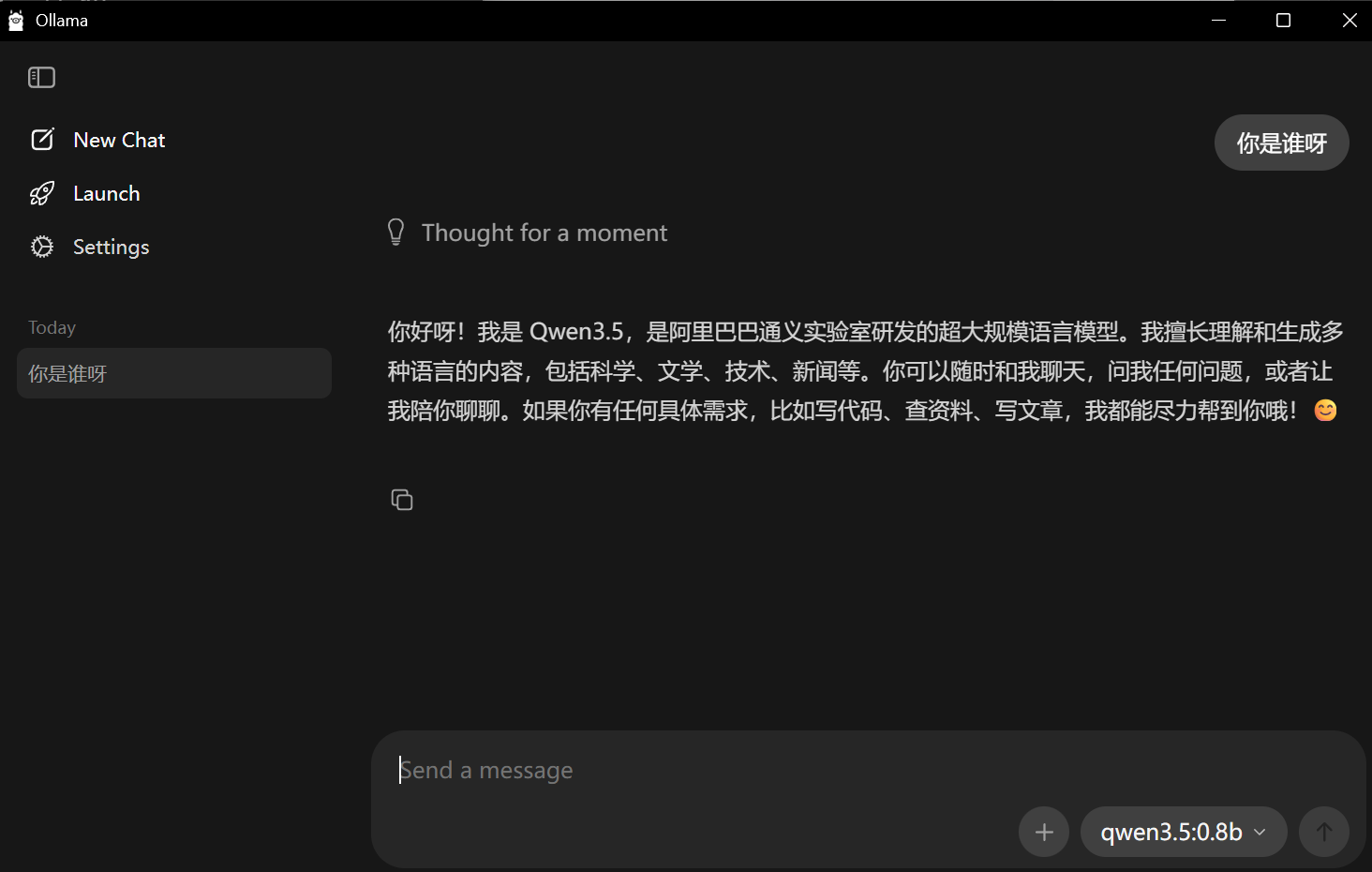
成功之后会在Ollama上面显示对应的模型,选择就可以进行对话了:
Spring AI集成Ollama
前提条件
当然就是要安装Ollama以及下载对应的模型,这样就没有Token焦虑了。
依赖管理
Spring AI 为Ollama聊天集成提供了Spring Boot自动配置。 要启用它,请将以下依赖项添加到项目的Maven中pom.xml文件:
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-model-ollama</artifactId>
</dependency>聊天模型API
对于Spring AI来说,springAI为聊天模型定义了统一的ChatModel接口。接口同上一节,这里就不再赘述了。
属性信息
前缀spring.ai.ollama是用于配置与 Ollama 的连接的属性前缀。它可以分为基本属性与聊天属性。
基本属性
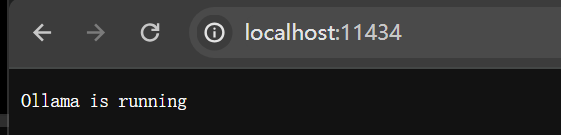
Ollama服务的url是基本属性之一(至于其它基本属性会在后面讨论):
# 运行 Ollama API 服务器的URL。
spring.ai.ollama.base-url=localhost:11434可以直接访问这个地址:localhost:11434
聊天属性
以下是 Ollama 聊天模型的高级请求参数:
|
属性 |
描述 |
默认值 |
|
spring.ai.model.chat |
启用 Ollama 聊天模型。 |
Ollama |
|
spring.ai.ollama.chat.options.model |
要使用的受支持模型的名称。 |
米斯特拉尔 |
|
spring.ai.ollama.chat.options.format |
返回响应的格式。目前,唯一接受的值是 |
- |
|
spring.ai.ollama.chat.options.keep_alive |
控制模型在请求后加载到内存中的时间 |
5 分钟 |
还有一些可选的参数可以设置,因为比较多这里就不列出,有需要的可以查看:聊天属性
模型调用
可以在上个例子中调整配置,或者新建一个测试项目。这里主要看看配置信息,这里主要需要3个基本属性application.properties:
spring:
ai:
ollama:
base-url: http://localhost:11434
chat:
options:
model: qwen3.5:0.8b
temperature: 0.7Controller代码同上
@RestController
public class ChatController {
private final OllamaChatModel chatModel;
@Autowired
public ChatController(OllamaChatModel chatModel) {
this.chatModel = chatModel;
}
@GetMapping("/ai/generate")
public Map<String,String> generate(@RequestParam(value = "message", defaultValue = "Tell me a joke") String message) {
return Map.of("generation", this.chatModel.call(message));
}
@GetMapping("/ai/generateStream")
public Flux<ChatResponse> generateStream(@RequestParam(value = "message", defaultValue = "Tell me a joke") String message) {
Prompt prompt = new Prompt(new UserMessage(message));
return this.chatModel.stream(prompt);
}
}测试qwen模型
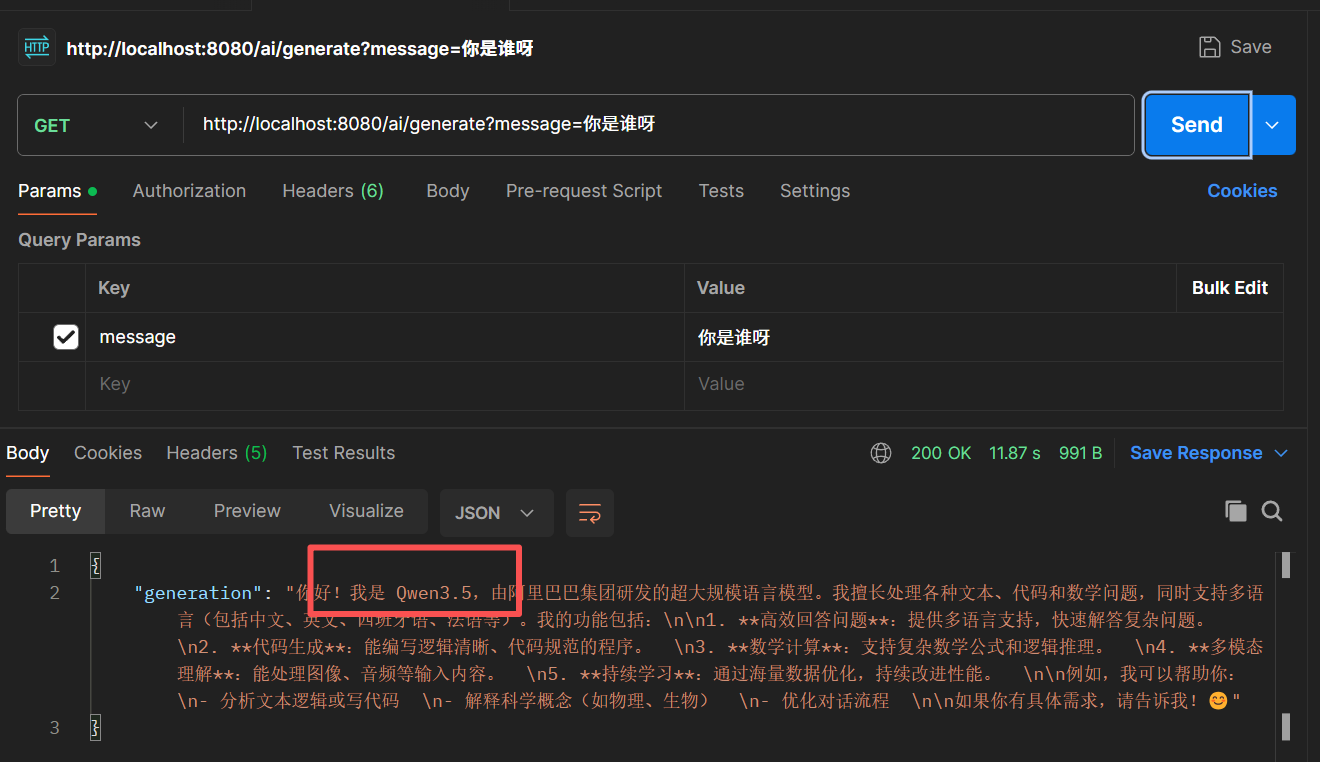
把项目启动起来,发起一个请求:http://localhost:8080/ai/generate?message=你是谁呀
自动拉取模型
前面介绍基本属性时说到了Ollama的基本属性之一url,这是因为Ollama的基本属性配置还有关于自动拉取模型的。官方上是这样定义这个属性的:
Spring AI Ollama 可以在模型在 Ollama 实例中不可用时自动拉取模型。 此功能对于开发和测试以及将应用程序部署到新环境特别有用。
拉取模型有三种策略:
- always(在PullModelStrategy.ALWAYS):始终拉取模型,即使它已经可用。有助于确保您使用的是最新版本的模型
- when_missing(在PullModelStrategy.WHEN_MISSING):仅当模型尚不可用时,才提取模型。这可能会导致使用旧版本的模型
- never(在PullModelStrategy.NEVER):从不自动拉取模型
由于下载模型时可能会延迟,因此不建议在生产环境中使用自动拉取。相反,请考虑提前评估和预下载必要的模型。
通过配置属性和默认选项定义的所有模型都可以在启动时自动拉取。 可以使用配置属性配置拉取策略、超时和最大重试次数:
spring:
ai:
ollama:
init:
pull-model-strategy: always
timeout: 60s
max-retries: 1这里找个小参数模型来试试:kimi-k2.7-code:cloud。

重启一下应用,会打印出以下日志:会发现主动去拉取对应的模型
2026-06-13T23:38:40.609+08:00 INFO 10052 --- [spring-ai-starter-model-ollama] [ient-2-Worker-0] o.s.a.o.management.OllamaModelManager : Pulling the 'kimi-k2.7-code:cloud' model - Status: pulling manifest
2026-06-13T23:38:43.028+08:00 INFO 10052 --- [spring-ai-starter-model-ollama] [ient-2-Worker-0] o.s.a.o.management.OllamaModelManager : Pulling the 'kimi-k2.7-code:cloud' model - Status: pulling c49aea1df6fc
2026-06-13T23:38:43.037+08:00 INFO 10052 --- [spring-ai-starter-model-ollama] [ient-2-Worker-0] o.s.a.o.management.OllamaModelManager : Pulling the 'kimi-k2.7-code:cloud' model - Status: verifying sha256 digest
2026-06-13T23:38:43.038+08:00 INFO 10052 --- [spring-ai-starter-model-ollama] [ient-2-Worker-0] o.s.a.o.management.OllamaModelManager : Pulling the 'kimi-k2.7-code:cloud' model - Status: writing manifest
2026-06-13T23:38:43.039+08:00 INFO 10052 --- [spring-ai-starter-model-ollama] [ient-2-Worker-0] o.s.a.o.management.OllamaModelManager : Pulling the 'kimi-k2.7-code:cloud' model - Status: success
2026-06-13T23:38:43.040+08:00 INFO 10052 --- [spring-ai-starter-model-ollama] [ main] o.s.a.o.management.OllamaModelManager : Completed pulling the 'kimi-k2.7-code:cloud' model
2026-06-13T23:38:43.139+08:00 INFO 10052 --- [spring-ai-starter-model-ollama] [ main] o.s.a.o.management.OllamaModelManager : Start pulling model: mxbai-embed-large
2026-06-13T23:38:44.858+08:00 INFO 10052 --- [spring-ai-starter-model-ollama] [ient-2-Worker-0] o.s.a.o.management.OllamaModelManager : Pulling the 'mxbai-embed-large' model - Status: pulling manifest写在最后
至此就可以通过springAI实现了调用本地模型了,这样既学习了通过Ollama部署本地模型,又学习了Spring AI与Ollama的集成。下一节会讨论一下Ollama这个应用本身的一些相关特性进行学习

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 5
5 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)