零起点Python机器学习快速入门【1.8】
5.5 案例源码
本章包括以下案例程序。
案例 5-1: Iris 爱丽丝,文件名是 zai101_iris01.py。
案例 5-2:爱丽丝进化与矢量化文本,文件名是 zai102_iris02.py。
案例 5-3: Iris 爱丽丝分解,文件名是 zai103_iris03.py。
案例 5-4:线性回归算法,文件名是 zai104_iris04.py。
案例 5-1: Iris爱丽丝
文件名是 zai101_iris01.py,源码如下。
#coding=utf-8
'''
Created on 2016.12.25
TopQuant-极宽量化系统·培训课件-配套教学 Python 程序
@ www.TopQuant.vip www.ziwang.com
'''
import pandas as pd
#-----------------------
#1
fss='dat/iris.csv'
df=pd.read_csv(fss,index_col=False)
print('\n#1 df')
print(df.tail())
print(df.describe())
#2
d10=df['xname'].value_counts()
print('\n#2 xname')
print(d10)
#-----------------------
print('\nok!')案例 5-2:爱丽丝进化与文本矢量化
文件名是 zai102_iris02.py,源码如下。
#coding=utf-8
'''
Created on 2016.12.25
TopQuant-极宽量化系统·培训课件-配套教学 Python 程序
@ www.TopQuant.vip www.ziwang.com
'''
import pandas as pd
#-----------------------
#1
fss='dat/iris.csv'
df=pd.read_csv(fss,index_col=False)
#2
df.loc[df['xname']=='virginica', 'xid'] = 1
df.loc[df['xname']=='setosa', 'xid'] = 2
df.loc[df['xname']=='versicolor', 'xid'] = 3
df['xid']=df['xid'].astype(int)
df.to_csv('tmp/iris2.csv',index=False)
#3
print('\n3#df')
print(df.tail())
print(df.describe())
#4
d10=df['xname'].value_counts()
print('\n4#xname')
print(d10)
#5
d10=df['xid'].value_counts()
print('\n5#xid')
print(d10)
#-----------------------
print('\nok!')
案例 5-3: Iris爱丽丝分解
文件名是 zai103_iris03.py,源码如下。
#coding=utf-8
'''
Created on 2016.12.25
TopQuant-极宽量化系统·培训课件-配套教学 Python 程序
@ www.TopQuant.vip www.ziwang.com
'''
import pandas as pd
#
import sklearn
from sklearn.cross_validation import train_test_split
#
#-----------------------
#1
fss='dat/iris2.csv'
df=pd.read_csv(fss,index_col=False)
#2
print('\n2# df')
print(df.tail())
#3
xlst,ysgn=['x1','x2','x3','x4'],'xid'
x,y= df[xlst],df[ysgn]
#
print('\n3# xlst,',xlst)
print('ysgn,',ysgn)
print('x')
print(x.tail())
print('y')
print(y.tail())
#4
x_train, x_test, y_train, y_test = train_test_split(x, y,
random_state=1)
x_test.index.name,y_test.index.name='xid','xid'
print('\n4# type')
print('type(x_train),',type(x_train))
print('type(x_test),',type(x_test))
print('type(y_train),',type(y_train))
print('type(y_test),',type(y_test))
#5
fs0='tmp/iris_'
print('\n5# fs0,',fs0)
x_train.to_csv(fs0+'xtrain.csv',index=False);
x_test.to_csv(fs0+'xtest.csv',index=False)
y_train.to_csv(fs0+'ytrain.csv',index=False,header=True)
y_test.to_csv(fs0+'ytest.csv',index=False,header=True)
#6
print('\n6# x_train')
print(x_train.tail())
print('\nx_test')
print(x_test.tail())
#7
print('\n7# y_train')
print(y_train.tail())
print('\ny_test')
print(y_test.tail())
#-----------------------
print('\nok!')案例 5-4:线性回归算法
文件名是 zai104_iris04.py,源码如下。
#coding=utf-8
'''
Created on 2016.12.25
TopQuant-极宽量化系统·培训课件-配套教学 Python 程序
@ www.TopQuant.vip www.ziwang.com
'''
import pandas as pd
#
import sklearn
from sklearn import datasets, linear_model
from sklearn.cross_validation import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn import metrics
from sklearn.model_selection import cross_val_predict
#
import zsys
import ztools as zt
import ztools_str as zstr
import ztools_web as zweb
import ztools_data as zdat
import ztop_ai as zai
import zpd_talib as zta
#
#-----------------------
#1
fs0='dat/iris_'
print('\n1# fs0,',fs0)
x_train=pd.read_csv(fs0+'xtrain.csv',index_col=False);
y_train=pd.read_csv(fs0+'ytrain.csv',index_col=False);
#2
print('\n2# train')
print(x_train.tail())
print(y_train.tail())
#3
print('\n3# 建模')
mx =zai.mx_line(x_train.values,y_train.values)
#4
x_test=pd.read_csv(fs0+'xtest.csv',index_col=False)
df9=x_test.copy()
print('\n4# x_test')
print(x_test.tail())
#5
print('\n5# 预测')
y_pred = mx.predict(x_test.values)
df9['y_predsr']=y_pred
#6
y_test=pd.read_csv(fs0+'ytest.csv',index_col=False)
print('\n6# y_test')
print(y_test.tail())
#7
df9['y_test'],df9['y_pred']=y_test,y_pred
df9['y_pred']=round(df9['y_predsr']).astype(int)
df9.to_csv('tmp/iris_9.csv',index=False)
print('\n7# df9')
print(df9.tail())
#
#8
dacc=zai.ai_acc_xed(df9,1,False)
print('\n8# mx:mx_sum,kok:{0:.2f}%'.format(dacc))
#-----------------------
print('\nok!')第 6 章 机器学习经典算法案例(上)
前面我们说过, Sklearn 中常用的经典机器学习算法有:线性回归算法、朴素贝叶斯算法、 kNN 近邻算法、逻辑回归算法、随机森林算法、决策树算法、 GBDT 迭代决策树算法、 SVM 向量机算法和 SVM-cross 向量机交叉算法。
在第 5 章我们已经学习过线性回归算法,本章将通过具体的案例,逐一学习相关的人工智能、机器学习经典算法。
需要注意的是,虽然本书和有关文档经常将 Sklearn 中相关的机器学习算法称之为“ xx 机器学习函数”,但其定义都是 class 类,大家要记住这点。
6.1 线性回归
在 Sklearn 模块库中有多种不同的线性回归函数,都位于 Linear_model模块中,函数名分别如下。
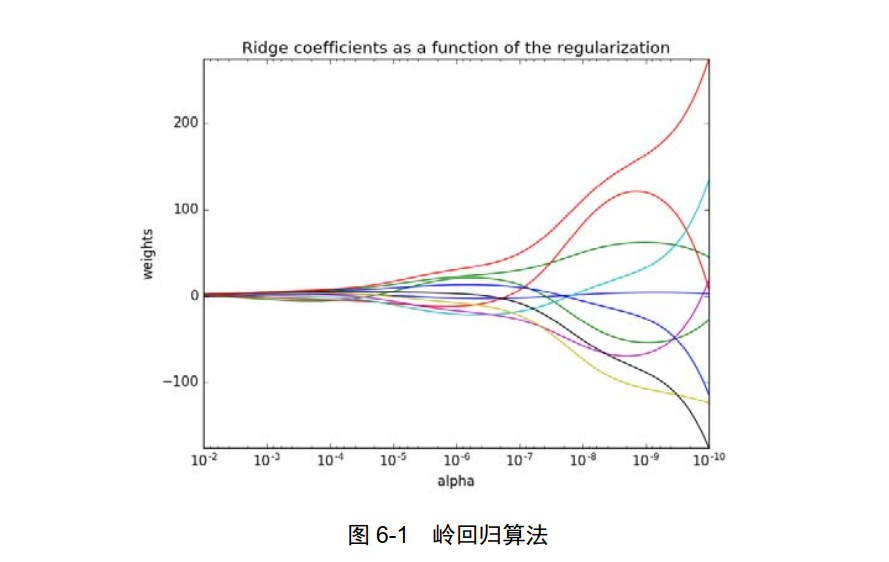
Ridge:岭回归算法,如图 6-1 所示。
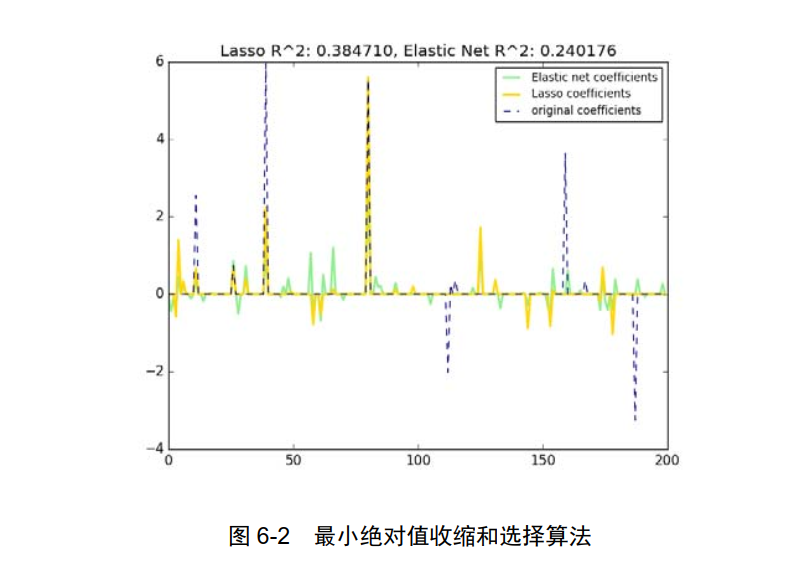
LASSO( Least Absolute Shrinkage and Selection Operator):最小绝对值收缩和选择算法,俗称套索算法,如图 6-2 所示。
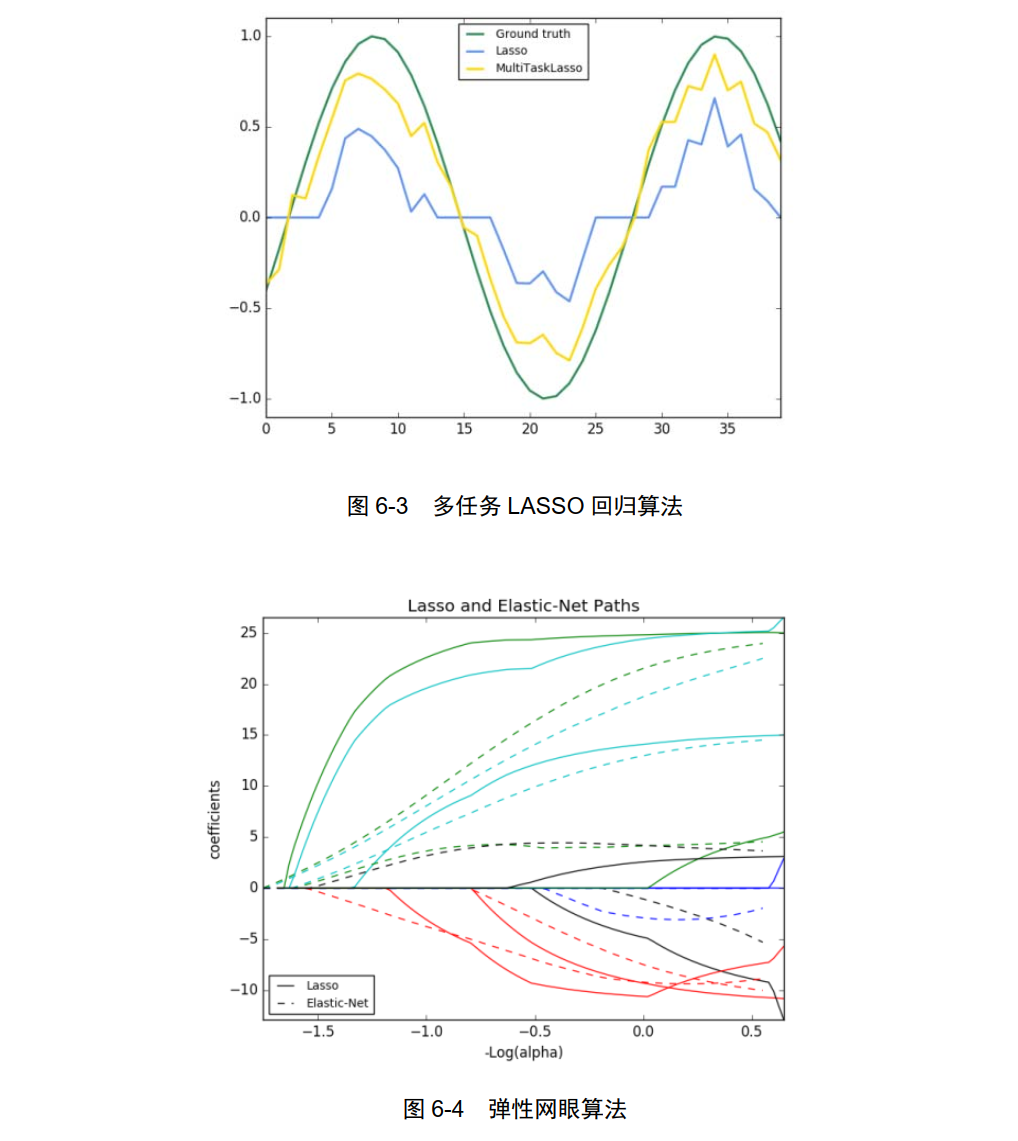
MultiTaskLasso:多任务 LASSO 回归算法,如图 6-3 所示。
ElasticNet:弹性网眼算法,如图 6-4 所示。
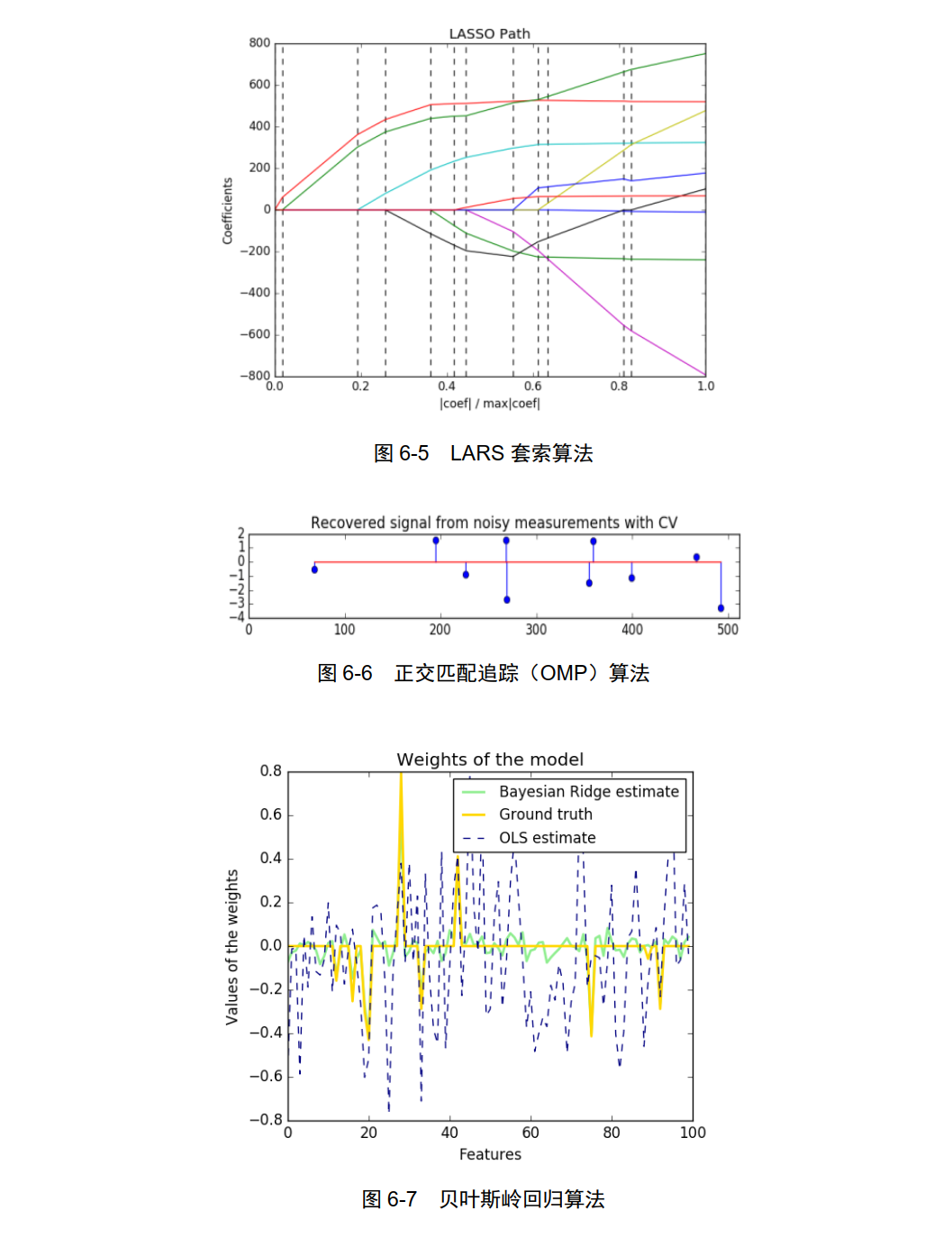
LassoLars: LARS 套索算法,如图 6-5 所示。
OrthogonalMatchingPursuit:正交匹配追踪( OMP)算法,如图 6-6所示。
BayesianRidge:贝叶斯岭回归算法,如图 6-7 所示。
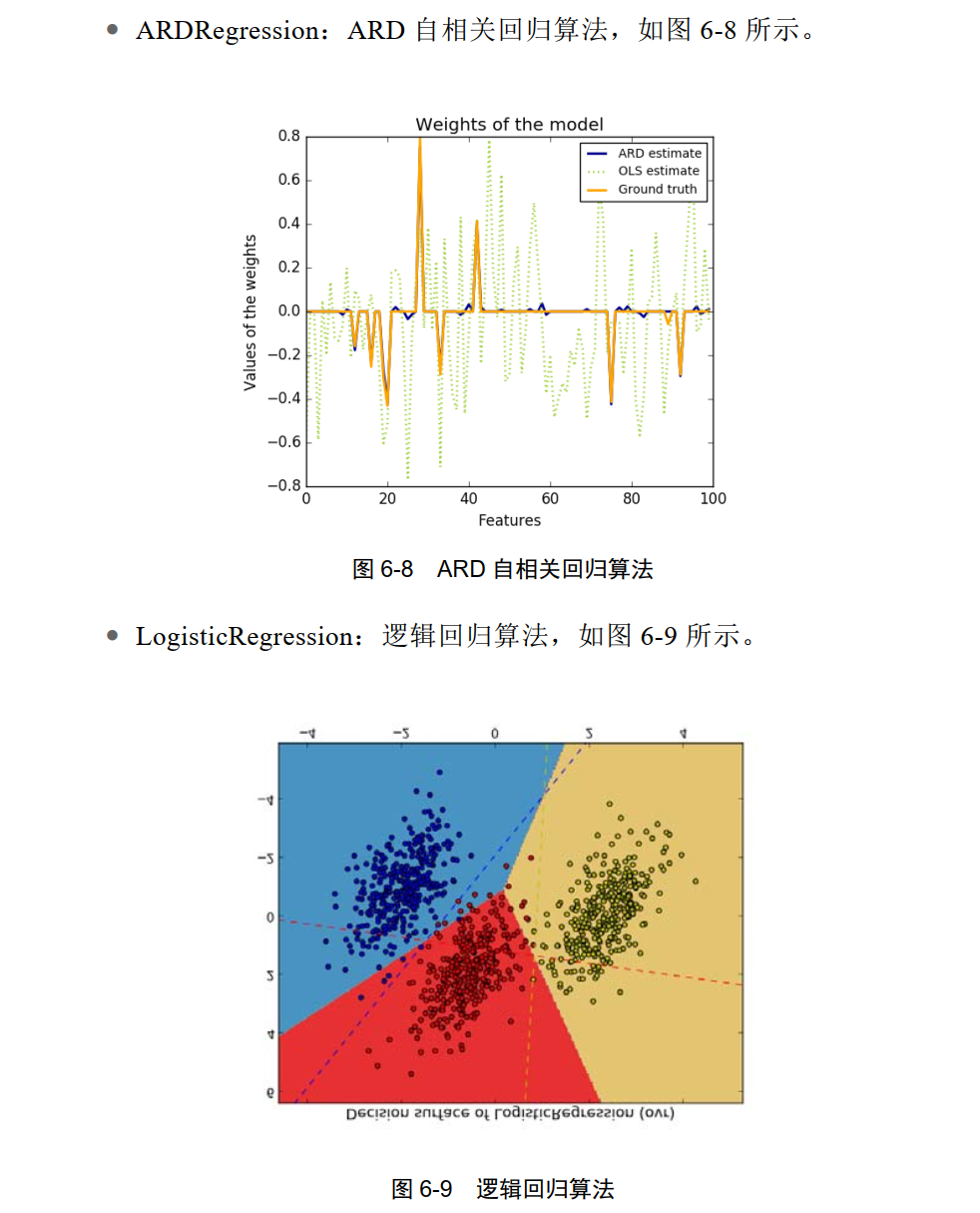
SGDClassifier: SGD 随机梯度下降算法,如图 6-10 所示。
MultiTaskElasticNet:多任务弹性网眼算法。
LARS:最小角回归算法。
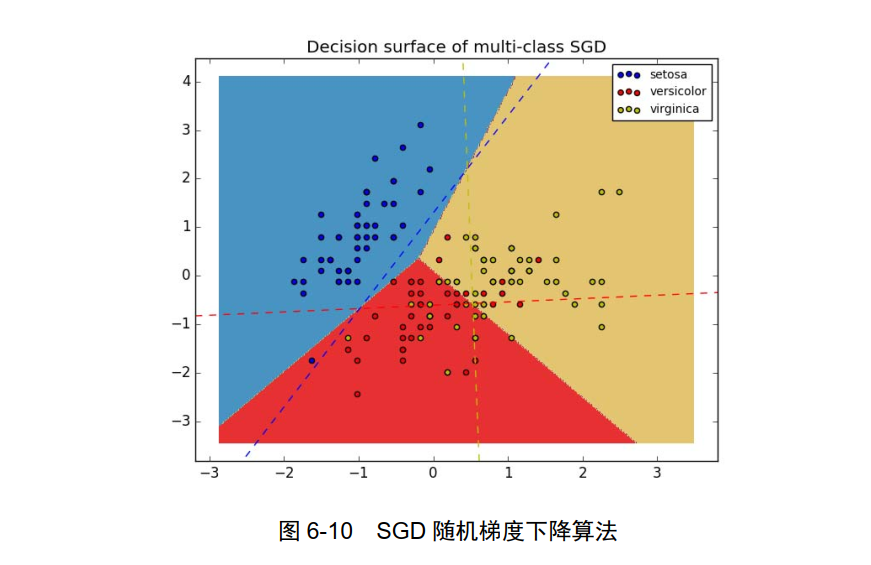
Perceptron:感知器算法,如图 6-11 所示。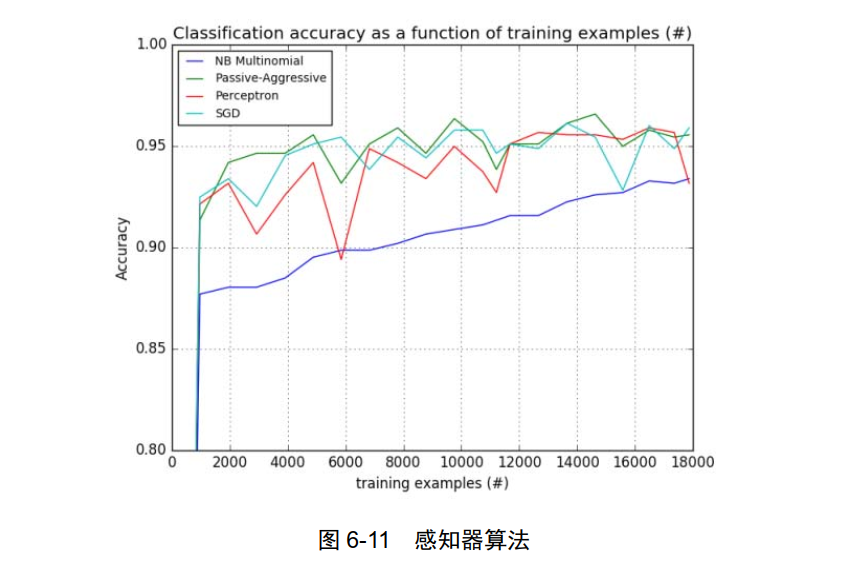
PassiveAggressiveClassifier: PA 被动感知算法,如图 6-12 所示。
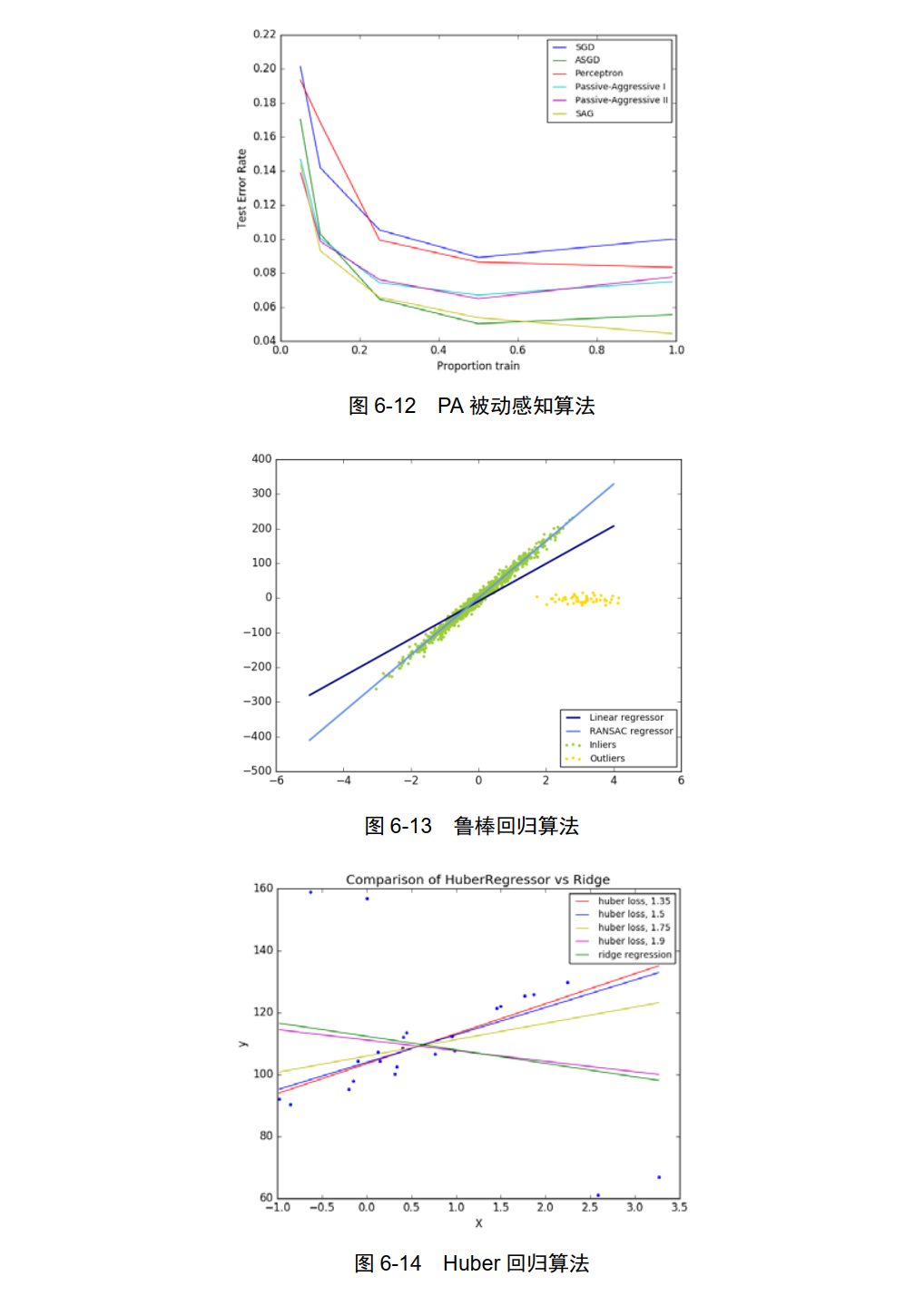
RANSACRegressor:鲁棒回归算法,如图 6-13 所示。
HuberRegressor: Huber 回归算法,如图 6-14 所示。
TheilSenRegressor: Theil-Sen 回归算法,如图 6-15 所示。
PolynomialFeatures:多项式函数回归算法,如图 6-16 所示。
LinearRegression:最小二乘法线性回归算法。
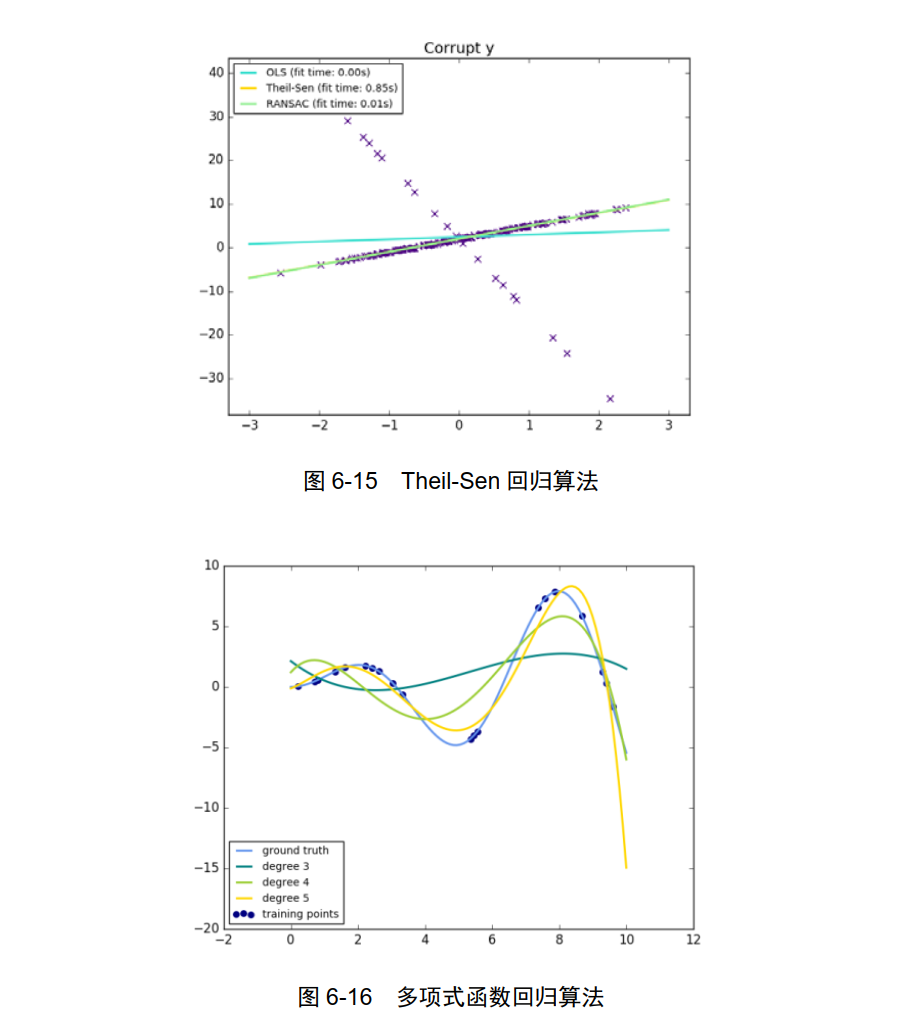
这些只是 Skearn0.18 版本的 linear_model 模块当中,所包括的机器学习的主要算法函数,关于以上函数需要注意的是:
LogisticRegression(逻辑回归算法),虽然也属于线性回归算法,但由于用的较多,所以我们把其作为一个独立类别。
ElasticNet(弹性网眼算法),对弹性神经网络进行分析,是一个改进型的弹性网络算法。
LASSO 算法与岭回归函数和 LARS 算法很类似。 LASSO 算法与岭回归函数都是通过增加惩罚函数来判断、消除特征间的共线性。LASSO 算法与 LARS 算法都可以用作参数选择,得出一个相关系数的稀疏向量。
Sklearn 项目官方网站,有大量的人工智能、机器学习专业文档和源码可以下载,网址是: http://scikit-learn.org。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 9
9 0
0- 0



 已为社区贡献22条内容
已为社区贡献22条内容

所有评论(0)