《Java 100 天进阶之路》第85篇:SQL优化实战(2026版)
第85篇:SQL优化实战(2026版)
📌 系列导航:《Java 100 天进阶之路》完整目录 |
⬅️ 上一篇:第84篇:MySQL事务与锁 |
➡️ 下一篇:第86篇:MyBatis核心原理(待发布)
一、核心知识点
- 慢查询日志:开启、分析、阈值设置
- EXPLAIN 执行计划:
type、key、rows、Extra关键字段解读(附 B+ 树图解) - 索引优化:覆盖索引、索引下推、最左前缀、三星索引原则
- 分页优化:深分页问题与解决方案(延迟关联、键集分页、游标分页)
- COUNT 优化:
COUNT(*)vsCOUNT(列),大数据量替代方案(Redis、统计表) - JOIN 优化:小表驱动大表,索引连接字段,避免笛卡尔积
- SQL 改写技巧:
OR转UNION、IN转EXISTS、避免函数操作 - MySQL 8.0+ 新特性:窗口函数实战对比、通用表表达式(CTE)、降序索引、不可见索引
二、通俗讲解(1分钟开心学)
1. 慢查询日志——SQL 性能的“体检报告”
慢查询日志记录执行时间超过阈值的 SQL,是定位性能问题的第一把刀。
生活类比:
就像公司给员工做体检,查出那些“耗时过长”的体检项,重点排查。
2. EXPLAIN——SQL 的“CT 扫描仪”
通过 EXPLAIN 可以看到 MySQL 如何执行你的 SQL:有没有用索引、扫描了多少行、是否用了文件排序等。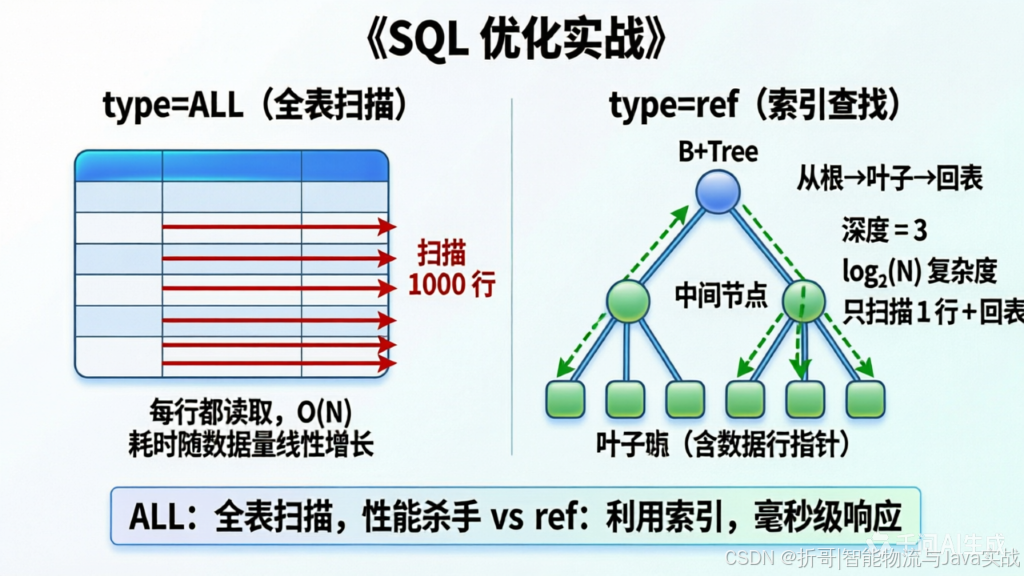
图解说明:
- type=ALL:全表扫描,就像把整本书从头到尾翻一遍。
- type=ref:通过索引快速定位,就像查字典的目录页,直接跳到对应页码。
(建议此处插入 EXPLAIN 执行流程图,展示 B+Tree 索引查找过程,直观对比ALL与ref的扫描路径差异)
3. 深分页——为什么 LIMIT 100000,10 越来越慢?
LIMIT 100000,10 会先扫描前 100010 行,再丢弃前 100000 行,导致大量无效 I/O。
生活类比:
从一本书的第 1000 页开始往后读 10 页,但你不得不先翻过前 999 页。优化方式是先记住第 1000 页的页码(主键),直接跳过去。
4. 三星索引原则
来自《高性能 MySQL》,一条查询使用的索引达到以下三个星级的越多,性能越好:
- 一星:索引将等值匹配的列放在最前面(
WHERE col = value)。 - 二星:索引的顺序与
ORDER BY一致,避免文件排序。 - 三星:索引包含
SELECT中所有列(覆盖索引),避免回表。
SQL优化实战必知的三星索引原则。
三、实操代码案例 + 场景说明
测试表:订单表
orders,数据量 500 万。
CREATE TABLE `orders` (
`id` bigint NOT NULL AUTO_INCREMENT,
`user_id` int NOT NULL,
`order_no` varchar(32) NOT NULL,
`amount` decimal(10,2) DEFAULT NULL,
`status` tinyint DEFAULT '0',
`create_time` datetime DEFAULT CURRENT_TIMESTAMP,
`update_time` datetime DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (`id`),
KEY `idx_user_id` (`user_id`),
KEY `idx_create_time` (`create_time`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
3.1 慢查询日志配置与查看
-- 查看慢查询日志状态
SHOW VARIABLES LIKE 'slow_query_log%';
SHOW VARIABLES LIKE 'long_query_time';
-- 临时开启(重启失效)
SET GLOBAL slow_query_log = ON;
SET GLOBAL long_query_time = 2; -- 超过2秒记录
-- 永久配置(修改 my.cnf)
[mysqld]
slow_query_log = 1
slow_query_log_file = /var/log/mysql/slow.log
long_query_time = 2
log_queries_not_using_indexes = 1
分析慢查询日志:
# 使用 mysqldumpslow 工具
mysqldumpslow -s t -t 10 /var/log/mysql/slow.log
3.2 EXPLAIN 执行计划深度解读
| 字段 | 最优值 | 说明 |
|---|---|---|
type |
const > eq_ref > ref > range > index > ALL |
ALL 表示全表扫描,必须优化 |
key |
实际使用的索引名 | NULL 表示未使用索引 |
rows |
越小越好 | 估算扫描的行数 |
Extra |
Using index(覆盖索引)、Using index condition(ICP) |
避免 Using filesort、Using temporary |
典型优化案例:
-- 待优化的 SQL
SELECT * FROM orders WHERE order_no = 'ORD123456';
EXPLAIN SELECT * FROM orders WHERE order_no = 'ORD123456';
-- type: ALL,rows: 全表,未使用索引
-- 优化:加索引
ALTER TABLE orders ADD INDEX idx_order_no (order_no);
EXPLAIN SELECT * FROM orders WHERE order_no = 'ORD123456';
-- 结果:type: ref,rows: 1,Extra: NULL
3.3 MySQL 8.0+ 窗口函数实战
场景:查询每个用户的最新订单(按 create_time 排序)。
-- 【旧写法】低效,需要子查询聚合
SELECT o1.* FROM orders o1
WHERE o1.create_time = (SELECT MAX(create_time) FROM orders o2 WHERE o2.user_id = o1.user_id);
-- 性能差,可能用到临时表
-- 【新写法】窗口函数,扫描一次即得,
WITH latest AS (
SELECT *, ROW_NUMBER() OVER (PARTITION BY user_id ORDER BY create_time DESC) AS rn
FROM orders
)
SELECT * FROM latest WHERE rn = 1;
-- 性能更好,逻辑清晰
💡 窗口函数优势:扫描全表一次,利用内存排序,避免多次回表和子查询。
3.4 深分页优化(从原理到最佳实践)
(1)低效写法:
SELECT * FROM orders ORDER BY id LIMIT 100000, 10;
-- 扫描 100010 行,丢弃 100000 行
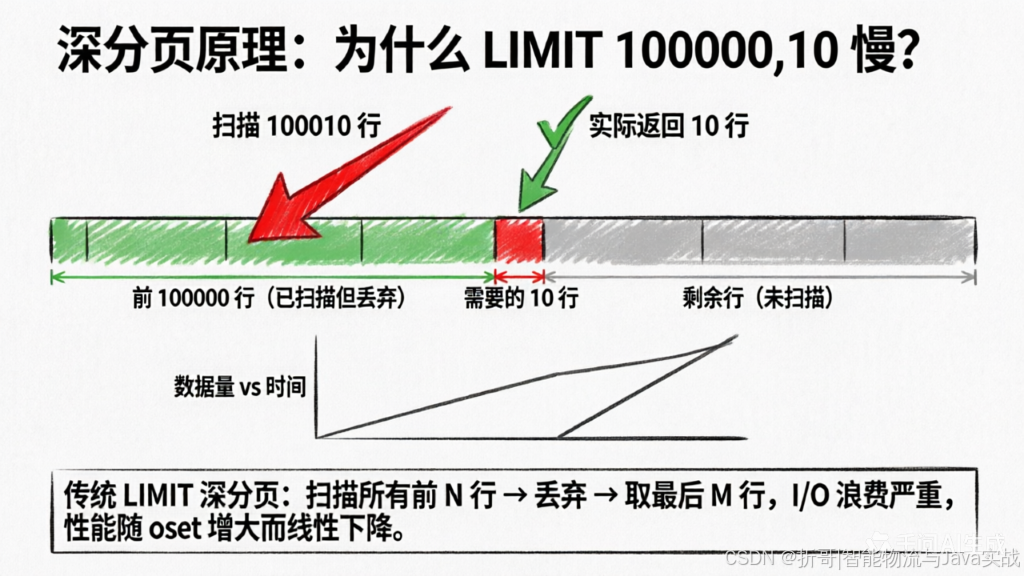
(2)延迟关联(通用方案):
SELECT * FROM orders o1
JOIN (SELECT id FROM orders ORDER BY id LIMIT 100000, 10) o2 ON o1.id = o2.id;
-- 重点:子查询仅扫描主键,走覆盖索引,不回表
(3)键集分页(Keyset Pagination,适合顺序翻页):
-- 仅适用于 id 自增且连续(不能跳页)
SELECT * FROM orders WHERE id > 100000 ORDER BY id LIMIT 10;
(4)游标分页(Cursor-based,适合 API 设计):
-- 将上一页最后一条记录的排序字段(如 id 或 create_time)编码为 Token 传参
-- 例如客户端传来 last_id = 100000
SELECT * FROM orders WHERE id > 100000 ORDER BY id LIMIT 10;

💡 2026年趋势:微服务接口推荐使用游标分页,避免前端传参篡改 offset,且性能恒定(无论翻到第几页,耗时都是 O(1))。
3.5 COUNT 优化与大数据量替代方案
-- 统计所有行(推荐)
SELECT COUNT(*) FROM orders; -- 走最小二级索引
-- 统计 status=1 的行数(走索引)
ALTER TABLE orders ADD INDEX idx_status (status);
SELECT COUNT(*) FROM orders WHERE status = 1; -- 走 idx_status
⚠️ 避坑:当单表数据量达到数亿级时,COUNT(*) 仍然可能很慢。解决方案:
- 方案A(近似值):使用
SHOW TABLE STATUS获取近似行数(误差可达 50%)。 - 方案B(实时精确值):使用 Redis 原子计数器(
INCR/DECR)实时维护。 - 方案C(离线统计):定期汇总到统计表(如每天凌晨计算)。
3.6 JOIN 优化与“小表驱动大表”
-- 低效:大表驱动小表
SELECT * FROM large_table l JOIN small_table s ON l.key = s.key;
-- 优化:保证小表在前,且连接字段有索引
SELECT * FROM small_table s JOIN large_table l ON s.key = l.key;
-- 同时 l.key 必须有索引
⭐ 三星索引应用示例:
-- 查询:SELECT user_id, order_no FROM orders
-- WHERE user_id=123 AND status=1
-- ORDER BY create_time LIMIT 10;
-- 三星索引设计:
ALTER TABLE orders ADD INDEX idx_user_status_time_no (user_id, status, create_time, order_no);
-- 一星:user_id, status 等值匹配 ✅
-- 二星:order by create_time 已在索引中 ✅
-- 三星:SELECT 中的 order_no 也在索引末尾,完全覆盖,无需回表 ✅
3.7 SQL 改写技巧与 MySQL 8.0 新特性
-- 1. OR 转 UNION(避免索引合并失效)
SELECT * FROM orders WHERE user_id = 123
UNION
SELECT * FROM orders WHERE order_no = 'ORD123';
-- 2. IN 转 EXISTS(子表较大时)
SELECT * FROM orders o
WHERE EXISTS (SELECT 1 FROM users u WHERE u.id = o.user_id AND u.vip = 1);
-- 3. 避免函数操作
-- 错误:WHERE DATE(create_time) = '2026-01-01'
-- 正确:WHERE create_time >= '2026-01-01' AND create_time < '2026-01-02'
-- 4. 通用表表达式(CTE)提高可读性
WITH vip_users AS (SELECT id FROM users WHERE vip = 1)
SELECT * FROM orders WHERE user_id IN (SELECT id FROM vip_users);
四、避坑要点
| 问题 | 错误写法 | 后果 | 正确做法 |
|---|---|---|---|
| 隐式类型转换 | WHERE order_no = 123 |
不走索引 | 保证字段类型匹配 |
| 前模糊匹配 | WHERE name LIKE '%abc' |
全表扫描 | 改为后模糊,或用 ES |
| 索引列参与运算 | WHERE id + 1 = 100 |
不走索引 | 等号两边独立运算 |
| 使用 OR 连接不同列 | WHERE a=1 OR b=2 |
可能不走索引 | 拆分为 UNION |
| SELECT * | 返回所有列,包含不需要的 | 浪费 I/O,无法覆盖索引 | 只查需要的列 |
| LIMIT 大偏移量 | LIMIT 100000,10 |
深分页性能差 | 延迟关联或游标 |
| COUNT(列) 统计行数 | COUNT(非索引列) |
慢 | 用 COUNT(*) |
| JOIN 字段类型不一致 | varchar vs int |
索引失效 | 统一字段类型 |
| MySQL 8.0 统计信息过期 | 优化器选错索引 | ANALYZE TABLE 更新 |
定期执行 |
五、面试高频考点(2026版)
Q1:如何定位慢 SQL?
开启慢查询日志,设置
long_query_time,分析慢查询日志文件,使用mysqldumpslow或 pt-query-digest。
Q2:EXPLAIN 的 type 列有哪些值?从好到差排序?
system>const>eq_ref>ref>range>index>ALL。ALL是全表扫描,必须优化。
Q3:深分页的三种优化方案?
延迟关联(通用)、键集分页(顺序翻页)、游标分页(API 设计)。其中游标分页在 2026 年的微服务架构中最常用。
Q4:COUNT(*) 在大数据量下的替代方案?
用 Redis 计数器、
SHOW TABLE STATUS(近似值)、或定时统计表。
Q5:什么是“三星索引”?
一星:等值匹配列在前;二星:索引顺序与 ORDER BY 一致;三星:覆盖索引。根据业务查询设计索引时,尽可能满足更多星。
Q6:JOIN 优化原则?
小表驱动大表;连接字段建索引;避免
SELECT *;尽量用INNER JOIN而非LEFT JOIN(业务允许时)。
Q7:MySQL 8.0 有哪些新特性可用于 SQL 优化?
窗口函数(替代复杂子查询)、CTE(提高可读性)、降序索引、不可见索引(安全测试)、直方图(优化器统计信息增强)。
六、练习题
-
分析:有一张 1000 万行日志表
logs,查询SELECT * FROM logs WHERE create_time > '2026-01-01' AND type = 'ERROR'非常慢,如何优化?💡 思路:建立联合索引
(type, create_time),按等值查询在前、范围查询在后的原则;若只查部分字段,可建覆盖索引。 -
改错:
SELECT * FROM user WHERE YEAR(birthday) = 1990,如何改写以使用索引?💡 思路:改为
birthday BETWEEN '1990-01-01' AND '1990-12-31'。 -
代码:模拟一个深分页查询,使用延迟关联优化前后对比,统计执行时间。
📊 你的学习进度
- 当前:第85篇 / 共108篇 · 进阶篇:数据库与持久层框架(第83~90篇)
- ✅ 已完成:基础篇44篇 + 第91~ 96篇(Redis/MQ)+ 第83~85篇
- 📖 正在学:第85篇
- ⏳ 待学习:第86~ 90篇(MyBatis/JDBC等)+ 第97~108篇
👉 📚 完整目录 & 学习指南 | 🔥 订阅本专栏,不错过每一篇
💡 本专栏每篇都包含:避坑表 + 面试高频考点 + 练习题。每天30分钟,100天拿offer!
👉 下一篇文章预告
《第86篇:MyBatis核心原理(2026版)》
内容简介:MyBatis 核心组件(SqlSession、Executor、StatementHandler)、动态 SQL 解析原理、一级/二级缓存机制、
#{}vs${}区别、Spring 整合原理、源码阅读技巧。
💡 学完这篇,你将彻底理解 MyBatis 底层原理,面试不再怕“MyBatis 缓存”问题。
🎁 福利提醒:评论区留言“SQL优化”可领取《SQL 优化实战清单与 EXPLAIN 速查表》PDF。
📌 《Java 100 天进阶之路 | 从入门到上岗就业》 每天一篇,建议收藏 + 关注,一起100天拿offer!
👉 点击关注我,更新后第一时间收到推送!

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 13
13 0
0- 0



 已为社区贡献20条内容
已为社区贡献20条内容

所有评论(0)