Kubernetes 中部署 NVIDIA GPU Operator,并接入 Prometheus + Grafana 监控 GPU 指标
一、背景说明
在 Kubernetes 中使用 NVIDIA GPU,不能只依赖 Kubernetes 自身能力。Kubernetes 通过 Device Plugin 机制来识别和调度 GPU 这类扩展资源。节点上安装对应厂商的 GPU 驱动和 Device Plugin 后,集群里会暴露出类似 nvidia.com/gpu 这样的可调度资源,Pod 通过 resources.limits.nvidia.com/gpu: 1 来申请 GPU。Kubernetes 官方文档也说明,GPU 这类设备资源需要写在 limits 中;如果只写 limits 不写 requests,Kubernetes 会默认把 limit 当成 request;如果同时写 requests 和 limits,两者必须相等。
NVIDIA GPU Operator 的作用,就是把 Kubernetes 使用 NVIDIA GPU 需要的组件统一交给 Operator 管理,包括 NVIDIA Driver、NVIDIA Container Toolkit、NVIDIA Device Plugin、GPU Feature Discovery、DCGM Exporter 等。NVIDIA GPU Operator 项目说明中也提到,它用于自动管理 Kubernetes 中运行 NVIDIA GPU 所需的软件组件。
本文主要记录四部分内容:
-
GPU Operator 的部署
-
GPU Operator 部署后的简单测试
-
Prometheus 通过 ServiceMonitor 接入 DCGM Exporter 指标
-
Grafana 导入 NVIDIA DCGM Dashboard 展示 GPU 监控数据
二、环境说明
本文环境大致如下:
Kubernetes: v1.35.5
节点名称: master-01
GPU: NVIDIA RTX 3070 Ti
容器运行时: containerd
GPU Operator: v25.3.4
Prometheus: 通过 Prometheus Operator 部署
Grafana: 已部署
先在宿主机上确认 NVIDIA Driver 是否正常:
nvidia-smi
如果宿主机上已经可以正常执行 nvidia-smi,说明 NVIDIA Driver 已经安装好。本文的部署方式就是基于“宿主机已经提前安装好 NVIDIA Driver”的场景,所以后面部署 GPU Operator 时会设置:
driver:
enabled: false
这个参数表示不让 GPU Operator 再去安装 NVIDIA Driver。NVIDIA 官方文档也说明,在节点已经预装 NVIDIA GPU Driver 的场景下,可以通过 driver.enabled=false 阻止 Operator 安装驱动。
三、部署 GPU Operator
1. 添加 NVIDIA Helm 仓库
helm repo add nvidia https://helm.ngc.nvidia.com/nvidia
helm repo update
GPU Operator 官方安装方式就是通过 Helm 部署 nvidia/gpu-operator 这个 chart。
2. 准备 values 文件
创建 gpu-operator-values.yaml:
cat > gpu-operator-values.yaml <<'EOF'
driver:
enabled: false
dcgmExporter:
enabled: true
config:
create: false
name: ""
EOF
这里几个参数说明一下。
driver:
enabled: false
表示不由 GPU Operator 安装 NVIDIA Driver。这个适合宿主机已经安装好驱动的场景。如果宿主机没有安装驱动,就不能直接照抄这个参数,需要根据自己的系统版本、驱动版本、GPU Operator 版本来确认是否让 Operator 管理驱动。
dcgmExporter:
enabled: true
表示启用 DCGM Exporter。DCGM Exporter 会采集 GPU 使用率、显存、温度、功耗等指标,并通过 HTTP /metrics 暴露给 Prometheus 抓取。NVIDIA DCGM Exporter 官方文档说明,dcgm-exporter 基于 NVIDIA DCGM,能够在 /metrics HTTP endpoint 暴露 GPU 指标,供 Prometheus 等监控系统采集。
dcgmExporter:
config:
create: false
name: ""
这个配置主要是为了避免某些版本中 dcgmExporter.config 字段为空时 Helm 模板渲染异常。不同 GPU Operator 版本的 values 字段可能会有变化,部署前建议先看一下当前版本默认 values:
helm show values nvidia/gpu-operator --version v25.3.4 | less
3. 安装 GPU Operator
helm install gpu-operator nvidia/gpu-operator \
-n gpu-operator \
--create-namespace \
--version v25.3.4 \
-f gpu-operator-values.yaml \
--wait \
--timeout 10m
四、GPU Operator 部署验证与 GPU Pod 测试
1. 查看 GPU Operator 相关 Pod
kubectl -n gpu-operator get pod
正常情况下可以看到类似组件:
gpu-operator-xxxx
gpu-operator-node-feature-discovery-master-xxxx
gpu-operator-node-feature-discovery-worker-xxxx
gpu-feature-discovery-xxxx
nvidia-container-toolkit-daemonset-xxxx
nvidia-device-plugin-daemonset-xxxx
nvidia-dcgm-exporter-xxxx
nvidia-cuda-validator-xxxx
其中几个比较关键的组件如下:
| 组件 | 作用 |
|---|---|
gpu-operator |
GPU Operator 控制器本身 |
node-feature-discovery |
发现节点硬件特征,并给节点打标签 |
nvidia-container-toolkit-daemonset |
配置容器运行时,使容器可以使用 NVIDIA GPU |
nvidia-device-plugin-daemonset |
向 kubelet 注册 nvidia.com/gpu 扩展资源 |
gpu-feature-discovery |
发现 GPU 型号、驱动、CUDA 等 GPU 信息 |
nvidia-dcgm-exporter |
暴露 GPU 监控指标给 Prometheus |
nvidia-cuda-validator |
验证 CUDA/GPU 是否可用 |
2. 查看节点是否识别到 GPU 资源
kubectl describe node master-01 | grep -A10 -E "Capacity|Allocatable"
重点看有没有下面这种资源:
nvidia.com/gpu: 1
也可以直接过滤:
kubectl describe node master-01 | grep nvidia.com/gpu
如果能看到 nvidia.com/gpu,说明 NVIDIA Device Plugin 已经把 GPU 资源注册给 Kubernetes 了。后续 Pod 就可以通过下面这种方式申请 GPU:
resources:
limits:
nvidia.com/gpu: 1
3. 创建 GPU 测试 Pod
创建一个简单的测试 Pod,启动后直接执行 nvidia-smi:
apiVersion: v1
kind: Pod
metadata:
name: gpu-test
spec:
restartPolicy: Never
containers:
- name: cuda-test
image: docker.io/nvidia/cuda:12.0.0-base-ubuntu22.04
command: ["nvidia-smi"]
resources:
limits:
nvidia.com/gpu: 1
查看日志:
kubectl logs gpu-test
如果日志中能看到类似下面的输出,说明 Pod 内已经可以正常使用 GPU:
+---------------------------------------------------------------------------------------+
| NVIDIA-SMI ... |
| Driver Version: ... |
| CUDA Version: ... |
+---------------------------------------------------------------------------------------+
测试完成后可以删除:
kubectl delete pod gpu-test
如果节点上已经识别到了 nvidia.com/gpu,但是 Pod 里执行 nvidia-smi 失败,需要重点检查 NVIDIA Container Toolkit、containerd runtime 配置、RuntimeClass/CDI 配置是否正常。
五、接入 Prometheus 并验证 DCGM Exporter 指标抓取
GPU Operator 部署完成后,会在 gpu-operator 命名空间中创建 DCGM Exporter 对应的 Service。Prometheus 后面就是通过这个 Service 去抓取 GPU 指标。
1. 查看 DCGM Exporter Service
kubectl -n gpu-operator get svc nvidia-dcgm-exporter
查看 Service 详细配置:
kubectl -n gpu-operator get svc nvidia-dcgm-exporter -o yaml
重点看 ports.name,一般是:
ports:
- name: gpu-metrics
port: 9400
targetPort: 9400
后面写 ServiceMonitor 的时候,endpoints.port 要写 Service 端口名称,也就是:
port: gpu-metrics
Prometheus Operator 的 ServiceMonitor 用来描述 Prometheus 应该如何抓取一组 Service。ServiceMonitor 会通过 label selector 选择 Service,再根据 endpoint 配置生成 Prometheus 抓取任务。Prometheus Operator 官方 API 文档中说明,ServiceMonitor CRD 用于定义 Prometheus 或 PrometheusAgent 如何从一组 Service 抓取指标,同时 Prometheus 会通过 label selector 和 namespace selector 选择 ServiceMonitor。
2. 先确认 DCGM Exporter 本身有指标
可以进入 nvidia-dcgm-exporter 容器内部测试:
kubectl -n gpu-operator exec -it <nvidia-dcgm-exporter-pod-name> -- bash
然后在容器里执行:
curl http://127.0.0.1:9400/metrics
如果能看到大量 DCGM_FI_DEV_ 开头的指标,说明 DCGM Exporter 本身正常,例如:
DCGM_FI_DEV_GPU_UTIL
DCGM_FI_DEV_FB_USED
DCGM_FI_DEV_FB_FREE
DCGM_FI_DEV_GPU_TEMP
DCGM_FI_DEV_POWER_USAGE
DCGM_FI_DEV_SM_CLOCK
DCGM_FI_DEV_MEM_CLOCK
3. 创建 ServiceMonitor
我的 Prometheus 是通过 Prometheus Operator 部署的,所以这里不直接修改 prometheus.yml,而是创建 ServiceMonitor。
创建 nvidia-dcgm-servicemonitor.yaml:
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
name: nvidia-dcgm-exporter
namespace: monitoring
labels:
app: nvidia-dcgm
spec:
endpoints:
- interval: 15s
path: /metrics
port: gpu-metrics
namespaceSelector:
matchNames:
- gpu-operator
selector:
matchLabels:
app: nvidia-dcgm-exporter
这里解释几个关键字段。
metadata.namespace: monitoring
metadata:
name: nvidia-dcgm-exporter
namespace: monitoring
这个表示 ServiceMonitor 对象创建在 monitoring 命名空间。
我的 Prometheus 也在 monitoring 命名空间,所以这样比较方便。如果你的 Prometheus 只发现当前命名空间下的 ServiceMonitor,那么 ServiceMonitor 就应该放在 Prometheus 能发现的命名空间。
可以通过下面命令查看 Prometheus 当前选择规则:
kubectl -n monitoring get prometheus -o yaml | grep -A20 -E "serviceMonitorSelector|serviceMonitorNamespaceSelector"
如果你的 Prometheus 配置了类似下面的 selector:
serviceMonitorSelector:
matchLabels:
release: kube-prometheus-stack
那 ServiceMonitor 也必须加上对应 label,例如:
metadata:
labels:
release: kube-prometheus-stack
否则 Prometheus 不会发现这个 ServiceMonitor。
namespaceSelector.matchNames: gpu-operator
spec:
namespaceSelector:
matchNames:
- gpu-operator
这个表示让这个 ServiceMonitor 去 gpu-operator 命名空间找 Service。
也就是说:
metadata:
namespace: monitoring
表示 ServiceMonitor 自己创建在哪里;
spec:
namespaceSelector:
matchNames:
- gpu-operator
表示 ServiceMonitor 要去哪个命名空间发现被监控的 Service。
这两个不是一个概念。
selector.matchLabels
selector:
matchLabels:
app: nvidia-dcgm-exporter
这个 selector 必须能匹配到 gpu-operator 命名空间里的 nvidia-dcgm-exporter Service。
可以用下面命令确认 Service 的 label:
kubectl -n gpu-operator get svc nvidia-dcgm-exporter --show-labels
如果看到类似:
app=nvidia-dcgm-exporter
那么上面的 selector.matchLabels 就是对的。
endpoints.port: gpu-metrics
endpoints:
- interval: 15s
path: /metrics
port: gpu-metrics
这里的 port 必须对应 Service 里的端口名称。可以确认一下:
kubectl -n gpu-operator get svc nvidia-dcgm-exporter -o jsonpath='{.spec.ports[*].name}'
如果输出:
gpu-metrics
那 ServiceMonitor 里就写:
port: gpu-metrics
4. 在 Prometheus 页面验证
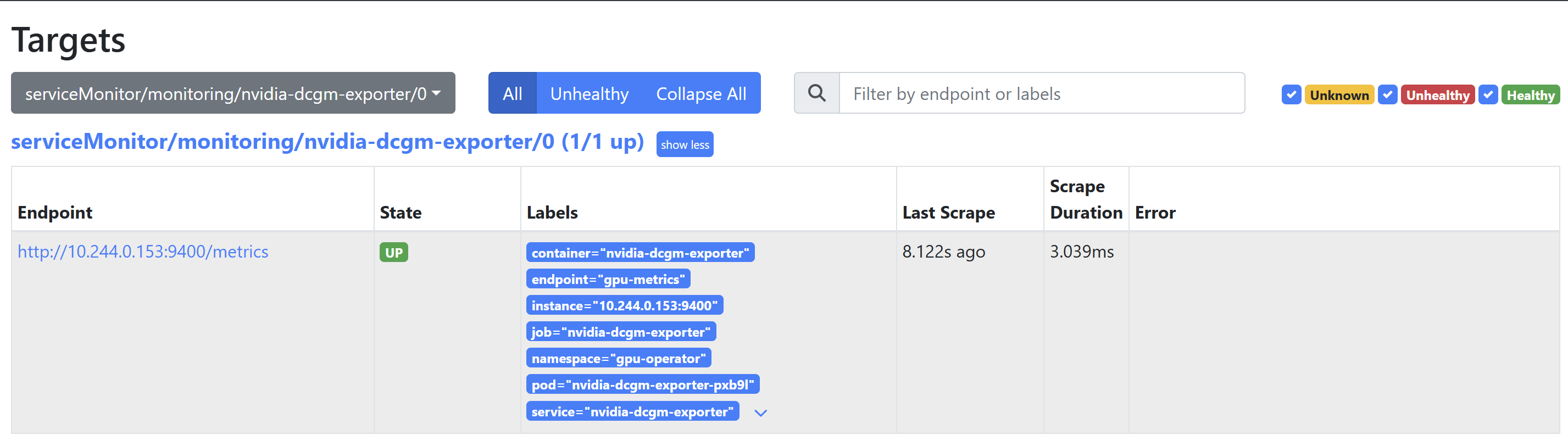
ServiceMonitor 创建后,稍等一会儿,打开 Prometheus 页面:
Status -> Targets
找到类似下面的 target:
serviceMonitor/monitoring/nvidia-dcgm-exporter/0
六、常见问题排查
1. Prometheus Targets 页面看不到 nvidia-dcgm-exporter
先确认 ServiceMonitor 是否创建成功:
kubectl -n monitoring get servicemonitor nvidia-dcgm-exporter
再确认 Prometheus 是否能选择这个 ServiceMonitor:
kubectl -n monitoring get prometheus -o yaml | grep -A20 serviceMonitorSelector
如果 Prometheus 的 serviceMonitorSelector 配置了 label 过滤,那么 ServiceMonitor 的 metadata.labels 必须匹配。
例如 Prometheus 只选择:
serviceMonitorSelector:
matchLabels:
release: kube-prometheus-stack
那 ServiceMonitor 也必须加:
metadata:
labels:
release: kube-prometheus-stack
否则 Prometheus 不会加载这个 ServiceMonitor。
2. Prometheus 日志中出现 Forbidden
如果 Prometheus 日志里有类似:
failed to list *v1.Pod: pods is forbidden
failed to list *v1.Endpoints: endpoints is forbidden
说明 Prometheus 的 ServiceAccount 没有权限读取 gpu-operator 命名空间的 Service、Endpoints、Pod 等资源。
先查看 Prometheus 使用的 ServiceAccount:
kubectl -n monitoring get prometheus -o yaml | grep serviceAccountName
假设 ServiceAccount 是:
prometheus-k8s
可以创建如下 RBAC:
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
name: prometheus-read-gpu-operator
namespace: gpu-operator
rules:
- apiGroups: [""]
resources:
- services
- endpoints
- pods
verbs:
- get
- list
- watch
- apiGroups: ["discovery.k8s.io"]
resources:
- endpointslices
verbs:
- get
- list
- watch
---
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
name: prometheus-read-gpu-operator
namespace: gpu-operator
subjects:
- kind: ServiceAccount
name: prometheus-k8s
namespace: monitoring
roleRef:
kind: Role
name: prometheus-read-gpu-operator
apiGroup: rbac.authorization.k8s.io
如果你的 Prometheus ServiceAccount 不是 prometheus-k8s,需要把上面 RoleBinding 中的 subjects.name 改成实际名称。
七、Grafana Dashboard 展示
Prometheus 已经能抓到 DCGM Exporter 指标后,就可以在 Grafana 里展示 GPU 监控面板。
Grafana 官方有现成的 NVIDIA DCGM Dashboard,例如 12219 这个 Dashboard,用于展示 Kubernetes 集群中由 DCGM Exporter 采集到的 GPU 指标。
导入步骤如下:
-
登录 Grafana
-
确认 Prometheus 数据源已经配置好
-
进入
Dashboards -
点击
New -
点击
Import -
输入 Dashboard ID,例如:
12219
或者使用其他 NVIDIA DCGM 相关 Dashboard。
-
点击
Load -
选择 Prometheus 数据源
-
点击
Import
导入完成后,可以看到 GPU 相关监控面板,例如:
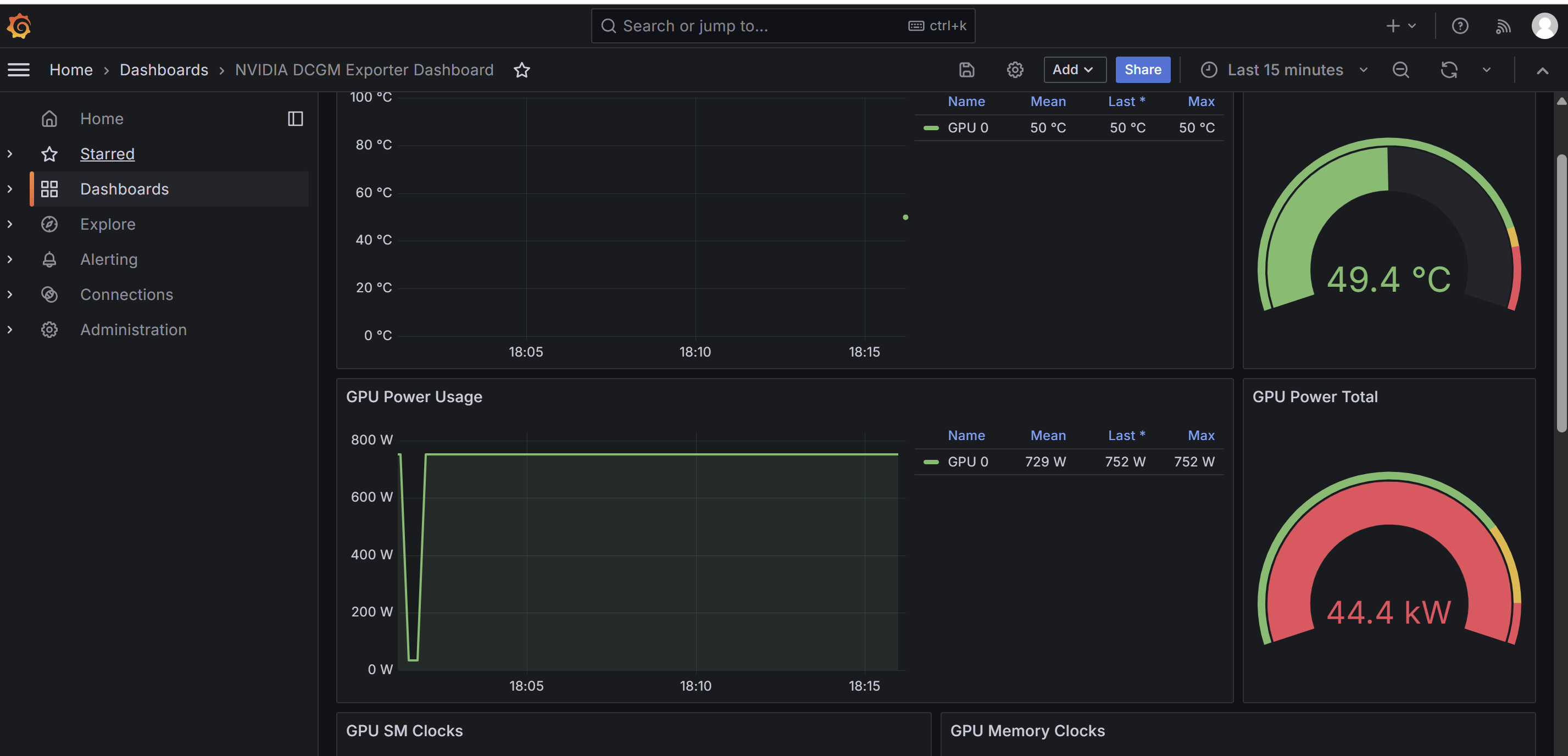
我这里导入的是 NVIDIA DCGM Exporter Dashboard,Grafana 页面中已经能看到 GPU 温度、功耗等面板,说明:
DCGM Exporter -> Prometheus -> Grafana
这条链路已经打通。
需要注意一点,不同 Dashboard 的 PromQL 写法、单位换算和聚合方式可能不完全适合所有显卡。如果某些功耗类面板出现明显不符合实际的数值,建议先回到 Prometheus 里直接查原始指标,例如:
DCGM_FI_DEV_POWER_USAGE
再结合宿主机上的 nvidia-smi 输出判断。如果 Prometheus 原始指标正常,只是 Grafana 面板显示异常,一般就是 Dashboard 的查询语句、单位或聚合方式需要调整。
八、整体链路总结
这套 GPU 监控链路可以理解为:
GPU
↓
NVIDIA Driver / DCGM
↓
DCGM Exporter
↓
Service: nvidia-dcgm-exporter
↓
ServiceMonitor
↓
Prometheus
↓
Grafana Dashboard
其中 GPU Operator 负责把 NVIDIA GPU 运行和监控所需的组件统一部署出来。部署完成后,Kubernetes 节点上会出现 nvidia.com/gpu 资源,业务 Pod 可以通过 resources.limits.nvidia.com/gpu: 1 申请 GPU。
DCGM Exporter 会暴露 GPU 监控指标,Prometheus 通过 ServiceMonitor 自动发现并抓取,最后 Grafana 导入现成的 Dashboard 做可视化展示。
本文最终验证结果如下:
Prometheus Targets:
serviceMonitor/monitoring/nvidia-dcgm-exporter/0 1/1 up
并且 Grafana 中已经可以看到 NVIDIA DCGM Exporter Dashboard 的 GPU 监控数据。到这里,GPU Operator 部署、GPU Pod 测试、Prometheus 指标接入、Grafana Dashboard 展示就都完成了。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 7
7 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)