Pytorch入门P5周学习打卡:Pytorch实现运动鞋识别
- 🍨 本文为🔗365天深度学习训练营 中的学习记录博客
- 🍖 原作者:K同学啊
文章目录
前言
本篇是我训练营的第五次学习,主要目标是使用 PyTorch 实现一个运动鞋品牌识别任务(Adidas vs Nike)。P1 周跑通了 MNIST 手写数字识别、P2 周理解了 CIFAR10 彩色图片和 CNN 的 shape 变化、P3 周掌握了本地自定义数据集的加载和 BatchNorm、P4 周学会了保存最佳模型和单张图片预测,本周的任务则在前面四周的基础上,重点学习动态学习率的设置方法,并进一步理解Dropout 正则化和模型保存与加载的完整流程。同时要求调整代码使测试集 accuracy 达到 84%,拔高目标是 86%。
本周的运动鞋品牌识别任务一共有 2 个类别:adidas 阿迪达斯、nike 耐克
感谢K同学啊老师的教学,以及 ChatGPT 和 Kimi。
P1-P5 周整体对比
| 对比项目 | P1 周:MNIST 手写数字识别 | P2 周:CIFAR10 彩色图片识别 | P3 周:天气识别 | P4 周:猴痘二分类识别 | P5 周:运动鞋品牌识别 |
|---|---|---|---|---|---|
| 图像类型 | 灰度图 | RGB 彩色图 | RGB 彩色图 | RGB 彩色图 | RGB 彩色图 |
| 输入 shape | [32, 1, 28, 28] |
[32, 3, 32, 32] |
[32, 3, 224, 224] |
[32, 3, 224, 224] |
[32, 3, 224, 224] |
| 类别数 | 10 类 | 10 类 | 4 类 | 2 类 | 2 类 |
| 训练集/测试集划分 | 已划分 | 已划分 | random_split 手动划分 |
random_split 手动划分 |
已分好 train/ 和 test/ |
| 学习率 | 固定 1e-2 |
固定 1e-2 |
固定 1e-4 |
固定 1e-4 |
动态学习率 |
| 正则化手段 | 无 | 无 | BatchNorm | BatchNorm | BatchNorm + Dropout |
| 特殊功能 | 基础流程 | shape 推导 | 本地数据加载 | 保存最佳模型+预测 | 动态学习率 + 模型保存加载 |
一、准备工作
1. 设置运行设备:GPU 或 CPU
和前面一样,首先判断当前设备是否支持 GPU,如果支持就使用 CUDA 加速,否则使用 CPU。
import torch
import torch.nn as nn
import torchvision.transforms as transforms
import torchvision
from torchvision import transforms, datasets
import os, PIL, pathlib
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
device
device(type='cpu')
2. 关于运动鞋品牌识别数据集
本周使用的是运动鞋品牌识别数据集,它需要自己下载并放在本地 5-data/ 文件夹下。和 P3、P4 周不同的是,本周的数据集已经提前分好了训练集和测试集,文件夹结构如下:
5-data/
├── train/
│ ├── adidas/ # 阿迪达斯运动鞋图片
│ └── nike/ # 耐克运动鞋图片
└── test/
├── adidas/ # 阿迪达斯运动鞋图片
└── nike/ # 耐克运动鞋图片
数据集共包含 2 个类别:
| 类别 | 标签含义 | 说明 |
|---|---|---|
adidas |
阿迪达斯品牌运动鞋 | 带有阿迪达斯三条纹标志的运动鞋图片 |
nike |
耐克品牌运动鞋 | 带有耐克勾形标志的运动鞋图片 |
P3 周和 P4 周的数据需要用 random_split 手动划分训练集和测试集,而本周数据集已经分好了 train/ 和 test/,所以分别加载即可。
3. 导入本地数据集
首先使用 pathlib.Path 读取本地数据文件夹,并提取类别名称。
import os, PIL, random, pathlib
data_dir = './5-data/'
data_dir = pathlib.Path(data_dir)
data_paths = list(data_dir.glob('*'))
classeNames = [str(path).split("\\")[1] for path in data_paths]
classeNames
['test', 'train']
这一段的意思是:
pathlib.Path(data_dir):把字符串路径./5-data/转换成 Path 对象;- 使用
glob('*')获取data_dir路径下的所有子文件夹路径; - 通过
split("\\")对每条路径进行分割,提取出文件夹名称,存入classeNames列表中。
由于最外层文件夹是 train 和 test,所以这里的 classeNames 先得到 ['test', 'train']。真正的类别名称(adidas / nike)需要在后续使用 ImageFolder 加载后才能获得。
4. 数据预处理:transforms.Compose()
本周的图片来自本地文件夹,不同图片的原始尺寸可能不同。CNN 网络要求输入图片大小一致,所以要先用 transforms 对图片进行统一处理。
# 关于transforms.Compose的更多介绍可以参考:https://blog.csdn.net/qq_38251616/article/details/124878863
train_transforms = transforms.Compose([
transforms.Resize([224, 224]), # 将输入图片resize成统一尺寸
# transforms.RandomHorizontalFlip(), # 随机水平翻转
transforms.ToTensor(), # 将PIL Image或numpy.ndarray转换为tensor,并归一化到[0,1]之间
transforms.Normalize( # 标准化处理-->转换为标准正太分布(高斯分布),使模型更容易收敛
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]) # 其中 mean=[0.485,0.456,0.406]与std=[0.229,0.224,0.225] 从数据集中随机抽样计算得到的。
])
test_transform = transforms.Compose([
transforms.Resize([224, 224]), # 将输入图片resize成统一尺寸
transforms.ToTensor(), # 将PIL Image或numpy.ndarray转换为tensor,并归一化到[0,1]之间
transforms.Normalize( # 标准化处理-->转换为标准正太分布(高斯分布),使模型更容易收敛
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]) # 其中 mean=[0.485,0.456,0.406]与std=[0.229,0.224,0.225] 从数据集中随机抽样计算得到的。
])
train_dataset = datasets.ImageFolder("./5-data/train/", transform=train_transforms)
test_dataset = datasets.ImageFolder("./5-data/test/", transform=test_transform)
transforms.Resize([224, 224]) 将不同大小的原始图片统一 resize 成 224 × 224 像素。
transforms.ToTensor() 将 PIL Image 或 numpy.ndarray 格式的图片转换为 PyTorch 的 Tensor 格式,同时把像素值从 0-255 缩放到 0-1 之间。
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) 对 RGB 三个通道进行标准化处理。
🌟 mean 与 std 数值是怎么来的?
这些均值和标准差不是从运动鞋数据集计算出来的,而是通过计算 ImageNet 数据集 中所有训练图像的 RGB 通道均值和标准差得出的,具体计算过程如下:
- 获取 ImageNet 数据集:ImageNet 包含约 120 万张训练图像,每张图像有 RGB 三个通道。
- 计算均值(Mean):
- Red 通道均值 ≈ 0.485
- Green 通道均值 ≈ 0.456
- Blue 通道均值 ≈ 0.406
- 计算标准差(Standard Deviation):
- Red 通道标准差 ≈ 0.229
- Green 通道标准差 ≈ 0.224
- Blue 通道标准差 ≈ 0.225
这组均值和标准差通常来自 ImageNet 数据集的 RGB 通道统计值。它们经常用于自然图片分类任务,尤其是在输入尺寸为 224 × 224 的图像任务中比较常见。
5. 使用 ImageFolder 自动生成标签
train_dataset.class_to_idx
{'adidas': 0, 'nike': 1}
ImageFolder 会根据文件夹名称自动分配标签,train_dataset.class_to_idx 是一个存储了数据集类别和对应索引的字典。adidas 对应索引 0,nike 对应索引 1。
6. 创建 DataLoader 数据加载器
划分好数据集后,用 DataLoader 包装成可以批量加载的数据迭代器。
batch_size = 32
train_dl = torch.utils.data.DataLoader(train_dataset,
batch_size=batch_size,
shuffle=True,
num_workers=1)
test_dl = torch.utils.data.DataLoader(test_dataset,
batch_size=batch_size,
shuffle=True,
num_workers=1)
这一段和前几周非常相似。DataLoader 的作用就是把数据按 batch 送入模型。这里设置 batch_size = 32,表示每次送入 32 张图片。shuffle=True 表示每个 epoch 开始前打乱数据顺序。num_workers=1 用 1 个子进程辅助加载数据。
与 P3、P4 周的对比:
| 项目 | P3/P4 周 | P5 周 |
|---|---|---|
| 数据划分方式 | random_split 手动 8:2 划分 |
数据集已分好 train/ 和 test/ |
| 加载方式 | 先加载全部数据再划分 | 分别加载 train/ 和 test/ |
| DataLoader | 从 Subset 创建 |
直接从 ImageFolder 创建 |
7. 查看一个 batch 的数据格式
for X, y in test_dl:
print("Shape of X [N, C, H, W]: ", X.shape)
print("Shape of y: ", y.shape, y.dtype)
break
Shape of X [N, C, H, W]: torch.Size([32, 3, 224, 224])
Shape of y: torch.Size([32]) torch.int64
这个 shape 可以拆开理解:
torch.Size([32, 3, 224, 224])
↑ ↑ ↑ ↑
N C H W
│ │ │ └── 宽度:224 像素
│ │ └─────── 高度:224 像素
│ └──────────── 通道数:3,RGB 彩色图
└──────────────── batch_size,一批 32 张图片
五周数据集 shape 对比:
MNIST: [32, 1, 28, 28]
CIFAR10: [32, 3, 32, 32]
天气图像: [32, 3, 224, 224]
猴痘图像: [32, 3, 224, 224]
运动鞋图像: [32, 3, 224, 224] ← 本周
| 项目 | P1 周 MNIST | P2 周 CIFAR10 | P3 周天气识别 | P4 周猴痘识别 | P5 周运动鞋识别 |
|---|---|---|---|---|---|
| shape | [32, 1, 28, 28] |
[32, 3, 32, 32] |
[32, 3, 224, 224] |
[32, 3, 224, 224] |
[32, 3, 224, 224] |
| 通道数 C | 1(灰度) | 3(RGB) | 3(RGB) | 3(RGB) | 3(RGB) |
| 高 H | 28 | 32 | 224 | 224 | 224 |
| 宽 W | 28 | 32 | 224 | 224 | 224 |
| 单张图像素数 | 784 | 3072 | 150528 | 150528 | 150528 |
可以看出,P5 周和 P3、P4 周在输入图片尺寸上完全一样,都是 224 × 224 的 RGB 彩色图。本周也是二分类问题,类别为 adidas 和 nike。
二、构建简单的 CNN 网络
本周使用的是一个带有 BatchNorm 和 Dropout 的 CNN 网络。整体结构可以分为两部分:
- 特征提取网络:用卷积层、池化层提取图片特征;
- 分类网络:用全连接层根据提取到的特征进行分类。
本周的运动鞋品牌识别任务有 2 个类别,所以最后一层输出维度是:len(classeNames),也就是 2。
1. torch.nn.Conv2d() 卷积层
卷积层用于提取图片的局部特征,比如运动鞋的品牌标志、鞋面纹理、鞋底形状等。
函数原型:
torch.nn.Conv2d(in_channels, out_channels, kernel_size, stride=1, padding=0,
dilation=1, groups=1, bias=True, padding_mode='zeros',
device=None, dtype=None)
常用参数解释:
| 参数 | 含义 | 本周代码中的体现 |
|---|---|---|
in_channels |
输入图片通道数 | 第一层是 3,因为运动鞋图片是 RGB 彩色图 |
out_channels |
输出特征图数量 | 第一层输出 12 个特征图 |
kernel_size |
卷积核大小 | 本周使用 5 × 5 |
stride |
卷积步长 | 本周为 1 |
padding |
是否填充边缘 | 本周为 0,不填充 |
例如:
self.conv1 = nn.Conv2d(3, 12, kernel_size=5, padding=0) # 12*220*220
这一句表示:输入是 RGB 三通道图片,经过第一层卷积后,输出 12 个特征图,图片尺寸从 224 × 224 变成 220 × 220。
2. torch.nn.BatchNorm2d() 批归一化层
函数原型:
torch.nn.BatchNorm2d(num_features, eps=1e-05, momentum=0.1, affine=True,
track_running_stats=True)
本周模型中加入了 BatchNorm2d,BatchNorm 的作用可以简单理解为:在训练过程中,对每一批数据的特征进行标准化,让数据分布更稳定,从而帮助模型更快、更稳定地训练。
具体来说,BatchNorm 会:
- 计算当前 batch 中每个通道的均值和方差;
- 用这些统计量对数据进行归一化;
- 引入可学习的缩放参数(gamma)和平移参数(beta),让网络自己决定是否需要恢复原始分布。
为什么使用 BatchNorm?
- 加速训练:归一化后的数据分布更稳定,可以使用更大的学习率;
- 减少 Internal Covariate Shift(内部协变量偏移):即减少网络各层之间数据分布的变化;
- 有一定正则化效果:因为每个 batch 的统计量不同,相当于给网络引入了噪声,减少了过拟合的风险。
3. torch.nn.Dropout() 丢弃层
函数原型:
torch.nn.Dropout(p=0.5, inplace=False)
| 参数 | 含义 |
|---|---|
p |
神经元被丢弃的概率,默认 0.5 |
inplace |
是否原地操作,默认 False |
本周模型中加入了 Dropout(0.2),表示在训练过程中,以 20% 的概率随机丢弃一部分神经元。
为什么使用 Dropout?
Dropout 是一种非常有效的正则化手段,它的核心思想是:在训练时随机关闭一部分神经元,强迫网络不依赖某些特定的特征,从而提高模型的泛化能力。
- 防止过拟合:网络不能依赖任何一个神经元,所以每个神经元都要学会更鲁棒的特征;
- 近似模型集成:每次训练时丢弃不同的神经元,相当于在训练多个不同的子网络,最终效果是多个模型的集成;
- 注意:Dropout 只在 训练时 生效,测试时会自动关闭。
P3-P5 周正则化手段对比:
| 周次 | BatchNorm | Dropout | 说明 |
|---|---|---|---|
| P3 周天气识别 | ✓ | ✗ | 只有批归一化 |
| P4 周猴痘识别 | ✓ | ✗ | 只有批归一化 |
| P5 周运动鞋识别 | ✓ | ✓(0.2) | BatchNorm + Dropout |
4. torch.nn.MaxPool2d() 池化层
池化层用于压缩特征图尺寸,减少计算量,同时保留比较明显的特征。
函数原型:
torch.nn.MaxPool2d(kernel_size, stride=None, padding=0, dilation=1,
return_indices=False, ceil_mode=False)
| 参数 | 含义 |
|---|---|
kernel_size |
最大的窗口大小 |
stride |
窗口的步幅,默认值为 kernel_size |
本周使用 nn.MaxPool2d(2),使用 2 × 2 的最大池化窗口,默认步长也是 2,所以每经过一次池化,图片的高和宽大约都会缩小一半。
5. torch.nn.Linear() 全连接层
卷积和池化之后,模型得到的是多维特征图。但是全连接层需要的是二维数据,所以要先把特征图展平成一维向量。
函数原型:
torch.nn.Linear(in_features, out_features, bias=True, device=None, dtype=None)
全连接层:
self.fc = nn.Sequential(
nn.Linear(24*50*50, len(classeNames)))
因为运动鞋品牌识别有 2 个类别(adidas 和 nike),len(classeNames) 等于 2,所以输出是 2 个分类分数。
这里 24*50*50 = 60000,是经过卷积和池化后展平的维度。
6. 定义 CNN 模型
import torch.nn.functional as F
class Model(nn.Module):
def __init__(self):
super(Model, self).__init__()
self.conv1 = nn.Sequential(
nn.Conv2d(3, 12, kernel_size=5, padding=0), # 12*220*220
nn.BatchNorm2d(12),
nn.ReLU())
self.conv2 = nn.Sequential(
nn.Conv2d(12, 12, kernel_size=5, padding=0), # 12*216*216
nn.BatchNorm2d(12),
nn.ReLU())
self.pool3 = nn.Sequential(
nn.MaxPool2d(2)) # 12*108*108
self.conv4 = nn.Sequential(
nn.Conv2d(12, 24, kernel_size=5, padding=0), # 24*104*104
nn.BatchNorm2d(24),
nn.ReLU())
self.conv5 = nn.Sequential(
nn.Conv2d(24, 24, kernel_size=5, padding=0), # 24*100*100
nn.BatchNorm2d(24),
nn.ReLU())
self.pool6 = nn.Sequential(
nn.MaxPool2d(2)) # 24*50*50
self.dropout = nn.Sequential(
nn.Dropout(0.2))
self.fc = nn.Sequential(
nn.Linear(24*50*50, len(classeNames)))
def forward(self, x):
batch_size = x.size(0)
x = self.conv1(x) # 卷积-BN-激活
x = self.conv2(x) # 卷积-BN-激活
x = self.pool3(x) # 池化
x = self.conv4(x) # 卷积-BN-激活
x = self.conv5(x) # 卷积-BN-激活
x = self.pool6(x) # 池化
x = self.dropout(x)
x = x.view(batch_size, -1) # flatten 变成全连接网络需要的输入 (batch, 24*50*50) ==> (batch, -1), -1 此处自动算出的是24*50*50
x = self.fc(x)
return x
device = "cuda" if torch.cuda.is_available() else "cpu"
print("Using {} device".format(device))
model = Model().to(device)
model
Model(
(conv1): Sequential(
(0): Conv2d(3, 12, kernel_size=(5, 5), stride=(1, 1))
(1): BatchNorm2d(12, eps=1e-05, momentum=0.1, affine=True, bias=True, track_running_stats=True)
(2): ReLU()
)
(conv2): Sequential(
(0): Conv2d(12, 12, kernel_size=(5, 5), stride=(1, 1))
(1): BatchNorm2d(12, eps=1e-05, momentum=0.1, affine=True, bias=True, track_running_stats=True)
(2): ReLU()
)
(pool3): Sequential(
(0): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(conv4): Sequential(
(0): Conv2d(12, 24, kernel_size=(5, 5), stride=(1, 1))
(1): BatchNorm2d(24, eps=1e-05, momentum=0.1, affine=True, bias=True, track_running_stats=True)
(2): ReLU()
)
(conv5): Sequential(
(0): Conv2d(24, 24, kernel_size=(5, 5), stride=(1, 1))
(1): BatchNorm2d(24, eps=1e-05, momentum=0.1, affine=True, bias=True, track_running_stats=True)
(2): ReLU()
)
(pool6): Sequential(
(0): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(dropout): Sequential(
(0): Dropout(p=0.2, inplace=False)
)
(fc): Sequential(
(0): Linear(in_features=60000, out_features=2, bias=True)
)
)
网络结构分析:
P5 周的网络相比 P3、P4 周有以下特点:
- 使用了
nn.Sequential包裹:每一层卷积都用nn.Sequential把Conv2d + BatchNorm2d + ReLU打包在一起,代码更整洁; - 卷积核大小是 5×5:P1 和 P2 周使用的是 3×3,P3-P5 周使用的是 5×5,所以每次卷积后尺寸减少得更多(减少 4 而不是 2);
- 增加了 Dropout(0.2):在全连接层之前加入了丢弃层,是本周相比 P3、P4 周的新增正则化手段;
- 没有中间全连接层:和 P3、P4 周一样,只有一个
fc,直接从展平后的特征映射到 2 个类别; - 使用
x.view()展平:x.view(batch_size, -1)会把特征图展平成一维向量,-1表示自动计算该维度的大小。
P4 周和 P5 周网络结构对比:
| 项目 | P4 周猴痘识别 | P5 周运动鞋识别 |
|---|---|---|
| 卷积核大小 | 5 × 5 | 5 × 5 |
| 卷积层数 | 4 层 | 4 层 |
| 池化层数 | 2 层 | 2 层 |
| BatchNorm 层数 | 4 层 | 4 层 |
| Dropout | 无 | 有(0.2) |
| 全连接层数 | 1 层 | 1 层 |
| 展平维度 | 60000 | 60000 |
| 输出类别数 | 2 | 2 |
P4 周和 P5 周的模型结构非常相似,唯一的区别是 P5 周增加了 Dropout(0.2) 层。
三、CNN 网络 shape 变化推导
本周输入图片被统一 resize 成:[3, 224, 224],其中:3:RGB 三个通道、224 :图片高度、224:图片宽度。
1. 卷积层输出尺寸公式
普通卷积层,输出尺寸公式是:
输出尺寸 = floor((输入尺寸 + 2 × padding - kernel_size) / stride + 1)
本周代码中,卷积层基本使用默认参数:
kernel_size = 5
stride = 1
padding = 0
所以公式可以简化成:
输出尺寸 = 输入尺寸 - 5 + 1 = 输入尺寸 - 4
也就是说,每经过一个 5 × 5 且不加 padding 的卷积层,高和宽都会减少 4。
2. 池化层输出尺寸公式
池化层是:
nn.MaxPool2d(2)
当 stride 不设置时,默认等于 kernel_size,所以这里相当于:
kernel_size = 2
stride = 2
可以简单理解为:每经过一次 2 × 2 最大池化,高和宽大约变成原来的一半。
3. 完整 shape 推导
输入图片
[3, 224, 224]
第一层卷积 conv1
self.conv1 = nn.Conv2d(3, 12, kernel_size=5)
输入通道数从 3 变成输出通道数 12。
图片大小变化:
224 × 224 → 220 × 220
所以输出变成:
[12, 220, 220]
第二层卷积 conv2
self.conv2 = nn.Conv2d(12, 12, kernel_size=5)
输入通道数从 12 变成输出通道数 12。
图片大小变化:
220 × 220 → 216 × 216
所以输出变成:
[12, 216, 216]
第一层池化 pool3
self.pool3 = nn.MaxPool2d(2)
图片大小减半:
216 × 216 → 108 × 108
所以输出变成:
[12, 108, 108]
第三层卷积 conv4
self.conv4 = nn.Conv2d(12, 24, kernel_size=5)
输入通道数从 12 变成输出通道数 24。
图片大小变化:
108 × 108 → 104 × 104
所以输出变成:
[24, 104, 104]
第四层卷积 conv5
self.conv5 = nn.Conv2d(24, 24, kernel_size=5)
通道数不变,图片大小变化:
104 × 104 → 100 × 100
所以输出变成:
[24, 100, 100]
第二层池化 pool6
self.pool6 = nn.MaxPool2d(2)
图片大小减半:
100 × 100 → 50 × 50
所以输出变成:
[24, 50, 50]
Flatten 展平
进入全连接层之前,需要把多维特征图展平成一维向量:
24 × 50 × 50 = 60000
所以:
self.fc = nn.Sequential(nn.Linear(24*50*50, len(classeNames)))
这里的 60000 就是这样来的。
完整结构汇总
输入:3, 224, 224
↓
Conv2d(3, 12, kernel_size=5) + BatchNorm2d(12) + ReLU
输出:12, 220, 220
↓
Conv2d(12, 12, kernel_size=5) + BatchNorm2d(12) + ReLU
输出:12, 216, 216
↓
MaxPool2d(2)
输出:12, 108, 108
↓
Conv2d(12, 24, kernel_size=5) + BatchNorm2d(24) + ReLU
输出:24, 104, 104
↓
Conv2d(24, 24, kernel_size=5) + BatchNorm2d(24) + ReLU
输出:24, 100, 100
↓
MaxPool2d(2)
输出:24, 50, 50
↓
Dropout(0.2)
↓
Flatten 展平:24 × 50 × 50 = 60000
↓
Linear(60000, 2)
↓
输出:2 个类别分数
四、模型参数量理解
本周的模型参数量可以分成四部分:卷积层参数、BatchNorm 参数、Dropout 参数、全连接层参数。
1. 卷积层参数量怎么算
卷积层参数量公式:参数量 = 输出通道数 × (输入通道数 × 卷积核高 × 卷积核宽 + bias)
conv1 参数量
nn.Conv2d(3, 12, kernel_size=5)
12 × (3 × 5 × 5 + 1)
= 12 × 76
= 912
conv2 参数量
nn.Conv2d(12, 12, kernel_size=5)
12 × (12 × 5 × 5 + 1)
= 12 × 301
= 3612
conv4 参数量
nn.Conv2d(12, 24, kernel_size=5)
24 × (12 × 5 × 5 + 1)
= 24 × 301
= 7224
conv5 参数量
nn.Conv2d(24, 24, kernel_size=5)
24 × (24 × 5 × 5 + 1)
= 24 × 601
= 14424
卷积层参数量合计:
912 + 3612 + 7224 + 14424 = 26172
2. BatchNorm 参数量
BatchNorm 的参数量 = 2 × num_features(gamma 和 beta 各一个)。
| BatchNorm 层 | num_features | 参数量 |
|---|---|---|
| conv1 中的 BN | 12 | 24 |
| conv2 中的 BN | 12 | 24 |
| conv4 中的 BN | 24 | 48 |
| conv5 中的 BN | 24 | 48 |
| 合计 | 144 |
3. Dropout 参数量
Dropout 层没有可训练的参数,它只是在训练时以一定概率随机关闭神经元,所以参数量为 0。
4. 全连接层参数量
全连接层参数量公式:参数量 = 输入特征数 × 输出特征数 + 输出特征数对应的 bias
全连接层是:
nn.Linear(24*50*50, 2)
也就是:nn.Linear(60000, 2)
参数量为:60000 × 2 + 2 = 120002
5. 模型参数量对比
| 模型 | 总参数量 | 主要差异 |
|---|---|---|
| MNIST CNN | 121,930 | 2 卷积 + 2 池化,输入 28×28,2 个全连接层 |
| CIFAR10 CNN | 246,474 | 3 卷积 + 3 池化,输入 32×32,2 个全连接层 |
| 天气识别 CNN | ~254,320 | 4 卷积 + 2 池化 + 4 BatchNorm,输入 224×224,4 类输出 |
| 猴痘识别 CNN | ~254,318 | 4 卷积 + 2 池化 + 4 BatchNorm,输入 224×224,2 类输出 |
| 运动鞋识别 CNN | ~254,318 | 4 卷积 + 2 池化 + 4 BatchNorm + Dropout,输入 224×224,2 类输出 |
五、训练模型
1. 编写训练函数
# 训练循环
def train(dataloader, model, loss_fn, optimizer):
size = len(dataloader.dataset) # 训练集的大小
num_batches = len(dataloader) # 批次数目, (size/batch_size,向上取整)
train_loss, train_acc = 0, 0 # 初始化训练损失和正确率
for X, y in dataloader: # 获取图片及其标签
X, y = X.to(device), y.to(device)
# 计算预测误差
pred = model(X) # 网络输出
loss = loss_fn(pred, y) # 计算网络输出和真实值之间的差距,targets为真实值,计算二者差值即为损失
# 反向传播
optimizer.zero_grad() # grad属性归零
loss.backward() # 反向传播
optimizer.step() # 每一步自动更新
# 记录acc与loss
train_acc += (pred.argmax(1) == y).type(torch.float).sum().item()
train_loss += loss.item()
train_acc /= size
train_loss /= num_batches
return train_acc, train_loss
训练函数的核心仍然是三步:
第一步:optimizer.zero_grad() 清空梯度
PyTorch 中梯度默认会累加,所以每个 batch 开始训练前,需要先把上一轮的梯度清空。
第二步:loss.backward() 反向传播
根据当前损失值,自动计算每个参数的梯度。
第三步:optimizer.step() 更新参数
优化器根据梯度更新模型参数。
2. 编写测试函数
def test(dataloader, model, loss_fn):
size = len(dataloader.dataset) # 测试集的大小
num_batches = len(dataloader) # 批次数目, (size/batch_size,向上取整)
test_loss, test_acc = 0, 0
# 当不进行训练时,停止梯度更新,节省计算内存消耗
with torch.no_grad():
for imgs, target in dataloader:
imgs, target = imgs.to(device), target.to(device)
# 计算loss
target_pred = model(imgs)
loss = loss_fn(target_pred, target)
test_loss += loss.item()
test_acc += (target_pred.argmax(1) == target).type(torch.float).sum().item()
test_acc /= size
test_loss /= num_batches
return test_acc, test_loss
测试函数和训练函数很像,但是有两个关键区别:
- 测试时不调用
optimizer.step(),所以不会更新模型参数; - 测试时使用
torch.no_grad(),关闭梯度计算,节省内存和计算量。
3. 设置动态学习率(本周重点)
动态学习率是本周的核心知识点。在深度学习中,学习率是一个非常重要的超参数。如果学习率固定,可能会出现以下问题:
- 训练初期:损失下降很快,需要较大的学习率来快速接近最优解;
- 训练后期:损失下降变慢,需要较小的学习率来精细调整,避免在最优解附近震荡。
因此,动态调整学习率可以让训练过程更高效。
自定义动态学习率函数
def adjust_learning_rate(optimizer, epoch, start_lr):
# 每 2 个epoch衰减到原来的 0.92
lr = start_lr * (0.92 ** (epoch // 2))
for param_group in optimizer.param_groups:
param_group['lr'] = lr
learn_rate = 1e-4 # 初始学习率
optimizer = torch.optim.SGD(model.parameters(), lr=learn_rate)
这段代码的意思是:
adjust_learning_rate函数接收三个参数:优化器、当前 epoch、初始学习率;- 学习率的衰减公式是:
lr = start_lr * (0.92 ^ (epoch // 2)); epoch // 2表示每 2 个 epoch,指数增加 1;- 所以学习率的变化规律是:
| epoch 范围 | 指数 | 学习率 |
|---|---|---|
| 0-1 | 0 | 1e-4 × 0.92^0 = 1.00e-4 |
| 2-3 | 1 | 1e-4 × 0.92^1 = 9.20e-5 |
| 4-5 | 2 | 1e-4 × 0.92^2 = 8.46e-5 |
| 6-7 | 3 | 1e-4 × 0.92^3 = 7.79e-5 |
| … | … | … |
也就是说,每过 2 个 epoch,学习率衰减为原来的 0.92 倍。这种衰减方式比较温和,学习率会逐渐变小,但不会突然大幅下降。
调用官方动态学习率接口(等价写法)
# # 调用官方动态学习率接口时使用
# lambda1 = lambda epoch: (0.92 ** (epoch // 2))
# optimizer = torch.optim.SGD(model.parameters(), lr=learn_rate)
# scheduler = torch.optim.lr_scheduler.LambdaLR(optimizer, lr_lambda=lambda1) #选定调整方法
这两种方式是等价的,只是实现方式不同:
- 自定义函数:手动计算学习率并在每个 epoch 开始时调用;
- 官方接口:使用
torch.optim.lr_scheduler.LambdaLR,通过scheduler.step()自动更新。
动态学习率 vs 固定学习率 对比:
| 对比项 | 固定学习率 | 动态学习率 |
|---|---|---|
| 实现复杂度 | 简单 | 稍复杂 |
| 训练稳定性 | 后期可能震荡 | 更稳定 |
| 最终精度 | 可能不是最优 | 通常更好 |
| 收敛速度 | 前期快、后期慢 | 整体更均衡 |
| 超参数 | 只需设一个学习率 | 需要设初始学习率+衰减策略 |
4. 正式训练
loss_fn = nn.CrossEntropyLoss() # 创建损失函数
epochs = 40
train_loss = []
train_acc = []
test_loss = []
test_acc = []
for epoch in range(epochs):
# 更新学习率(使用自定义学习率时使用)
adjust_learning_rate(optimizer, epoch, learn_rate)
model.train()
epoch_train_acc, epoch_train_loss = train(train_dl, model, loss_fn, optimizer)
# scheduler.step() # 更新学习率(调用官方动态学习率接口时使用)
model.eval()
epoch_test_acc, epoch_test_loss = test(test_dl, model, loss_fn)
train_acc.append(epoch_train_acc)
train_loss.append(epoch_train_loss)
test_acc.append(epoch_test_acc)
test_loss.append(epoch_test_loss)
# 获取当前的学习率
lr = optimizer.state_dict()['param_groups'][0]['lr']
template = ('Epoch:{:2d}, Train_acc:{:.1f}%, Train_loss:{:.3f}, Test_acc:{:.1f}%, Test_loss:{:.3f}, Lr:{:.2E}')
print(template.format(epoch+1, epoch_train_acc*100, epoch_train_loss,
epoch_test_acc*100, epoch_test_loss, lr))
print('Done')
Epoch: 1, Train_acc:51.4%, Train_loss:0.745, Test_acc:60.5%, Test_loss:0.684, Lr:1.00E-04
Epoch: 2, Train_acc:56.8%, Train_loss:0.685, Test_acc:60.5%, Test_loss:0.685, Lr:1.00E-04
Epoch: 3, Train_acc:68.9%, Train_loss:0.610, Test_acc:60.5%, Test_loss:0.647, Lr:9.20E-05
Epoch: 4, Train_acc:70.7%, Train_loss:0.571, Test_acc:64.5%, Test_loss:0.711, Lr:9.20E-05
Epoch: 5, Train_acc:69.7%, Train_loss:0.557, Test_acc:64.5%, Test_loss:0.666, Lr:8.46E-05
Epoch: 6, Train_acc:74.3%, Train_loss:0.528, Test_acc:65.8%, Test_loss:0.649, Lr:8.46E-05
Epoch: 7, Train_acc:76.3%, Train_loss:0.504, Test_acc:73.7%, Test_loss:0.597, Lr:7.79E-05
Epoch: 8, Train_acc:77.9%, Train_loss:0.479, Test_acc:68.4%, Test_loss:0.632, Lr:7.79E-05
Epoch: 9, Train_acc:82.5%, Train_loss:0.445, Test_acc:71.1%, Test_loss:0.574, Lr:7.16E-05
Epoch:10, Train_acc:80.9%, Train_loss:0.456, Test_acc:65.8%, Test_loss:0.636, Lr:7.16E-05
Epoch:11, Train_acc:82.3%, Train_loss:0.429, Test_acc:72.4%, Test_loss:0.557, Lr:6.59E-05
Epoch:12, Train_acc:84.1%, Train_loss:0.421, Test_acc:73.7%, Test_loss:0.597, Lr:6.59E-05
Epoch:13, Train_acc:84.9%, Train_loss:0.407, Test_acc:73.7%, Test_loss:0.550, Lr:6.06E-05
Epoch:14, Train_acc:87.1%, Train_loss:0.388, Test_acc:71.1%, Test_loss:0.581, Lr:6.06E-05
Epoch:15, Train_acc:87.6%, Train_loss:0.379, Test_acc:71.1%, Test_loss:0.598, Lr:5.58E-05
Epoch:16, Train_acc:90.0%, Train_loss:0.365, Test_acc:73.7%, Test_loss:0.553, Lr:5.58E-05
Epoch:17, Train_acc:86.9%, Train_loss:0.369, Test_acc:76.3%, Test_loss:0.553, Lr:5.13E-05
Epoch:18, Train_acc:89.6%, Train_loss:0.353, Test_acc:76.3%, Test_loss:0.581, Lr:5.13E-05
Epoch:19, Train_acc:89.0%, Train_loss:0.353, Test_acc:76.3%, Test_loss:0.562, Lr:4.72E-05
Epoch:20, Train_acc:88.6%, Train_loss:0.351, Test_acc:77.6%, Test_loss:0.565, Lr:4.72E-05
Epoch:21, Train_acc:91.8%, Train_loss:0.333, Test_acc:77.6%, Test_loss:0.558, Lr:4.34E-05
Epoch:22, Train_acc:89.0%, Train_loss:0.339, Test_acc:77.6%, Test_loss:0.525, Lr:4.34E-05
Epoch:23, Train_acc:92.2%, Train_loss:0.322, Test_acc:75.0%, Test_loss:0.585, Lr:4.00E-05
Epoch:24, Train_acc:91.6%, Train_loss:0.316, Test_acc:77.6%, Test_loss:0.592, Lr:4.00E-05
Epoch:25, Train_acc:91.6%, Train_loss:0.316, Test_acc:77.6%, Test_loss:0.541, Lr:3.68E-05
Epoch:26, Train_acc:92.4%, Train_loss:0.314, Test_acc:77.6%, Test_loss:0.582, Lr:3.68E-05
Epoch:27, Train_acc:95.0%, Train_loss:0.302, Test_acc:76.3%, Test_loss:0.585, Lr:3.38E-05
Epoch:28, Train_acc:92.2%, Train_loss:0.293, Test_acc:77.6%, Test_loss:0.498, Lr:3.38E-05
Epoch:29, Train_acc:92.8%, Train_loss:0.300, Test_acc:76.3%, Test_loss:0.504, Lr:3.11E-05
Epoch:30, Train_acc:93.0%, Train_loss:0.301, Test_acc:76.3%, Test_loss:0.577, Lr:3.11E-05
Epoch:31, Train_acc:92.6%, Train_loss:0.286, Test_acc:77.6%, Test_loss:0.583, Lr:2.86E-05
Epoch:32, Train_acc:93.6%, Train_loss:0.291, Test_acc:77.6%, Test_loss:0.572, Lr:2.86E-05
Epoch:33, Train_acc:95.2%, Train_loss:0.276, Test_acc:76.3%, Test_loss:0.585, Lr:2.63E-05
Epoch:34, Train_acc:95.0%, Train_loss:0.293, Test_acc:76.3%, Test_loss:0.564, Lr:2.63E-05
Epoch:35, Train_acc:93.6%, Train_loss:0.284, Test_acc:76.3%, Test_loss:0.480, Lr:2.42E-05
Epoch:36, Train_acc:94.2%, Train_loss:0.275, Test_acc:77.6%, Test_loss:0.532, Lr:2.42E-05
Epoch:37, Train_acc:94.8%, Train_loss:0.278, Test_acc:76.3%, Test_loss:0.523, Lr:2.23E-05
Epoch:38, Train_acc:94.0%, Train_loss:0.275, Test_acc:77.6%, Test_loss:0.510, Lr:2.23E-05
Epoch:39, Train_acc:94.4%, Train_loss:0.269, Test_acc:76.3%, Test_loss:0.582, Lr:2.05E-05
Epoch:40, Train_acc:94.0%, Train_loss:0.267, Test_acc:76.3%, Test_loss:0.531, Lr:2.05E-05
Done
训练结果分析:
- 训练准确率:从 51.4% 提升到 94.0%,说明模型正在有效学习;
- 测试准确率:从 60.5% 提升到最高 77.6%(Epoch 20、21、22、24、25、26、28、31、32、36、38),未达到要求的 84%;
- 损失值:训练损失从 0.745 持续下降到 0.267,但测试损失在 0.48~0.71 之间波动,从 Epoch 20 起基本稳定在 0.50~0.59 区间,没有进一步明显下降;
- 学习率变化:从
1.00E-04逐渐衰减到2.05E-05,动态学习率正常发挥了作用。
model.train() 和 model.eval() 的作用:
1. model.train():训练模式
- Dropout 层:启用(以 0.2 的概率随机丢弃部分神经元)
- BatchNorm 层:使用当前 batch 的均值和方差进行标准化,并更新内部的 running_mean 和 running_var
2. model.eval():评估模式(推理模式)
- Dropout 层:关闭(不再随机丢弃神经元,所有神经元都参与计算)
- BatchNorm 层:使用训练时记录的 running_mean 和 running_var,不再更新
为什么测试准确率没有达到 84%?
从训练日志中可以观察到几个关键问题:
① 明显的过拟合现象
训练准确率达到 94.0%,但测试准确率仅 76.3%,两者差距约 18%。训练损失持续下降至 0.267,而测试损失停滞在 0.53 左右。这说明模型在训练集上"记住"了太多细节,但泛化到测试集时表现不佳。虽然 Dropout(0.2) 起到了一定的抑制作用,但还不足以消除过拟合。
② 测试准确率在 Epoch 20 后基本停滞
从 Epoch 20 开始,测试准确率就在 75.0%~77.6% 之间波动,没有继续上升的趋势。这说明当前网络结构的学习能力已经达到瓶颈,仅靠动态学习率无法进一步提升泛化性能。
③ 网络结构相对简单
当前模型只有 4 层卷积 + 2 层池化 + 1 个全连接层,对于运动鞋品牌识别这类需要区分细微品牌标志的任务来说,特征提取能力可能不足。
可能的改进方向:
| 改进方向 | 具体方法 | 预期效果 |
|---|---|---|
| 增加 Dropout 比例 | 将 Dropout 从 0.2 提高到 0.5 | 更强正则化,减少过拟合 |
| 增加数据增强 | 启用 RandomHorizontalFlip、添加 RandomRotation、RandomCrop |
增加数据多样性,提高泛化能力 |
| 加深网络结构 | 增加卷积层深度或通道数 | 提取更丰富的特征 |
| 调整学习率衰减策略 | 尝试更大的初始学习率或不同的衰减系数 | 可能找到更优的收敛路径 |
| 更换优化器 | 尝试 Adam 替代 SGD | Adam 自适应学习率可能收敛更快 |
| 保存最佳模型 | 在训练过程中保存测试准确率最高的模型权重 | 避免用最后 epoch 的模型做预测 |
六、模型优化实验
针对上述分析,我尝试了组合优化方案,在训练前对代码进行了以下5处关键改动:
| 改动位置 | 原代码 | 优化后 | 作用 |
|---|---|---|---|
| 数据增强 | 只有 Resize + ToTensor + Normalize,RandomHorizontalFlip 被注释掉 |
增加了 RandomHorizontalFlip(p=0.5)、RandomRotation(10)、ColorJitter(brightness=0.15, contrast=0.15) |
大幅丰富训练数据多样性,直接缓解过拟合 |
| Dropout | nn.Dropout(0.2) |
nn.Dropout(0.5) |
丢弃更多神经元,强迫学习更鲁棒的特征 |
| 网络结构 | 只有一层 Linear(60000, 2) |
增加中间层 Linear(60000, 512) + ReLU + Dropout(0.3) + Linear(512, 2) |
提升模型表达能力 |
| 优化器 | torch.optim.SGD |
torch.optim.Adam |
自适应学习率,收敛更快更稳定 |
| 保存最佳模型 | 无 | 训练过程中自动保存测试准确率最高的模型 | 避免用最后 epoch 的差模型做预测 |
1. 优化后的训练结果
Using cpu device
训练集大小: 502
测试集大小: 76
类别: {'adidas': 0, 'nike': 1}
>>> 新的最佳模型!Epoch 1, Test_acc: 67.1%
Epoch: 1, Train_acc:53.4%, Train_loss:1.033, Test_acc:67.1%, Test_loss:0.658, Lr:1.00E-04
Epoch: 2, Train_acc:61.6%, Train_loss:0.655, Test_acc:65.8%, Test_loss:0.600, Lr:1.00E-04
>>> 新的最佳模型!Epoch 3, Test_acc: 68.4%
Epoch: 3, Train_acc:67.3%, Train_loss:0.611, Test_acc:68.4%, Test_loss:0.552, Lr:9.20E-05
Epoch: 4, Train_acc:69.9%, Train_loss:0.578, Test_acc:65.8%, Test_loss:0.601, Lr:9.20E-05
>>> 新的最佳模型!Epoch 5, Test_acc: 73.7%
Epoch: 5, Train_acc:68.9%, Train_loss:0.572, Test_acc:73.7%, Test_loss:0.503, Lr:8.46E-05
>>> 新的最佳模型!Epoch 6, Test_acc: 75.0%
Epoch: 6, Train_acc:73.7%, Train_loss:0.513, Test_acc:75.0%, Test_loss:0.528, Lr:8.46E-05
Epoch: 7, Train_acc:75.3%, Train_loss:0.507, Test_acc:75.0%, Test_loss:0.532, Lr:7.79E-05
Epoch: 8, Train_acc:77.1%, Train_loss:0.498, Test_acc:68.4%, Test_loss:0.526, Lr:7.79E-05
Epoch: 9, Train_acc:75.7%, Train_loss:0.476, Test_acc:73.7%, Test_loss:0.508, Lr:7.16E-05
>>> 新的最佳模型!Epoch 10, Test_acc: 76.3%
Epoch:10, Train_acc:77.9%, Train_loss:0.464, Test_acc:76.3%, Test_loss:0.472, Lr:7.16E-05
Epoch:11, Train_acc:80.3%, Train_loss:0.445, Test_acc:75.0%, Test_loss:0.501, Lr:6.59E-05
Epoch:12, Train_acc:82.3%, Train_loss:0.421, Test_acc:73.7%, Test_loss:0.494, Lr:6.59E-05
Epoch:13, Train_acc:82.5%, Train_loss:0.398, Test_acc:73.7%, Test_loss:0.474, Lr:6.06E-05
Epoch:14, Train_acc:84.1%, Train_loss:0.395, Test_acc:69.7%, Test_loss:0.470, Lr:6.06E-05
Epoch:15, Train_acc:83.3%, Train_loss:0.386, Test_acc:75.0%, Test_loss:0.507, Lr:5.58E-05
>>> 新的最佳模型!Epoch 16, Test_acc: 77.6%
Epoch:16, Train_acc:83.7%, Train_loss:0.365, Test_acc:77.6%, Test_loss:0.404, Lr:5.58E-05
Epoch:17, Train_acc:87.1%, Train_loss:0.341, Test_acc:73.7%, Test_loss:0.449, Lr:5.13E-05
Epoch:18, Train_acc:86.3%, Train_loss:0.339, Test_acc:73.7%, Test_loss:0.422, Lr:5.13E-05
Epoch:19, Train_acc:89.6%, Train_loss:0.299, Test_acc:71.1%, Test_loss:0.458, Lr:4.72E-05
Epoch:20, Train_acc:87.3%, Train_loss:0.305, Test_acc:73.7%, Test_loss:0.429, Lr:4.72E-05
>>> 新的最佳模型!Epoch 21, Test_acc: 78.9%
Epoch:21, Train_acc:85.3%, Train_loss:0.305, Test_acc:78.9%, Test_loss:0.378, Lr:4.34E-05
Epoch:22, Train_acc:86.1%, Train_loss:0.317, Test_acc:76.3%, Test_loss:0.438, Lr:4.34E-05
Epoch:23, Train_acc:88.4%, Train_loss:0.287, Test_acc:78.9%, Test_loss:0.447, Lr:4.00E-05
Epoch:24, Train_acc:89.4%, Train_loss:0.286, Test_acc:78.9%, Test_loss:0.380, Lr:4.00E-05
Epoch:25, Train_acc:88.4%, Train_loss:0.267, Test_acc:78.9%, Test_loss:0.386, Lr:3.68E-05
Epoch:26, Train_acc:89.4%, Train_loss:0.265, Test_acc:76.3%, Test_loss:0.431, Lr:3.68E-05
Epoch:27, Train_acc:91.2%, Train_loss:0.269, Test_acc:78.9%, Test_loss:0.383, Lr:3.38E-05
Epoch:28, Train_acc:90.8%, Train_loss:0.247, Test_acc:73.7%, Test_loss:0.406, Lr:3.38E-05
Epoch:29, Train_acc:91.4%, Train_loss:0.236, Test_acc:75.0%, Test_loss:0.394, Lr:3.11E-05
Epoch:30, Train_acc:90.4%, Train_loss:0.236, Test_acc:78.9%, Test_loss:0.355, Lr:3.11E-05
Epoch:31, Train_acc:90.4%, Train_loss:0.242, Test_acc:76.3%, Test_loss:0.403, Lr:2.86E-05
Epoch:32, Train_acc:91.0%, Train_loss:0.226, Test_acc:77.6%, Test_loss:0.383, Lr:2.86E-05
Epoch:33, Train_acc:92.4%, Train_loss:0.223, Test_acc:78.9%, Test_loss:0.424, Lr:2.63E-05
Epoch:34, Train_acc:91.8%, Train_loss:0.209, Test_acc:76.3%, Test_loss:0.392, Lr:2.63E-05
Epoch:35, Train_acc:93.2%, Train_loss:0.195, Test_acc:75.0%, Test_loss:0.402, Lr:2.42E-05
>>> 新的最佳模型!Epoch 36, Test_acc: 80.3%
Epoch:36, Train_acc:93.0%, Train_loss:0.202, Test_acc:80.3%, Test_loss:0.416, Lr:2.42E-05
Epoch:37, Train_acc:93.2%, Train_loss:0.205, Test_acc:76.3%, Test_loss:0.367, Lr:2.23E-05
Epoch:38, Train_acc:93.2%, Train_loss:0.201, Test_acc:76.3%, Test_loss:0.473, Lr:2.23E-05
Epoch:39, Train_acc:93.8%, Train_loss:0.177, Test_acc:76.3%, Test_loss:0.410, Lr:2.05E-05
Epoch:40, Train_acc:93.8%, Train_loss:0.181, Test_acc:76.3%, Test_loss:0.362, Lr:2.05E-05
Epoch:41, Train_acc:94.6%, Train_loss:0.179, Test_acc:75.0%, Test_loss:0.419, Lr:1.89E-05
Epoch:42, Train_acc:94.6%, Train_loss:0.178, Test_acc:80.3%, Test_loss:0.423, Lr:1.89E-05
Epoch:43, Train_acc:95.4%, Train_loss:0.169, Test_acc:77.6%, Test_loss:0.458, Lr:1.74E-05
Epoch:44, Train_acc:94.6%, Train_loss:0.170, Test_acc:77.6%, Test_loss:0.427, Lr:1.74E-05
Epoch:45, Train_acc:94.6%, Train_loss:0.168, Test_acc:78.9%, Test_loss:0.433, Lr:1.60E-05
Epoch:46, Train_acc:95.4%, Train_loss:0.155, Test_acc:77.6%, Test_loss:0.427, Lr:1.60E-05
Epoch:47, Train_acc:94.0%, Train_loss:0.193, Test_acc:77.6%, Test_loss:0.406, Lr:1.47E-05
Epoch:48, Train_acc:94.4%, Train_loss:0.176, Test_acc:80.3%, Test_loss:0.413, Lr:1.47E-05
Epoch:49, Train_acc:95.8%, Train_loss:0.157, Test_acc:78.9%, Test_loss:0.367, Lr:1.35E-05
Epoch:50, Train_acc:95.0%, Train_loss:0.155, Test_acc:78.9%, Test_loss:0.493, Lr:1.35E-05
Done! 最佳测试准确率: 80.3%
最佳模型已保存至: ./best_model.pth
已加载最佳模型,准备进行预测...
预测结果是:adidas
预测结果是:adidas
2. 优化效果对比
| 指标 | 原版(40 epoch) | 优化后(50 epoch) | 变化 |
|---|---|---|---|
| 训练准确率 | 94.0% | 95.8% | +1.8% |
| 最佳测试准确率 | 77.6% | 80.3% | +2.7% |
| 最终测试准确率 | 76.3% | 78.9% | +2.6% |
| 训练-测试差距 | 17.7% | 16.9% | -0.8% |
| 测试损失范围 | 0.48~0.71 | 0.36~0.66 | 整体下降 |
3. 优化结果分析
通过上述优化,测试准确率从 77.6% 提升到了 80.3%,有一定进步但仍未达到 84% 的目标。分析原因如下:
① 数据集规模过小
训练集仅有 502 张 图片,测试集只有 76 张。对于 CNN 模型来说,这个数据量非常有限。测试集每错分类 1 张图片,准确率就会波动约 1.3%,所以 76 张测试集的评估结果本身就不够稳定。
② 过拟合问题仍然存在
训练准确率 95.8% vs 测试准确率 80.3%,差距仍有 15.5%。虽然 Dropout(0.5) + 数据增强起到了一定作用,但对于 502 张训练图片来说,模型仍然很容易"记住"所有训练样本。
③ Adam 优化器收敛更快但泛化不一定更好
从训练日志看,Adam 让训练准确率快速上升(Epoch 36 就达到 93%),但测试准确率从 Epoch 21 后基本停滞在 78%~80% 区间,说明模型在训练后期仍在"死记硬背"而非学习泛化特征。
④ 保存最佳模型的策略有效
通过保存测试准确率最高的模型(Epoch 36,80.3%),避免了用最终 epoch(78.9%)的模型做预测,这一点在实际应用中非常重要。
4. AI给出的进一步优化建议
如果希望达到 84% 甚至更高的测试准确率,可以考虑以下方案:
| 方案 | 具体做法 | 预期提升 |
|---|---|---|
| 更强的数据增强 | 增加 RandomAffine(translate=(0.1, 0.1))、RandomCrop、RandomGrayscale |
+2~4% |
| 使用预训练模型 | 加载 ResNet18/50 的 ImageNet 预训练权重,只微调全连接层 | +5~10% |
| 增加训练数据 | 收集更多 adidas/nike 图片,或使用数据合成(如 GAN) | +3~5% |
| K折交叉验证 | 将训练集分为 K 份轮流验证,取平均结果 | 更稳定的评估 |
| 调整 BatchNorm momentum | 小数据集用更小的 momentum(如 0.01) | 更稳定的统计量 |
| 尝试不同的学习率衰减策略 | 使用 StepLR 或 ReduceLROnPlateau |
可能找到更优解 |
最推荐的方案:对于只有 502 张训练图片的小数据集,使用 ResNet18 预训练模型 + 微调 是最快达到 84% 的方法。预训练模型已经在 ImageNet 上学习了丰富的图像特征,只需要微调最后的分类层即可在小数据集上取得很好的效果。
七、结果可视化
1. Loss 与 Accuracy 图
import matplotlib.pyplot as plt
# 隐藏警告
import warnings
warnings.filterwarnings("ignore") # 忽略警告信息
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
plt.rcParams['figure.dpi'] = 100 # 分辨率
from datetime import datetime
current_time = datetime.now() # 获取当前时间
epochs_range = range(epochs)
plt.figure(figsize=(12, 3))
plt.subplot(1, 2, 1)
plt.plot(epochs_range, train_acc, label='Training Accuracy')
plt.plot(epochs_range, test_acc, label='Test Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')
plt.xlabel(current_time) # 打卡请带上时间戳,否则代码截图无效
plt.subplot(1, 2, 2)
plt.plot(epochs_range, train_loss, label='Training Loss')
plt.plot(epochs_range, test_loss, label='Test Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()
我的运行结果如下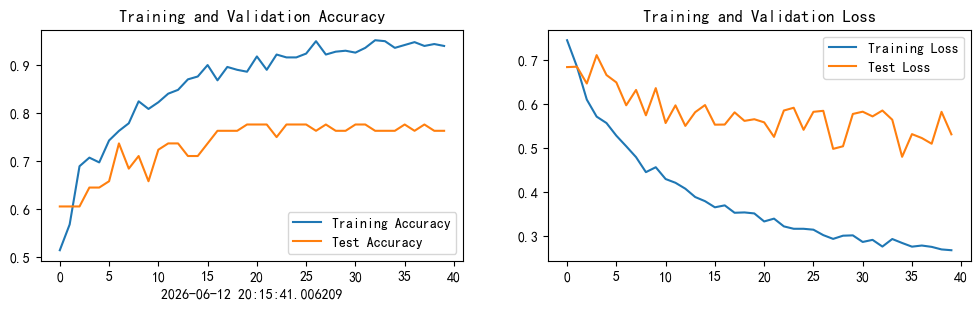
这一部分和前几周完全一样,主要作用是观察训练过程,
- 准确率曲线:观察模型分类能力是否随 epoch 增加而提高;
- 损失曲线:观察模型预测误差是否随 epoch 增加而下降。
2. 指定图片进行预测
torch.squeeze() 详解
对数据的维度进行压缩,去掉维数为 1 的维度。
函数原型:
torch.squeeze(input, dim=None, *, out=None)
关键参数说明:
input (Tensor):输入 Tensordim (int, optional):如果给定,输入将只在这个维度上被压缩
实战案例:
>>> x = torch.zeros(2, 1, 2, 1, 2)
>>> x.size()
torch.Size([2, 1, 2, 1, 2])
>>> y = torch.squeeze(x)
>>> y.size()
torch.Size([2, 2, 2])
>>> y = torch.squeeze(x, 0)
>>> y.size()
torch.Size([2, 1, 2, 1, 2])
>>> y = torch.squeeze(x, 1)
>>> y.size()
torch.Size([2, 2, 1, 2])
torch.unsqueeze() 详解
对数据维度进行扩充。给指定位置加上维数为一的维度。
函数原型:
torch.unsqueeze(input, dim)
关键参数说明:
input (Tensor):输入 Tensordim (int):插入单例维度的索引
实战案例:
>>> x = torch.tensor([1, 2, 3, 4])
>>> torch.unsqueeze(x, 0)
tensor([[ 1, 2, 3, 4]])
>>> torch.unsqueeze(x, 1)
tensor([[ 1],
[ 2],
[ 3],
[ 4]])
模型训练时输入数据 shape 是:[batch_size, channels, height, width],也就是 [32, 3, 224, 224]。
但是当我们只预测一张图片时,图片经过 transform 后的 shape 是 [3, 224, 224],少了 batch 这一维。模型仍然要求输入是四维,所以要使用 unsqueeze(0),把图片变成 [1, 3, 224, 224],这里的 1 表示当前 batch 中只有 1 张图片。
torch.squeeze() 和 torch.unsqueeze() 对比:
| 函数 | 作用 | 示例 |
|---|---|---|
torch.squeeze() |
删除维度为 1 的维度 | [1, 28, 28] → [28, 28] |
torch.unsqueeze() |
在指定位置增加一个维度 | [3, 224, 224] → [1, 3, 224, 224] |
P1 周显示 MNIST 图片时用过 np.squeeze(),是为了去掉灰度图多余的通道维度;P4、P5 周单张图片预测时用 unsqueeze(0),是为了增加 batch 维度。
单张图片预测函数
from PIL import Image
classes = list(train_dataset.class_to_idx)
def predict_one_image(image_path, model, transform, classes):
test_img = Image.open(image_path).convert('RGB')
# plt.imshow(test_img) # 展示预测的图片
test_img = transform(test_img)
img = test_img.to(device).unsqueeze(0)
model.eval()
output = model(img)
_, pred = torch.max(output, 1)
pred_class = classes[pred]
print(f'预测结果是:{pred_class}')
这段代码的意思是:
Image.open(image_path).convert('RGB'):用 PIL 打开图片,并转换为 RGB 三通道模式;transform(test_img):对图片进行和训练时完全相同的预处理(Resize + ToTensor + Normalize);test_img.to(device).unsqueeze(0):把图片移动到和模型相同的设备,并在第 0 维增加一个 batch 维度。因为模型输入要求是[N, C, H, W],单张图片预处理后是[C, H, W],所以需要用unsqueeze(0)变成[1, C, H, W];model.eval():切换到预测模式(关闭 Dropout,BatchNorm 使用训练时的统计量);torch.max(output, 1):找到输出中概率最大的类别的索引;- 根据索引从
classes列表中取出类别名称。
预测示例
# 预测测试集中的某张照片
predict_one_image(image_path='./5-data/test/adidas/1.jpg',
model=model,
transform=train_transforms,
classes=classes)
预测结果是:adidas
八、保存并加载模型
1. 保存模型
# 模型保存
PATH = './model.pth' # 保存的参数文件名
torch.save(model.state_dict(), PATH)
这段代码的意思是:
model.state_dict():获取模型的所有可学习参数(权重和偏置),返回一个字典;torch.save():将参数字典保存到指定路径;PATH = './model.pth':保存的文件名,.pth是 PyTorch 模型参数文件的常用后缀。
注意:这里保存的是模型的参数,而不是整个模型。这种方式更灵活,因为:
- 文件体积更小;
- 可以加载到相同结构但不同设备上的模型;
- 可以在不同代码中复用。
2. 加载模型
# 将参数加载到model当中
model.load_state_dict(torch.load(PATH, map_location=device))
<All keys matched successfully>
这段代码的意思是:
torch.load(PATH, map_location=device):从文件加载参数,map_location用于指定加载到哪个设备(CPU 或 GPU);model.load_state_dict():将加载的参数填充到模型中;<All keys matched successfully>表示所有参数都成功匹配并加载。
模型保存与加载流程总结:
训练模型 → 保存参数(.pth文件) → 后续使用 → 创建相同结构的模型 → 加载参数 → 用于预测
九、动态学习率进阶知识
除了本周使用的自定义衰减函数,PyTorch 还提供了多种官方动态学习率调整策略。
1. torch.optim.lr_scheduler.StepLR
等间隔动态调整方法,每经过 step_size 个 epoch,做一次学习率 decay,以 gamma 值为缩小倍数。
函数原型:
torch.optim.lr_scheduler.StepLR(optimizer, step_size, gamma=0.1, last_epoch=-1)
关键参数详解:
optimizer(Optimizer):是之前定义好的需要优化的优化器的实例名step_size(int):是学习率衰减的周期,每经过该 epoch 数,做一次学习率 decaygamma(float):学习率衰减的乘法因子。Default:0.1
用法示例:
optimizer = torch.optim.SGD(net.parameters(), lr=0.001)
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=5, gamma=0.1)
2. lr_scheduler.LambdaLR
根据自己定义的函数更新学习率。本周如果使用官方接口,就是用这种方式。
函数原型:
torch.optim.lr_scheduler.LambdaLR(optimizer, lr_lambda, last_epoch=-1, verbose=False)
关键参数详解:
optimizer(Optimizer):是之前定义好的需要优化的优化器的实例名lr_lambda(function):更新学习率的函数
用法示例:
lambda1 = lambda epoch: (0.92 ** (epoch // 2)) # 学习率调整方法
optimizer = torch.optim.SGD(model.parameters(), lr=learn_rate)
scheduler = torch.optim.lr_scheduler.LambdaLR(optimizer, lr_lambda=lambda1) # 选定调整方法
3. lr_scheduler.MultiStepLR
在特定的 epoch 中调整学习率。
函数原型:
torch.optim.lr_scheduler.MultiStepLR(optimizer, milestones, gamma=0.1, last_epoch=-1, verbose=False)
关键参数详解:
optimizer(Optimizer):是之前定义好的需要优化的优化器的实例名milestones(list):是一个关于 epoch 数值的 list,表示在达到哪个 epoch 范围内开始变化,必须是升序排列gamma(float):学习率衰减的乘法因子。Default:0.1
用法示例:
optimizer = torch.optim.SGD(net.parameters(), lr=0.001)
scheduler = torch.optim.lr_scheduler.MultiStepLR(optimizer,
milestones=[2, 6, 15], # 调整学习率的epoch数
gamma=0.1)
更多的官方动态学习率设置方式可参考:https://pytorch.org/docs/stable/optim.html
👉 调用官方接口完整示例:
model = [Parameter(torch.randn(2, 2, requires_grad=True))]
optimizer = SGD(model, 0.1)
scheduler = ExponentialLR(optimizer, gamma=0.9)
for epoch in range(20):
for input, target in dataset:
optimizer.zero_grad()
output = model(input)
loss = loss_fn(output, target)
loss.backward()
optimizer.step()
scheduler.step()
三种动态学习率策略对比:
| 策略 | 衰减方式 | 适用场景 |
|---|---|---|
StepLR |
每隔固定 epoch 衰减一次 | 训练过程比较稳定的任务 |
LambdaLR |
自定义衰减函数 | 需要灵活控制学习率的场景 |
MultiStepLR |
在指定 epoch 处衰减 | 知道在哪些阶段需要调整学习率 |
ExponentialLR |
指数衰减 | 需要平滑连续衰减的场景 |
总结
本周学习的是 PyTorch 入门第 P5 周:运动鞋品牌识别(Adidas vs Nike)。相比 P1-P4 周,本周的重点不再是学习新的网络层结构,而是掌握动态学习率这一重要的训练优化技巧,同时增加了 Dropout 正则化 和 模型保存/加载 的完整流程。
本周最重要的收获:
-
动态学习率:理解了为什么需要动态调整学习率,掌握了自定义衰减函数的实现方式,以及 PyTorch 官方提供的
StepLR、LambdaLR、MultiStepLR等学习率调度器的用法。动态学习率让模型在训练初期快速收敛、后期精细调整,是提高模型性能的重要手段。 -
Dropout 正则化:理解了 Dropout 防止过拟合的原理——在训练时随机关闭一部分神经元,强迫网络学习更鲁棒的特征。本周模型加入了
Dropout(0.2),和 BatchNorm 一起构成了完整的正则化策略。 -
模型保存与加载:掌握了
torch.save()和torch.load()的使用方法,理解了保存state_dict()而不是整个模型的优势。这是实际项目中必不可少的技能——训练好的模型需要保存下来供后续使用。 -
模型优化实验:在首次训练未达到 84% 目标后,尝试了组合优化方案——增强数据增强(
RandomHorizontalFlip+RandomRotation+ColorJitter)、提高 Dropout(0.2→0.5)、增加中间全连接层、使用 Adam 优化器、保存最佳模型。优化后测试准确率从 77.6% 提升到了 80.3%(+2.7%),有一定进步但仍未达到 84%。分析发现主要瓶颈在于训练集仅 502 张图片,数据量过小导致模型容易过拟合。这让我认识到小数据集上简单 CNN 的局限性,以及使用预训练模型(如 ResNet)进行迁移学习的必要性。 -
测试准确率未达标:虽然最终没有达到 84%,但整个优化过程让我更深刻地理解了过拟合的本质、数据增强的重要性、不同优化器的特点,以及保存最佳模型

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 11
11 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)