进程与线程--线程(2)--实现方式与多线程模型
上一篇我们搞懂了线程的基础定义、核心属性,以及进程和线程的本质区别。很多同学会有疑问:同样是多线程,为什么有的程序开几百个就卡顿耗资源,有的能轻松跑几十万个?为什么有的线程一卡住,整个程序全停,有的却互不影响?
答案就藏在线程的底层实现方式,以及用户线程与内核线程的映射模型里。今天我们用「政务大厅办事」的生活化类比,把用户级线程、内核级线程,以及三种多线程模型讲透。
一、两种基础线程实现:民间自助 vs 官方窗口
我们先做一个核心类比,把整套逻辑落地到生活场景里:
把操作系统内核比作政务服务大厅,CPU 算力就是大厅里的办事窗口,只有站在窗口前,才能真正办理业务(执行代码)。
根据管理主体不同,线程分为两大类:
1. 用户级线程(ULT):民间自助排队
通俗类比
一群办事群众(用户线程)自己找了一位志愿者(线程库),在大厅门外自行排号、维持秩序,轮流进去办事。 大厅管理员(操作系统内核)完全不知道外面分了多少人,只感知到「有一拨人在办事」,全程只对接一个整体。
专业原理
- 线程的创建、调度、切换、销毁,全部由用户态的线程库完成,不需要操作系统内核介入;
- 内核感知不到线程的存在,只会把整个进程当成一个调度单元;
- 线程切换全程在用户空间完成,不需要切换到内核态。
优缺点
- 优点:切换速度极快、系统开销极低,完全由应用程序自主管控,跨平台兼容性好;
- 缺点:只要有一个线程卡住(比如等待文件读写、网络请求),整个进程都会被内核暂停,所有线程一起等待;并且只能占用一个 CPU 核心,无法利用多核性能。
真实例子
Python 的协程、早期 Java 的绿色线程、很多轻量级脚本语言的异步任务,本质都是用户级线程的思路。
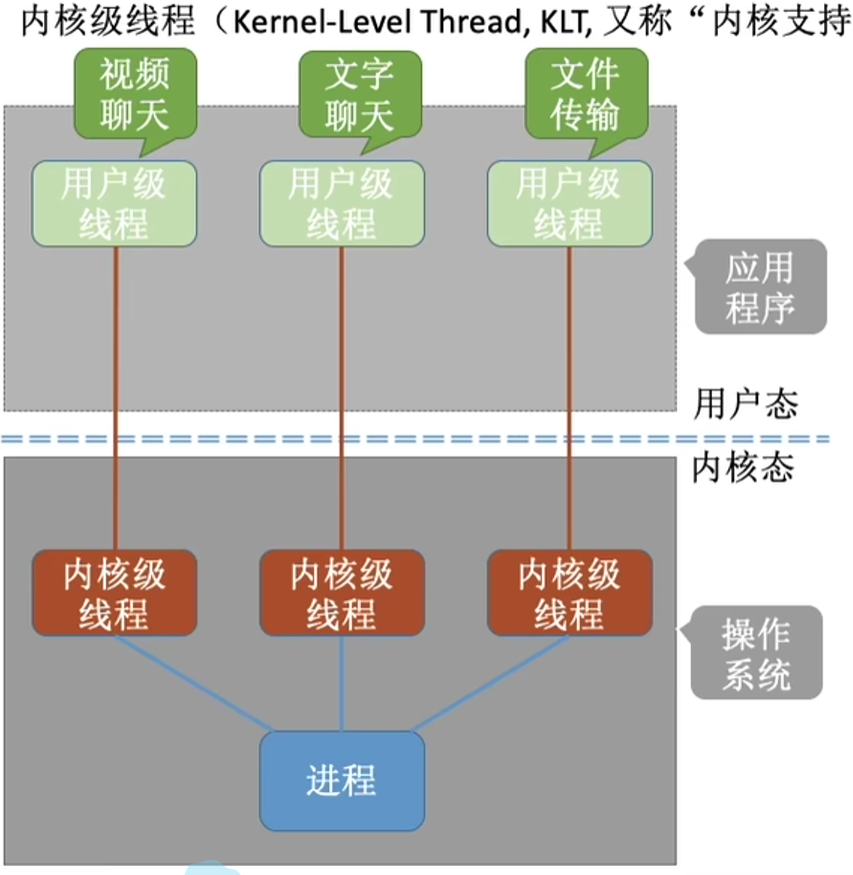
2. 内核级线程(KLT):官方窗口办事
类比
每一位办事群众(用户线程)都对应一个独立的办事窗口(内核线程),大厅管理员(内核)给每个窗口配备专属工作台(TCB 线程控制块)。 谁先办、谁等待、遇到暂停怎么处理,全由管理员统一调度,一个人卡住不会耽误其他窗口办事。
专业原理
- 线程的全部管理工作都由操作系统内核完成,内核为每一条线程创建专属的 TCB 线程控制块;
- 内核级线程才是 CPU 真正调度分配的最小单位,只有内核线程能拿到 CPU 运行时间;
- 线程切换必须陷入内核态才能完成,存在用户态→内核态的切换开销。
优缺点
- 优点:单条线程阻塞,不会影响同进程的其他线程;多条线程可以分配到不同 CPU 核心并行运行,充分发挥多核性能;稳定性强;
- 缺点:线程创建、切换都要经过内核,系统开销更大;每条线程都占用内核资源,不能无限创建。
真实例子
我们日常开发接触的绝大多数线程都是内核级线程:Linux 的 pthread 线程库、Windows 系统原生线程、C++ 的 std::thread、Java 的系统线程。
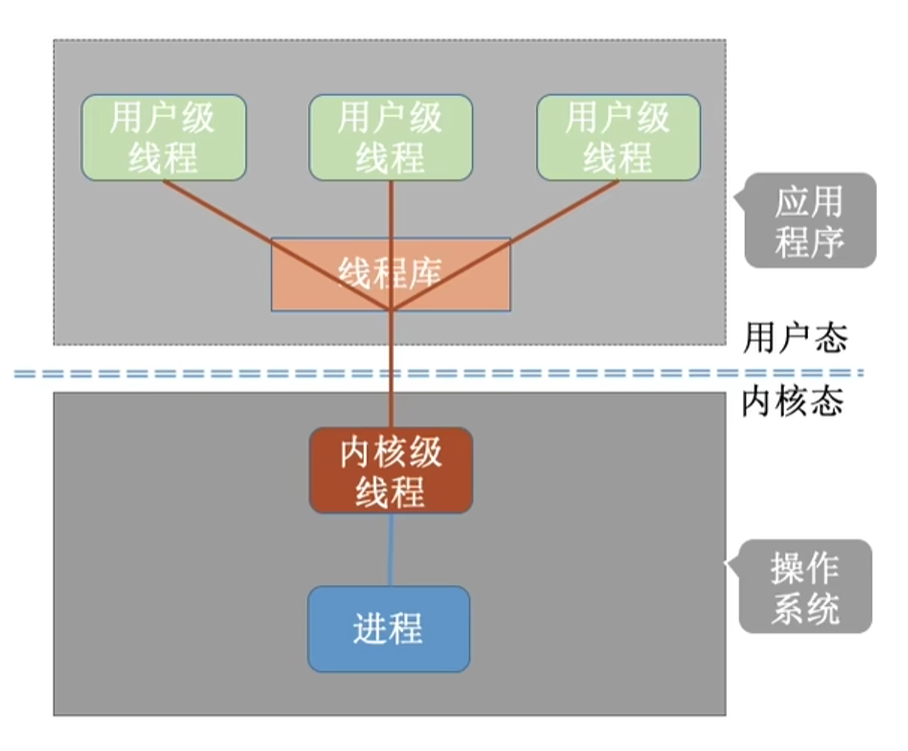
3. 混合实现方式
结合前两者的优势:用户层创建大量轻量用户线程,内核层维护少量内核线程,由调度器把用户线程动态分配到内核线程上运行,兼顾低开销和多核并发能力。 典型代表就是 Go 语言的 GMP 调度模型、Solaris 操作系统的原生线程。
二、三大映射模型:群众和窗口的三种对应关系
在支持内核级线程的系统里,根据「用户线程」和「内核线程」的数量对应关系,衍生出三种经典多线程模型。
1. 多对一模型(M : 1)
映射规则
多个用户级线程,全部映射到同一个内核级线程上,本质就是纯用户级线程实现。
通俗类比
M 个办事群众,只对应 1 个办事窗口。群众自己在门外排队,轮流进去办事,窗口全程只服务这一群人。
优缺点
- 优点:线程切换都在用户态完成,管理成本最低、速度最快;
- 缺点:一个线程阻塞,整个进程全部阻塞;只能用一个 CPU 核心,并发能力最弱。
适用场景
轻量级异步脚本、单核心设备、计算密集型的单进程任务拆分。
2. 一对一模型(1 : 1)
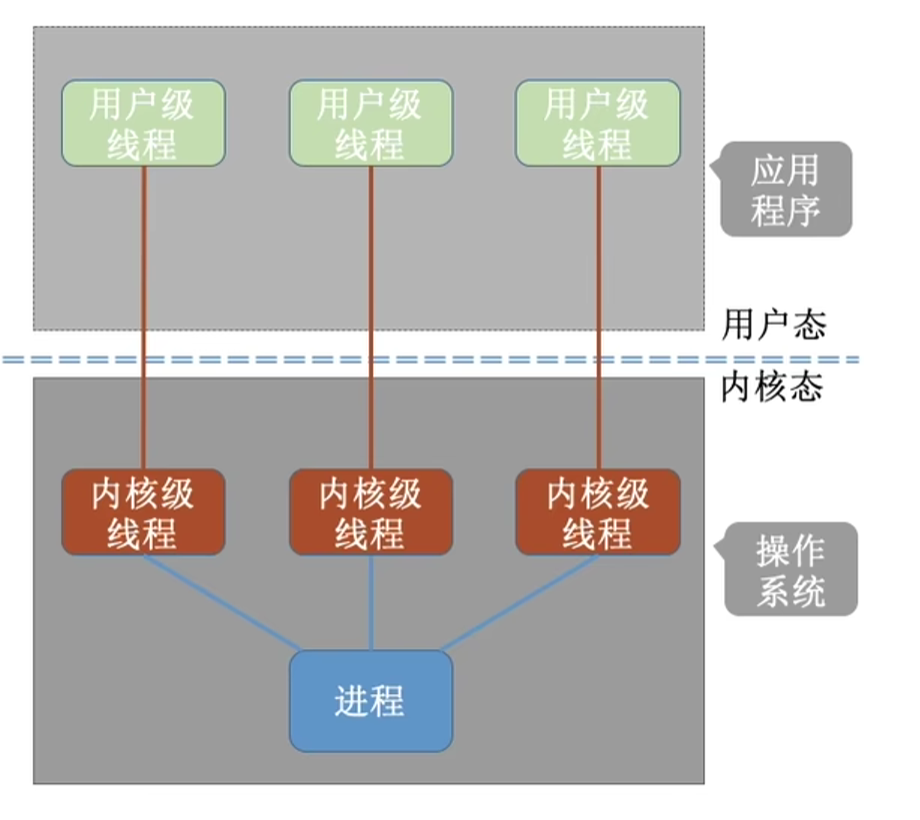
映射规则
每创建 1 个用户线程,就对应创建 1 个独立的内核线程,一一绑定、一一调度。
类比
来 1 位办事群众,大厅就开 1 个专属窗口,专人专窗,互不干扰。
优缺点
- 优点:并发能力最强,单线程阻塞不影响其他线程;完美支持多核 CPU 并行;实现简单、调试方便、稳定性高;
- 缺点:每条线程都占用内核资源,创建数量有上限;线程切换需要陷入内核,开销比多对一模型大。
适用场景
这是目前主流操作系统的默认方案,Windows、Linux、macOS 的原生线程都采用一对一模型,覆盖绝大多数桌面软件、后端业务、游戏开发等普通开发场景。
3. 多对多模型(M : N,M > N)
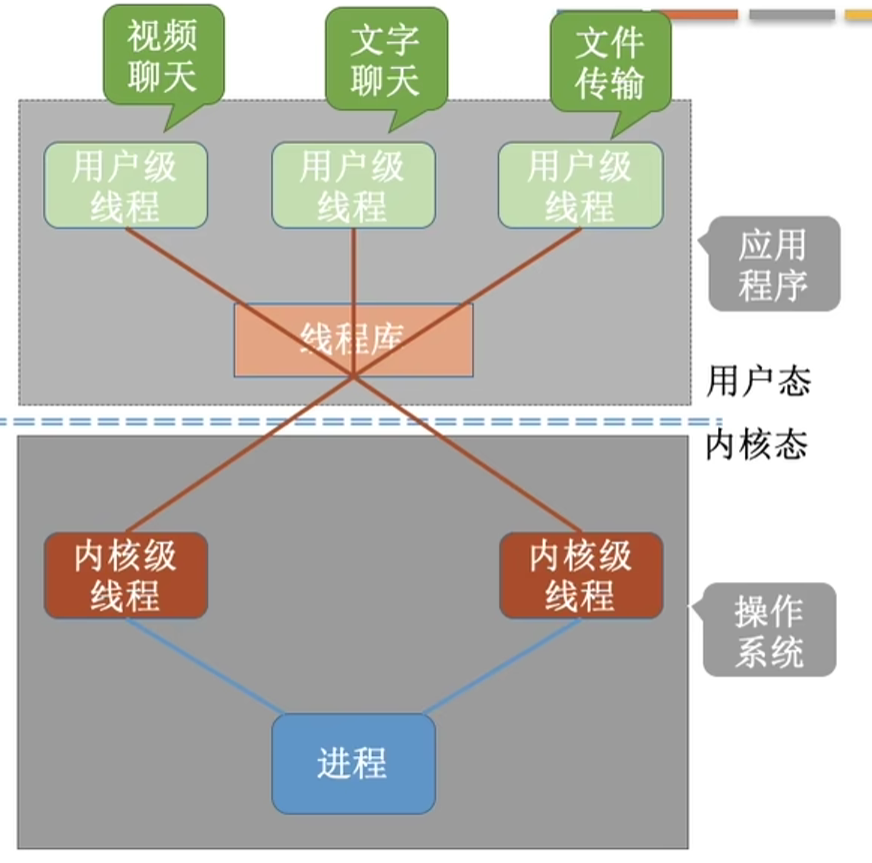
映射规则
M 个用户级线程,映射到 N 个内核级线程上运行;用户线程数量远多于内核线程,内核线程相当于「运行工位」,空闲工位可以承接任意就绪的用户线程。
类比
大厅开了 N 个办事窗口,外面有 M 位办事群众;志愿者(线程调度器)会把群众动态分配到空闲窗口,窗口满了就排队等待。 不会因为一个人卡住就全停,也不用给每个人都开一个窗口,兼顾效率和成本。
优缺点
- 优点:集前两者之长
- 用户线程切换在用户态完成,整体开销低;
- 支持海量轻量线程,不会耗尽内核资源;
- N 个内核线程可以占满 N 个 CPU 核心,充分利用多核性能;
- 单个线程阻塞,只会占用一个工位,不影响其他工位运行。
- 缺点:双层调度逻辑复杂,开发、调试难度高。
适用场景
高并发服务器、海量轻量任务场景,最典型的就是 Go 语言的 goroutine,轻松支持几十万并发协程。
三、比较
| 对比维度 | 多对一模型(用户级线程) | 一对一模型(内核级线程) | 多对多模型(混合实现) |
|---|---|---|---|
| 切换位置 | 全程用户态 | 必须切换内核态 | 用户线程切换在用户态 |
| 阻塞影响 | 一个阻塞,整进程暂停 | 单线程阻塞,互不干扰 | 仅占用一个工位,其余正常 |
| 多核利用 | 无法利用多核 | 完美支持多核并行 | 支持 N 个核心并行 |
| 切换开销 | 极小 | 偏大 | 中等 |
| 线程数量上限 | 极高,可开几十万个 | 较低,受内核资源限制 | 极高,支持海量轻量任务 |
| 实现难度 | 简单 | 中等 | 复杂 |
| 典型场景 | 轻量异步脚本 | 通用业务开发 | 高并发海量任务服务 |
四、注意
-
谁才是 CPU 调度的真正单位? 只有内核级线程才是 CPU 分配算力的最小单位。用户级线程只是代码逻辑的载体,必须绑定到内核线程上,才能获得 CPU 运行时间。
-
线程开得越多,程序跑得越快吗? 不是。当内核线程数量超过 CPU 核心数时,频繁的线程切换反而会消耗大量 CPU 资源,导致程序变慢。日常开发中,不是线程越多越好,匹配核心数才是最优解。
-
既然多对多这么好,为什么不全都用它? 多对多模型虽然性能上限高,但实现、调试、排错的复杂度都远高于一对一模型。对于绝大多数普通业务场景,一对一模型的稳定性、开发效率远胜于极致性能,是性价比最高的选择。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 4
4 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)