Claude Code 深度拆解:执行机制 + 实际工作流融合指南
Claude Code 深度拆解:执行机制 + 实际工作流融合指南
最近把 Claude Code 接入了日常开发,顺手把踩过的坑和理解到的东西整理成这篇文章。不是官方文档的翻译,是真实使用后的理解。
一、Claude Code 到底在做什么?
很多人第一次用 Claude Code 会有一种感觉:它"好像在自己思考"。它会自己读文件、自己跑命令、自己修代码,然后告诉你做了什么。
这背后的执行机制其实是一个 Agent 循环,理解这个循环,你才能真正驾驭它。
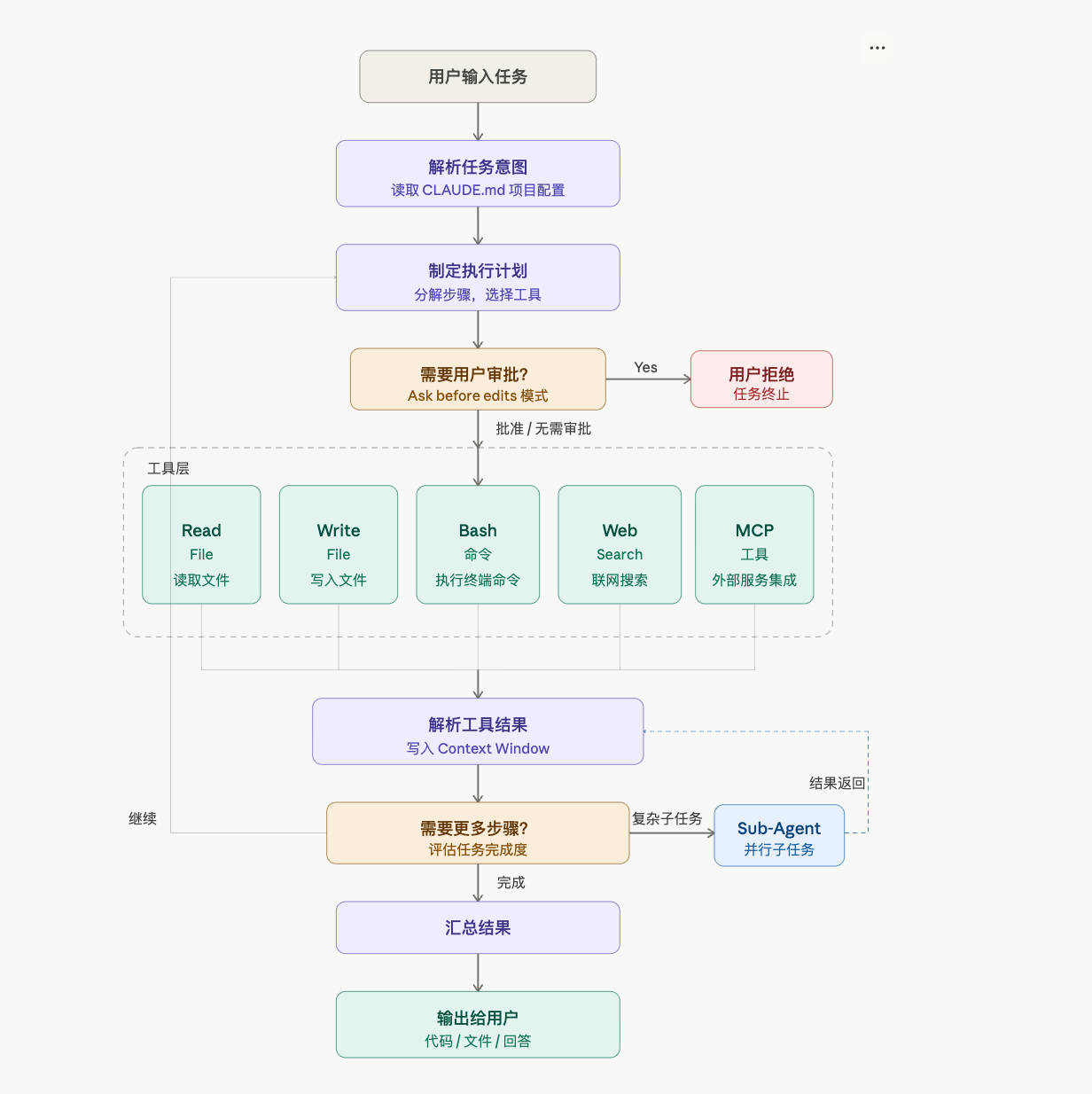
Agent 执行循环(核心)
用户输入
↓
解析任务意图(读取 CLAUDE.md 项目配置)
↓
制定执行计划(分解步骤,选择工具)
↓
需要用户审批? → 是 → 等待确认(Ask before edits 模式)
↓ 否 / 批准
调用工具执行
↓
解析结果,写入 Context Window
↓
还需要更多步骤? → 是 → 回到"制定计划"
↓ 否
汇总结果,输出给用户
每一轮循环,Claude Code 都在做三件事:想(规划)、做(调工具)、记(写上下文)。理解这三件事,很多"它为什么这么做"的疑问就解开了。
它能调用的工具
| 工具 | 用途 |
|---|---|
| Read File | 读取源码、配置文件 |
| Write File | 修改或新建文件 |
| Bash | 执行终端命令(npm、git、测试等) |
| Web Search | 联网查文档、搜错误 |
| MCP 工具 | 连接外部服务(数据库、API、Figma 等) |
Sub-Agent 机制
当任务足够复杂,Claude Code 会拆分子任务,派出 Sub-Agent 并行处理,结果汇总后再继续主流程。这就是为什么处理大型重构时它能同时改多个文件——不是顺序一个个改,而是并行调度的。
二、CLAUDE.md:你和 Claude Code 之间的"项目说明书"
Claude Code 每次启动都会读取项目根目录的 CLAUDE.md。这是你影响它行为最直接的方式。
原则:写 Claude 不知道但需要知道的事。
PHP 语法、Vue 基础用法不用写,它都懂。但你们项目独有的这些,必须写:
# 项目说明
工业设备维修管理系统,PHP 8.1 后端 + Vue 3 前端 + Ionic/Angular 移动端
## 技术约束
- 命名空间:Customized\Himile24484
- 禁止引入新 npm 包(需提前确认)
- API 响应统一用 ApiResponse::success() 包装
## 业务背景
- FMEA 模块:故障模式与影响分析,核心表 fmea_items
- 工单状态流转见 WorkOrderStatus 枚举类
- 设备编码规则:前6位设备类型,后4位序列号
## 编码规范
- Repository 层只写查询,业务逻辑放 Service
- 注释用中文
- 不要修改已有的 migration 文件
## 常用命令
php artisan test 运行测试
npm run dev 启动前端
CLAUDE.md 支持多级放置:
项目根/CLAUDE.md→ 全项目生效src/CLAUDE.md→ 仅该子目录生效~/.claude/CLAUDE.md→ 所有项目生效(写个人偏好)
三、实际工作流:怎么融合进日常开发?
场景 1:新功能开发
传统方式:自己分析需求 → 设计接口 → 写代码 → 联调
接入 Claude Code 后:
# 把需求描述清楚,让它先出方案
"在 FMEA 模块新增一个分页弹窗组件 FailureModeV2Modal,
调用 /api/failure-mode/v2/list 接口,支持无限滚动,
参考同目录下 FailureModeModal 的结构"
它会自己:读现有组件 → 分析接口格式 → 生成新组件 → 告诉你需要确认的地方。
关键技巧:给它一个参照物(“参考 XX 组件的结构”),输出质量会显著提升。
场景 2:调试一个复杂 Bug
# 不要只说"有个 bug",把上下文全给它
"PHP 的 FailureCauseBrowseRepository 里有个 UNION 查询,
跨6张表,当节点被多个父节点共享时,祖先路径校验结果不对。
先读一下这个文件,分析一下问题在哪"
让它先 Read File → 分析 → 提方案,而不是直接让它改代码。复杂 bug 先分析,再动手,避免越改越乱。
场景 3:批量重构
这是 Claude Code 最有优势的地方,Sub-Agent 并行调度能同时处理多个文件。
"把 pages/ 目录下所有页面组件的 HTTP 请求,
从直接调用 HttpClient 改为走 ApiService 统一封装,
保持原有业务逻辑不变"
务必提前做的事:
git commit当前状态,留好退路- 说清楚边界(“不要动 shared/ 目录”)
- 让它改完后跑一次测试(
/run npm test)
场景 4:接入第三方模型降低成本
Claude Code 默认用 Anthropic 自己的模型,价格不低。如果是重度使用,可以切到 DeepSeek V4 Pro:
# macOS / Linux,写入 ~/.zshrc
export ANTHROPIC_BASE_URL=https://api.deepseek.com/anthropic
export ANTHROPIC_AUTH_TOKEN=你的DeepSeek_API_Key
export ANTHROPIC_MODEL=deepseek-v4-pro[1m]
export ANTHROPIC_DEFAULT_HAIKU_MODEL=deepseek-v4-flash
export CLAUDE_CODE_SUBAGENT_MODEL=deepseek-v4-flash
DeepSeek V4 Pro 在 SWE-bench(真实 GitHub issue 自动修复)上得分 80.6%,与 Claude Opus 4.6 相差 0.2 个百分点,但价格约为后者的 1/7。主力任务用 Pro,轻量子任务用 Flash,成本可以压得很低。
注意:V4 Pro 当前不支持图片输入,如果需要分析截图,临时切回原生模型。
四、让 Claude Code 更好用的几个习惯
1. 任务描述要带上下文,不要只说目标
❌ 帮我写一个列表组件
✅ 参考 src/components/WorkOrderList,写一个 FaultRecordList,数据结构见 types/fault.ts
2. 复杂任务先让它"想",再让它"做"
# 先规划
"分析一下要新增设备台账导出功能,需要改哪些文件,不要动代码"
# 确认方案后再执行
"按刚才的方案实现"
3. 用 /status 确认当前模型和配置
切换了 Base URL 后,/status 会显示当前连接的端点和模型,确认生效再开始工作。
4. 长任务中途 /compact 压缩上下文
Context Window 有上限,长会话后用 /compact 压缩历史,避免后期模型"忘事"。
5. CLAUDE.md 随项目迭代同步更新
加了新的业务规则、改了接口约定,记得同步更新 CLAUDE.md。它是你和 Claude Code 之间的"共识文档",越准确,输出越精准。
五、适合 Claude Code 的任务 vs 不适合的
| 适合 ✅ | 不适合 ❌ |
|---|---|
| 多文件重构 | 需要肉眼对比 UI 效果 |
| 写 Repository / Service 模板代码 | 涉及复杂业务决策(这是人的事) |
| 跑测试 + 修报错的循环 | 与外部系统实时联调 |
| 生成 FMEA 测试数据 | 分析截图(V4 Pro 不支持) |
| 整理 API 文档 | 需要产品层面的方案拍板 |
小结
Claude Code 的本质是一个有工具调用能力的 Agent 循环,它通过读取 CLAUDE.md 理解你的项目,通过工具操作你的代码库,通过 Sub-Agent 处理并行任务。
真正让它发挥价值的,不是把它当"更聪明的代码补全",而是把它当一个理解项目上下文的协作者——你负责定方向、做决策,它负责执行、处理细节。
工作流融合的核心:给好上下文,把握好边界,重要变更前先 commit。
基于 Claude Code + DeepSeek V4 Pro 的实际使用整理,2026 年 6 月

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 2
2 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)