Breast Cancer 二分类实验:随机森林预测乳腺肿瘤良恶性
| 属性 | 内容 |
|---|---|
| 链接 | breast-cancer-random-forest-classification |
| 摘要 | 基于 Breast Cancer Wisconsin 数据集,使用随机森林训练二分类模型预测肿瘤为恶性或良性,结合混淆矩阵、ROC 曲线和特征重要性,解读关键医学指标。 |
| 描述 | 本文基于 Breast Cancer Wisconsin 数据集,使用随机森林模型对乳腺肿瘤进行良恶性二分类预测,涵盖数据探索、模型训练、结果评估与特征解释,提供完整可复现代码与实验输出。 |
本项目由 星枢 支持

星枢官网:https://claudeaihub.cloud/
Breast Cancer 二分类实验:随机森林预测乳腺肿瘤良恶性
医疗数据是机器学习最敏感也最有价值的应用场景之一。这次用经典的 Breast Cancer Wisconsin 数据集做一个二分类实验:根据肿瘤的 30 个形态学特征,预测它是恶性(malignant)还是良性(benign)。
项目已开源:
https://github.com/coderWang404/xingshuProjects/tree/main/2026-06-12-breast-cancer-classification
核心结论:
- 数据规模:569 个肿瘤样本,30 个数值特征
- 模型:RandomForestClassifier
- Accuracy:0.9386
- ROC AUC:0.9931
- F1 Score:0.9510
- 最强特征:
worst concave points(最严重的凹点数量)
1. 数据集
Breast Cancer Wisconsin 数据集来自 scikit-learn 内置数据。每个样本对应一个乳腺肿瘤的细针穿刺活检结果,包含 30 个数值特征,这些特征都是从数字化细胞核图像中提取出来的形态学测量值。
from sklearn.datasets import load_breast_cancer
cancer = load_breast_cancer()
# 569 个样本,30 个特征
# target: 0 = malignant, 1 = benign
30 个特征可以分成 3 组,每组 10 个:
- mean 前缀:细胞核形态的平均值
- se 后缀:标准差
- worst 前缀:最大值或最严重值
类别分布:
| 类别 | 数量 | 占比 |
|---|---|---|
| malignant(恶性) | 212 | 37.3% |
| benign(良性) | 357 | 62.7% |
良性样本更多,但恶性样本也占了 37%,属于轻度类别不均衡。和 Wine Quality 项目一样,我用 class_weight="balanced" 来缓解这个问题。
2. 环境准备
pandas
numpy
scikit-learn
matplotlib
git clone https://github.com/coderWang404/xingshuProjects.git
cd xingshuProjects/2026-06-12-breast-cancer-classification
python -m venv venv
source venv/bin/activate
pip install -r requirements.txt
3. 运行实验
python experiments/breast-cancer/run_experiment.py
4. 建模思路
随机森林在这个任务上的表现非常好,原因有几个:
- 特征全是数值型,没有类别特征需要编码。
- 特征之间存在高度相关性(比如 radius、perimeter、area 几何相关),树模型能自动处理这种共线性。
- 可解释性强,医生可以理解"某个形态学特征为什么重要"。
参数:
model = RandomForestClassifier(
n_estimators=200,
max_depth=8,
min_samples_leaf=3,
class_weight="balanced",
random_state=42,
n_jobs=-1,
)
max_depth=8 设得比前几个项目保守一些。医疗诊断这种场景,过拟合的代价很高——一个被错误分类的恶性病例可能延误治疗。限制树的深度可以降低模型记住训练数据噪声的风险。
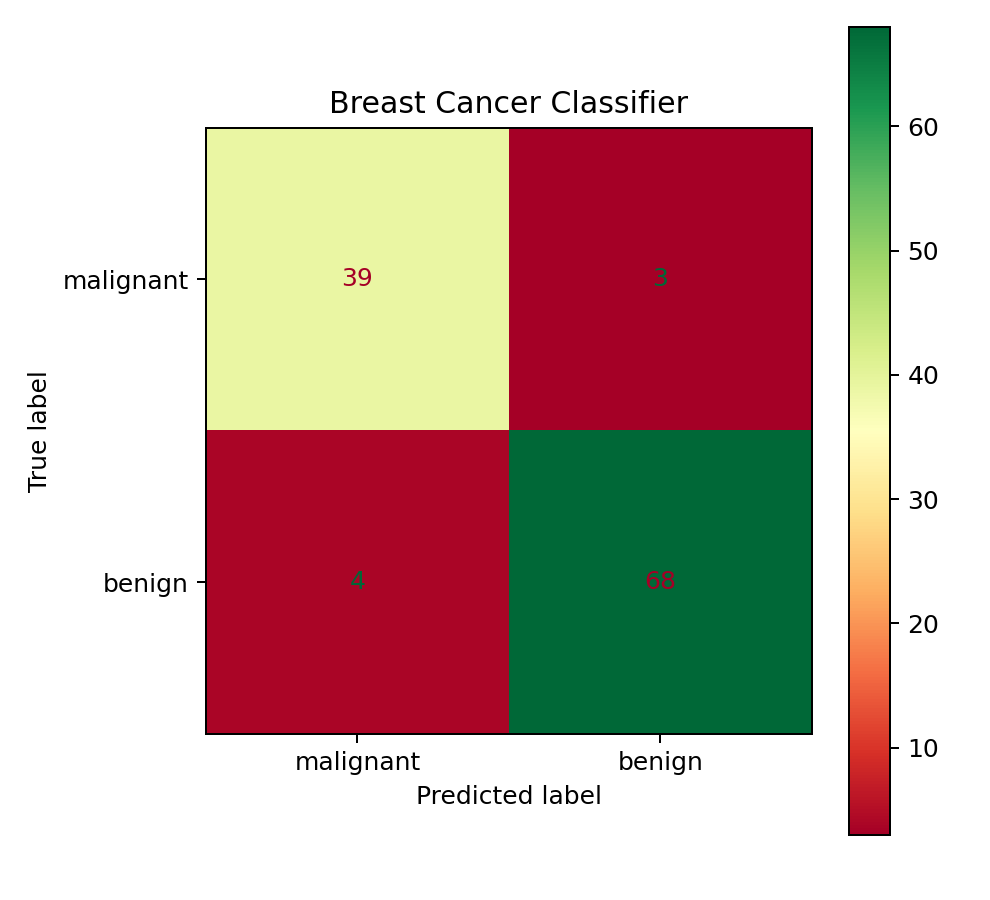
5. 结果分析:ROC AUC 0.9931 意味着什么
测试集 114 个样本,核心指标:
| 指标 | 数值 |
|---|---|
| Accuracy | 0.9386 |
| Precision | 0.9577 |
| Recall | 0.9444 |
| F1 | 0.9510 |
| ROC AUC | 0.9931 |
分类报告:
precision recall f1-score support
malignant 0.91 0.93 0.92 42
benign 0.96 0.94 0.95 72
accuracy 0.94 114
macro avg 0.93 0.94 0.93 114
weighted avg 0.94 0.94 0.94 114
ROC AUC 0.9931 非常高,说明模型几乎能完美地区分良性和恶性肿瘤。但注意,这是基于现有 30 个形态学特征的诊断,不是真正的医学诊断流程——真实医疗场景中还需要结合临床检查、影像学、病理学等多种信息。
Precision 0.9577 意味着:模型预测为良性的样本中,约 96% 真的是良性。Recall 0.9444 意味着:真实良性的样本中,约 94% 被模型正确识别。
对于恶性样本(少数类),Precision 0.91,Recall 0.93。也就是说,模型漏掉了约 7% 的恶性肿瘤。在医疗场景里,漏诊(False Negative)通常比误诊(False Positive)代价更高——把良性判成恶性还可以进一步检查,但把恶性判成良性可能延误治疗。从这个角度看,Recall 0.93 还有提升空间,可以通过降低分类阈值来提高恶性样本的召回率。
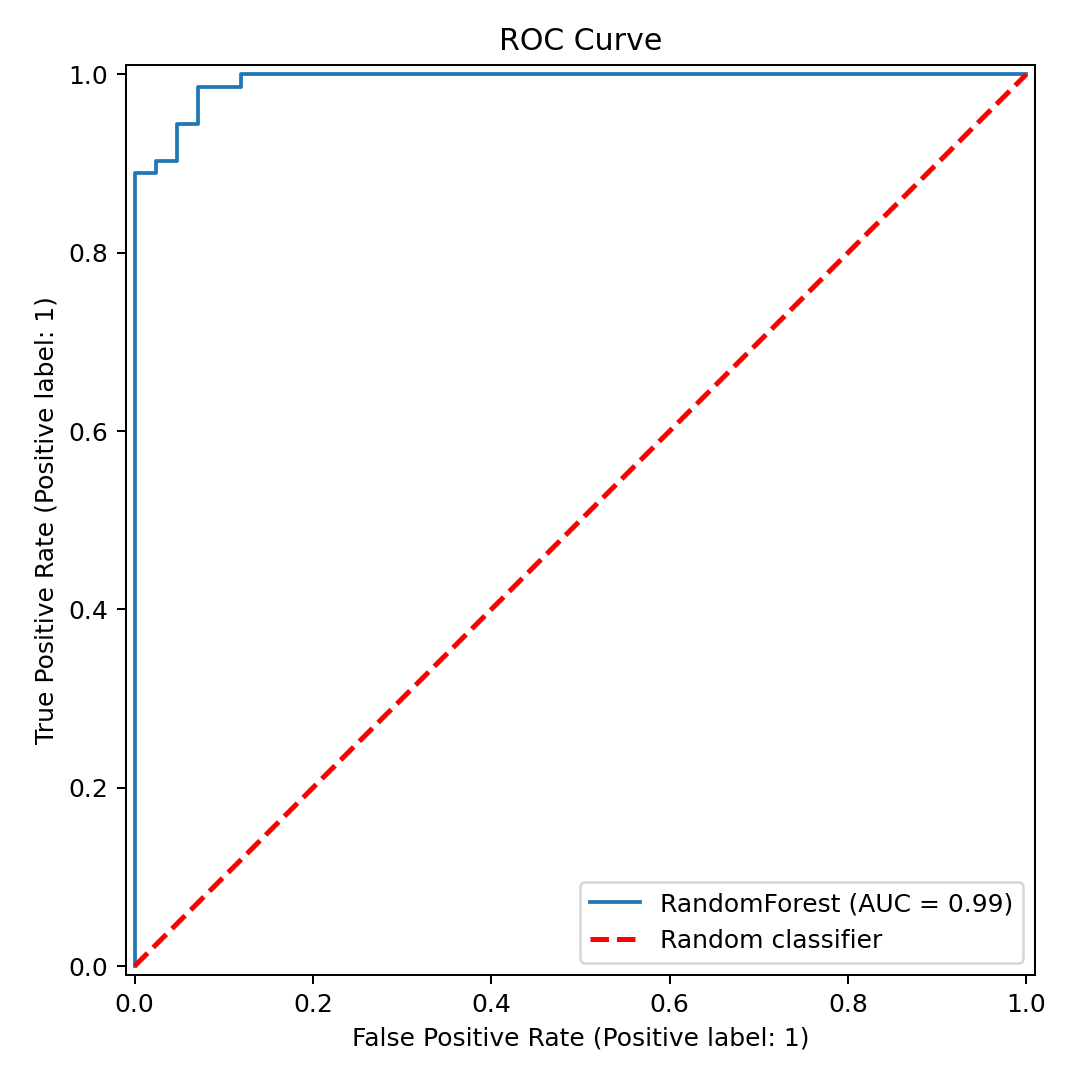
ROC 曲线非常贴近左上角,AUC 接近 1,印证了模型的强区分能力。
6. 特征重要性:worst concave points 最关键
Permutation Importance 排名前 10 的特征:
| 排名 | 特征 | 重要性 |
|---|---|---|
| 1 | worst concave points | 0.00513 |
| 2 | worst area | 0.00248 |
| 3 | mean concave points | 0.00237 |
| 4 | worst perimeter | 0.00198 |
| 5 | worst concavity | 0.00171 |
| 6 | worst smoothness | 0.00132 |
| 7 | worst texture | 0.00094 |
| 8 | mean smoothness | 0.00047 |
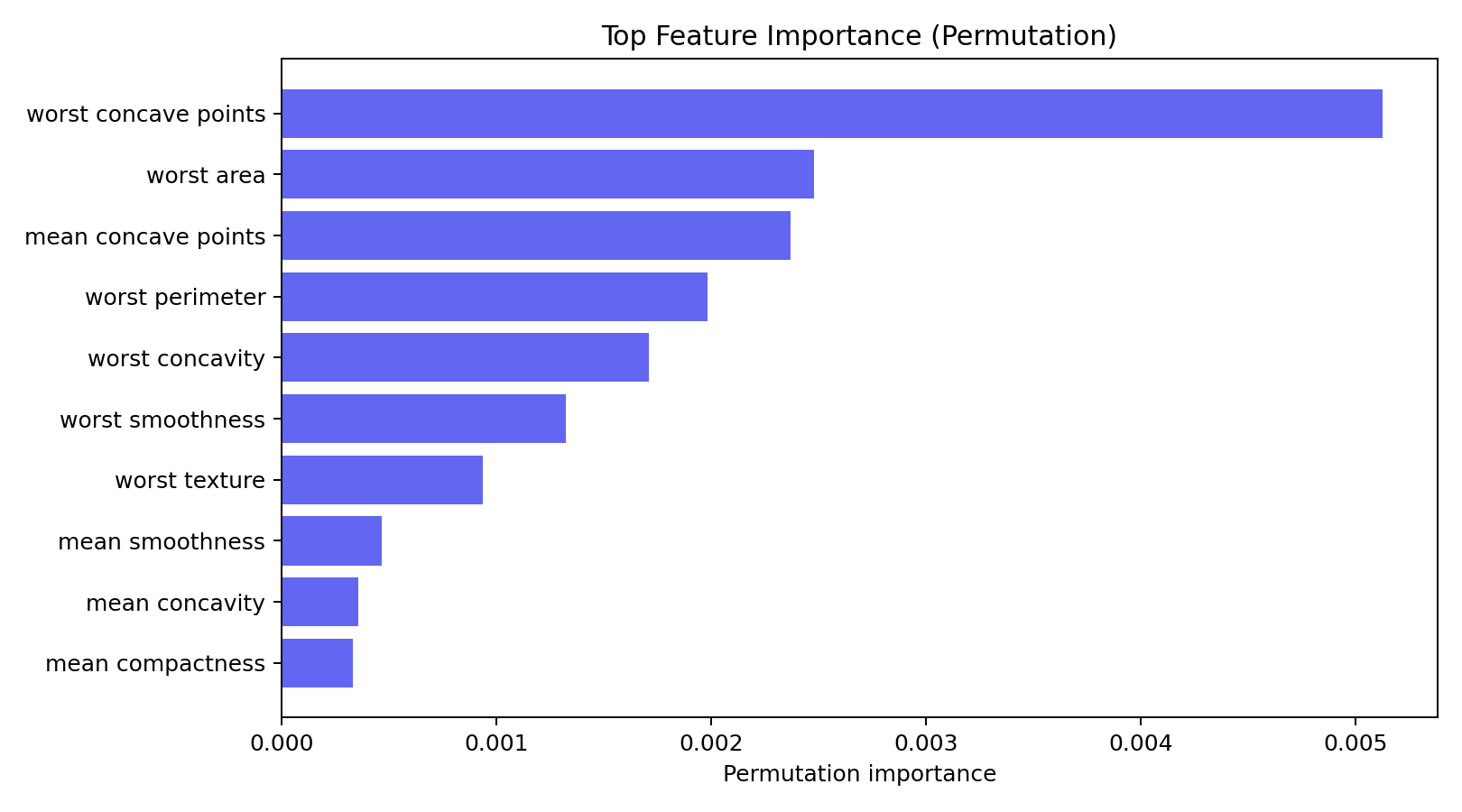
worst concave points(最严重的凹点数量)排名第一。这在医学上很有意义:恶性肿瘤的细胞核边界通常不规则,凹点数量多,形状更复杂。
另一个观察是:排名前 5 的特征里有 4 个是 worst 前缀。这说明肿瘤的"最坏情况"下的形态特征比平均值更能区分良恶性。也就是说,判断一个肿瘤是否恶性,关键不是看整体平均水平,而是看细胞核中最异常的那部分。
还有一些特征的重要性接近 0 甚至为负(比如 mean perimeter、texture error)。这并不意味着这些特征没用,而是因为它们的信息已经被其他强相关特征覆盖了。随机森林通过组合多个特征来做判断,单个特征的边际贡献可能很小。
7. 这个模型能用于医疗诊断吗
直接回答:不能单独用于临床诊断。
原因:
- 这是公开数据集,不是真实临床数据。真实医疗数据更复杂,有更多的噪声和缺失值。
- 没有医学专家的验证。特征重要性和医生的临床经验是否一致,需要专业评估。
- 模型的错误代价极高。即使 ROC AUC 0.99,仍然有 7% 的恶性肿瘤可能被漏掉。
但这个实验的价值在于:
- 展示机器学习在医疗数据上的应用流程
- 理解 Precision/Recall 在医疗场景中的权衡
- 学习如何用可解释模型辅助医生做初步筛选
在实际应用中,这种模型更适合作为辅助筛查工具——帮医生快速标记高风险病例,然后由医生做最终判断。
8. 实验输出
运行脚本后 experiments/breast-cancer/outputs/ 会生成:
metrics.json # 完整指标 JSON
classification_report.txt # 分类报告
dataset_profile.csv # 数据统计
feature_importance.csv # 全部特征重要性
class_distribution.png # 类别分布图
confusion_matrix.png # 混淆矩阵图
roc_curve.png # ROC 曲线图
feature_importance.png # 特征重要性图
summary.md # 实验摘要
9. 总结
这个实验让我对医疗二分类有了新的认识:
- ROC AUC 0.99 不等于临床可用。高 AUC 只说明模型区分能力强,但医疗场景需要考虑误诊和漏诊的实际代价。
- worst 前缀的特征比 mean 前缀更重要。判断肿瘤良恶性,关键看最异常的那部分细胞核形态。
- 凹点数量(concave points)是最强信号。这与医学常识一致:恶性肿瘤的细胞核边界更不规则。
- 这个模型适合作为辅助工具,不能替代医生。
如果想继续探索,可以试试:
- 调整分类阈值,提高恶性样本的 Recall
- 用 Logistic Regression 对比,看看哪些特征系数和随机森林一致
- 加入特征选择,只保留 top 10 特征,观察模型性能变化
本项目由 星枢 支持

星枢官网:https://claudeaihub.cloud/

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 7
7 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)