企业级 AI 知识引擎:02多格式文本提取
全模态文件解析引擎:让所有文件说同一种语言
不挑格式,不丢内容。一套管道吞下办公文档、图片、音频、网页、日志,吐出干净、分块、可检索的纯文本。
目标:格式无差别 → 文本无损耗 → 入库无冗余。

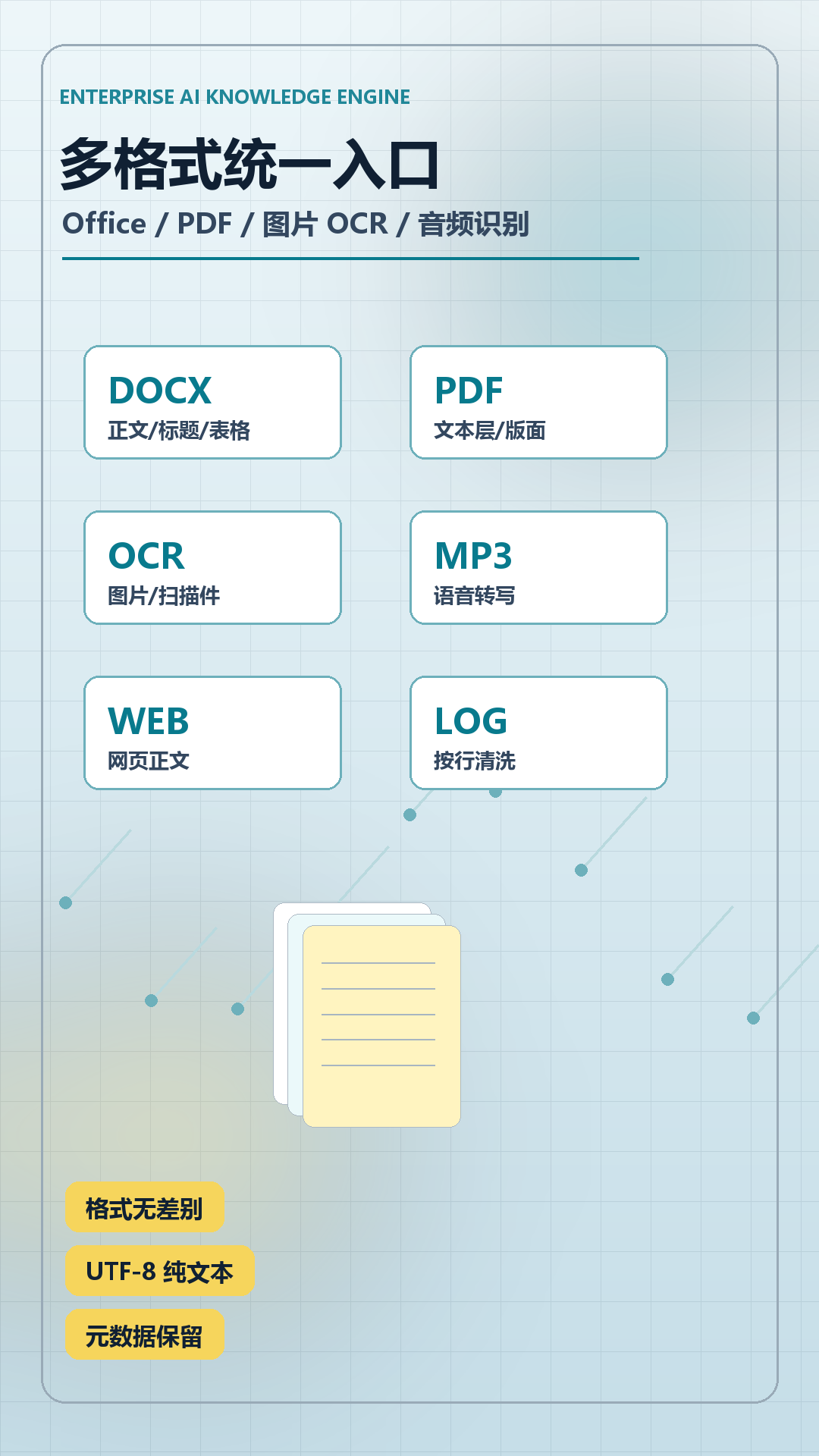
📄 第一层:格式归一化
解决“什么文件能进来”。覆盖 20+ 种实际业务格式:
办公文档:.doc/.docx/.xls/.xlsx/.ppt/.pptx/.pdf
老版 PPT:NPOI 暴力扫描二进制 .ppt,直接提取文字原子,不依赖 COM 或 Office 组件
图片 OCR:.jpg/.png/.bmp/.tif,调用外部 ocrimg.exe 进行高精度文字识别
音频语音:.wav/.mp3/.m4a/.aac → NAudio 重采样 + Whisper.net 本地离线转写
纯文本族:.txt/.log/.md/.csv/.xml/.html
所有格式统一输出 UTF-8 纯文本,并保留原始元数据(文件名、格式、大小、创建时间),供后续过滤与追溯。
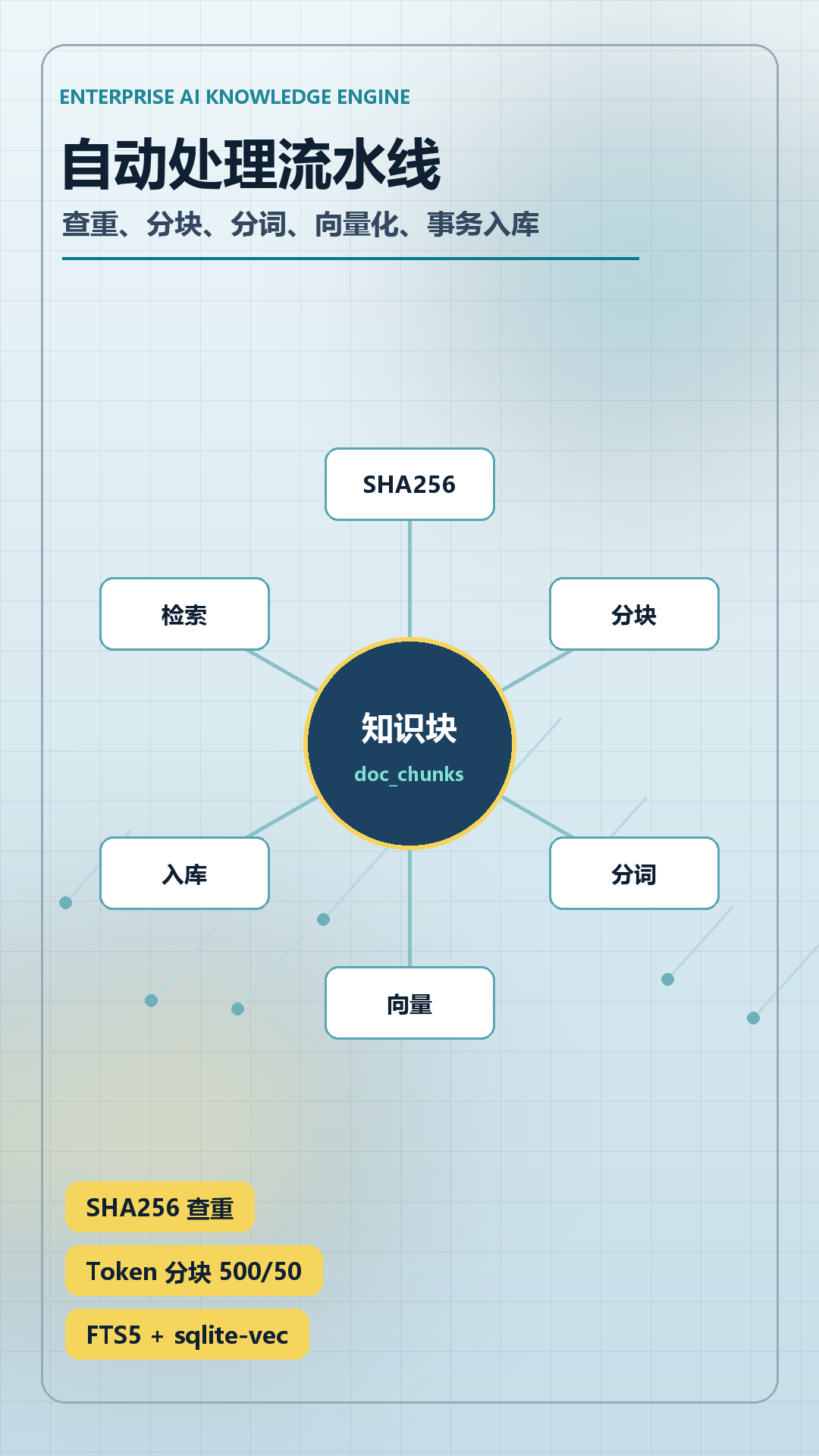
⚙️ 第二层:全自动处理流水线
文本从解析到入库,中间必须经过工程化清洗与切分,一步不能少:
哈希查重:SHA256 计算文件指纹,相同文档自动跳过,防止重复入库。
Token 分块:按 500 token 切分(重叠 50 token),保留语义边界,适配嵌入模型上下文长度。
中文分词:集成 jieba.NET,对分块文本精确分词,为 FTS5 全文索引提供词元。
向量化嵌入:通过本地 LLM(LlamaSharp + GGUF 模型)生成嵌入向量,超长文本分块后平均池化。
事务入库:写入 SQLite + sqlite-vec 的 vss_doc_chunks 向量表,同时建立 FTS5 倒排索引。
每一步可观测、可断点续传,确保资料“读得懂、切得准、存得稳”。
🔍 第三层:混合索引与检索准备
入库后的知识块同时支持三种召回方式,为上层 RAG 问答铺路:
关键词索引:FTS5 全文索引 + 结巴分词,适合精确匹配(合同编号、产品型号、人名地名)。
语义向量:sqlite-vec 近邻检索,适合模糊问法(“那份关于预算调整的 PPT”)。
元数据过滤:按来源文件、项目、时间、权限等标签提前剪枝。
检索时采用 RRF(倒数排名融合) 加权合并 BM25 + 向量得分,不依赖外部搜索引擎,纯本地运行。
🧰 工程要点
零外部依赖:老 PPT 用 NPOI 二进制扫描;OCR 可外挂 ocrimg.exe 也可用内置轻量版;音频全离线转写。
全自动初始化:SQLite 自动配置 sqlite-vec 扩展,创建 FTS5 虚拟表和向量表,无需手动建库。
事务保证:文件元数据(FileIndexService)与向量块同库写入,支持 CRUD 与回滚。
多模态扩展:Florence-2 模型支持图像描述、目标检测等视觉问答,与纯文本向量统一管理。
📌 总结
全模态文件解析引擎的核心不是“能打开多少种格式”,而是把异构、脏乱、多源的原始文件,变成干净、分块、可检索、可追溯的向量化知识块。没有这一层,上层的 RAG 问答、混合检索、多轮对话都是空中楼阁。
🗺️ 后续拆解路线
接下来逐层拆解:
哈希查重与分块策略(如何定义重复、如何选择块大小)→ 中文分词与 FTS5 调优 → 向量化嵌入与池化方案 → RRF 混合检索工程实现 → 音频/图片解析深度优化。
先讲全局,再拆模块,下期见。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 16
16 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)