让神经网络拥有“记忆”:RNN、LSTM 与 GRU 的通俗图解与代码实战【NLP系列第二篇】
让神经网络拥有“记忆”:RNN、LSTM 与 GRU 的通俗图解与代码实战
1. 引子:为什么需要序列模型?
上一篇我们聊了词向量(Word2Vec、nn.Embedding),把文本从文字变成了一堆向量。但有个问题——词向量本身不包含位置信息。
举个最简单的例子:
“我爱你” 和 “你爱我”
这两个句子的词向量是一模一样的(只是顺序不同),但语义完全相反。这说明了一个关键问题:
文本的顺序本身就是信息。
这就需要一类专门处理序列数据的模型——循环神经网络(RNN)。从 RNN 到 LSTM 再到 GRU,它们统治了 NLP 领域很多年,直到 Transformer 出现。但即使到今天,理解它们仍然是学习 NLP 的必修课,因为它们是理解 Attention、Seq2Seq、Transformer 的基石。
本文会覆盖三块内容:
- RNN:循环神经网络,序列建模的起点
- LSTM:长短期记忆网络,解决 RNN 的"记不住"问题
- GRU:门控循环单元,LSTM 的轻量替代
2. RNN:循环神经网络
2.1 核心思想
传统神经网络(全连接、CNN)的输入输出是独立的——前一个输入和后一个输入没啥关系。但文本显然不是这样,每个词都和它前后的词有关联。
RNN 的核心思想就一句话:
把上一个时间步的输出,作为下一个时间步的输入的一部分。
这种"循环"的结构让网络有了"记忆"能力。
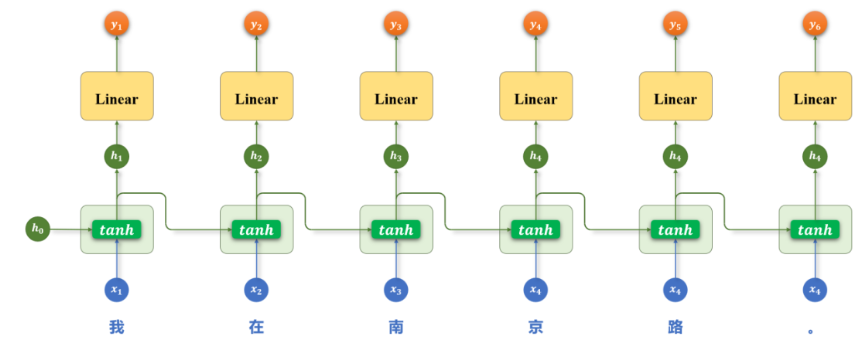
2.2 数学表达
RNN 在每个时间步 t t t 的计算公式:
h t = tanh ( W i h x t + b i h + W h h h t − 1 + b h h ) h_t = \tanh(W_{ih} x_t + b_{ih} + W_{hh} h_{t-1} + b_{hh}) ht=tanh(Wihxt+bih+Whhht−1+bhh)
其中:
- x t x_t xt:当前时间步的输入
- h t − 1 h_{t-1} ht−1:上一个时间步的隐状态
- h t h_t ht:当前时间步的隐状态(也是输出)
- W i h , W h h W_{ih}, W_{hh} Wih,Whh:权重矩阵(所有时间步共享)
参数共享是 RNN 的关键特性。不管序列有多长, W i h W_{ih} Wih 和 W h h W_{hh} Whh 在所有时间步上都是同一套参数。这大大减少了参数量,也让模型能够处理变长序列。
2.3 输入输出结构(3D 张量)
RNN 的输入输出都是三维张量,理解它们的形状是写代码的第一步。
输入 Tensor 的形状取决于 batch_first 参数:
| 参数 | 形状 | 示例 |
|---|---|---|
batch_first=False(默认) |
(seq_len, batch, input_size) |
(5, 3, 10) |
batch_first=True |
(batch, seq_len, input_size) |
(3, 5, 10) |
输出 Tensor 有两部分:
output:所有时间步的输出,形状为(seq_len, batch, hidden_size * num_directions)h_n:最后一个时间步的隐状态,形状为(num_layers * num_directions, batch, hidden_size)
注意:
output和h_n的区别——前者是"全程记录",后者是"最终状态"。双向 RNN 中,h_n正向和反向是分开存的,不是简单把 hidden_size 翻倍。
2.4 PyTorch 代码实战
基础调用:
import torch
import torch.nn as nn
# 创建一个单层 RNN
# input_size=10: 每个时间步输入是 10 维向量
# hidden_size=20: 隐状态维度为 20
# num_layers=1: 单层 RNN
# batch_first=True: 输入形状为 (batch, seq_len, input_size)
rnn = nn.RNN(input_size=10, hidden_size=20, num_layers=1, batch_first=True)
# 构造输入: (batch_size=3, seq_len=5, input_size=10)
x = torch.randn(3, 5, 10)
# 前向传播
output, hn = rnn(x)
print(output.shape) # torch.Size([3, 5, 20])
print(hn.shape) # torch.Size([1, 3, 20])
多层双向 RNN:
# 两层双向 RNN
# bidirectional=True: 双向,output 的 hidden_size 会翻倍
# num_layers=2: 堆叠两层
rnn = nn.RNN(10, 20, num_layers=2, batch_first=True, bidirectional=True)
x = torch.randn(3, 5, 10)
output, hn = rnn(x)
# output: 双向使 hidden_size 翻倍 (20 → 40)
print(output.shape) # torch.Size([3, 5, 40])
# hn: (num_layers * num_directions, batch, hidden_size)
# 2层 * 2方向 = 4,所以第一个维度是 4
print(hn.shape) # torch.Size([4, 3, 20])
易错点:双向 RNN 中
h_n的形状是(4, 3, 20)而不是(2, 3, 40)。正向和反向的隐状态是各自独立保存的,不会在 hidden_size 维度拼接。只有output会在 hidden_size 维度拼接。
2.5 BPTT 与梯度消失
RNN 的训练用的是 BPTT(Backpropagation Through Time),说白了就是把 RNN 在时间轴上"展开",变成一个很深的网络,然后正常反向传播。
但问题来了——序列一长,梯度就没了。
因为每个时间步共享参数 W h h W_{hh} Whh,反向传播时梯度包含 W h h k W_{hh}^k Whhk 项,会随着时间步 k k k 呈指数级变化。如果 W h h W_{hh} Whh 的特征值小于 1,梯度迅速消失;大于 1,梯度爆炸。
这就是 RNN 的致命缺陷:长距离依赖根本记不住。
于是 LSTM 诞生了。
3. LSTM:长短期记忆网络
3.1 从 RNN 的痛点说起
RNN 记不住长距离信息,本质原因是隐状态 h t h_t ht 既要当"记忆"又要当"输出",承担了太多职责。每次更新都要把旧信息覆盖掉,很难保留之前的关键内容。
LSTM 的解决方案很巧妙:把"记忆"和"输出"分开。
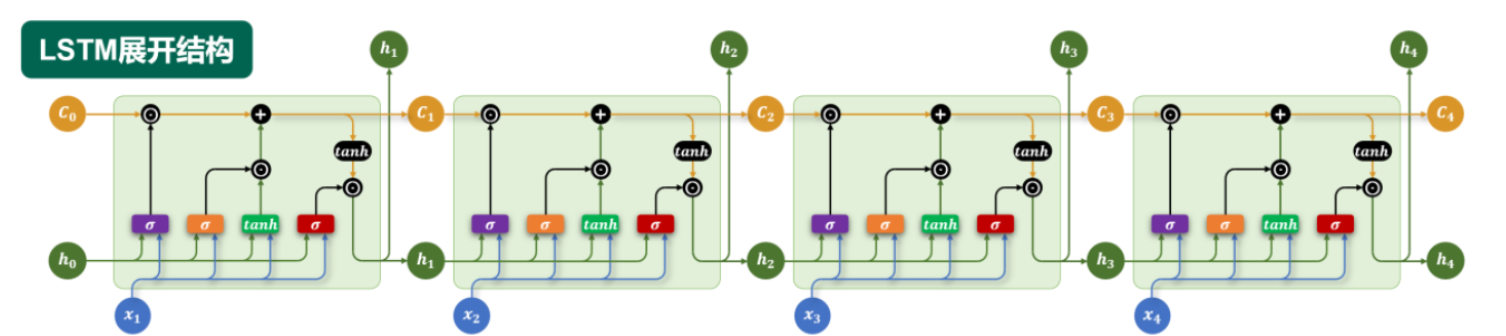
3.2 细胞状态与三扇门
LSTM 引入了一个新概念——细胞状态(Cell State) C t C_t Ct,你可以把它想象成一条"传送带",贯穿整个时间链条,承载着长期记忆。
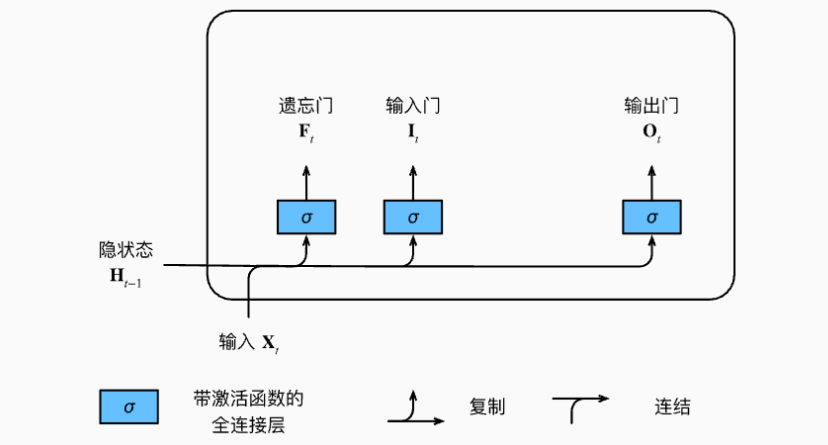
然后通过三个门控结构来控制这条传送带上的信息流动:
- 遗忘门(Forget Gate):决定从细胞状态中丢弃哪些信息
- 输入门(Input Gate):决定哪些新信息存入细胞状态
- 输出门(Output Gate):决定基于当前细胞状态输出什么
3.3 公式拆解
遗忘门:
f t = σ ( W f ⋅ [ h t − 1 , x t ] + b f ) f_t = \sigma(W_f \cdot [h_{t-1}, x_t] + b_f) ft=σ(Wf⋅[ht−1,xt]+bf)
- 输出范围 [0, 1],1 表示"完全保留",0 表示"完全丢弃"
输入门(两步):
i t = σ ( W i ⋅ [ h t − 1 , x t ] + b i ) i_t = \sigma(W_i \cdot [h_{t-1}, x_t] + b_i) it=σ(Wi⋅[ht−1,xt]+bi)
C ~ t = tanh ( W C ⋅ [ h t − 1 , x t ] + b C ) \tilde{C}_t = \tanh(W_C \cdot [h_{t-1}, x_t] + b_C) C~t=tanh(WC⋅[ht−1,xt]+bC)
- i t i_t it 决定更新哪些信息
- C ~ t \tilde{C}_t C~t 生成候选细胞状态(新信息的内容)
更新细胞状态:
C t = f t ⊙ C t − 1 + i t ⊙ C ~ t C_t = f_t \odot C_{t-1} + i_t \odot \tilde{C}_t Ct=ft⊙Ct−1+it⊙C~t
- 遗忘旧信息: f t ⊙ C t − 1 f_t \odot C_{t-1} ft⊙Ct−1
- 添加新信息: i t ⊙ C ~ t i_t \odot \tilde{C}_t it⊙C~t
输出门:
o t = σ ( W o ⋅ [ h t − 1 , x t ] + b o ) o_t = \sigma(W_o \cdot [h_{t-1}, x_t] + b_o) ot=σ(Wo⋅[ht−1,xt]+bo)
h t = o t ⊙ tanh ( C t ) h_t = o_t \odot \tanh(C_t) ht=ot⊙tanh(Ct)
LSTM 的巧妙之处在于: C t C_t Ct 的更新是"加性"的(遗忘 + 添加),而不是像 RNN 那样直接覆盖。这就避免了梯度消失——梯度可以从 C t C_t Ct 直接传到 C t − 1 C_{t-1} Ct−1,穿过长时间步而不衰减。
3.4 PyTorch 代码实战
LSTM 的输出比 RNN 多了一个 c n c_n cn(细胞状态)。
基础调用:
import torch
import torch.nn as nn
# 创建单层 LSTM
lstm = nn.LSTM(input_size=10, hidden_size=20, num_layers=1, batch_first=True)
# 输入: (batch=3, seq_len=5, input_size=10)
x = torch.randn(3, 5, 10)
# LSTM 返回三部分: output, (hn, cn)
output, (hn, cn) = lstm(x)
print(output.shape) # torch.Size([3, 5, 20])
print(hn.shape) # torch.Size([1, 3, 20])
print(cn.shape) # torch.Size([1, 3, 20]) ← 细胞状态,形状和 hn 一样
多层双向 LSTM:
# 两层双向 LSTM
lstm = nn.LSTM(10, 20, num_layers=2, batch_first=True, bidirectional=True)
x = torch.randn(3, 5, 10)
output, (hn, cn) = lstm(x)
# output: hidden_size 翻倍
print(output.shape) # torch.Size([3, 5, 40])
# hn, cn: (2层 * 2方向, batch, hidden_size)
print(hn.shape) # torch.Size([4, 3, 20])
print(cn.shape) # torch.Size([4, 3, 20])
易错点:LSTM 的返回值是
output, (hn, cn)这种嵌套结构。新手容易写成output, hn, cn = lstm(x),这样hn会接收到元组(hn, cn),导致后续报错。一定要记得解包两层。
4. GRU:门控循环单元
4.1 更轻量的选择
GRU 是 LSTM 的简化版,2014 年由 Cho 等人提出。核心思路:
- LSTM 有三扇门,参数多,训练慢
- 能不能在不损失太多效果的前提下,减少门的数量?
GRU 做到了:把遗忘门和输入门合并成更新门,同时去掉了细胞状态。
4.2 两个门控结构
GRU 只有两个门:
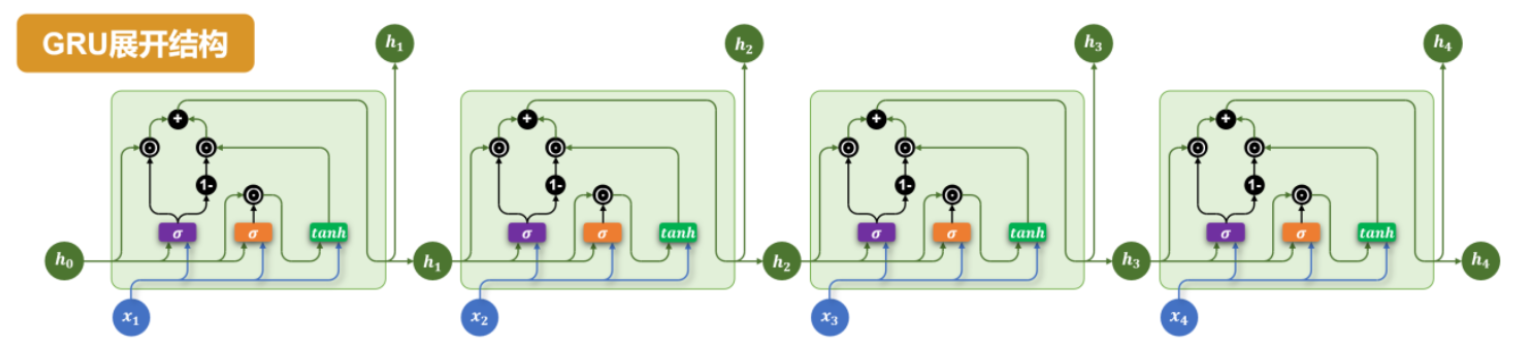
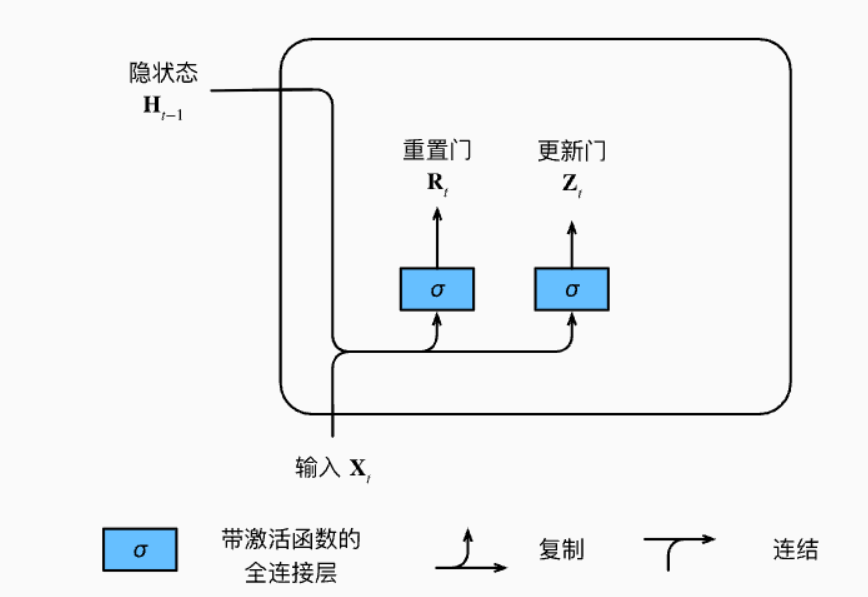
更新门(Update Gate) z t z_t zt:
决定保留多少历史信息,同时融入多少新信息。
z t = σ ( W z ⋅ [ h t − 1 , x t ] + b z ) z_t = \sigma(W_z \cdot [h_{t-1}, x_t] + b_z) zt=σ(Wz⋅[ht−1,xt]+bz)
- 相当于 LSTM 中遗忘门 + 输入门的结合体
- 越接近 1:越遗忘历史,融入更多新信息
重置门(Reset Gate) r t r_t rt:
决定历史隐状态对当前候选隐状态的影响程度。
r t = σ ( W r ⋅ [ h t − 1 , x t ] + b r ) r_t = \sigma(W_r \cdot [h_{t-1}, x_t] + b_r) rt=σ(Wr⋅[ht−1,xt]+br)
- 越接近 0:越忽略历史,相当于"重置"状态
- 越接近 1:越多保留历史信息
候选隐状态:
h ~ t = tanh ( W h ⋅ [ r t ⊙ h t − 1 , x t ] + b h ) \tilde{h}_t = \tanh(W_h \cdot [r_t \odot h_{t-1}, x_t] + b_h) h~t=tanh(Wh⋅[rt⊙ht−1,xt]+bh)
- r t ⊙ h t − 1 r_t \odot h_{t-1} rt⊙ht−1 按重置门决定保留多少历史信息
- 然后和当前输入 x t x_t xt 拼接,经过 tanh \tanh tanh 激活
最终隐状态:
h t = ( 1 − z t ) ⊙ h t − 1 + z t ⊙ h ~ t h_t = (1 - z_t) \odot h_{t-1} + z_t \odot \tilde{h}_t ht=(1−zt)⊙ht−1+zt⊙h~t
- ( 1 − z t ) ⊙ h t − 1 (1 - z_t) \odot h_{t-1} (1−zt)⊙ht−1:保留一部分历史信息
- z t ⊙ h ~ t z_t \odot \tilde{h}_t zt⊙h~t:融入一部分新信息
- 两者互补,实现类似 LSTM 中遗忘门 + 输入门的效果
4.3 PyTorch 代码实战
GRU 的 API 和 RNN 几乎一样,但没有细胞状态。
基础调用:
import torch
import torch.nn as nn
# 创建单层 GRU
gru = nn.GRU(input_size=10, hidden_size=20, num_layers=1, batch_first=True)
# 输入: (batch=3, seq_len=5, input_size=10)
x = torch.randn(3, 5, 10)
# GRU 返回 output 和 hn(没有 cn)
output, hn = gru(x)
print(output.shape) # torch.Size([3, 5, 20])
print(hn.shape) # torch.Size([1, 3, 20])
多层双向 GRU:
# 两层双向 GRU
gru = nn.GRU(10, 20, num_layers=2, batch_first=True, bidirectional=True)
x = torch.randn(3, 5, 10)
output, hn = gru(x)
print(output.shape) # torch.Size([3, 5, 40])
print(hn.shape) # torch.Size([4, 3, 20])
5. RNN / LSTM / GRU 对比
| 维度 | RNN | LSTM | GRU |
|---|---|---|---|
| 门控数量 | 0(无门控) | 3(遗忘/输入/输出) | 2(更新/重置) |
| 细胞状态 | 无 | 有 C t C_t Ct | 无 |
| 参数量 | 最少 | 最多 | 中等 |
| 长序列能力 | 差(梯度消失) | 强(加性更新) | 较强 |
| 训练速度 | 最快 | 最慢 | 中等 |
| 输出内容 | output, hn |
output, (hn, cn) |
output, hn |
选型建议:
- 对速度有要求、任务不太复杂:选 GRU,参数少、训练快、效果和 LSTM 相当
- 追求最佳效果、序列很长:选 LSTM,三门控 + 细胞状态,长距离依赖更强
- 学习研究、理解序列模型本质:从 RNN 入手,虽然实际用得少,但它是理解 LSTM/GRU 的基础
- 数据量很小:注意 LSTM 参数量多,容易过拟合,这时 GRU 反而更稳妥
6. PyTorch 避坑指南
总结几个写代码时最容易踩的坑:
6.1 batch_first 默认是 False
这是最经典的坑。nn.RNN、nn.LSTM、nn.GRU 的 batch_first 默认是 False,输入形状要求 (seq_len, batch, input_size)。
如果你习惯用 (batch, seq_len, input_size),一定记得加上 batch_first=True,否则算出来的形状全不对。
6.2 双向 RNN 的 h_n 维度
正向和反向的终点不同,h_n 中正向和反向分别保存:
h_n[0]:第一层正向h_n[1]:第一层反向h_n[2]:第二层正向h_n[3]:第二层反向
维度公式:(num_layers * num_directions, batch, hidden_size)
6.3 output vs h_n 的区别
output:所有时间步的输出。需要每个时刻的输出时用(比如序列标注)h_n:最后一个时间步的隐状态。只需要最终结果时用(比如文本分类)
如果任务只需要序列的最终表示,用 h_n 就够了,用 output 反而浪费计算。
6.4 LSTM 返回值解包
# 正确写法 ✅
output, (hn, cn) = lstm(x)
# 错误写法 ❌
output, hn, cn = lstm(x) # hn 会接到 (hn, cn) 元组,下一行 cn 就报错了
6.5 官方文档
下篇预告:讲完传统序列模型,下一步就是 Self-Attention 和 Transformer 了——当前大模型时代的真正基石。但有了 RNN / LSTM / GRU 的基础,理解 Attention 会轻松很多。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 25
25 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)