LLM —— Milvmus向量数据库
目录
1.1 FLAT:适合小型,百万型。(不建议 - 暴力搜索)
1.2 IVF_FLAT: 是一种基于倒排的索引方法。(比较常用)
一、什么是数据库
数据库可以按数据模型和使用场景来分。
简单概况就是:
关系型数据库适合结构化数据和强事务。
比如用户、订单、支付、库存,常见有 MySQL、PostgreSQL、Oracle、SQL Server。
NoSQL 数据库适合高并发、灵活结构或海量数据。
比如 Redis、MongoDB、Cassandra、HBase、Elasticsearch。
向量数据库适合 AI 语义检索、RAG、相似度搜索,
比如 Milvus、Chroma、FAISS、Pinecone、Weaviate、Qdrant。
|
向量数据库 |
特点 |
适合 |
|---|---|---|
|
Milvus |
开源、性能强、支持大规模向量检索、Hybrid Search |
企业级 RAG、大规模知识库 |
|
Chroma |
简单易用,和 LangChain 配合方便 |
本地学习、小型 RAG Demo |
|
FAISS |
Meta 开源,本地向量检索库,不是完整数据库 |
本地实验、高性能向量索引 |
|
Qdrant |
开源,API 友好,过滤能力好 |
中小型生产 RAG |
|
Weaviate |
向量库 + schema + GraphQL/REST |
语义搜索、知识库 |
|
Pinecone |
云服务,免运维 |
商业项目、快速上线 |
二、向量数据怎么来
1.文本向量的计算
1.文字如何转为向量的算法 TF-IDF
TF(词频): 词t在文档d中出现的次数 / 文档d的总次数
IDF(拟文档频率): IDF(t) = log ( N / 包含词t的文档总数)
比如:
D1:苹果 好吃 苹果
D2:香蕉 好吃
D3:橘子 很甜
① 计算 TF(词频)
以 D1 里「苹果」为例:
D1 总词数 = 3,苹果出现 2 次
TF(苹果,D1)=2/3≈0.667
TF(好吃,D1)=1/3=0.333
② 计算 IDF
公式(常用):
IDF(w)=log(N/包含词t的文档总是)
总文档数 N=3
词「苹果」 词「好吃」
只在 D1 出现,含该词文档数 = 1 D1、D2 都有,含该词文档数 = 2
IDF(苹果)=log(3/1)=0.48 IDF(好吃)=log(3/2)=0.18
③ 求TF - IDF
D1 中「苹果」 D1 中「好吃」
TF-IDF=0.667×0.48=0.320 TF-IDF=0.333*0.18=0.0599
④ 相似度计算
向量值随便给,好看计算过程
V1(好吃): [0, 0.1 , 0.2, 0.3, 0]
V2(苹果): [0.3, 0.1 , 0.9, -0.2, 0.1]
相似度= (0 * 0.3 ) + (0.1 * 0.1) + (0.2 * 0.9) + (0.3 * -0.2) + (0 * 0.1) =0.13
2.多模态(文本、图片、音频、视频)向量怎么来的?
上一片多模态篇:
LLM —— 多模态(文本、图片、音频、视频)-CSDN博客
3.主流的向量维度是多少?
OpenAI Text-embedding-3-small 1536维度
..具体看模型官方介绍
一般是 768维度 或 1536维,数据非常专业、上下文极度复杂,可以考虑用3072维
维度越大,计算成本越高。不过计算是线性的,同一复杂度。量大了 768 -> 3072
计算相似度(余弦相似度)或者(L2欧式距离)| L1曼哈顿距离 | IP内积 等等
三. Milvmus向量数据库
开源的向量数据库 2019年提出。
相似度计算搜索
Collection 表 注意:1个collection最多支持4个向量Field
Field 字段 字段Schema相当于表中的列
is_primary. 主键
dtype 数据类型 字段的数据类型,如INT, VARCHAR等
max_length. 最大长度 对应VARCHAR类型字段的最大字符数
dim 维度
Collection Schema
| 属性 | 描述 | 备注 |
| field | 集合中要创建的字段 | 必填 |
| description | 集合描述 | String,选填 |
| partition_key_field | 设计用作分区键的字段的名称。 | String, 选填 |
| enable_dynamic_field | 是否启用动态模式 | Boolean (true or false) |
Field Schema: 表头信息
Milvus 集合中仅支持一个主键字段
| 属性 | 描述 | 备注 |
| name | 要创建的集合中的字段名称 | String,必填 |
| dtype | 字段的数据类型 | 必填 |
| description | 字段描述 | String,选填 |
| is_primary | 是否设置该字段为主键字段 | Boolean (true or false) 主键字段必填 |
| auto_id(主键字段必填) | 切换以启用或禁用自动 ID(主键)分配 | True或False |
| max_length(VARCHAR 字段必需) | 允许插入的字符串的最大长度。 | [1, 65,535] |
| dim | 向量的维数 | ∈[1, 32768] |
| is_partition_key | 该字段是否是分区键字段 |
布尔值(true 或 false) |
总结:
Collection:类似 MySQL 的表
Field:类似表字段
Vector Field:向量字段
Index:建立在向量字段上的索引
1. 索引
使用近似最近邻搜索(ANNS)
包括:
1.1 FLAT:适合小型,百万型。(不建议 - 暴力搜索)
1.2 IVF_FLAT: 是一种基于倒排的索引方法。(比较常用)
正排:id -> content
倒排: content -> id
如:
“关键词1”:“文档1”的ID,“文档2”的ID,…………。
“关键词2”:带有此关键词的文档ID列表。
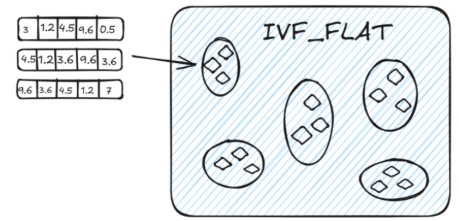
① 聚类
先分桶 bucket,再桶内暴力搜索
nlist:建索引时分多少个桶(越大:桶越多,分得越细)
nprobe:查询时搜多少个桶 (越大:查的桶越多,准确率更高,但速度更慢)
原理参考机器学习里面:聚类算法 (如k-means)多个簇
② 倒排索引
为每个簇创建倒排索引。每个向量会被映射到它所属的簇,这样在查询时,系统只需关注与查询向量相似的簇,而不需要搜索整个高维空间,从而显著降低搜索的时间复杂度。
③ 查询处理
例如:
比如有100万条向量,先分成1024个桶。查询时不扫100万条,而是只扫其中几个桶。
nlist = 1024
nprobe = 16
优点:
比 FLAT 快很多,实现简单,适合中等数据量。
缺点:
可能漏掉其他桶里的相似向量,参数需要调。
<1> 将查询向量分配到距离最近的簇中心(即子空间)
<2> 然后在该簇内执行精确的线性搜索,从而查找与查询向量相似的向量
<3> nprobe 来控制搜索的(桶)簇数。 nprobe 控制搜索时考虑的簇的数量,从而平衡查询精度和查询速度
<4> 增大 nprobe 可以搜索更多簇,返回更多候选向量,提高结果的精确度,但查询时间也会增加。减少 nprobe 可以缩小搜索范围,降低计算时间,查询速度更快,但可能会牺牲一些精度
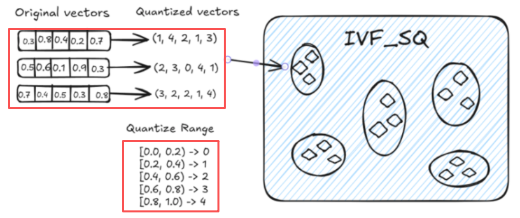
1.3 IVF_SQ8
(压缩向量,省内存)在IVF_FLAT基础上增加了量化步骤。
(精度会下降,召回可能变差)
把原来 float32 (4个字节)的每个维度,压缩成 8bit (1个字节) 整数。
占用内存是 原来的 1/4
通过 标量量化 将每个维度的4字节浮点数表示压缩为1字节表示 1字节整数。
1.4 IVF_PQ:
(倒排分桶索引)
先把向量分桶,再把向量切分,把整个向量切成几段,每段用一个编号表示。用更少内存、更快速度做相似度检索。
比如:1024维度 -> 切16段 每段64维度
如果 nbits = 8,每段只需要 1 字节。
原来 1024 * 4 = 4096个字节
变成 16 * 1 = 16个字节
非常省内存,但是向量精神损失非常大。
1.5 HNSW
HNSW = 给向量建一张“多层高速公路图”,查询时不用全量扫描,而是沿着图快速跳到最相似的向量附近。HNSW 会把所有向量组织成一张图。
A —— B —— C
| | |
D —— E —— F.
从某个入口点开始 -> 找附近更相似的点 -> 一步步往更接近目标的位置走 -> 最后找到 topK
Hierarchical:分层的
Navigable:可以导航的
Small World:小世界图
HNSW = 图索引 + 分层搜索(多层)
比如:
第 3 层:高速公路,点很少,跳得远
第 2 层:主干道,点多一些
第 1 层:普通道路,点更多
第 0 层:小路,包含全部点
优点:
适合
中小到大规模向量检索
需要高召回
希望查询速度快
内存比较充足
RAG 知识库
语义搜索
推荐系统
图片相似搜索
缺点:
内存很紧张
数据量超巨大但机器资源有限
频繁大量插入删除
极端追求最低存储成本
因为 HNSW 要保存图的连接关系,所以内存占用会比 IVF_FLAT / IVF_SQ8 / IVF_PQ 更高。
使用:常见三个参数
index_params = {
"index_type": "HNSW",
"metric_type": "COSINE",
"params": {
"M": 16,
"efConstruction": 200
}
}
search_params = {
"metric_type": "COSINE",
"params": {
"ef": 64
}
}M 表示:每个向量节点最多连接多少个邻居节点。常用 8 / 16 / 32
efConstruction表示:建索引时搜索候选邻居的范围。常见值 100 / 200 / 400
ef 是查询参数,表示:搜索时保留多少个候选点。常见值 32 / 64 / 128
注意:ef >= topK 一般要求
1.6 各种索引类型总结
|
FLAT |
全量扫描 |
最准 |
慢 |
|
IVF_FLAT |
分桶搜索 |
快,内存适中 |
可能漏桶 |
|
IVF_SQ8 |
分桶 + 8bit 压缩 |
省内存 |
有精度损失 |
|
IVF_PQ |
分桶 + PQ 压缩 |
极省内存 |
精度损失更大 |
|
HNSW |
图导航搜索 |
快,召回高 |
占内存较多 |
2.相似度计算
余弦相似度,欧式距离L2,内积IP
|
Cosine |
余弦相似度 |
看两个向量的方向是否一致 |
夹角越小越相似 |
基本不受长度影响 |
越大越相似,最大接近 1 |
文本语义检索、RAG、问答系统、句向量匹配 |
看“意思像不像” |
|
L2 |
欧式距离 |
看两个向量在空间里的距离远近 |
距离越小越相似 |
受长度影响 |
越小越相似 |
图像检索、聚类、数值特征、部分向量检索 |
看“离得近不近” |
|
IP |
内积/点积 |
看两个向量的点积大小 |
点积越大越相似 |
受长度影响 |
越大越相似 |
推荐系统、排序、 归一化向量检索、Milvus 稀疏向量/BM25 |
看“匹配强不强” |
官方:https://milvus.io/docs/zh/metric.md?tab=floating
|
普通文本 dense embedding 检索 |
COSINE |
|
向量已 normalize,想用高性能相似度 |
IP |
|
Milvus sparse vector / BM25 |
IP |
|
图像、数值特征、聚类 |
L2 |
|
Hybrid Search:dense + sparse |
dense 用 COSINE 或 IP,sparse 用 IP |
3.数据库操作
举例版本:milvmus V2.4.x
建库 建表 索引
1.创建数据库
2.建表
3.建索引 关联 表 字段
4.删除关联 索引
from pymilvus import MilvusClient, DataType
# 1.建数据库
def operate_db():
db_name = "milvus_demo"
client = MilvusClient(url=db_name)
# 代码查看 milvus 版本号
print(client.get_server_version())
databases = client.list_databases()
if db_name not in databases:
client.create_database(db_name=db_name)
client.using_database(db_name=db_name)
return client
# 2.建表
def opreate_table(client: MilvusClient):
# 定义schema
schema = client.create_schema(
auto_id=False, #是否自动生成主键
enable_dynamic_field=True #是否允许插入 schema 之外的动态字段
)
schema.add_field(
field_name="id",
datatype=DataType.INT64,
is_primary=True #是否是主键
)
schema.add_field(
field_name="embedding",
datatype=DataType.FLOAT_VECTOR,
dim=3
)
schema.add_field(
field_name="content",
datatype=DataType.VARCHAR,
max_length=1024,
description='内容'
)
client.create_collection(collection_name='base_info',schema=schema)
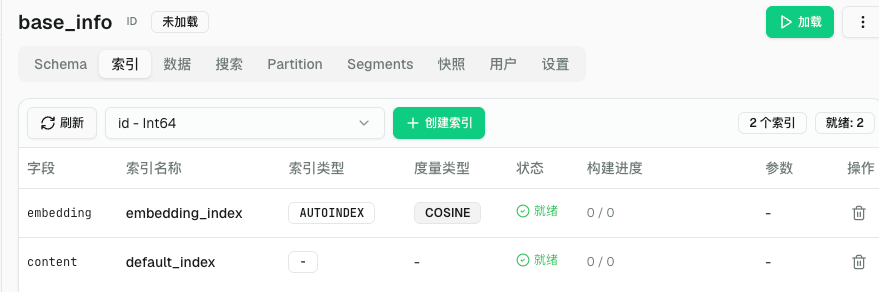
index_parmas = client.prepare_index_params()
index_parmas.add_index(
field_name="embedding", #给 字段 加索引
metric_type='COSINE',
index_type='',
index_name='embedding_index',
)
index_parmas.add_index(
field_name='content', #给 字段 加索引
index_type='',
index_name='default_index'
)
client.create_index(collection_name='base_info',index_params=index_parmas)
#查看索引信息
res = client.list_indexes(collection_name='base_info')
print(f'索引信息--》{res}')
res = client.describe_index(collection_name='base_info', index_name='embedding_index')
print(f'指定索引详细信息-->{res}')
# 表信息
# collection_base_info = client.load_collection(collection_name='base_info')
# print(client.get_load_state(collection_name='base_info'))
# 如果不需要索引,可以删除相关索引
# (两行一起才生效)
# client.release_collection(collection_name='base_info')
# client.drop_index(collection_name='base_info', index_name='embedding_index')
if __name__ == "__main__":
client = operate_db()
opreate_table(client=client)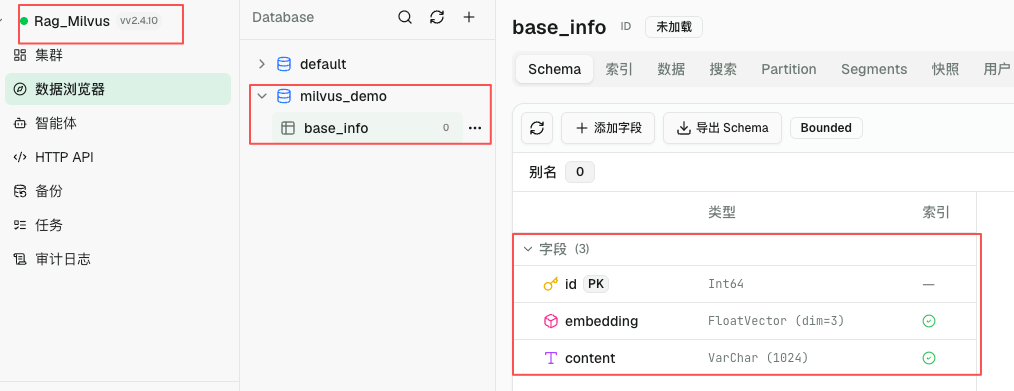
案例二:
增
enable_dynamic_field = True
表字段之外的所有字段都将被视为动态字段
data = [
{
"id": 0,
"embedding": [0.3580376395471989, -0.6023495712049978, 0.18414012509913835],
"content": "第0个数据",
"color": "yellow_4222"
},
{
"id": 1,
"embedding": [0.19886812562848388, 0.06023560599112088, 0.6976963061752597],
"content": "第1个数据",
"color": "red_7025"
},
{
"id": 2,
"embedding": [0.3172005263489739, 0.9719044792798428, -0.36981146090600725],
"content": "第2个数据",
"color": "orange_6781"
},
]
res = client.insert(collection_name="base_info", data=data)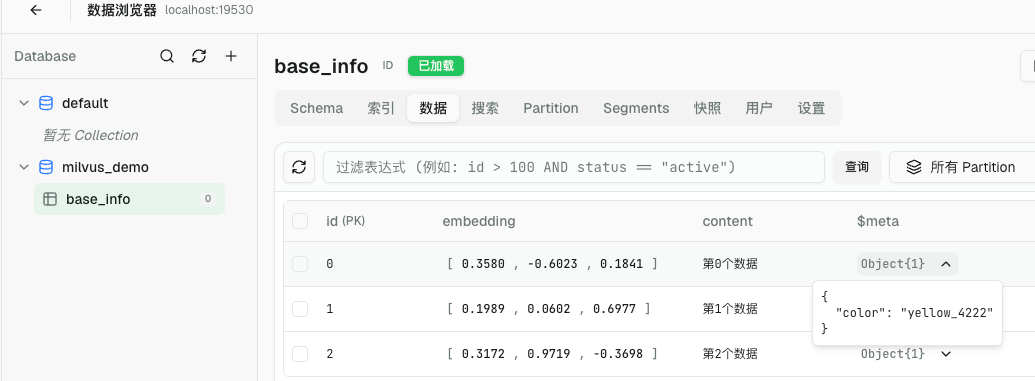
增 分区
def db_insert_partition():
data = [
{
"id": 3,
"embedding": [-0.6023495712049978, 0.3580376395471989, 0.18414012509913835],
"content": "第3个数据",
"color": "yellow_4222"
},
{
"id": 4,
"embedding": [0.6976963061752597, 0.19886812562848388, 0.06023560599112088],
"content": "第1个数据",
"color": "red_7025"
},
{
"id": 5,
"embedding": [0.3172005263489739, -0.36981146090600725, 0.9719044792798428],
"content": "第2个数据",
"color": "orange_6781"
},
]
# 创建新区
client.create_partition(
collection_name="base_info",
partition_name="partition_2"
)
# 插入指定区
res = client.insert(
collection_name="base_info",
data=data,
partition_name="partition_2"
)
print(res)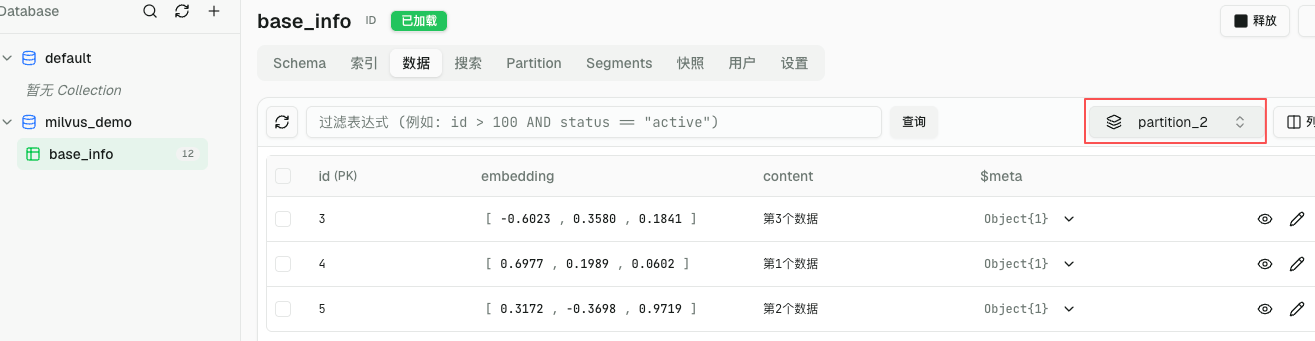
删
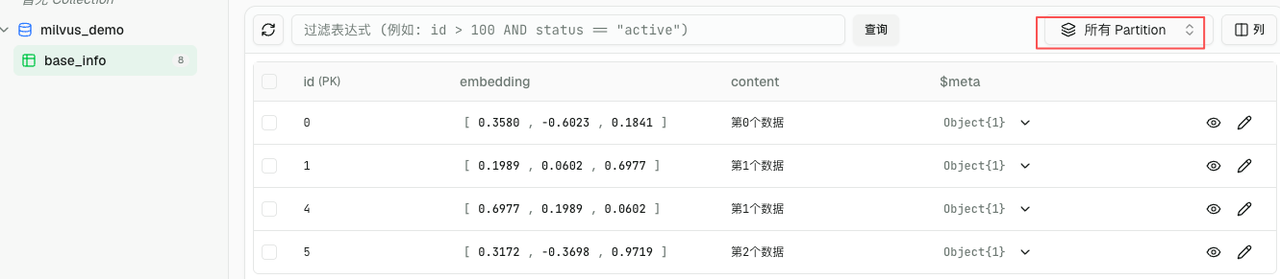
0,1 不在 区 partition_2 内,无法删。
del1 = client.delete(collection_name='base_info', filter='id in [2, 3]')
del2 = client.delete(collection_name='base_info', ids=[0, 1], partition_name='partition_2')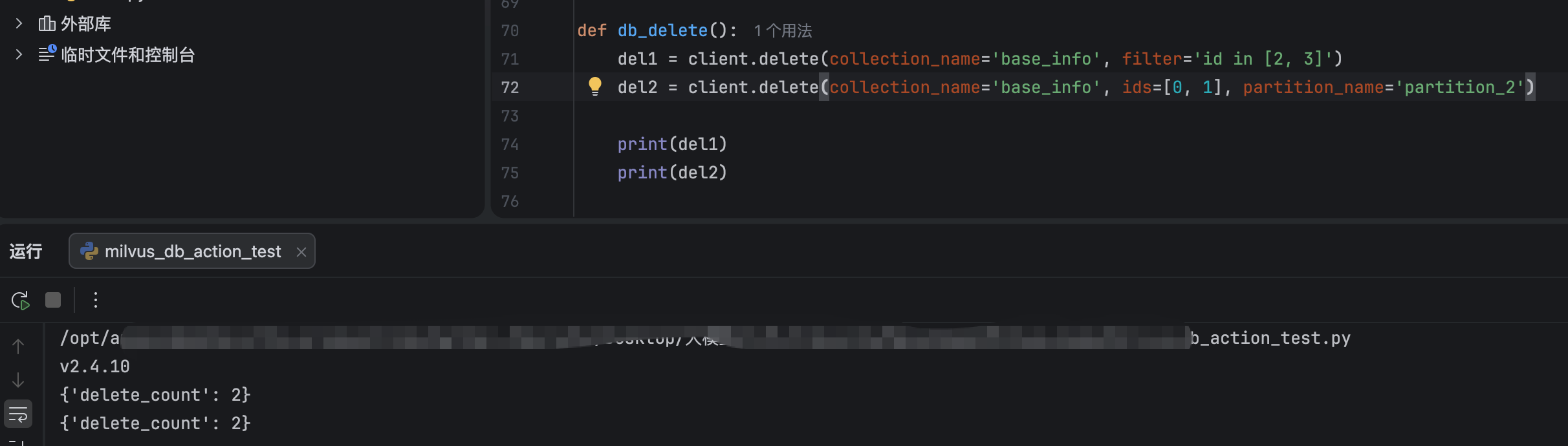
删表
client.drop_collection(collection_name="表名")插入(新增 || 更新修改)
原来有的覆盖更新,没有的插入
res = client.upsert(collection_name='base_info', data=data)查
① 输入根据2组向量,查4个,根据COSINE,输出字段id embedding
res = client.search(collection_name='base_info',
data=[[0.19886812562848388, 0.06023560599112088, 0.6976963061752597],
[0.3172005263489739, 0.9719044792798428, -0.36981146090600725]],
limit=4,
search_params={"metric_type": "COSINE"},
output_fields=["id", 'embedding']) # search_params是在查询时执行距离计算方式,如果定义索引的时候,已经制定了方式可以不写
print(res)② 分区查,limit = 5 ,实际数据只有2,只输出2条。 Data = [] 数组
res = client.search(
collection_name="base_info",
data=[[0.02174828545444263, 0.058611125483182924, 0.6168633415965343]],
limit=5,
search_params={"metric_type": "COSINE", "params": {}},
partition_names=["partition_2"] # 这里指定搜索的分区
)③ 使用字段来搜索 color
res = client.search(
collection_name="base_info",
data=[[0.3580376395471989, -0.6023495712049978, 0.18414012509913835]],
limit=5,
search_params={"metric_type": "COSINE", "params": {}},
output_fields=['id', "color"] # 返回定义的字段
)④ filter 过滤类似 sql 语句
res = client.search(
collection_name="base_info",
data=[[0.3580376395471989, -0.6023495712049978, 0.18414012509913835]],
limit=5,
search_params={"metric_type": "COSINE", "params": {}},
output_fields=["color"],
filter='color like "red%"'
)⑤ 范围 search_params
search_params = {
"metric_type": "COSINE",
"params": {
"radius": 0.8, # 搜索圆的半径
"range_filter": 1 # 范围过滤器,用于过滤出不在搜索圆内的向量。
}
}
res = client.search(
collection_name="base_info",
data=[[0.3580376395471989, -0.6023495712049978, 0.184140125099138352]],
limit=3, # 返回的搜索结果最大数量
search_params=search_params,
output_fields=["color"],
)——————————————————————————————————————————
4. 综合复杂查询(混合检索)
混合检索:要对两组 ANN 搜索结果进行合并和重新排序
两种重排策略
4.1 加权排名策略 WeightedRanker
如果要求结果强调特定的向量场,使用该策略。可以为某些向量场分配更高的权重。
类似,特征级,某个特征的权重比例。
在多模态搜索中,图片和文字描述可能比图片的颜色更重要。
WeightedRanker 是多路检索结果加权重排器,专门用于同时执行 向量检索 + 关键词检索(BM25) 两路召回后做分数融合:
第 1 个参数:向量相似度分数权重(对应 ANN 向量检索得分)
第 2 个参数:BM25 关键词匹配分数权重(对应全文检索得分)
融合公式(归一化加权求和):
final_score=wvec⋅norm(vec_score)+wbm25⋅norm(bm25_score)
权重取值规则 & 怎么合理赋值
① 权重不需要加起来 = 1
② 常用赋值策略
策略 A:更看重语义向量. 语义优先,关键词辅助。
from pymilvus import WeightedRanker
weight1 = 0.8
weight2 = 0.3
rerank = WeightedRanker(weight1, weight2)策略 B:两路同等重要
# 向量、关键词权重均等
WeightedRanker(1.0, 1.0)策略 C:强依赖关键词精准命中
# BM25关键词优先级更高
WeightedRanker(0.4, 1.0)策略 D:单路召回(不建议用重排器)
③ 多检索扩展(3路及以上)
如果同时开:向量检索 + BM25 + 文本匹配第 3 路,可继续追加参数:
# 3路召回,依次给每一路分配权重
rerank = WeightedRanker(0.7, 0.4, 0.2)4.2 倒数排序融合排序器 RRFRanker
RRFRanker:在没有特定重点的情况下,建议采用这种策略。RRF 可以有效平衡每个向量场的重要性。
核心思想:根据每个结果在其检索列表中的排名位置来计算分数。
以下公式为每个结果分配分数
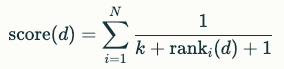
-
d:表示文档。
-
N:表示不同检索路径的数量。
-
ranki(d):表示文档 d 在第 i 个检索器中的排名位置,从0开始计数。
-
k:是一个平滑参数,用于控制随着排名增加分数的降低速度。
-
from pymilvus import RRFRanker ranker = RRFRanker(100)
案例:
数据库中至少要2个字段的向量数据。通常:表示 稀疏向量(关键词) 和 稠密向量(文本)。
① 建表 dim要相同才能计算
# 1. 定义schema 表
schema = client.create_schema(enable_dynamic_field=False)
schema.add_field(field_name='film_id', datatype=DataType.INT64, is_primary=True)
schema.add_field(field_name='filmVector', datatype=DataType.FLOAT_VECTOR, dim=4) # 向量字段
schema.add_field(field_name="posterVector", datatype=DataType.FLOAT_VECTOR, dim=4) # 向量字段② 定义 索引关联 2个向量字段
# 2. 定义 索引
index_params = client.prepare_index_params()
index_params.add_index(
field_name='filmVector',
index_type="IVF_FLAT",
metric_type="L2",
params={"nlist": 128}
)
index_params.add_index(
field_name='posterVector',
index_type="",
metric_type="COSINE"
)③ 构建集合
# 3.创建集合
client.create_collection(
collection_name='base_info_2',
schema=schema,
index_params=index_params
)④ 插入数据
# 4.向量库中插入实体
entities = []
for _ in range(1000):
# 构造实体
film_id = random.randint(1, 10000)
film_vector = [random.random() for _ in range(4)]
poster_vector = [random.random() for _ in range(4)]
entity = {
"film_id": film_id,
"filmVector": film_vector,
"posterVector": poster_vector
}
entities.append(entity)
client.insert(collection_name='base_info_2', data=entities)⑤ 构建查询需要的 两组ANNRequest
<1> 假定2个数据 (稀疏向量 和 稠密向量)
<2> 构建 稀疏+稠密向量 请求ANN参数
query_filmVector = [[0.8896863042430693,
0.370613100114602,
0.23779315077113428,
0.38227915951132996]]
# 稠密搜索
dense_search_params = {
"data": query_filmVector,
"anns_field": "filmVector", # 该参数值必须与集合模式中使用的值相同。
"param": {
"metric_type": "L2", # 计算相似度公式
"nprobe": 10 # nprobe代表访问簇的数量
},
"limit": 2
}query_posterVector = [[0.02550758562349764,
0.006085637357292062,
0.5325251250159071,
0.7676432650114147]]
# 稀疏搜索
sparse_search_params = {
"data": query_posterVector,
"anns_field": "posterVector",
# 该参数值必须与集合模式中使用的值相同。
"param": {"metric_type": "COSINE"},
"limit": 2
}<3> 构建2个ANNRequest
request_1 = AnnSearchRequest(**dense_search_params)
request_2 = AnnSearchRequest(**sparse_search_params)<4> 多向量搜索使用 hybrid_search() API 在一次调用中执行多个 ANN 搜索请求。每个 AnnSearchRequest 代表特定矢量场上的单个搜索请求
reqs = [request_1, request_2]
ranker = RRFRanker(100)
res = client.hybrid_search(
collection_name="base_info_2",
reqs=reqs,
ranker=ranker,
limit=2,
output_fields=["filmVector", "posterVector"]
)<5> 打印结果
for hits in res:
print("TopK results:")
for hit in hits:
print(hit)

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 9
9 0
0- 0



 已为社区贡献18条内容
已为社区贡献18条内容

所有评论(0)