电商项目核心技术五大解决方案
·
目录
一、分布式唯一 ID 生成解决方案
场景说明
- 电商系统中,商品 ID、SKU ID、订单 ID、支付流水号等数据,都要求全局唯一、有序、高可用
- 单机自增 ID 无法满足分布式集群、分库分表架构,因此需要专用分布式 ID 方案
UUID 算法
工作原理
- 基于时间、设备标识、随机因子生成 128 位字符串 ID,本地算法生成,不依赖外部服务
适用场景
- 临时标识、日志编号、非数据库主键场景
优缺点
- 优点:实现简单、无服务依赖、无性能瓶颈、天然全局唯一
- 缺点:无序字符串,MySQL 索引效率低;长度过长占用存储空间;可读性差,不建议做主键
手动分配(数据库自增 ID)
工作原理
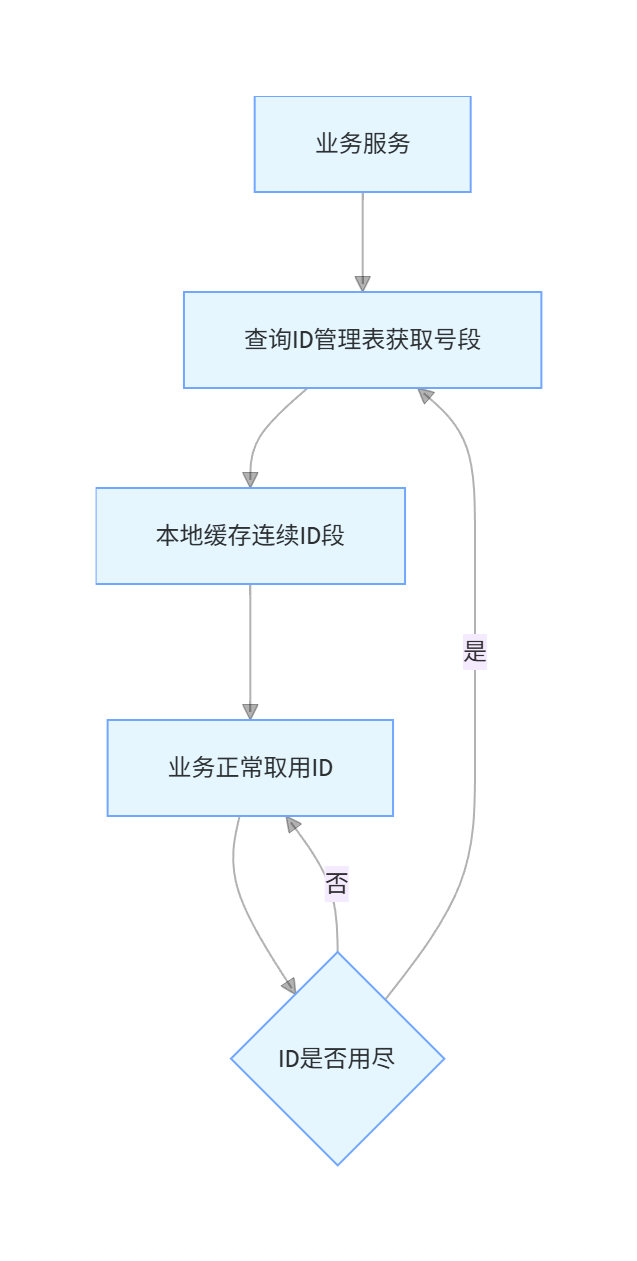
- 单独搭建一张 ID 管理表,统一维护各业务线当前最大 ID 与增长步长
- 业务服务批量拉取一段连续 ID 缓存到本地,耗尽后再重新拉取,减少数据库访问频次
流程示意图
适用场景
- 中小体量电商、并发量中等、追求简单稳定的业务
优缺点
- 优点:ID 有序递增、索引友好、规则可控
- 缺点:存在数据库单点风险;高并发下号段争抢易出现瓶颈;步长设置不合理易造成 ID 浪费
雪花算法(Snowflake)
结构说明
采用 64 位 Long 类型数字 ID,分段组合含义明确:
- 符号位:1 位,固定为 0,保证 ID 为正数
- 时间戳:41 位,毫秒级,可使用近 70 年
- 机器节点 ID:10 位,支持最多 1024 台服务节点
- 毫秒内序列号:12 位,单节点每毫秒可生成 4096 个 ID
结构模式图
0 | 41位时间戳 | 10位机器ID | 12位序列号整体工作流程
- 服务启动时配置唯一机器 ID,避免集群 ID 重复
- 每次生成 ID 先获取当前系统毫秒时间戳
- 同一毫秒内,序列号自增;序列号用尽则等待下一毫秒
- 多段数据按位拼接,生成最终全局唯一 ID
适用场景
- 高并发电商、分布式集群、分库分表架构,电商主键首选
优缺点
- 优点:高性能、趋势递增、索引友好、纯数字占用空间小、分布式适配性强。
- 缺点:强依赖服务器系统时间,时钟回拨会造成 ID 重复;需手动管理机器 ID
二、对象存储服务(文件上传)
场景说明
- 电商存在大量商品主图、详情图、轮播图、短视频、评价图片等静态资源
- 若将文件存储在业务服务器,会造成带宽压力大、扩容困难、访问缓慢等问题,行业统一采用对象存储 + CDN架构实现动静分离
整体架构模式图
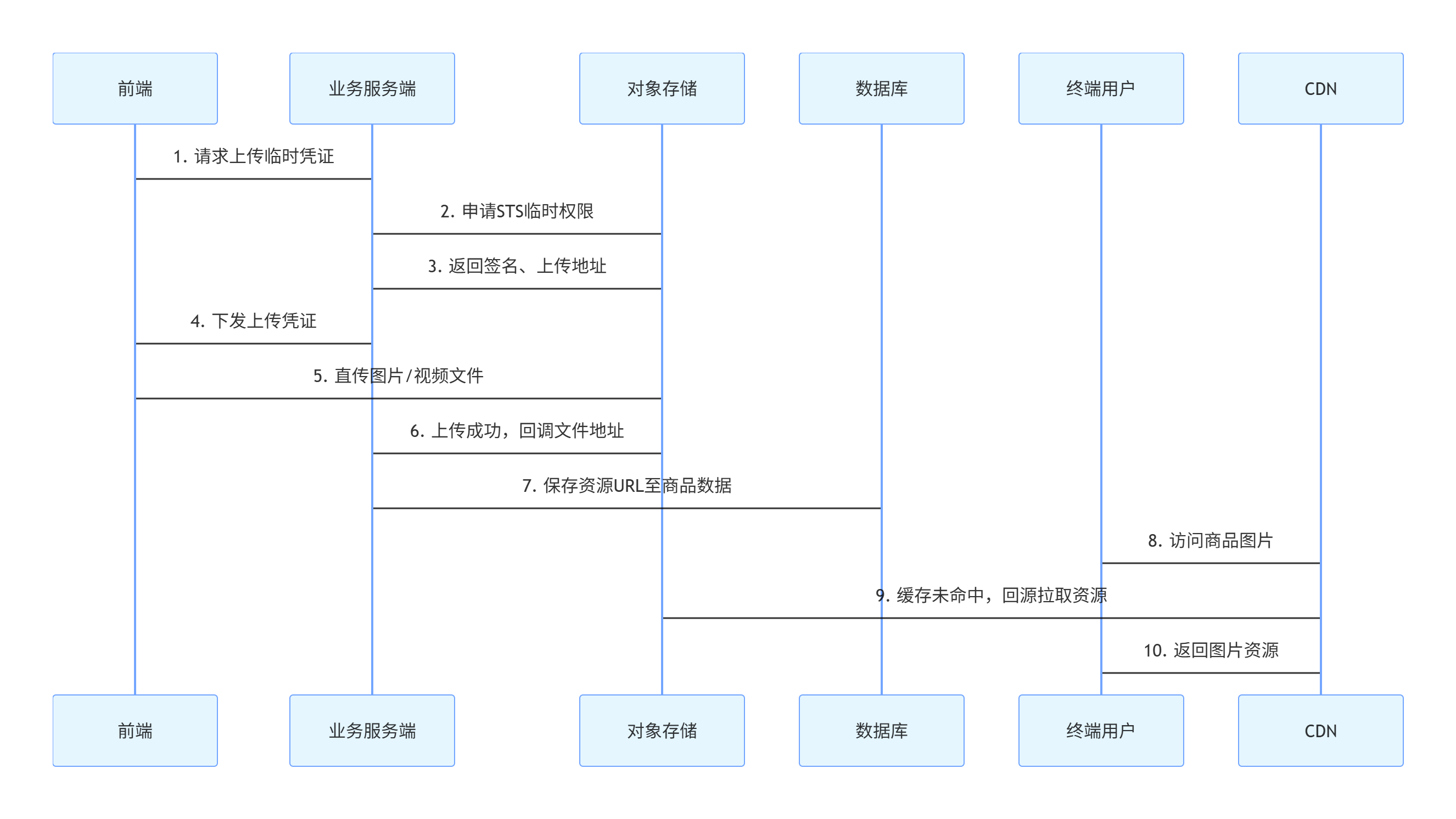
完整业务流程(前端直传模式,电商标准方案)
- 前端发起凭证请求:客户端携带文件信息,向业务服务端申请上传临时凭证
- 服务端生成签名:服务端调用对象存储接口,通过 STS 生成短期有效签名、上传地址、临时密钥,不泄露永久密钥
- 返回上传凭证:服务端将签名、上传地址返回给前端
- 前端直传文件:前端携带凭证,直接将文件上传至对象存储,不经过业务服务器中转
- OSS 异步回调:文件上传完成后,对象存储主动回调业务服务端,回传文件 URL、大小、格式等信息
- 业务数据落地:服务端将文件 URL 存入商品表、SKU 表等业务数据表
- 用户访问资源:用户浏览商品时,请求指向 CDN 节点;CDN 有缓存则直接返回,无缓存则回源至 OSS 拉取文件并缓存
时序流程图
核心规范与落地要点
- 采用前端直传,减轻业务服务器带宽与 IO 压力
- 使用临时签名机制,保障账号密钥安全
- 文件命名统一规则:雪花 ID + 后缀,避免重名覆盖
- 增加文件校验:限制格式、大小,拦截恶意文件
- 搭配 CDN 加速,提升全国用户访问速度
- 定时清理 OSS 中未关联业务数据的垃圾文件

三、SPU vs SKU(电商商品模型核心)
核心概念定义
电商商品最核心的数据模型,实现商品基础信息与销售规格信息解耦,是多规格商品管理的基础。
- SPU(标准产品单元) 代表一款产品的整体抽象,描述品牌、名称、分类、详情、基础参数等公共属性。一款 SPU 对应一类商品。 示例:华为 Mate 70、安踏运动跑鞋。
- SKU(库存保有单元) 代表具体可下单、可管理库存的最小销售单元,绑定规格、价格、库存、图片。用户下单本质是选购某一个 SKU。 示例:华为 Mate70 128G 黑色、安踏跑鞋 42 码 白色
模型关系模式图
SPU(商品整体) ├─ SKU1:规格A + 价格 + 库存 ├─ SKU2:规格B + 价格 + 库存 └─ SKU3:规格C + 价格 + 库存对应关系与业务价值
- 数据关系:一对多,一个 SPU 对应多个 SKU,一个 SKU 仅归属一个 SPU。
- 解耦价值:公共信息统一维护,避免大量数据冗余;规格、价格、库存单独管理,灵活支持促销、改价、控库存。
- 页面应用:前台展示商品列表基于 SPU,进入详情页后切换规格选择对应 SKU。
数据表设计规范
- SPU 表:存储商品名称、品牌、分类、详情、审核状态、上下架状态。
- SKU 表:关联 SPU ID,存储规格组合、售价、库存、单品图片、销售状态
四、商品管理涉及的实体类关系
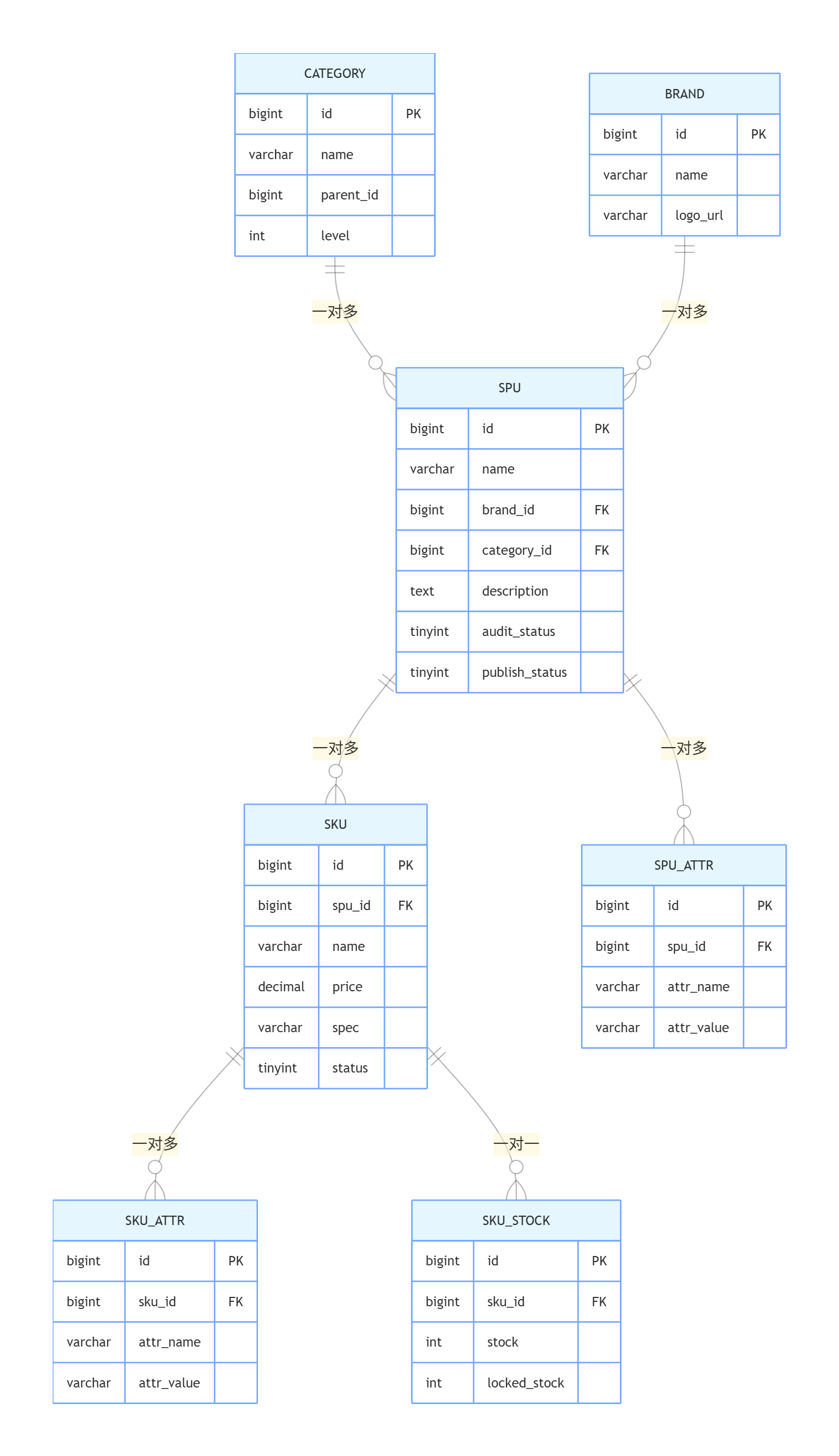
模块说明
商品体系并非只有 SPU、SKU,还包含分类、品牌、商品属性、库存等实体,多表关联构成完整商品数据体系。
实体 ER 关系图
核心实体关系说明
- 分类(Category)→ SPU:三级分类(一级 - 二级 - 三级),每个三级分类下有多个 SPU
- 品牌(Brand)→ SPU:一个品牌对应多个 SPU,SPU 必须关联一个品牌
- SPU → SKU:一个 SPU 对应多个 SKU,SKU 通过
spu_id关联 SPU- SPU → SPU_ATTR:SPU 的平台属性(如型号、产地),用于商品筛选
- SKU → SKU_ATTR:SKU 的销售属性(如颜色、尺寸),用于规格选择
- SKU → SKU_STOCK:一对一关联库存表,管理实际库存与锁定库存(下单锁定)
五、商品的上架和下架流程设计
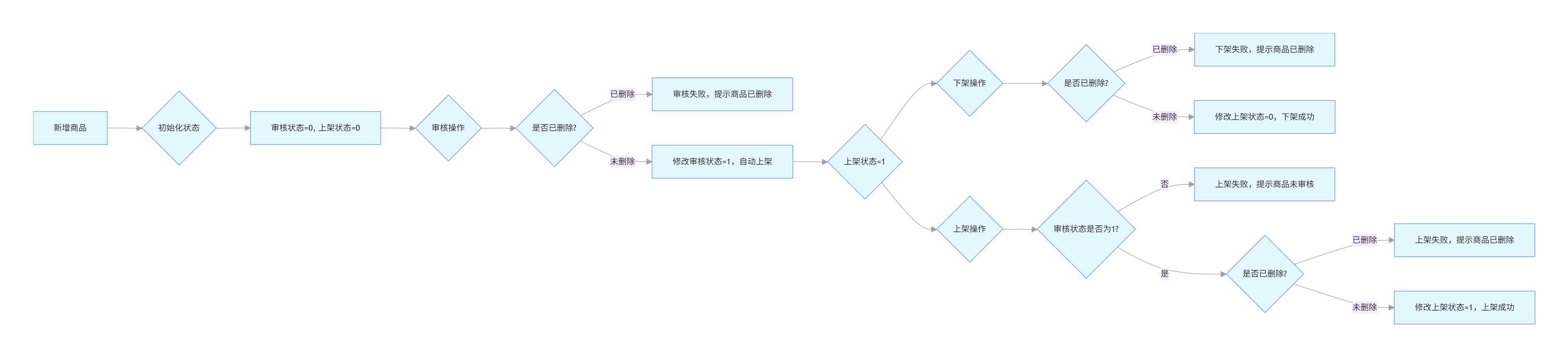
状态定义
状态类型 数值 含义 审核状态 0 未审核 审核状态 1 已审核 上下架状态 0 下架(不可售卖) 上下架状态 1 上架(正常售卖) 逻辑删除 0 正常商品 逻辑删除 1 已删除商品 整体业务流程图
关键业务规则
- 新增商品:默认审核状态为 0(未审核),上架状态为 0(下架),不对外展示
- 审核流程:
- 校验商品是否被逻辑删除,已删除商品无法审核
- 审核通过后,自动将上架状态改为 1,商品可对外销售
- 下架流程:
- 校验商品是否被逻辑删除,已删除商品无法下架
- 直接修改上架状态为 0,商品从前端列表隐藏,无法下单
- 上架流程:
- 校验审核状态是否为 1,未审核商品无法上架
- 校验商品是否被逻辑删除,已删除商品无法上架
- 校验通过后,修改上架状态为 1,同时更新 SKU 表状态为 1
- 数据同步规则:
- 商品上架时,必须先插入 SPU 主表数据,再插入对应的 SKU 数据(先一方,后多方)
- 上架失败时,需回滚已插入的 SKU 数据,避免数据不一致
- 下架时,需同时修改 SPU 和所有关联 SKU 的状态为 0
核心业务约束
- 未审核商品不允许上架,把控平台内容合规性。
- 已逻辑删除商品,审核、上下架全部禁用。
- SPU 上下架时,同步联动所有关联 SKU 状态,保证数据一致性。
- 上架瞬间同步商品数据至搜索索引、缓存,保证前端实时生效。
- 下架商品保留数据,支持重新编辑、重新上架,不物理删除数据。
六、方案整体总结
技术模块 最优解决方案 核心作用 分布式 ID 雪花算法 保证主键全局唯一、适配分布式与分库分表 文件存储 对象存储 OSS + CDN 动静分离,减轻服务压力,加速静态资源访问 商品模型 SPU + SKU 拆分模型 解耦公共信息与规格库存,适配多规格商品 实体关系 分类 / 品牌 / 属性 / 库存 多表关联 搭建完整商品数据体系,支撑搜索、筛选、售卖 商品上下架 审核 + 上下架双状态管控 规范商品发布流程,保障平台合规与业务可控

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 8
8 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)