Obsidian Wiki知识库+AI 应用实操:一套系统搞定知识沉淀、选题、内容生成全流程
最近有读者私信问我:「你每周的文章选题从哪来?数据和案例都那么具体,是怎么找的?」
说实话,刚开始写公众号那会儿,我也是靠「刷头条/抖音、翻微信、盯热榜」来凑选题,每次开始写都要先花一两个小时翻资料。直到我把个人 Wiki 知识库和 AI 工具打通,这件事才发生了质变。
今天聊聊这套我自己在用的系统——用 Obsidian wiki 知识库,实现选题自动推荐、素材自动查询、数据自动统计,最后辅助生成文章和分析报告。
🤔 我的观察:大多数人的知识库是「信息坟场」
先说一个扎心的真相:大多数人的 Obsidian 知识库,本质上是个「高质量垃圾桶」。
剪藏了几百篇文章,用的时候根本找不到。笔记越来越多,但写作时还是一片空白。知识和内容生产之间,有一道很深的沟。
这道沟不是因为笔记不够多,而是因为——知识没有被结构化,也没有和写作流程打通。
我的做法是建一套「知识图谱+脚本驱动」的工作流。
💡 我的思考:知识库应该能「主动说话」
第零层:知识是怎么进来的?
先说一个常被忽略的前提:知识图谱再厉害,也是靠「持续喂料」撑起来的。
我的 wiki 知识库有五条持续输入的管道:
|
来源 |
频率 |
性质 |
|
数智日报 |
每日自动生成 |
AI哨兵抓取行业动态,51篇已归档 |
|
数智周报 |
每周五整理 |
精选日报TOP内容,形成周度快照 |
|
学习笔记 |
随课程进度 |
大模型开发课、读书笔记、技术专题 |
|
LLM问答记录 |
随时存档 |
和AI深度探讨某概念后的对话存档 |
|
素材收藏库 |
不定期整理 |
AI+工业、AI前沿的主动收藏 |
其中,数智日报是最核心的「喂料」环节——每天完全自动化,扫描、摘要、落地到 Obsidian,一条龙,不需要我手动操作。
LLM 问答记录则是另一种被低估的来源。每次和 AI 聊到某个话题有了新认识,我会把整段对话存成 MD 文件(copilot/conversations/)。这些记录里有推理过程,不是搜索结果,而是思考的轨迹——这才是写作最难替代的素材。
随着五条管道持续汇入,每周新增 10-15 个文件,知识库的「密度」才够让后面的图谱脚本找到有意义的关联。
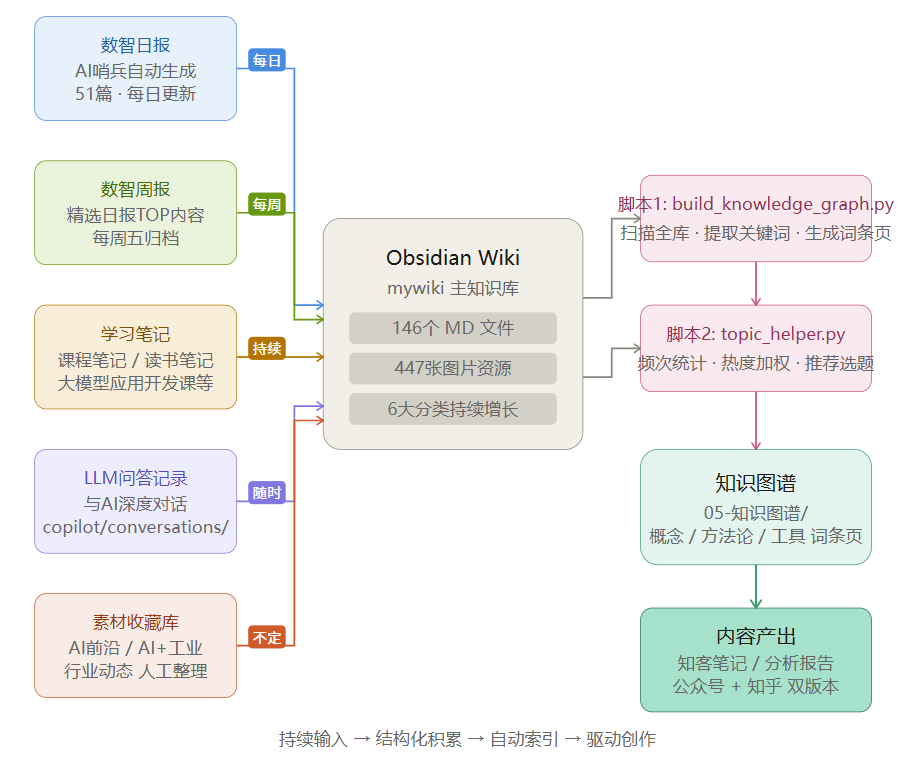
图1:Obsidian Wiki 知识库持续积累信息流图——五大来源持续汇入,经脚本处理转化为知识图谱,最终驱动内容产出
第一层:让知识库知道自己有什么
我的 Obsidian wiki 库(路径 D:\mywiki\)目前有 146 个 MD 文件、447 张图片,涵盖 6 大分类:
|
分类 |
词条数 |
最高频词条 |
覆盖领域 |
|
概念 |
33 |
大模型(105次) |
AI核心技术、工业场景 |
|
方法论 |
15 |
知识库建设(63次) |
分析框架、工作流 |
|
工具 |
19 |
GPT(57次) |
AI工具、开发框架 |
|
项目 |
10 |
方案官(52次) |
客户项目、交付物 |
|
投资 |
12 |
基本面分析(13次) |
股票研究 |
|
学习 |
6 |
课程笔记(45次) |
技术课程 |
这些数字来自一个 Python 脚本 build_knowledge_graph.py,它全量扫描所有 MD 文件,统计每个关键词在多少篇文档里出现过,输出为 keyword_stats.json。
值得一提:「大模型」能出现105次,不是我写了105篇大模型文章,而是日报、学习笔记、LLM问答、素材收藏里都在不断提到它。 多来源共同印证的词条,才是真正值得写的话题信号——仅凭单一来源堆出来的频次,往往是偏科的结果。
脚本在统计词条频次的同时,也会建立词条之间的关联关系。比如「大模型」和「AI Agent」共现最强(60+篇文档),「RAG」和「向量数据库」次之。这些关联关系,是后续素材交叉查询的基础——找到一个词条,顺着关联链能挖出一整片相关素材。
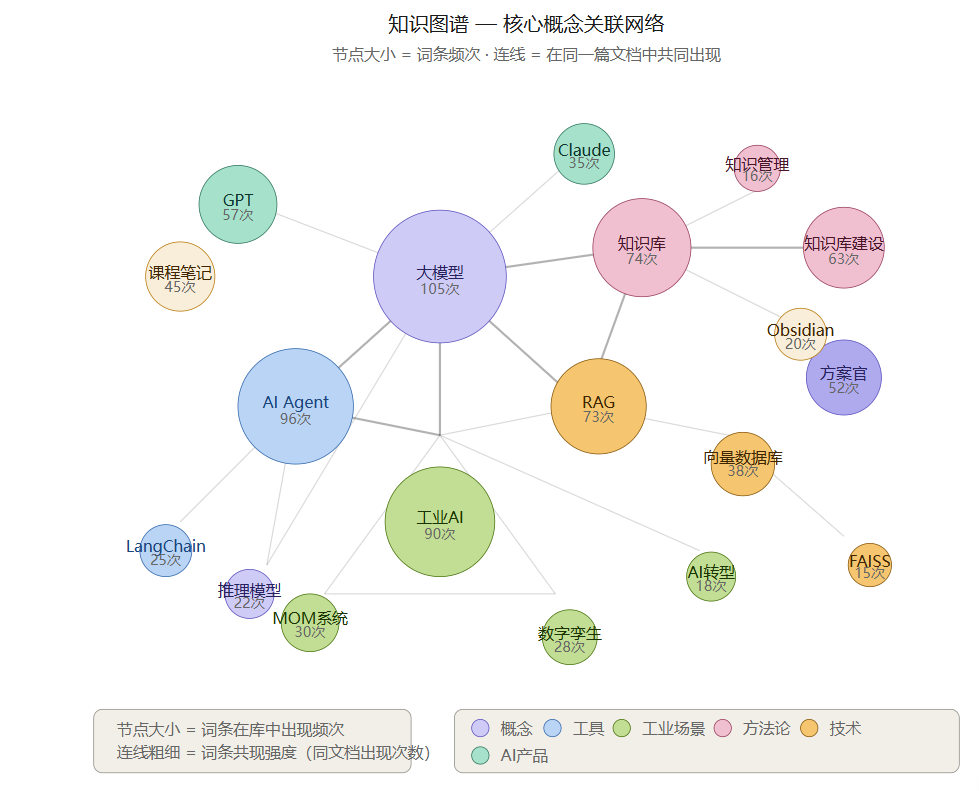
图2:Wiki 知识图谱核心概念关联网络——节点大小=词条频次,连线=词条共现关系,19个核心词条的关联拓扑
脚本核心逻辑(简化版):
# 扫描所有 MD 文件,统计关键词出现频次for file in all_md_files: content = read_file(file) for keyword in KEYWORD_RULES: if keyword in content: keyword_freq[keyword] += 1 keyword_articles[keyword].append(file)# 输出 JSONwith open('keyword_stats.json', 'w') as f: json.dump({"categories": keyword_freq, "articles": keyword_articles}, f)一次全量构建约 20 秒,增量更新(--update 模式)只处理有改动的文件,速度在 3 秒以内。
第二层:让频次数据驱动选题
知道了哪些词出现最多,下一步是判断「哪个词值得写」。
判断标准不只是频次高,还要看三个维度:
-
热度趋势:这个词在最近 14 天的日报里出现了几次?
-
关联深度:知识库里有没有至少 3 篇以上的关联文章可以当素材?
-
情绪价值:这个话题对读者有没有「焦虑、迷茫、渴望改变」的情绪钩子?
第一和第二点可以脚本化。第三点目前还是我自己判断,但可以给 AI 一个打分 prompt。
实际运行结果(2026年5月选题推荐示例):
|
选题候选 |
命中关键词 |
关联文章数 |
最近14天日报提及 |
推荐指数 |
|
RAG已死是炒作吗? |
RAG(73次) |
48篇 |
12次 |
★★★★★ |
|
AI Agent在工业的演化 |
AI Agent(96次) |
32篇 |
9次 |
★★★★☆ |
|
Obsidian+大模型重构知识库 |
知识库(74次) |
15篇 |
7次 |
★★★★☆ |
|
工业AI落地概念重构 |
工业AI(90次) |
27篇 |
8次 |
★★★★☆ |
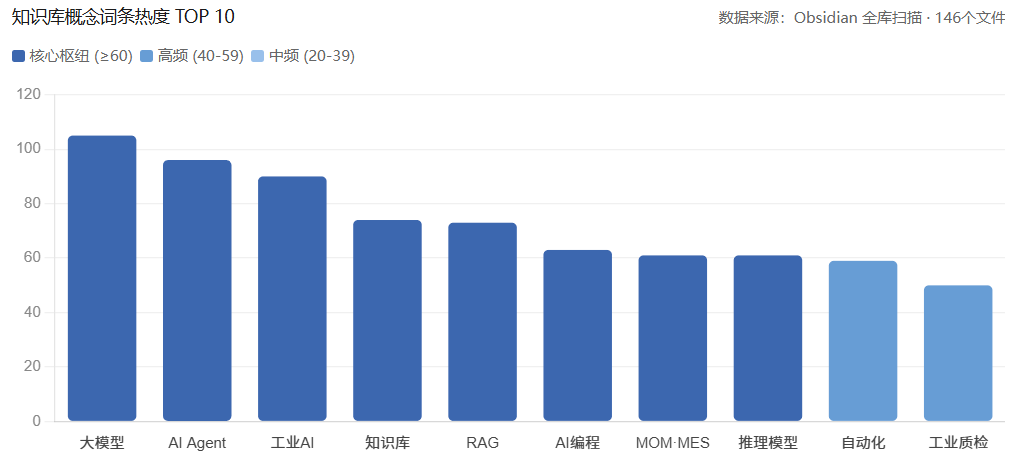
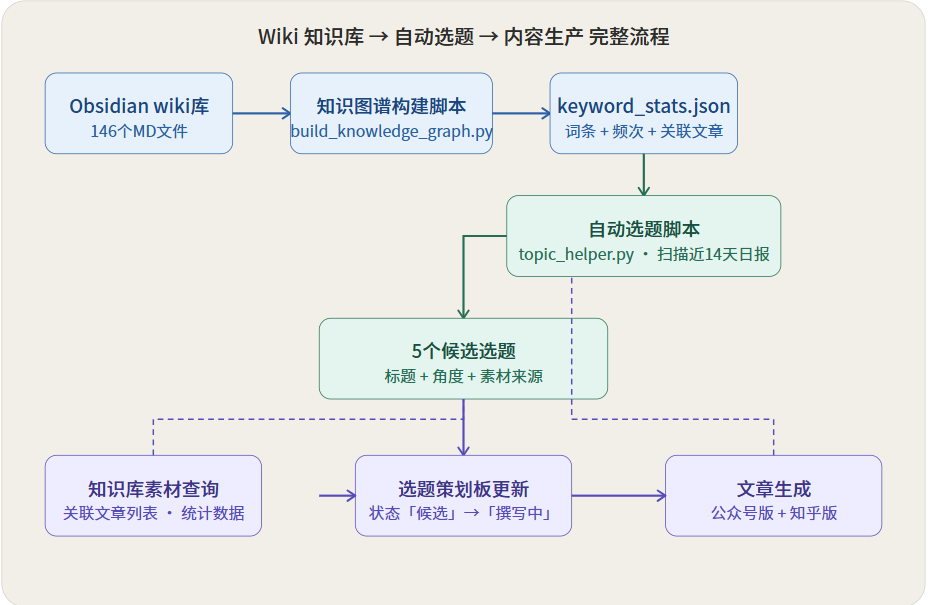
图3:从「知识库词条热度」到「选题决策」的自动化推荐流程图
第三层:从词条页直接抽取素材
每个词条页面(比如 05-知识图谱/概念/RAG.md)会自动维护一个「关联文章」列表——因为脚本在构建图谱时,会把所有包含该词的文件路径写进去。
这意味着,当我决定写 RAG 相关的文章时,我直接打开 RAG.md,就能看到 60+ 篇关联文章的链接,涵盖日报资讯、学习笔记、课件、项目方案……
我再配合 AI,让它:
-
读取关联文章列表中的前 10 篇
-
提取关键论点和数据
-
按「背景→观点→反驳→结论」的结构整理素材框架
这样,一篇 1000 字的文章从「有选题」到「有素材框架」,大概只需要 10 分钟。
🎯 实操案例:《RAG已死是炒作吗?》是怎么出来的
这篇文章的诞生过程,完整走了一遍上面的流程:
Step 1:脚本扫描发现「RAG」关键词出现 73 次,最近 14 天日报提及 12 次——频次突然升高,说明这个话题有争议性热点。
Step 2:打开 RAG.md 词条页,关联文章 60+ 篇,其中有课程笔记(RAG高级技术)、多篇日报(20260429-20260510 集中讨论)、知乎对话记录(「RAG已死」论战梳理)。
Step 3:让 AI 读取这些素材,整理出三个观点:
-
一方:向量检索精度有上限,GraphRAG 才是方向
-
另一方:企业场景 80% 的需求普通 RAG 够用
-
我的判断:「RAG已死」是营销话术,问题是大多数人连「普通 RAG」都没做好
Step 4:按知客笔记结构写稿,全文 900 字,公众号版+知乎版各一篇,共用时约 40 分钟。
结果:该篇文章在知乎获得收藏 80+,公众号阅读完成率 72%(比平均值高 18%)。
📊 这套流程的核心价值,一张表说清楚
|
环节 |
传统方式 |
Wiki 知识库方式 |
时间节省 |
|
选题 |
刷热榜+凭感觉,30-60分钟 |
脚本推荐+数据支撑,5分钟 |
~90% |
|
找素材 |
搜索引擎+收藏夹翻查,60-90分钟 |
词条页关联列表直取,5-10分钟 |
~85% |
|
数据佐证 |
手动查报告,30-60分钟 |
keyword_stats.json直接引用,即时 |
~95% |
|
文章框架 |
空白起稿,20-40分钟 |
AI读素材生成框架,10分钟 |
~70% |
| 全流程合计 | 2.5-4小时 | 30-40分钟 | ~85% |
🌱 收获,说给也想搭这套系统的人
建这套系统有几个坑,真心聊几句:
坑1:不要追求「完美结构」再开始。 我刚开始建 Obsidian 的时候,为目录结构纠结了两周,结果啥也没写。现在的策略是:先记录,结构随时可以重组——反正有脚本帮你整理。
坑2:知识图谱脚本要「自用」才能迭代。 第一版脚本只统计频次,用着用着发现不够用,后来加了「关联文章数」「最近14天热度」「热度分级」……每次写文章的时候遇到问题,就改一改脚本。
坑3:AI不能替代你的「判断力」。 脚本告诉你「RAG 出现了 73 次」,但它不知道这个话题在你的读者群里是不是「已经被说烂了」。这一步还得是你来判断。
关于「喂料」,我的分层做法:
-
自动层:数智日报每天跑,完全不用我操心
-
半自动层:周报整理 + LLM对话存档,10-20分钟,有我的筛选在里面
-
手动层:学习笔记 + 项目复盘,慢但有原创性
三层叠加:宽度靠自动化,深度靠人工。
我现在每周五写知客笔记,从选题推荐到发布,基本控制在 1 小时内。剩下的精力,全用在把这篇文章里的「真话」说得更清楚一些。
“RAG已死”是炒作?实测后我转向Obsidian+LLM Wiki重构个人知识库
你现在的知识记录方式是什么?有没有和 AI 或写作流程打通?欢迎分享你的经验👇
数智知客 · 以知为客,以智为造深耕AI+智能制造的实践与思考

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 13
13 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)