AI狼人杀评测系统技术解析
一、简要介绍
在 AI 狼人杀项目中,为了评估 AI 玩家在游戏中的表现,方便用户了解自身情况以及日后为了筛选出优质策略提供一个评分标准,我们实现了一套完整的评测体系。本文将深入解析这一系统的技术设计与实现细节。
在ai狼人杀中,我们不能只考虑游戏是否胜利,还得考虑到如下情况:这些都是我们所不能忽视的,可能其中的一小步就会影响到整个游戏的走向
多维度的决策空间:发言、投票、技能使用、身份隐藏。
信息的不对称性:每个角色只知道部分信息。
长期策略与短期博弈的交织:既要隐藏身份,又要推动局势。
难以量化的社交能力:说服力、感染力、逻辑推理。
为了解决这个问题,我们专门设计了一套组织架构来收集对局的游戏信息并进行一个打分。框架图如下所示:
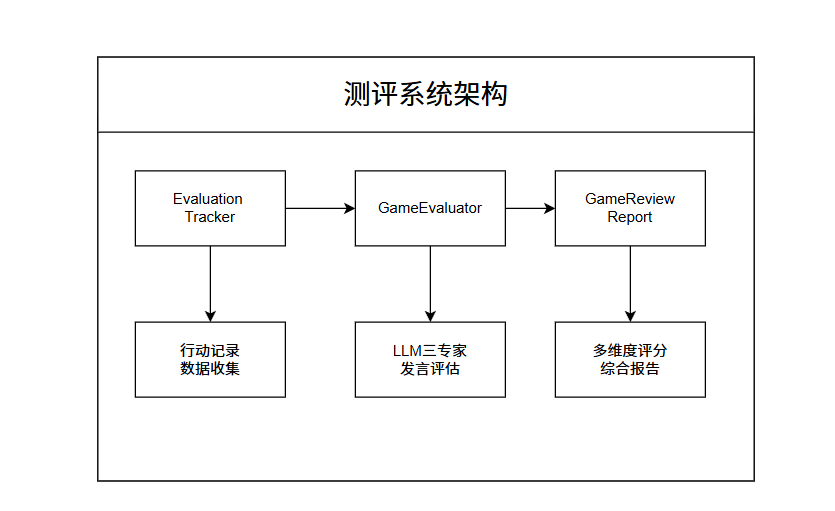
这主要由以下四部分组成:1.EvaluationTracke用于游戏过程数据收集,在游戏开始时就记录数据,每次关键节点结束后就会开始收集相应的数据,在游戏结束后就会根据这些数据来计算本局游戏的策略的评分。2.GameEvaluator是核心评测引擎,也是我们设计的重点,来对收集的数据进行计算得到本局游戏策略评分。3.LLMSpeechEvaluator基于 LLM 的三专家评估系统。4.GameReviewReport用于最终复盘报告生成。
二、详细实现
对于测评系统,我们主要是从发言质量、投票决策质量、角色功能实现这三个方面来进行的一个评估。
对于发言质量我们采用的是双轨评分机制:
# 规则评分 + LLM 评分
speech_score_combined = speech_score * 0.3 + speech_score_llm * 0.7我们把评分系统主要重点集中在大语言模型上,由大预言模型对于游戏过程中的步骤等进行一个评分,这样可以减少我们对于规则评分的设计难度,也可以保证评分的准确可靠性。
规则评分基于发言长度和内容丰富度:
def _evaluate_speeches(self, player_id: str) -> float:
player_speeches = [...]
for speech in player_speeches:
content = speech.get("content", "") or ""
length = len(content)
# 基础分:基于长度
if length < 20:
base_score = 30.0 # 太短
elif length < 50:
base_score = 60.0 # 适中
elif length < 150:
base_score = 80.0 # 较好
else:
base_score = 90.0 # 详细LLM 评分则通过三专家系统进行深度评估。
投票评分考虑阵营视角:对于不同的角色,投给敌对的角色就可以加分,如果投给同阵营的就会进行一个相应的扣分。
def _evaluate_votes(self, player_id: str) -> float:
player_camp = self._get_player_camp(player_id)
for vote in player_votes:
target_camp = self._get_player_camp(vote["target"])
if player_camp == "wolf":
# 狼人视角
if target_camp == "good":
total_score += 80.0 # 投对好人阵营 ✓
else:
total_score += 20.0 # 投给狼队友 ✗
else:
# 好人视角
if target_camp == "wolf":
total_score += 90.0 # 投对狼人 ✓
else:
total_score += 40.0 # 投错好人 ✗鉴于每个角色的功能,我们都对其功能设计了不同的评分系统,这样可以体现他们功能决策的重要性:
预言家 (Seer) 其核心指标就是查验狼人命中率,这个主要由查验到狼人数量 / 狼人总数来计算。
def _evaluate_seer_skill(self, player_id: str) -> float:
seer_checks = self.records.get("seer_checks", {}).get(player_id, [])
wolves_found = sum(1 for check in seer_checks if ":Wolf" in check)
total_wolves = sum(1 for role in self.roles.values() if role == "Wolf")
return (wolves_found / total_wolves) * 100.0女巫 (Witch) 其核心指标就是药水使用效率,由是否给好人使用药或者对狼人使用毒来计算。
def _evaluate_witch_skill(self, player_id: str) -> float:
witch_uses = self.records.get("witch_uses", {}).get(player_id, [])
good_saved = 0 # 救人次数
wolf_poisoned = 0 # 毒狼次数
for use in witch_uses:
if use.startswith("save:"):
target = use.split(":")[1]
if self._get_player_camp(target) == "good":
good_saved += 1
elif use.startswith("poison:"):
target = use.split(":")[1]
if self._get_player_camp(target) == "wolf":
wolf_poisoned += 1
return ((good_saved + wolf_poisoned) / len(witch_uses)) * 100.0接下来就是身份推断准确率:这个主要考虑的是衡量对他人的身份判断能力。
def _evaluate_irp(self, player_id: str) -> float:
player_votes = self.records.get("vote_records", [])
correct = 0
player_camp = self._get_player_camp(player_id)
for vote in player_votes:
target_camp = self._get_player_camp(vote["target"])
# 投票给敌对阵营算正确
if player_camp != target_camp:
correct += 1
return correct / len(player_votes)最后,我们加入了投票成功率:这个我觉得也会体现决策能力的一种要素,如果只有自己推断出来了,但是没人跟投,只能说明策略太差了。也是体现玩家策略能力的一个重要的方面。
def _evaluate_vss(self, player_id: str) -> float:
voted_out = {d["player_id"]: d for d in death_records if d["cause"] == "vote"}
successful = 0
for vote in player_votes:
target = vote["target"]
if target in voted_out:
voter_camp = self._get_player_camp(player_id)
target_camp = self._get_player_camp(target)
if voter_camp != target_camp:
successful += 1
return successful / len(player_votes)接下来的就是对LLM 三专家评估系统详细描述。这部分是我认为最重要的一部分,因为上述的规则评分都是基于数据的,他没法对于每个玩家决策时候的想法,发言的内容进行具体的评估。通俗来讲,传统规则评分只能评估发言的"形"(长度、格式),无法评估"神"(逻辑、策略、信息价值)。我们就可以通过 LLM 模拟三位不同视角的专家,可以获得更全面的评估。
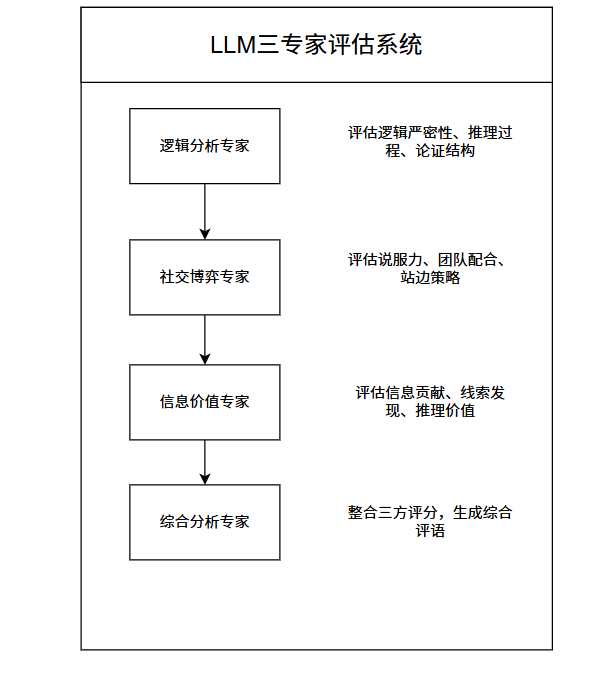
对于具体实现,我们还是使用 DSPy 的 ChainOfThought 实现带推理过程的评分:
class LogicAnalystSignature(dspy.Signature):
"""
你是狼人杀游戏中的【逻辑分析专家】。
你的职责是评估玩家发言的逻辑质量:
- 推理是否严密、前后一致
- 论据是否充分、论证是否有力
- 是否存在逻辑漏洞或自相矛盾
- 是否有清晰的论证结构
评分标准 (0-100):
- 90-100: 逻辑严密,推理清晰,无漏洞
- 70-89: 逻辑较好,论证基本合理
- 50-69: 逻辑一般,有一定论证但不够严密
- 30-49: 逻辑较差,存在明显漏洞或矛盾
- 0-29: 逻辑混乱,前后矛盾
"""
speech_content = dspy.InputField(desc="玩家的发言内容")
game_context = dspy.InputField(desc="游戏上下文")
player_role = dspy.InputField(desc="该玩家的角色身份")
player_camp = dspy.InputField(desc="该玩家的阵营")
expert_name = dspy.OutputField(desc="专家名称")
score = dspy.OutputField(desc="逻辑评分 (0-100)")
reasoning = dspy.OutputField(desc="评分理由")
strengths = dspy.OutputField(desc="优点列表")
weaknesses = dspy.OutputField(desc="缺点列表")
suggestions = dspy.OutputField(desc="改进建议")对于三位专家的结果我们进行汇总,并交由综合分析专家进行最后总结:
三位专家独立评分后,取平均值作为最终 LLM 评分
class LLMSpeechEvaluator:
def evaluate(self, ...) -> LLMSpeechEvaluation:
# 三位专家独立评估
logic_score = self.logic_expert(speech_content=..., ...)
social_score = self.social_expert(speech_content=..., ...)
info_score = self.info_expert(speech_content=..., ...)
# 综合评分 = 三位专家平均分
final_score = (
logic_score.score +
social_score.score +
info_score.score
) / 3
# 生成综合分析
consensus = self.consensus_module(...)
return LLMSpeechEvaluation(
logic_score=logic_score,
social_score=social_score,
info_score=info_score,
final_score=final_score,
consensus_analysis=consensus,
)三、结语
这是一次将 AI 评测从"结果导向"推向"过程导向"的尝试。通过多维度、多专家的评估框架,我们能够更全面地理解 AI 玩家在复杂社交推理游戏中的表现。也为未来构建决策选择提供了一套合适的评分系统。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 8
8 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)