简单聊聊移到GPU上训练自己的模型(生搬硬套版)
前几天有粉丝私信我默认是在cpu上,怎么在GPU上训练自己的模型。这里a哥就来简单聊聊这件事情。
为什么需要在GPU上
核心区别:一个天才 vs. 一群小学生
CPU (中央处理器) = 一位博学的老教授
特点:他脑子特别灵光,逻辑能力极强,擅长处理各种复杂的、需要动脑筋的突发状况(比如判断“如果下雨就带伞,否则不带”)。
缺点:他只有一个大脑(核心少)。让他去算那几亿个小题目,他必须一个一个地按顺序算。
结果:算完所有题,可能需要几天甚至几个月。
GPU (图形处理器/CUDA) = 几千名小学生
特点:他们每个人都不如老教授聪明,处理复杂逻辑不行。但是,他们有成千上万个人(核心多),而且大家动作整齐划一。
优势:对于大模型训练这种任务,其实大部分工作就是简单的加减乘除。
操作:老教授让这几千个小学生每人负责算一点点。
结果:虽然每个人慢一点,但因为人太多,大家一起算,几秒钟就能把老教授几天的活干完了。
结论:大模型训练本质上就是重复做大量简单的计算,这正是 GPU 最擅长的,而 CPU 在这种场景下就像“杀鸡用牛刀”,效率太低。
除了算得快,还有一个关键问题:数据怎么给到计算器?
CPU 的情况:
想象数据存在仓库(硬盘)里,CPU 住在离仓库很远的地方。每次要算一个数,CPU 得亲自跑一趟仓库拿回来,再跑回来算。因为路窄(内存带宽低),一次只能拿很少的东西,大部分时间都在路上跑,没时间在算。
GPU 的情况:
GPU 旁边有一条超级宽的高速公路(HBM 显存带宽)。
仓库(硬盘)先把一大堆数据直接通过高速公路运到 GPU 旁边的“临时堆放点”(显存)。
因为路太宽了,一次能运走几十吨数据。
GPU 拿到数据后,不用等,立刻开始让那几千个小学生疯狂计算。
结论:GPU 不仅算得快,而且取货也快,不会让计算器闲着等数据。
如何移动到cuda上?
多数情况下可以生搬硬套:
配置的位置:
紧接着导包代码下面:
device = "cuda" if torch.cuda.is_available() else "cpu"
其他位置:
创建(实例化)模型处代码后加 .to(device)
构建损失函数代码处加 .to(device)
在遍历数据加载对象代码处,对训练的特征和标签加上 .to(device)
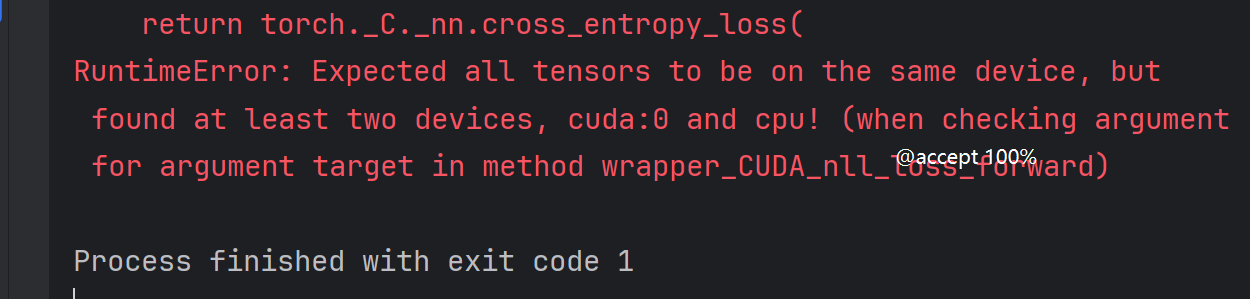
tips:如果遇到一下报错,可能是因为有些数据没有移到cuda上。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 10
10 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)