数智洞察:为什么企业数字化,困在了数据怎么用这一步?
罗克韦尔 2026 智能制造报告刚出炉,一组数据直接戳中了中国制造业的 “隐秘痛点”:中国制造企业 AI 采用率高达 44%,领跑全球;但我们辛辛苦苦采集的海量数据里,只有 43% 被真正有效利用。
一边是抢跑的 AI 普及率,一边是数据躺在硬盘里 “沉睡” 的现实。就在上周的项目沟通会上,客户抛来的问题,让我这个做了多年数字化的人,一时竟给不出满意的答案:“我们系统、设备都上了,数据也采全了,可这些数据到底帮我们解决了什么问题?”
今天就来聊聊,为什么那么多企业的数字化,最终都卡在了 “数据怎么用” ,“数据如何创造价值”这个死胡同里。
🤔 我的观察
近期在某大型制造集团正在推进IOT项目。方案交流那天,对方技术负责人突然停下来,认真地问了一个问题,大致意思:
"设备数据采集上来了,系统也集成了,但除了看监控大屏——数据怎么高效分析?怎么真正带来价值?未来怎么结合AI?"
现场安静了几秒。
这个问题不好答,但客户问得直击要害。因为说实话,我们行业里太多项目停在了"采到了"这一步,后面的事,大家都在摸索。
罗克韦尔发布第十一版年度《智能制造现状报告》验证了这件事——全球范围内,数据利用率都是个难题。但中国的情况有点特殊:我们AI采用率全球最高,说明大家在积极投入;但数据利用率不足一半。
报告中还有两组数据,更能直观感受到中国制造业对AI的热情与期待。
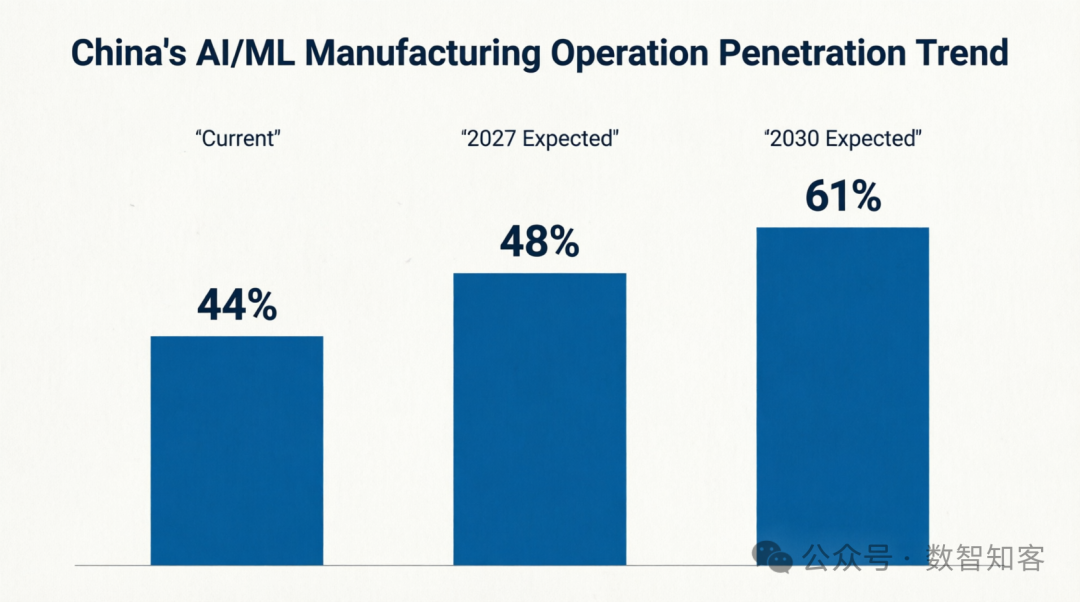
第一张趋势图清晰展示了中国制造业AI/ML运营的渗透率变化:
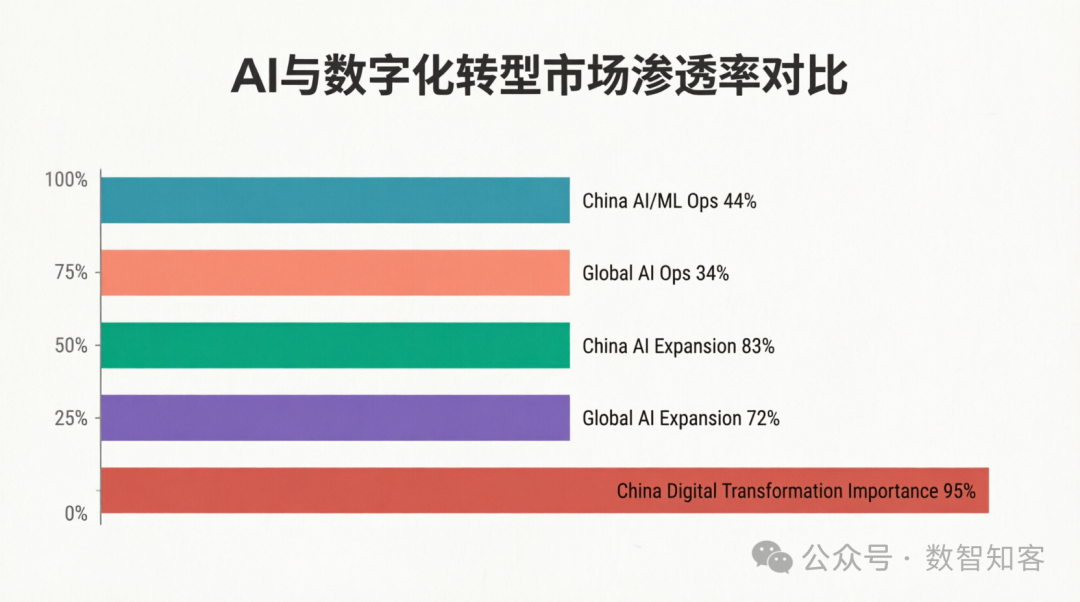
第二张对比图则进一步凸显了中国市场的领先优势:
-
• 中国制造业AI/ML运营渗透率(44%),远超全球平均水平(34%);
-
• 企业对AI扩展的意愿(83%),同样高于全球均值(72%);
-
• 更值得注意的是,高达95%的中国企业认为数字化转型至关重要。
一边是企业对数字化、AI的重视度与投入意愿全球领先,另一边却是数据有效利用率不足一半的现实,这种强烈的反差,说明"采"和"用"之间,断了一截。恰恰印证了本文的核心观点:行业的瓶颈,从来不是“要不要采数”,而是“怎么用好数据”。
💡 我的思考
困住企业数字化转型的三道坎,全卡在“用数据”上
我从项目实践中总结三道坎如下:
第一道坎:数据质量。 采上来的数据干净吗?缺失值怎么办?不同设备的时序对得上吗?很多项目采了半年才发现,数据质量根本支撑不了分析,更别说AI建模了。
第二道坎:业务对齐。 数据对应哪个决策场景?是谁来看?用来做什么决策?这些年做过很多数采项目,比如有个客户花了不小成本,给关键设备装上传感器,采了多维度的温度数据,结果是只出了温度曲线报表,但生产业务人员不知道它和工艺参数、产品良率有什么关系,更不知道该用它做什么决策。
第三道坎:AI准备度。 这是客户问得最多的——"未来我们要上AI,现在这些数据够不够?格式对不对?需不需要提前标注?"坦白说,大多数项目在采集阶段,并没有为AI应用场景做过设计。
这三道坎,本质上是同一个问题:数据采集的出发点,是"能采什么",而不是"要用来做什么"。
如何破除“用数据”困局?
其实这个困局,根子从来不在技术上,而在做事的顺序上。
前些年,工业物联网还很火热的时候,我们行已推进全量数据采集项目,习惯了一个固定的顺序:
先立项 → 再采集 → 做大屏可视化 → 然后呢?……
“然后”之所以成了无解的难题,是因为每个工厂的业务痛点、决策场景、人员习惯千差万别,没有通用的“数据使用手册”。
我觉得正确的顺序,应该是反过来的:
先想清楚要解决的业务问题→再倒推需要什么数据→精准采集→采完直接能用
这个逻辑听起来简单,落地却极难——“想清楚业务问题”,要求团队沉到产线一线,跟着操作工、班组长、车间主任走完整个决策流程,而非坐在会议室里对着PPT拍脑袋。
而AI时代的到来,让这个逻辑又多了一层要求:
数据采集不仅要对齐当下的业务问题,还要适配未来的智能决策。
过去,数据是“事后分析”的工具——出了故障调历史数据找原因,效率低且被动;但现在,AI驱动的设备异常预测、质量趋势预警、排产动态优化等场景,要求数据从采集之初,其粒度、频率、维度就为AI模型量身定制。今天采集的数据如果适配不了明天的AI应用,本质上就是另一种形式的浪费。
在这家制造集团的项目里,我们没有回避行业的共性难题,而是给出了最务实的方案:先聚焦一个核心业务场景跑通闭环,用“数据→分析→决策→价值”的真实链路,证明数据能用、能用出价值,再谈规模化扩展。这个思路,也得到了客户的认可。
🎯 所以呢
如果你正在推进或准备启动数字化项目,不妨在开会讨论数据采集方案时,先别急着聊“能连多少台设备”“能采多少维度数据”,先问一句:“这些数据连上来之后,你最想用它解决哪个具体问题?”
答不上来的,就先停一停采集的脚步。想清楚那个核心问题,数据的采集方案、粒度设计、存储结构,才会有明确的方向——毕竟数据从来不是采得越多越好,而是采得越准、越贴合业务需求越好。
💬 互动话题
你们工厂的数据采了之后,真正用起来了吗?最头疼的是哪一步——数据质量、业务对齐,还是不知道怎么结合AI?欢迎在评论区聊聊你们的真实情况👇
数智知客 · 以知为客,以智为造
深耕AI+智能制造的实践与思考

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 4
4 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)