山东大学项目实训个人纪实(3)——UI概念设计和语音合成调研
在完成了前期的框架搭建与接口集成后,这一周我们把工作的重心放到了系统“交互体验”的打磨上,主要开展了UI概念草图的设计以及语音合成(TTS)的方案调研。
首先是UI概念草图的设计。我们希望整个交互界面在功能完善的同时,也能保持视觉上的整洁与直观,为此分别对三个核心页面进行了规划:
-
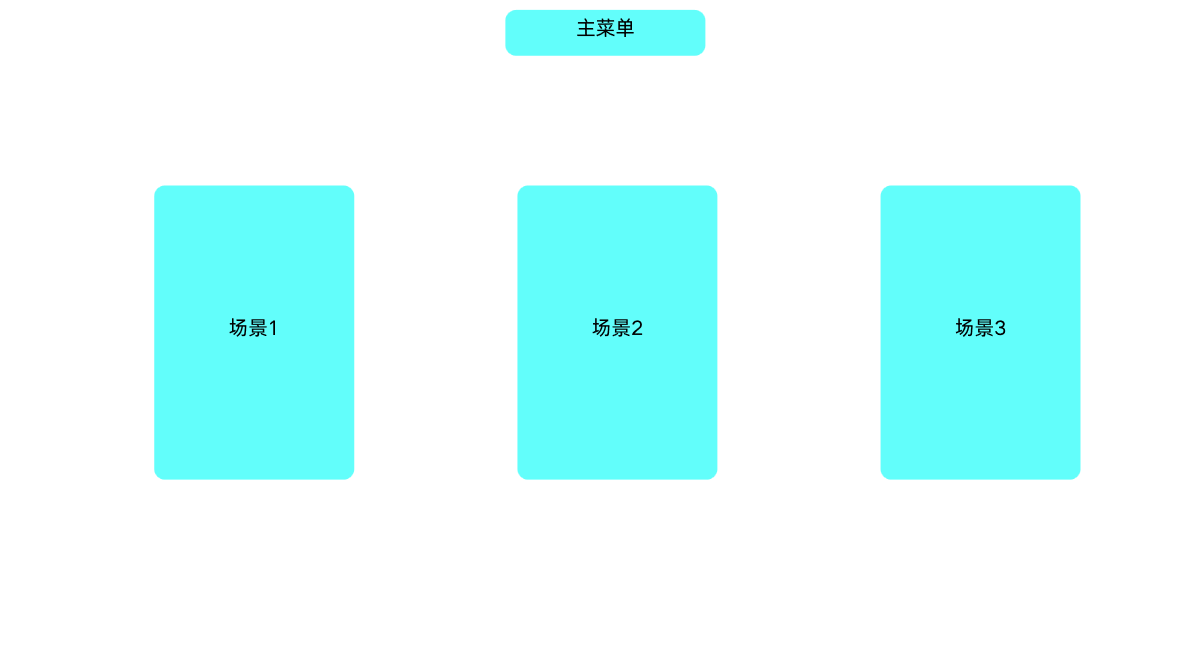
主菜单页面:设计得相对精简,主要提供场景切换功能,方便使用者选择并进入对应的虚拟诊疗环境。
-
主场景页面(问诊过程):
-
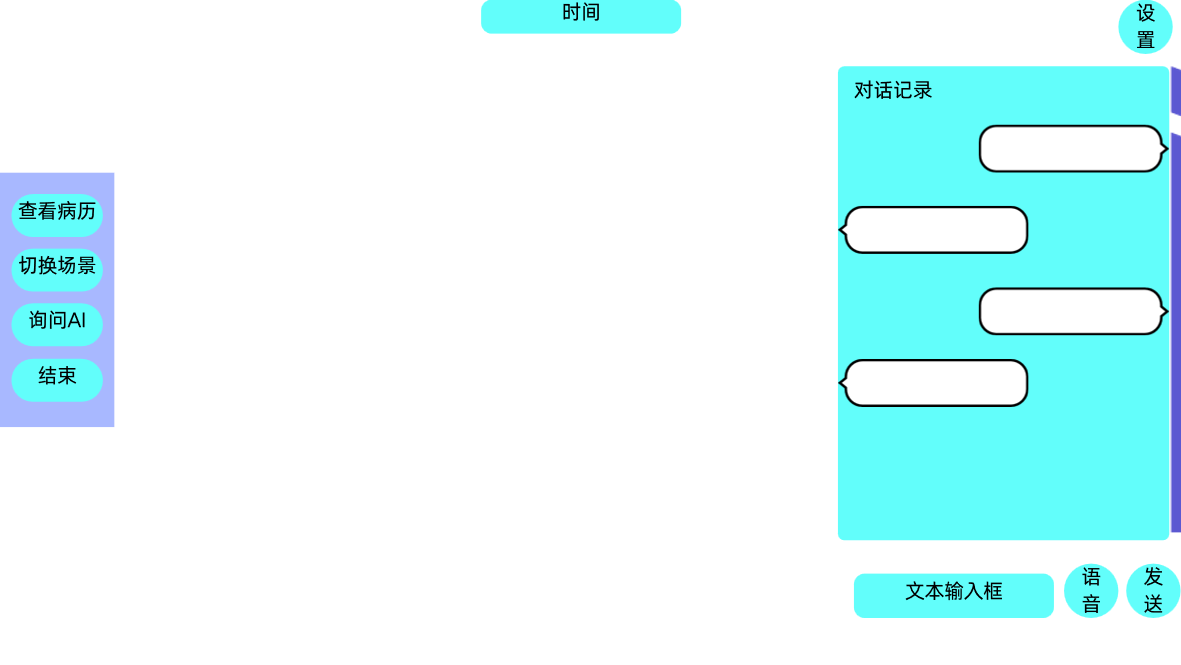
顶部时间显示:用于实时展示当前对话的用时,帮助使用者掌控沟通节奏。
-
左侧隐藏式工具栏:正常情况下处于隐藏状态,鼠标悬停时才会显示,以减少视觉干扰。里面集成了查看病例、切换场景、询问AI(点击后右侧对话框会临时切换为AI导师的建议,指导下一步该如何提问)以及触发结束的评分按钮。
-
右侧对话区域:作为交互的核心板块,包含历史对话记录、文本输入、语音输入以及发送按钮,支持双重输入方式。
-
设置面板:提供音量调节、返回病房以及返回主菜单等基础控制功能。
-
-
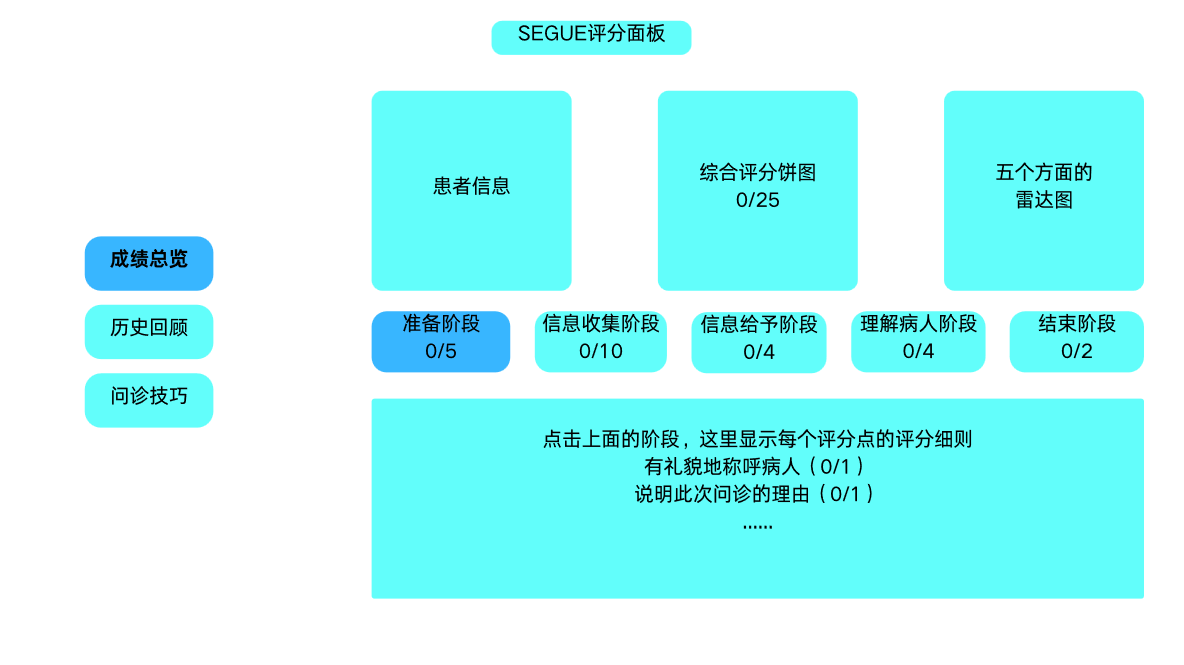
SEGUE评分页面:作为系统的核心反馈环节,我们反复推敲了其信息呈现方式,最终决定划分出三个子板块:
-
成绩总览:呈现患者基本信息、综合得分比例饼图,以及展示五个沟通维度的雷达图,便于使用者直观地看出自己的优缺点。
-
历史回顾:梳理并展示每一轮对话的详细文本及对应的得分情况。
-
问诊技巧分析:基于SEGUE评价体系的五个阶段,列出详细得分、评分证据以及AI生成的针对性评语。
-
画好这些草图后,我们下一步的任务就是分工合作——前端同学负责将草图在UE5中落地并编写HUD的切换逻辑,而我则需要在后端提供对应的API接口,确保真实的动态数据能够准确渲染到界面中。
除了UI设计,这周的另一个突破点是语音合成(TTS)的调研。
为了让虚拟患者的声音更加贴合其病症和人物设定,我们尝试使用了阿里云百炼大模型的语音设计功能。通过在平台上编写Prompt来调试、设计具有特定情绪和质感的虚拟音色,并在后端调用对应的语音合成接口,将大模型输出的文本转化为动态音频文件。目前,这一方案已经完成了后台接口的查询与集成调试。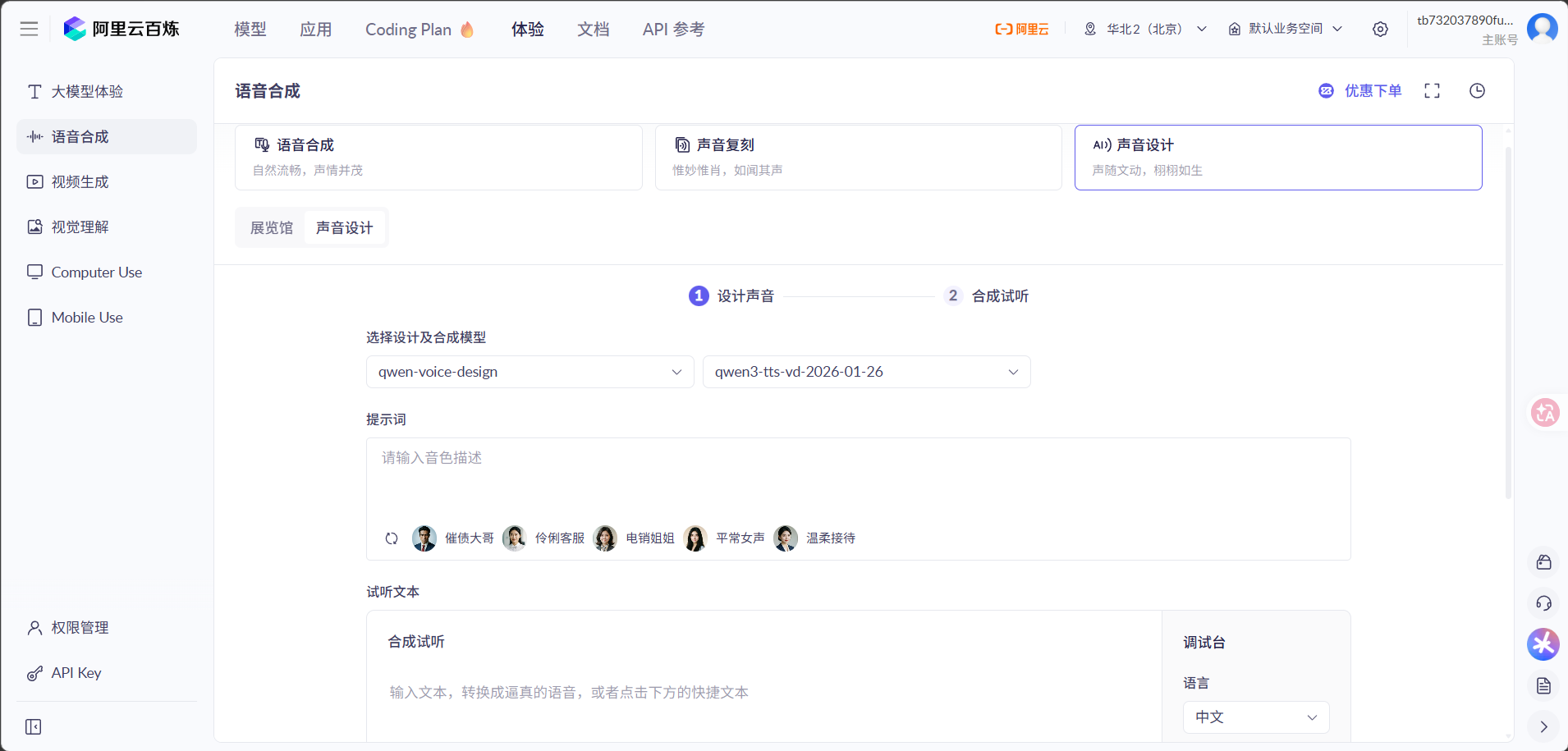
从概念草图绘制到音色设计,虽然许多细节目前还停留在原型和接口联调阶段,但看着系统框架一点点被内容填补,确实让人感到踏实。接下来,我们需要抓紧时间在UE5中把这些设计还原出来,让整个系统真正变得“看”得到、“听”得见。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 3
3 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)