从 2D U-Net 到 3D 多器官分割:基于 MONAI 3D U-Net 的腹部 CT 分割项目复盘
项目任务:BTCV 腹部 CT 多器官分割
项目地址:GitHub - AbdomenSeg_3D
方法:MONAI 3D U-Net
输入:腹部 CT NIfTI 体数据
输出:背景 + 13 个腹部器官的多类别 3D mask
数据集:BTCV Abdomen Multi-Organ Segmentation Dataset
主要结果:验证集 Mean Dice 78.00%,测试集 Mean Dice 69.32%
项目定位:2D U-Net 之后、nnU-Net 之前的 3D 医学影像分割过渡项目
一、项目背景:为什么在 2D U-Net 之后做 3D U-Net
在完成 2D U-Net 脾脏 CT 分割项目之后,我继续往 3D 医学影像分割方向推进。前一个项目虽然已经从普通图像分类进入了医学图像分割,但它本质上仍然是 2D 训练:把 3D CT volume 切成一张张 2D slice,然后用 2D U-Net 做单器官二分类分割。
这个项目则进一步进入了 3D 腹部多器官分割。它不再只处理单张 CT 切片,也不再只分割一个脾脏,而是直接处理 3D CT 体数据,并同时预测多个腹部器官类别。对我来说,它在学习路线中刚好处于 2D U-Net 之后、nnU-Net 之前,是一个很重要的过渡项目。
我做这个项目的目标不是追求一个特别高的 Dice,也不是一上来就做复杂模型创新,而是先把一个手工配置的 3D 医学影像分割 pipeline 跑通。也就是理解:NIfTI 体数据怎么读取,spacing 和方向怎么统一,HU 值怎么归一化,3D patch 怎么采样,3D U-Net 怎么训练,多类别 Dice 怎么评估,滑动窗口推理怎么生成完整 3D mask。
后面再进入 nnU-Net 时,我就不会只是把它当成一个“很强的黑箱框架”,而是能理解它到底自动化了哪些原本需要手动配置的步骤。
二、项目整体流程
这个项目可以理解成一条从原始 BTCV CT 数据到最终 3D 分割结果的完整链路:
BTCV 原始 NIfTI 数据
↓
数据集划分 train / val / test
↓
3D 医学影像预处理
Load → Channel First → Orientation → Spacing → HU Normalize → Crop Foreground
↓
3D patch-based training
↓
MONAI 3D U-Net
↓
DiceCE Loss 训练
↓
验证集 sliding-window inference
↓
测试集 Mean Dice / per-class Dice
↓
独立推理并保存 NIfTI mask
和前一个 2D U-Net 项目相比,这个项目的变化主要有三点。
第一,数据从 2D slice 变成了 3D volume。模型不再只看单张切片,而是看一个 3D patch,能够利用上下层之间的空间信息。
第二,任务从单器官二分类变成了多器官多类别分割。之前只需要判断每个像素是不是脾脏;现在每个 voxel 需要在背景和 13 个器官之间选择一个类别。
第三,训练方式从相对简单的 2D batch 训练,变成了 3D patch-based training。完整 CT 体数据通常太大,不能直接一次送入显存,所以训练时需要裁 patch,推理时再用 sliding-window inference 覆盖整例 CT。
这个项目最让我明显感受到的是:3D 医学影像分割不是简单地把 2D 卷积换成 3D 卷积。真正变复杂的是数据、预处理、采样、显存控制和评价方式。
三、数据集准备:第一个大坑是“数据格式对了,但任务错了”
这个项目使用的是 BTCV 腹部多器官分割数据集。正确的 BTCV 标签应该是 0–13 的多类别 label,其中 0 是背景,1–13 对应不同腹部器官。
但这个项目一开始出现了一个很值得复盘的错误:我下载 BTCV 数据集时,下成了同一页面下的另一个二分类数据集。
这个错误一开始非常隐蔽。因为正确数据和错误数据看起来都差不多,都是 .nii.gz 文件,命名略有不同,但都能被 MONAI 正常读取。代码层面也没有报错,预处理流程可以正常执行,模型也可以正常训练。
问题在于,我的模型是按照 14 类输出设计的,但错误数据集的标签里实际只有 0 和 1。由于标签值没有超过类别范围,所以它依然可以被转换成 14 通道 one-hot,只是第 2–13 类一直是空的。这样代码不会崩,loss 能算,Dice 也能输出,但任务语义已经错了。
当时训练曲线也很迷惑。前 100 轮 Dice 非常低,甚至不到 3%,后来突然快速上升到 80% 以上,再训练到 200 轮左右达到 85%。当时我以为这是 3D 分割训练本身比较慢,后来复盘才发现,这更像是模型逐渐发现标签里只有背景和一个前景类,于是放弃其他器官通道,只学习那个唯一存在的类别。也就是说,一个设计为 13 器官分割的网络,实际被训练成了二分类分割模型。
真正暴露问题的是测试阶段的 per-class Dice。总体 Dice 看起来不错,但一展开每个类别的 Dice,才发现其他器官类别完全异常。这件事给我的教训很直接:
医学影像项目里最危险的问题不一定是代码报错,而是代码完全不报错,但任务语义已经错了。
所以后面做 nnU-Net 项目时,我专门加了一个数据预检查脚本,在运行 nnU-Net 自带的数据检查前,先检查当前数据是否真的是 BTCV 多器官数据集,尤其是确认 label 中是否真的包含 0–13 的多类别标签,而不是只有 0 和 1。
这个检查非常简单,比如训练前打印几个 label 的 unique values:
unique_values = np.unique(label)
print(unique_values)
但它能避免把很长时间浪费在错误任务上。
四、3D 医学影像预处理:这个项目最需要理解的部分
这个项目里,我最想真正盘明白的其实不是 3D U-Net 本身,而是预处理。
在普通 2D 图像项目里,预处理通常是 resize、normalize、augmentation。到了 2D 脾脏分割项目,开始涉及 CT 窗宽窗位、mask 对齐、病例级划分。但进入 3D CT 后,预处理复杂度明显提高,因为 CT 不是普通图片,而是带有物理空间信息的体数据。
这个项目的训练集预处理流程大致如下:
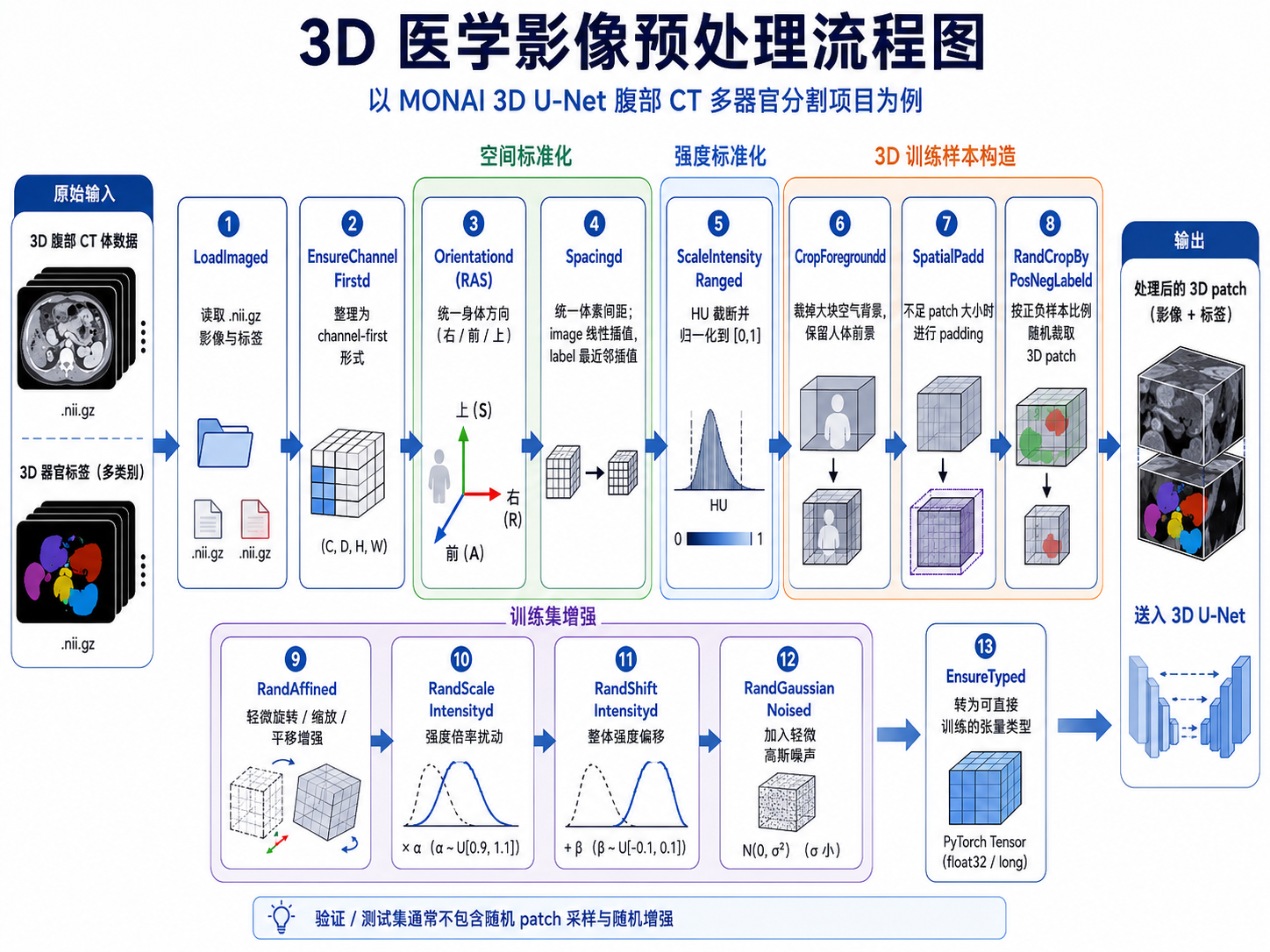
图1:3D 预处理流程图
验证集和测试集则只保留确定性的预处理步骤,不做随机 patch 采样和随机增强。
1. LoadImaged:读取 NIfTI 体数据
LoadImaged 负责把 .nii.gz 路径读成真正的医学影像数据。它不是普通地读取一张图片,而是读取 NIfTI 体数据,同时尽量保留 spacing、affine、方向等医学影像 metadata。
这一点很重要,因为医学分割最终不是只要一个数组,而是要一个能和原始 CT 在空间中对齐的 mask。
2. EnsureChannelFirstd:整理通道维度
原始 CT 可以理解成一个 3D 数组,比如 [H, W, D],但 3D U-Net 需要明确的通道维。单模态 CT 只有一个通道,所以经过 EnsureChannelFirstd 后会变成类似 [1, H, W, D] 的形式。
这里 label 也会加上一个通道维,但它仍然是单通道整数标签,不是 14 类 one-hot。
3. Orientationd:统一身体方向
Orientationd(axcodes="RAS") 用来统一图像方向。RAS 不是“从哪个角度看图像”,而是医学影像里的坐标方向约定,表示三个轴的正方向分别对应 Right、Anterior、Superior,也就是右、前、上。
不同 NIfTI 文件的数组轴方向可能不完全一致。如果不统一方向,模型看到的左右、前后、上下解剖关系就可能混乱。腹部多器官分割尤其依赖空间位置,比如肝脏、脾脏、左右肾、左右肾上腺都有相对固定的位置,所以方向统一是很基础但很关键的一步。
4. Spacingd:统一体素间距
spacing 表示一个 voxel 在真实物理空间中代表多少毫米。不同 CT 的 spacing 可能不同,如果不统一 spacing,同样大小的 patch 在不同病例中代表的真实人体范围就不一样,模型看到的器官尺度也会混乱。
这个项目中将 spacing 统一到 [1.5, 1.5, 2.0]。这里还有一个非常重要的细节:image 和 label 的插值方式不同。
CT image 是连续强度值,可以用线性插值;label 是离散类别编号,必须使用最近邻插值。如果 label 也用线性插值,可能会插出 1.3、2.7 这种没有意义的类别值,直接破坏标注。
5. ScaleIntensityRanged:HU 截断与归一化
CT 的数值不是普通 RGB 图像的 0–255,而是 HU 值。空气、脂肪、软组织、骨骼都有不同的 HU 范围。腹部多器官分割主要关注软组织区域,所以需要把 HU 范围截断到一个更适合腹部器官观察的区间。
这个项目把 HU 值截断到 [-175, 250],再归一化到 [0, 1]。这和窗宽窗位的思想有点像,但目的不是为了显示给人看,而是为了让神经网络更容易学习腹部软组织之间的差异。
6. CropForegroundd:裁掉大块无关背景
CT 原图中有很多人体外部空气区域,这些区域对腹部器官分割没有太大帮助。CropForegroundd 会根据 image 找到前景区域,然后把 image 和 label 一起裁剪。
这一步更接近我前一个 2D 项目里“裁掉无关背景”的思路,只不过这里处理的是 3D 体数据。
7. SpatialPadd 与 RandCropByPosNegLabeld:构造 3D patch
因为 3D CT 太大,训练时不能直接整例输入,所以这个项目使用 patch-based training。
SpatialPadd 的作用是保证图像尺寸至少够裁出一个指定大小的 patch,比如 [96, 96, 96]。如果前景裁剪后某个方向太小,就需要 padding。
RandCropByPosNegLabeld 则负责从体数据中随机裁 patch,并控制正负样本比例。这个项目里设置 pos=1, neg=1, num_samples=4,可以理解为每个 CT 数据体在一次 transform 中随机裁出 4 个 patch,并尽量让其中既有包含器官区域的 patch,也有一定比例的背景或非前景 patch。
这里我一开始也容易混淆。CropForegroundd 是病例级别裁掉大块无关背景;RandCropByPosNegLabeld 是训练阶段在体数据内部按正负比例抽 patch。两者不是一个层级的操作。
8. 数据增强:医学图像不能随便翻转
后面的 RandAffined、RandScaleIntensityd、RandShiftIntensityd、RandGaussianNoised 属于训练集数据增强。
RandAffined 是轻微 3D 几何增强,包括小幅旋转、缩放和平移,用来模拟体位、视野、重采样差异。这里需要特别注意:医学图像不能机械照搬自然图像增强。
我之前做这个项目时曾经加过水平翻转,结果训练明显变慢,Dice 也很低。后来取消翻转后才恢复正常。复盘后看,这很可能是因为 BTCV 多器官分割中有左右肾、左右肾上腺这类带左右语义的类别。如果不处理类别交换就直接翻转,会破坏解剖标签含义。
自然图像里,猫狗左右翻转还是猫狗;但在多器官医学分割里,左右翻转可能会把 left kidney 和 right kidney 的语义搞乱。所以数据增强必须结合任务本身设计。
RandScaleIntensityd 是强度倍率变化,RandShiftIntensityd 是整体强度偏移,RandGaussianNoised 是加入轻微噪声。这些增强主要是为了让模型对不同扫描条件和轻微噪声更鲁棒,但幅度也不能太大,否则可能破坏小器官边界。
最后,EnsureTyped 把处理后的数据整理成 MONAI/PyTorch 可以直接训练的 tensor 类型。
整体来看,这个预处理流程可以分成三层:
医学空间标准化:Orientationd + Spacingd
医学强度标准化:ScaleIntensityRanged
3D 训练样本构造:CropForegroundd + SpatialPadd + RandCropByPosNegLabeld
这个项目让我真正意识到,3D 医学影像分割最复杂的地方并不只是 3D U-Net,而是数据在送入网络之前,就已经有一整套非常重要的医学影像处理逻辑。
五、为什么要使用 patch-based training
这个项目不能直接把整例 CT 送进 3D U-Net 训练,最直接的原因是显存放不下。
3D 数据比 2D 图像多了一个空间维度,卷积特征图、梯度和中间激活都会显著增加显存消耗。尤其是在普通单卡环境下,完整 CT 体数据直接训练非常困难。所以项目中使用 [96,96,96] 的 3D patch 作为训练输入。
但 patch-based training 不只是显存不够时的无奈选择,它也是一种采样策略。完整腹部 CT 里有大量背景和非目标区域,如果完全随机训练,模型可能花很多时间看没有多少信息量的区域。通过正负样本 patch 采样,可以提高模型看到器官区域的概率,尤其对胰腺、血管、肾上腺这类小器官更重要。
这里还要区分训练阶段的 patch 采样和推理阶段的 sliding-window inference。
训练时的 patch 是随机采样,目的是让模型高效学习局部区域;推理时的 sliding window 是系统覆盖整例 CT,目的是把一整例 CT 分块预测完,再拼回完整 mask。
简单说就是:
训练 patch:为了学习
滑动窗口:为了完整预测
它们窗口大小可能一样,但作用不同。
六、模型结构:MONAI 3D U-Net
这个项目使用的是 MONAI 提供的 3D U-Net。它和之前 2D U-Net 的核心思想是一样的,仍然是 encoder-decoder 结构:encoder 通过下采样提取更抽象的语义特征,decoder 通过上采样恢复空间分辨率,中间通过 skip connection 融合浅层细节和深层语义。
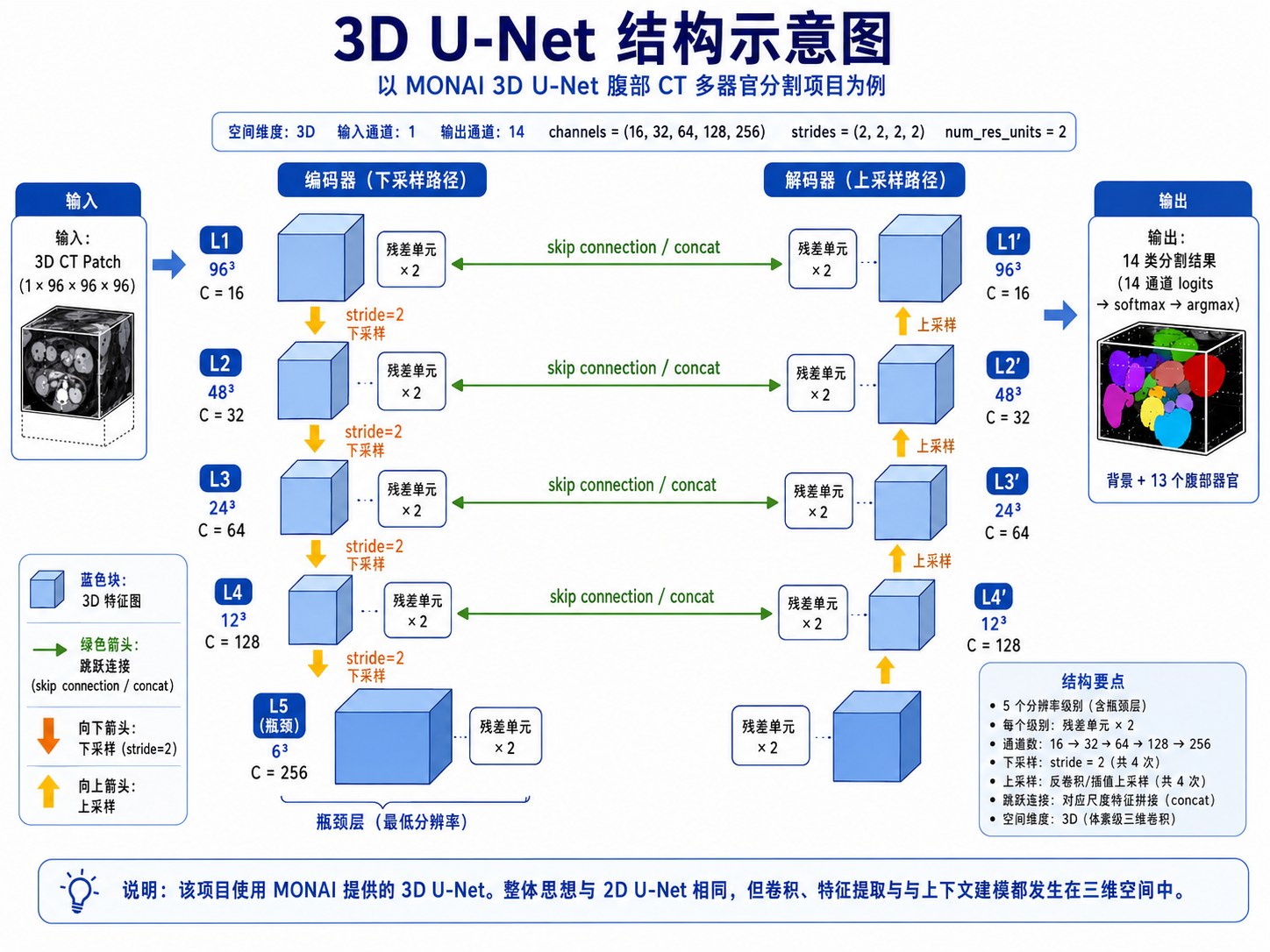
图2:3D U-Net 结构示意图
区别在于,之前 2D U-Net 处理的是二维切片,而这里的 3D U-Net 处理的是 3D patch。卷积、下采样、上采样都发生在三维空间中,所以模型能够利用切片之间的上下文信息。
这个项目中的主要配置是:
spatial_dims = 3
in_channels = 1
out_channels = 14
channels = (16, 32, 64, 128, 256)
strides = (2, 2, 2, 2)
num_res_units = 2
in_channels=1 表示输入是单通道 CT。out_channels=14 表示输出是背景加 13 个腹部器官。channels=(16,32,64,128,256) 表示编码器逐层增加特征通道数。由于 3D 卷积显存压力很大,初始通道数从 16 开始,是一个相对保守的设置。
num_res_units=2 表示在 U-Net 的局部模块中加入 residual units。它并没有改变 U-Net 的整体结构,只是让局部卷积块更容易训练。
这个项目的重点不是模型结构创新,而是先用一个标准 3D U-Net baseline 把完整 3D 多器官分割流程跑通。当时我还没有进入 nnU-Net 和 Transformer 阶段,所以这里不应该写成“我对比后选择不用复杂模型”。更真实的说法是:先用 3D U-Net 理解 3D 医学影像分割 pipeline,后面再自然过渡到 nnU-Net。
七、多类别输出与 DiceCE Loss
这个项目和前面的单器官分割项目相比,一个重要变化是 loss 和输出形式变复杂了。
之前单器官分割主要是背景和脾脏二分类,模型只需要判断某个像素是不是脾脏。而这个项目是背景 + 13 个器官的多类别分割,每个 voxel 最终只能属于一个类别。
所以模型输出不是一个通道,而是 14 个通道。每个 voxel 都会对应 14 个 logits,分别表示它属于背景或某个器官的原始分数。
训练时的流程可以这样理解:
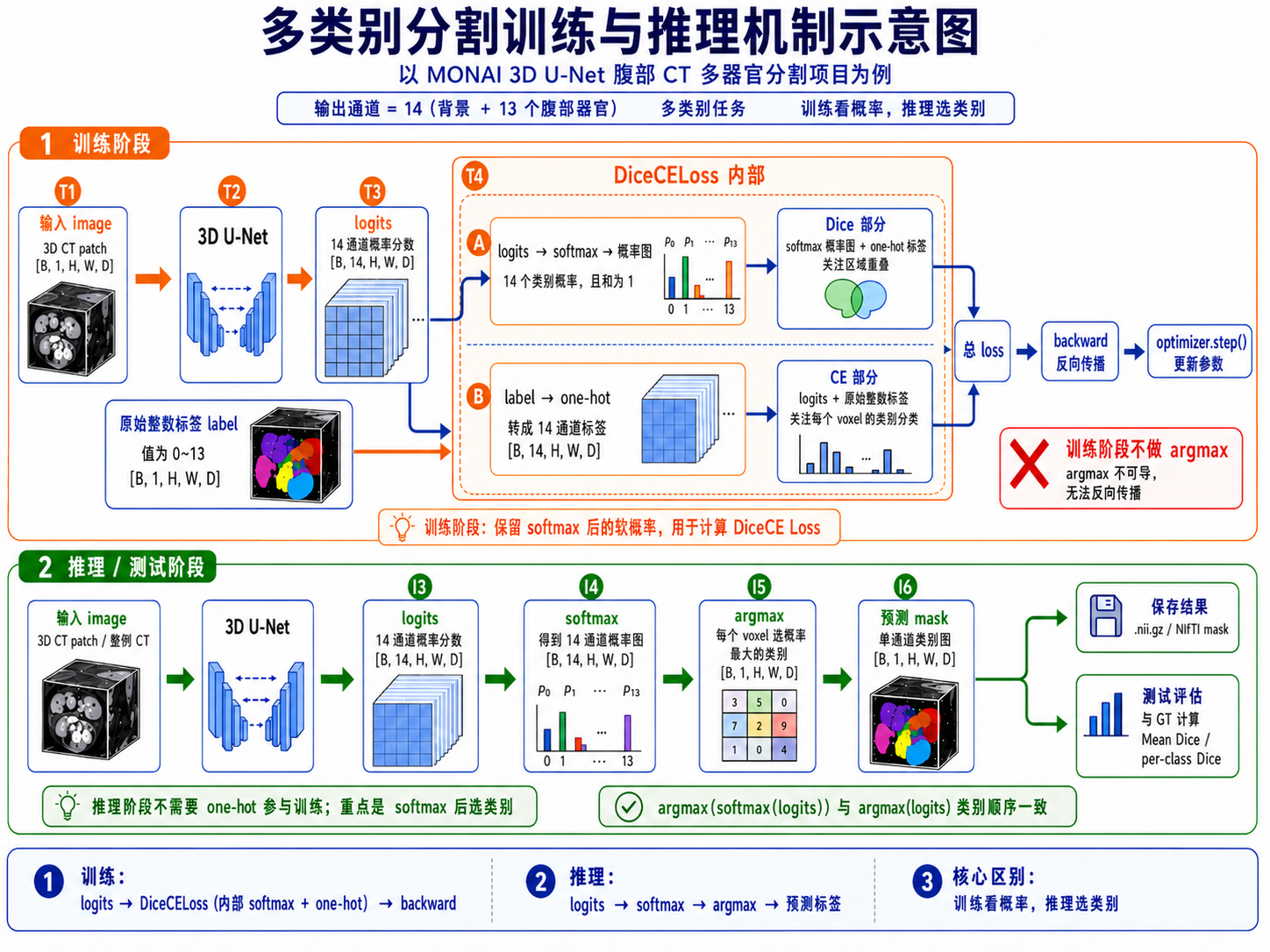
图3:训练与推理机制示意图
这里最容易混的是 softmax、one-hot 和 argmax。
训练阶段不会先做 argmax。因为 argmax 会把连续概率变成硬类别,不能反向传播。训练时保留的是 softmax 后的“软概率”,loss 根据这些概率和 one-hot 标签之间的差异来计算损失。
to_onehot_y=True 处理的是原始 label。原始 label 是单通道整数标签,值为 0–13;但模型输出是 14 通道,所以需要把 label 转成 14 通道 one-hot,才能逐类别计算 Dice。
而推理阶段才会真正把概率变成类别,从数学上说,argmax 直接作用在 logits 上也可以,因为 softmax 不改变大小顺序。但理解时可以记成:训练看概率,推理选类别。
DiceCELoss 可以理解为 Dice Loss 和 Cross Entropy Loss 的组合。Dice 关注预测区域和真实区域的重叠程度,适合医学图像这种类别不平衡明显的分割任务;CE 则关注每个 voxel 的类别分类是否正确。
这个项目里不是因为 DiceCE 比 Dice “更高级”,而是因为多器官任务本身更复杂。单器官分割主要问“这里是不是目标器官”,多器官分割还要问“这里到底是哪一个器官”。因此,DiceCE 同时考虑区域重叠和类别分类,更适合这个任务。
八、训练流程与工程组件
训练流程整体仍然是 PyTorch 项目的常规闭环:
读取 batch
↓
前向传播
↓
计算 loss
↓
反向传播
↓
更新参数
↓
验证集评估
↓
保存 best checkpoint
不过 3D 医学影像分割的训练成本比之前高很多,所以一些工程组件也变得更重要。
optimizer 负责根据梯度更新参数。scheduler 负责动态调整学习率,比如验证指标进入平台期后降低学习率,让模型以更小步长继续收敛。AMP 混合精度训练可以减少显存占用、加快训练速度,对 3D 分割这种显存压力大的任务很有用。
checkpoint 用来保存模型状态,最重要的是保存验证集表现最好的权重,也可以用于断点续训。early stopping 是提前停止训练的策略,如果验证集长期没有提升,就及时停止,避免继续浪费时间或者增加过拟合风险。TensorBoard 则用来可视化 loss、Dice 和学习率变化。
这些东西本身不是模型创新,但对 3D 项目很重要。因为一次 3D 分割训练成本更高,不能只追求“能跑”,还要尽量让训练过程可观察、可恢复、可控制。
九、验证、测试与独立推理
验证、测试和独立推理阶段都需要使用 sliding-window inference。
原因很简单:完整 3D CT 仍然太大,不能一次性全部送进网络。所以推理时会按照固定窗口大小一块一块预测,再把局部预测拼接回完整体数据。
这里再次强调训练和推理的区别:
训练阶段:随机裁 patch,用来学习
推理阶段:滑动窗口覆盖整例 CT,用来得到完整预测
测试阶段除了计算 Mean Dice,还应该输出 per-class Dice。因为多器官分割不能只看一个总体分数。肝脏、脾脏这种大器官通常更容易分割,小器官或细长结构,比如胰腺、血管、肾上腺,Dice 往往更低。只有展开 per-class Dice,才能知道模型到底哪些器官分得好,哪些器官是短板。
预测结果最终保存为 NIfTI mask,也就是 .nii.gz 文件,而不是普通图片或 numpy 数组。原因是医学影像分割结果需要和原始 CT 在三维空间中对齐。NIfTI 可以保留 spacing、orientation、affine 等空间信息,方便后续在 ITK-SNAP、3D Slicer 等软件中查看。
普通图片只能表示某个 2D 切片,numpy 数组虽然能保存数值,但容易丢失医学空间信息。所以 3D 分割项目最终保存 NIfTI mask 是更合理的做法。
十、实验结果与理解
这个项目当前结果如下:
| Split | Cases | Mean Dice | 说明 |
|---|---|---|---|
| Train | 21 | - | patch-based training |
| Val | 3 | 78.00% | best checkpoint selection |
| Test | 6 | 69.32% | final evaluation |
从学习项目的角度看,这个结果首先说明流程是成功的。项目已经完成了 3D 多器官分割从数据读取、预处理、patch 训练、验证、测试、滑动窗口推理到 NIfTI mask 保存的完整闭环。
但测试集 69.32% 的 Mean Dice 并不算高,也不能被过度拔高。验证集 78%,测试集 69%,测试集低了接近 10%,可能有几方面原因。
第一,验证集只有 3 例,数据量太小,Dice 波动会比较大。只要验证集中有比较简单的病例,平均分就可能偏高。
第二,训练集只有 21 例,模型可能确实存在一定过拟合。
第三,测试集本身可能更难,比如某些病例器官边界更复杂,小器官更多,或者扫描范围与训练/验证病例存在差异。
所以不能一看到验证集比测试集高,就简单归因于“模型失败”或者“完全过拟合”。更合理的做法是结合 per-class Dice 和 per-case Dice 分析:到底是某几个病例特别难,还是某些器官普遍分不好。
不过这个结果也让我意识到,手工 3D U-Net 项目非常依赖配置。spacing、patch size、batch size、num_samples、数据增强、学习率、训练轮数、网络通道数,这些都会影响最终结果。继续手动调参可能会带来提升,但实验成本很高。
以前做简单项目时,调参可以比较凭感觉,而且调不调区别可能没那么大。但到了 3D 多器官分割,pipeline 和参数配置的重要性明显提高,有时候甚至不亚于换一个更复杂的网络结构。
这也正好自然引出下一个项目:nnU-Net。
十一、项目局限与 nnU-Net 的自然衔接
这个项目的主要局限有三个。
第一,数据量小。BTCV 训练集本身只有 30 例,这次划分后训练集 21 例、验证集 3 例、测试集 6 例。小数据集下,验证集波动和测试集差异都比较明显。
第二,当前模型只是一个手工配置的 3D U-Net baseline。它能跑通 3D 多器官分割流程,但还没有达到非常强的分割性能,也没有做交叉验证、外部数据验证或系统消融实验。
第三,手工调参成本很高。3D 分割里,spacing、patch size、网络结构、训练策略、数据增强都很关键,但每改一组配置都可能需要很长时间训练。对于我当前阶段来说,把 3D U-Net 调到极致并不是最优先的目标。
因此,nnU-Net 项目的出现就很自然。nnU-Net 不是简单“换了一个更强网络”,它更重要的地方在于自动化配置。它会根据数据集自动分析 spacing、patch size、网络结构、预处理和训练策略。
这个 3D U-Net 项目让我知道了:3D 医学影像分割到底有哪些东西需要配置;而 nnU-Net 进一步回答的是:这些复杂配置能不能被系统化、自动化。
所以它们不是割裂的两个项目,而是连续的学习台阶:
2D U-Net:理解医学图像分割基本闭环
3D U-Net:理解 3D 多器官分割手工 pipeline
nnU-Net:理解成熟医学分割框架如何自动配置强 baseline
十二、我真正理解了什么
复盘这个项目后,我觉得它最重要的价值不是“我会用 3D U-Net 了”,而是让我真正体会到 3D 医学影像分割和 2D 分割之间的差异。
在 2D 脾脏分割项目里,输入是 2D slice,目标是单器官,预处理和训练都比较直观。而这个项目进入 3D 腹部多器官分割后,数据变成了带 spacing、orientation、HU 值和空间信息的体数据,任务也变成了多类别分割。模型输出、loss、评价指标、推理方式、结果保存都随之变化。
这个项目最让我印象深刻的有三点。
第一,3D 训练对显存和配置非常敏感。我一开始经常遇到内存或显存溢出,需要不断调整 patch size、batch size、num_samples、网络通道数等配置,才能让训练正常跑起来。
第二,医学影像预处理比我之前想象的重要得多。NIfTI、spacing、orientation、HU 归一化、foreground crop、label 插值方式,这些都不是可有可无的细节,而是 3D 分割 pipeline 的基础。
第三,数据检查非常重要。下错二分类数据集这件事让我意识到,代码能跑、loss 能降、Dice 看起来高,都不一定代表任务做对了。多器官分割必须检查 label 类别范围,也必须看 per-class Dice。
所以,这个项目不是我的终点,而是一个过渡台阶。它让我从 2D 单器官分割进入了 3D 多器官分割,也让我在进入 nnU-Net 之前,亲手体验了一遍手工 3D pipeline 的复杂性。后面再看 nnU-Net 时,我就能更清楚地理解:它不是凭空变强,而是在很多关键配置上做了系统化和自动化。
十三、总结
这个项目是我在 2D U-Net 脾脏分割之后完成的 3D 腹部多器官分割项目。它使用 BTCV 数据集,基于 MONAI 3D U-Net 实现了从 NIfTI 数据读取、3D 预处理、patch-based training、DiceCE Loss、多类别 Dice 评估、sliding-window inference 到 NIfTI mask 导出的完整流程。
从结果看,验证集 Mean Dice 为 78.00%,测试集 Mean Dice 为 69.32%。这个结果不能说很高,但从学习角度看,它证明我已经完整跑通了一个 3D 医学影像多器官分割 baseline。
更重要的是,通过这个项目,我理解了 3D 医学影像分割和 2D 分割的本质区别:3D 不只是多了一个维度,多器官也不只是多了几个类别。真正复杂的是空间信息、物理尺度、HU 强度、patch 采样、多类别 loss、per-class 指标、滑动窗口推理和工程配置。
如果说前一个 2D U-Net 项目让我理解了医学影像分割的基本形态,那么这个 3D U-Net 项目让我第一次真正进入了 3D 医学影像分割的工程现场。它不是一个完美项目,但它是我进入 nnU-Net 和后续医学影像算法项目之前,非常必要的一步。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 8
8 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)