零起点Python机器学习快速入门【1.9】
6.2 逻辑回归算法
逻辑回归算法( LogisticRegression),虽然也属于线性回归算法,但由于使用较多,我们把其作为一个独立类别,如图 6-17 所示。
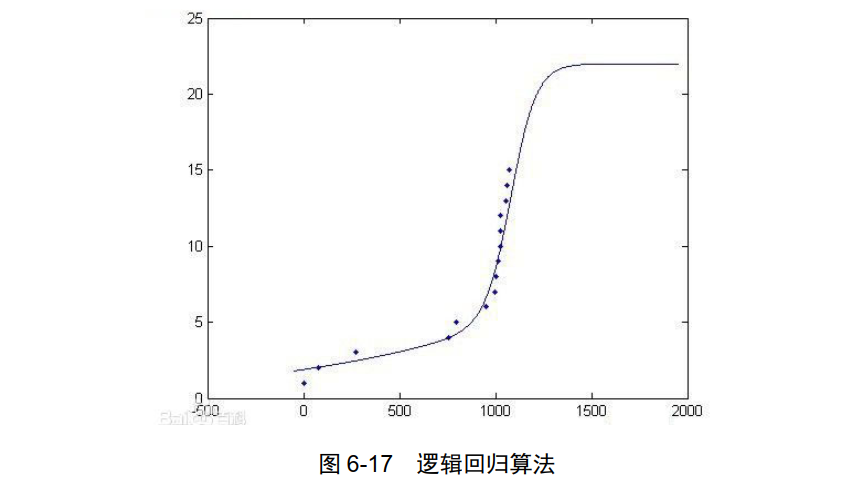
Logistic 回归又称 Logistic 回归分析,是一种广义的线性回归分析模型,常用于数据挖掘、疾病自动诊断、经济预测等领域。例如,探讨引发疾病的危险因素,并根据危险因素预测疾病发生的概率等。
逻 辑 回 归 算 法 函 数 ( LogisticRegression ) , 位 于 Sklearn 模 块 库 的linear_model 线性回归子模块,函数接口是:
LogisticRegression(penalty='l2', dual=False, tol=0.0001, C=1.0, fit_intercept=True,intercept_scaling=1,class_weight=None,random_s tate=None, solver='liblinear', max_iter=100, multi_class= 'ovr', verbose=0, warm_start=False, n_jobs=1)
案例 6-1:逻辑回归算法
案例 6-1 文件名是 zai201_mx_log.py, 下面将具体介绍逻辑回归算法的应用。
案例 6-1 是基于案例 5-4 线性回归算法,由于案例 5-4 是第一个机器学习案例,为了方便讲解,其中有不少冗余代码,案例 6-1 将其进行了优化,更加接近实盘程序。
下面我们详细讲解案例 6-1 的程序代码。
第 1 组代码,读取训练数据并保存到相关变量,复制 x_test 测试到 df9结果数据变量中:
1
fs0='dat/iris_'
print('\n1# init, fs0,',fs0)
x_train=pd.read_csv(fs0+'xtrain.csv',index_col=False);
y_train=pd.read_csv(fs0+'ytrain.csv',index_col=False);
x_test=pd.read_csv(fs0+'xtest.csv',index_col=False)
y_test=pd.read_csv(fs0+'ytest.csv',index_col=False)
df9=x_test.copy()
第 2 组代码,根据逻辑回归算法,建立机器学习模型,并保存到变
量 mx:
#2
print('\n2# 建模')
mx =zai.mx_log(x_train.values,y_train.values)在本案例中,第 2 组代码使用的是逻辑回归算法建立机器学习模型,但是并没有直接调用 Sklearn 模块库当中的 LogisticRegression 逻辑回归建模函数,而是通过 ztop_ai 极宽智能模块库的函数接口间接进行调用,对应的函数代码是:
# 逻辑回归算法,函数名, LogisticRegression
def mx_log(train_x, train_y):
mx = LogisticRegression(penalty='l2')
mx.fit(train_x, train_y)
return mx
LogisticRegression 回归函数位于 sklearn.linear_model 模块,函数接口
在前面已经介绍过了,在此不再赘述。
第 3 组代码,运行机器学习变量 mx 的内置函数 predict,生成结果数
据,并保存到结果数据变量 df9:
#3
print('\n3# 预测')
y_pred = mx.predict(x_test.values)
df9['y_predsr']=y_pred
df9['y_test'],df9['y_pred']=y_test,y_pred
df9['y_pred']=round(df9['y_predsr']).astype(int)
第 4 组代码,保存数据结果并显示相关信息:
#4
df9.to_csv('tmp/iris_9.csv',index=False)
print('\n4# df9')
print(df9.tail())
对应的输出信息是:
4# df9
x1 x2 x3 x4 y_predsr y_test y_pred
33 6.4 2.8 5.6 2.1 1 1 1
34 5.8 2.8 5.1 2.4 1 1 1
35 5.3 3.7 1.5 0.2 2 2 2
36 5.5 2.3 4.0 1.3 3 3 3
37 5.2 3.4 1.4 0.2 2 2 2
第 5 组代码,检验测试结果:
#5
dacc=zai.ai_acc_xed(df9,1,False)
print('\n5# mx:mx_sum,kok:{0:.2f}%'.format(dacc))
对应的输出信息是:
5# mx:mx_sum,kok:84.21%
84.21%的结果非常不错了,案例 5-4 线性回归的准确率只有 44.74%:
8# mx:mx_sum,kok:44.74%虽然案例 6-1 将程序进行了优化,但还是有不少冗余代码,在实盘操作时只要前面三组代码就完全足够了,而且有些命令还可以进一步精简。
6.3 朴素贝叶斯算法
学过统计学的读者一定都知道贝叶斯定理,这个 250 多年前发明的算法,在信息领域内有着无与伦比的地位。贝叶斯分类是一系列分类算法的总称,这类算法均以贝叶斯定理为基础,故统称为贝叶斯分类。
朴素贝叶斯算法( Naive Bayesian)是其中应用最为广泛的分类算法之一,该算法基于一个简单的假定:给定目标值时,属性之间相互条件独立,如图 6-18 所示。
在 Sklearn 模块库中,涉及贝叶斯原理的算法函数有很多,这里只介绍位于独立子模块 naive_bayes 中的几个相关函数:
MultinomialNB([alpha, ...]), 多项式朴素贝叶斯算法,如图 6-19 所示。
GaussianNB([priors]),高斯朴素贝叶斯算法,如图 6-20 所示。
BernoulliNB,伯努利朴素贝叶斯算法。
案例 6-2:贝叶斯算法
案例 6-2 文件名是 zai202_mx_nb.py, 介绍的是多项式朴素贝叶斯算法,函数名 MultinomialNB 位于 naive_bayes 模块,函数接口是:
MultinomialNB(alpha=1.0, fit_prior=True, class_prior=None)
案例 6-2 源码和本章其他小节的源码,基本都与案例 6-1 的源码类似,只是调用的具体的机器学习函数不同,为简化篇幅,本节及后面的章节只介绍程序代码当中不同的部分。
案例 6-2 的核心在于第 2 组代码,建模:
#2
print('\n2# 建模') mx =zai.mx_bayes(x_train.values,y_train.values)
本案例中的第 2 组代码,使用的是多项式朴素贝叶斯算法,建立机器学习模型,但是并没有直接调用 Sklearn 模块库当中的 MultinomialNB 建模函数,而是通过 ztop_ai 极宽智能模块库的函数接口间接进行调用,对应的函数代码是:
# 多 项 式 朴 素 贝 叶 斯 算 法 , Multinomial Naive Bayes , 函 数 名 ,
multinomialnb def mx_bayes(train_x, train_y): mx = MultinomialNB(alpha=0.01) mx.fit(train_x, train_y) return mx
MultinomialNB 回归函数位于 sklearn.naive_bayes 模块,函数接口我们在前面已经介绍过了,在此不再赘述。
第 4 组代码,保存数据结果并显示相关信息:
#4 df9.to_csv('tmp/iris_9.csv',index=False)
print('\n4# df9')
print(df9.tail())
对应的输出信息是:
4# df9
x1 x2 x3 x4 y_predsr y_test y_pred
33 6.4 2.8 5.6 2.1 1 1 1
34 5.8 2.8 5.1 2.4 1 1 1
35 5.3 3.7 1.5 0.2 2 2 2
36 5.5 2.3 4.0 1.3 1 3 1
37 5.2 3.4 1.4 0.2 2 2 2
第 5 组代码,检验测试结果:
#5
dacc=zai.ai_acc_xed(df9,1,False)
print('\n5# mx:mx_sum,kok:{0:.2f}%'.format(dacc))
对应的输出信息是:
5# mx:mx_sum,kok:57.89%57.89%的准确度,结果有些偏低,虽然比线性回归算法的 44.74%的结果好一点,但远远低于逻辑回归算法的 84.21%。
6.4 KNN近邻算法
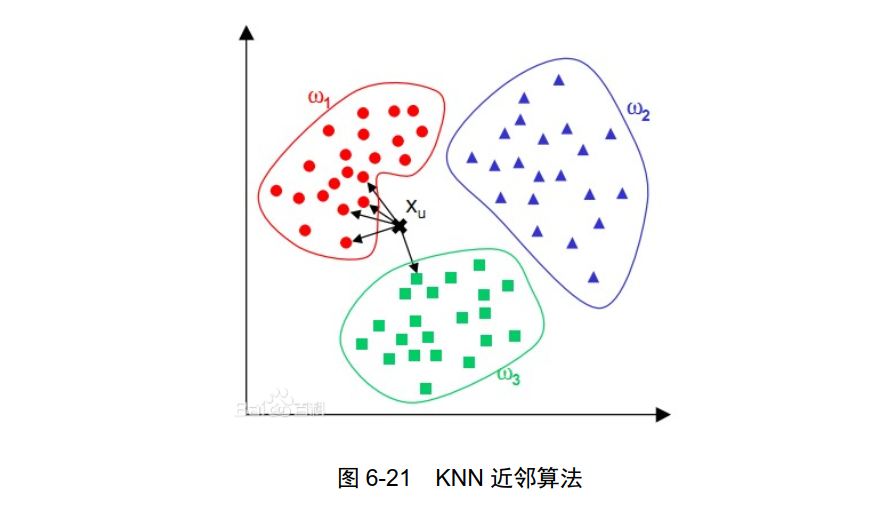
KNN 近邻算法,又叫作 K 最近邻( KNN, k-NearestNeighbor)分类算法,是数据挖掘分类技术中最简单的方法之一。所谓 K 最近邻就是 k 个最近的邻居的意思,即每个样本都可以用它最接近的 k 个邻居来代表,如图 6-21 所示。
在 Sklearn 模块库中, KNN 近邻算法相关的算法函数位于 Neighbors 模块库,主要的机器学习算法函数如下。
KNeighborsClassifier: KNN 近邻算法,如图 6-22 所示。
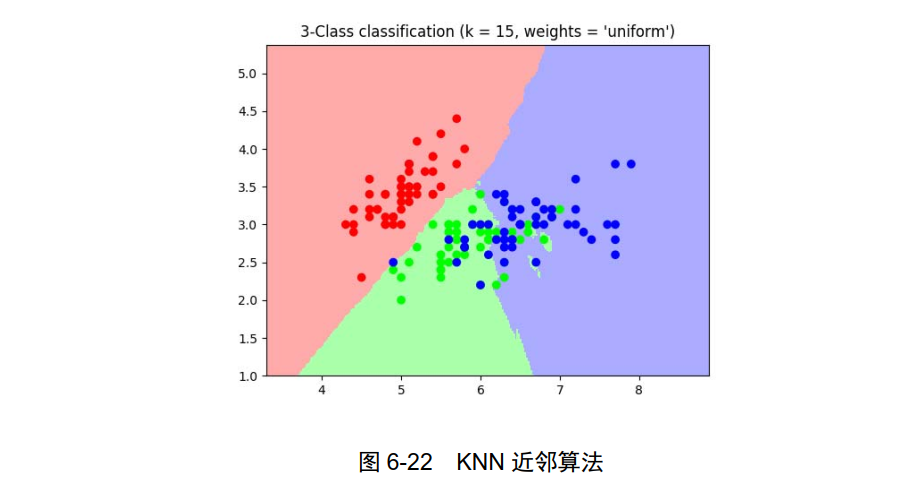
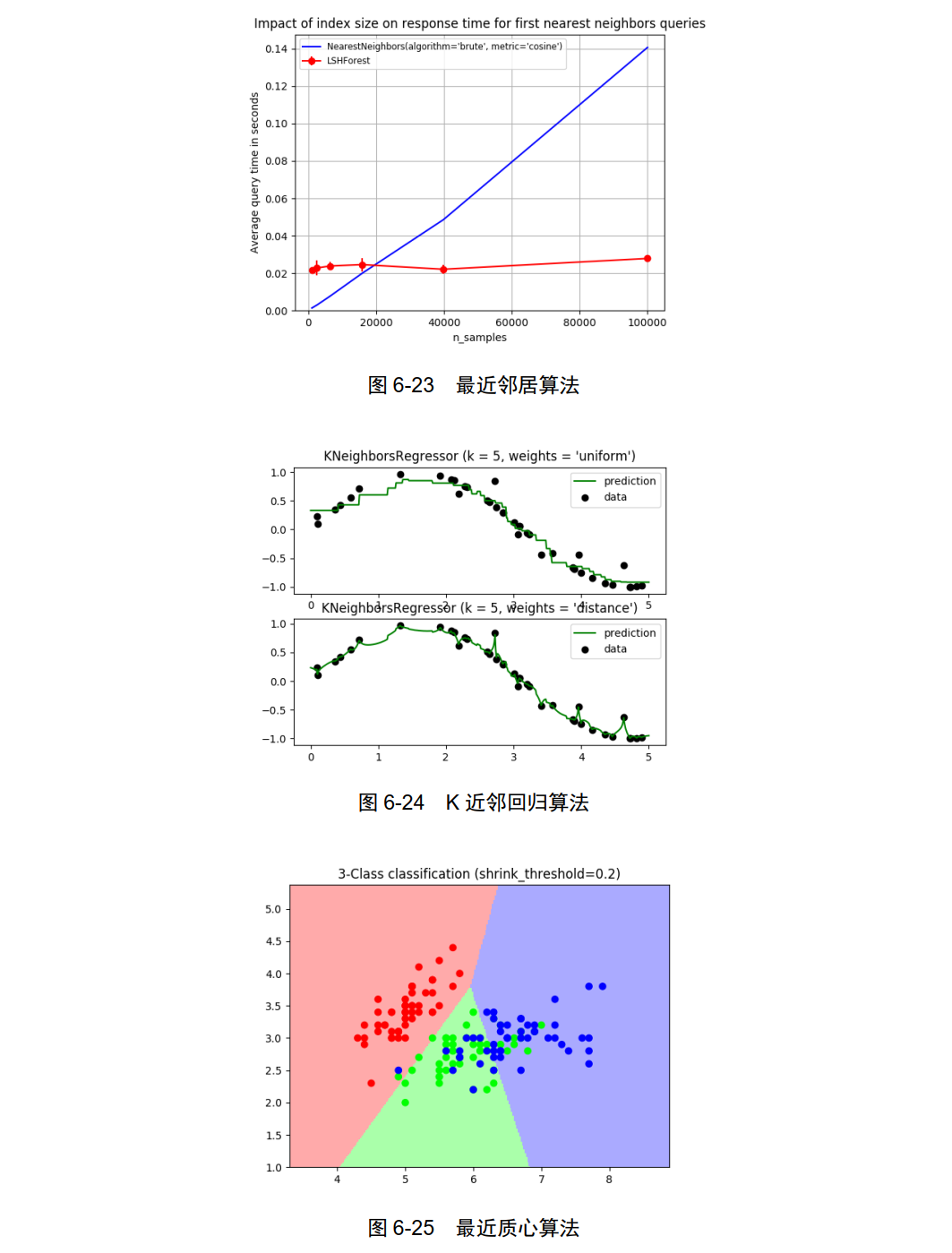
NearestNeighbors:最近邻居算法,如图 6-23 所示。
KNeighborsRegressor: K 近邻回归算法,如图 6-24 所示。
NearestCentroid:最近质心算法,如图 6-25 所示。
LSHForest( Locality Sensitive Hashing forest, LSH):局部敏感哈希森林算法,是最近邻搜索方法的代替,排序实现二进制搜索和 32 位定长数组和散列,使用 Hash 家族的随机投影方法,近似余弦距离,如图 6-26 所示。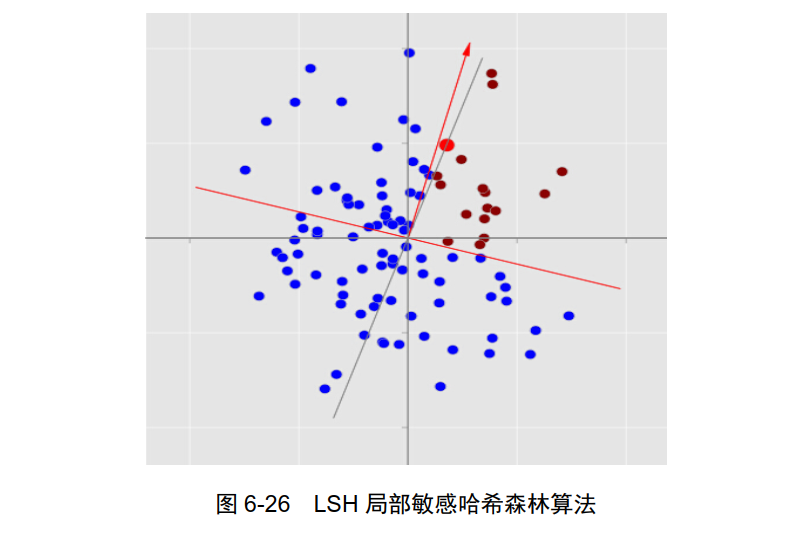
案例 6-3: KNN近邻算法
案例 6-3 文件名是 zai203_mx_knn.py,介绍的是 KNN 近邻算法,位于Neighbors 模块,函数名是 KNeighborsClassifier,函数接口是:
KNeighborsClassifier(n_neighbors=5,weights='uniform',algorith
m='auto', leaf_size=30, p=2, metric='minkowski', metric_params=None,
n_jobs=1, **kwargs)
案例 6-3 的核心在于第 2 组代码,建模:
#2
print('\n2# 建模')
mx =zai.mx_knn(x_train.values,y_train.values)在案例中,第 2 组代码使用的是 KNN 近邻算法,建立机器学习模型,但是并没有直接调用 Sklearn 模块库当中的 KNeighborsClassifier 函数,而是通过 ztop_ai 极宽智能模块库的函数接口间接进行调用,对应的函数代码是:
# KNN 近邻算法,函数名, KNeighborsClassifier
def mx_knn(train_x, train_y):
mx = KNeighborsClassifier()
mx.fit(train_x, train_y)
return mx
KNN 近邻算法,位于 sklearn.neighbors 模块,函数接口我们在前面已
经介绍过了,在此不再赘述。
第 4 组代码,保存数据结果并显示相关信息:
#4
df9.to_csv('tmp/iris_9.csv',index=False)
print('\n4# df9')
print(df9.tail())
对应的输出信息是:
4# df9
x1 x2 x3 x4 y_predsr y_test y_pred
33 6.4 2.8 5.6 2.1 1 1 1
34 5.8 2.8 5.1 2.4 1 1 1
35 5.3 3.7 1.5 0.2 2 2 2
36 5.5 2.3 4.0 1.3 3 3 3
37 5.2 3.4 1.4 0.2 2 2 2
第 5 组代码,检验测试结果:
#5
dacc=zai.ai_acc_xed(df9,1,False)
print('\n5# mx:mx_sum,kok:{0:.2f}%'.format(dacc))
对应的输出信息是:
5# mx:mx_sum,kok:100.00%这个结果居然是 100%, 全垒打,不过大家不要高兴得太早,这个 100%只是基于爱丽丝 Iris 数据集的,数据量有些偏低,不一定有普适性。
不管如何,这个案例也是大家学习人工智能、机器学习算法的第一个100%准确率的程序,第一个全垒打程序,还是值得庆祝一下的。
6.5 随机森林算法
随机森林算法( Random forest),是指利用多棵树对样本进行训练并预测的一种算法,如图 6-27 所示。随机森林这个术语,是由 1995 年贝尔实验室的 Tin Kam Ho 所提出的随机决策森林( Random Decision Forests)理论发展而来的。后来, Leo Breiman 和 Adele Cutler 推论出了随机森林的算法,并注册了 Random Forests 商标。
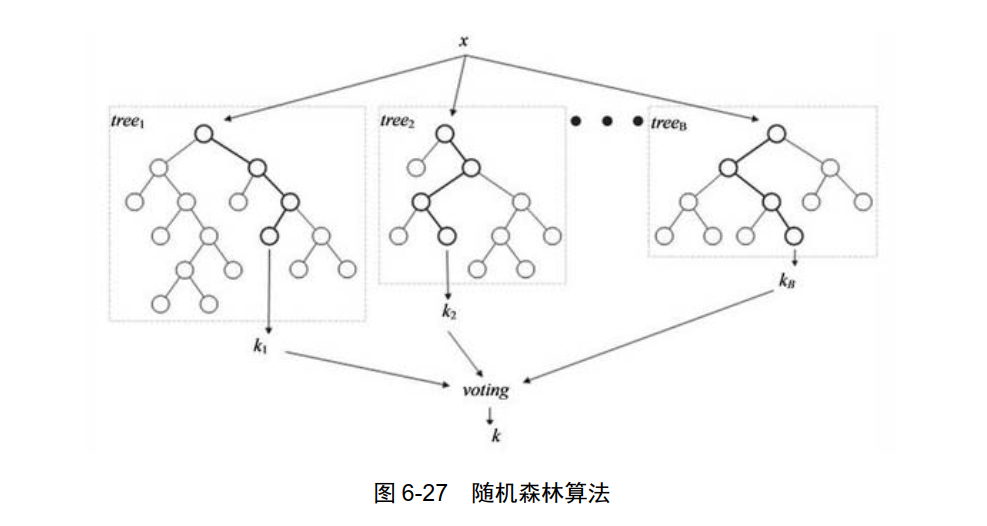
随机森林算法是一个包含多个决策树的算法,并且其输出的类别是由个别树输出的类别的众数而定,这个算法结合了 Breimans 的“ Bootstrap Aggregating”想法和 Tin Kam Ho 的“ Random Subspace Method”算法,以建造决策树的集合。
在 Sklearn 模块库中, Random Forest 随机森林算法相关的算法函数,位于集成算法模块 Ensemble 中,其中相关的机器学习算法函数如下。
RandomForestClassifier:随机森林算法,如图 6-28 所示。
BaggingClassifier: Bagging 装袋算法,相当于多个专家投票表决,对于多次测试,每个样本返回的是多次预测结果较多的那个,如图 6-29所示。
ExtraTreesClassifier:完全随机树算法,如图 6-30 所示。
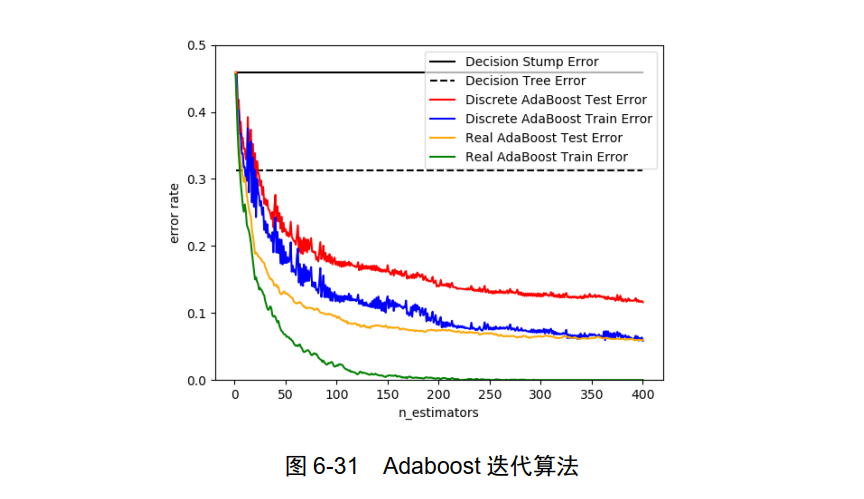
Adaboost:迭代算法,其核心思想是针对同一个训练集,训练不同的分类器(弱分类器),然后把这些弱分类器集合起来,构成一个更强的最终分类器(强分类器),如图 6-31 所示。
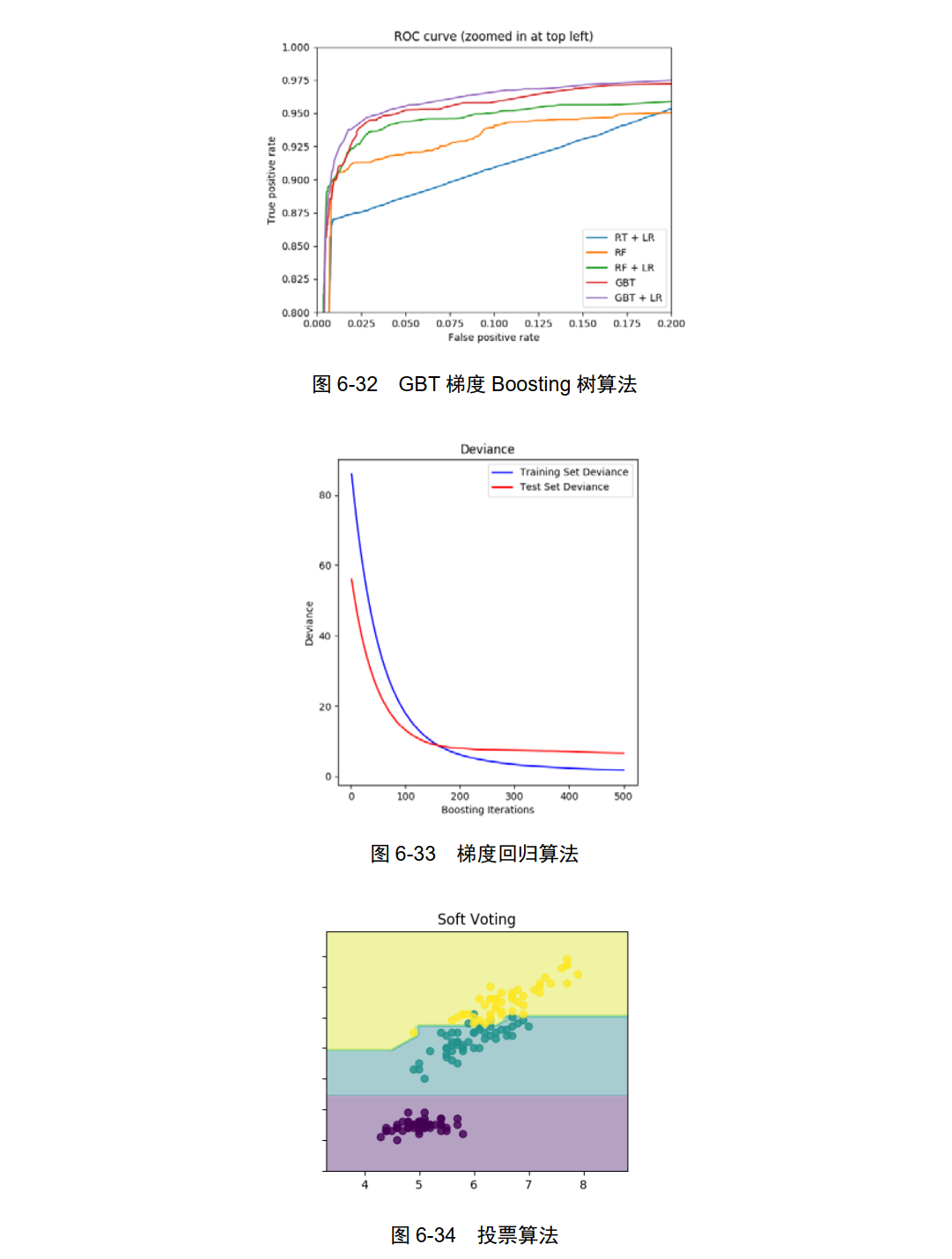
GradientBoostingClassifier: GBT 梯度 Boosting 树算法,如图 6-32所示。
GradientBoostingRegressor:梯度回归算法,如图 6-33 所示。
VotingClassifier:投票算法,如图 6-34 所示。
案例 6-4 文件名是 zai204_mx_rf.py,介绍的是随机森林算法,位于
Ensemble 集成算法模块,函数名是 KNeighborsClassifier,函数接口是:
RandomForestClassifier(n_estimators=10, criterion='gini', max_
depth=None, min_samples_split=2, min_samples_leaf=1, min_weight_
fraction_leaf=0.0, max_features='auto', max_leaf_nodes=None, min_
impurity_split=1e-07,bootstrap=True,oob_score=False,n_jobs=1,rand
om_state=None, verbose=0, warm_start=False, class_weight=None)
案例 6-4 的核心在于第 2 组代码,建模:
#2
print('\n2# 建模')
mx =zai.mx_forest (x_train.values,y_train.values)
在本案例中,第 2 组代码使用的是随机森林算法建立机器学习模型,
但是并没有直接调用 Sklearn 模块库当中的 RandomForestClassifier 函数,
而是通过 ztop_ai 极宽智能模块库的函数接口间接进行调用,对应的函数
代码是:
# 随机森林算法, Random Forest Classifier, 函数名,
RandomForestClassifier
def mx_forest(train_x, train_y):
mx = RandomForestClassifier(n_estimators=8)
mx.fit(train_x, train_y)
return mx
随机森林算法位于 sklearn.ensemble 集成算法模块,函数接口我们在前
面已经介绍过了,在此不再赘述。
第 4 组代码,保存数据结果并显示相关信息:
#4
df9.to_csv('tmp/iris_9.csv',index=False)
print('\n4# df9')
print(df9.tail())
对应的输出信息是:
4# df9
x1 x2 x3 x4 y_predsr y_test y_pred
33 6.4 2.8 5.6 2.1 1 1 1
34 5.8 2.8 5.1 2.4 1 1 1
35 5.3 3.7 1.5 0.2 2 2 2
36 5.5 2.3 4.0 1.3 3 3 3
37 5.2 3.4 1.4 0.2 2 2 2
第 5 组代码,检验测试结果:
#5
dacc=zai.ai_acc_xed(df9,1,False)
print('\n5# mx:mx_sum,kok:{0:.2f}%'.format(dacc))
对应的输出信息是:
5# mx:mx_sum,kok:97.37%
结果是 97.37%,这已经非常好了,虽然不是 100%的全垒打,不过作
为预测模型,这种精度比 100%给大家的感觉更加心安。
AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 7
7 0
0- 0



 已为社区贡献22条内容
已为社区贡献22条内容

所有评论(0)